 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Δ$ynamics: Language-Based Representation for Inferring Rigid-Body Dynamics From Videos
May 20, 2026Inferring rigid-body physical states and properties from monocular videos is a fundamental step toward physics-based perception and simulation. Existing approaches assume specific underlying physical systems, object types, and camera poses, making them unable to generalize to complex real-world settings. We introduce $Δ$YNAMICS, a vision-language framework that uses language as a unified representation of rigid-body dynamics. Instead of directly predicting parameters, $Δ$YNAMICS generates scene configurations in a structured text format for physics simulation. We enhance the model's generalization by integrating natural language motion reasoning and leveraging optical flow as a semantic-agnostic input. On the CLEVRER dataset, $Δ$YNAMICS achieves a segmentation IoU of 0.30, a 7x improvement over leading VLMs (InternVL3-8B, Qwen2.5-VL-7B and Claude-4-Sonnet). Additionally, test-time sampling and evolutionary search further boost performance by 27% and 120% in segmentation IoU, respectively. Finally, we demonstrate strong transfer to a new dataset of 235 real-world rigid-body videos, highlighting the potential of language-driven physics inference for bridging perception and simulation.
AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery
Oct 31, 2024



Clouds in satellite imagery pose a significant challenge for downstream applications. A major challenge in current cloud removal research is the absence of a comprehensive benchmark and a sufficiently large and diverse training dataset. To address this problem, we introduce the largest public dataset -- $\textit{AllClear}$ for cloud removal, featuring 23,742 globally distributed regions of interest (ROIs) with diverse land-use patterns, comprising 4 million images in total. Each ROI includes complete temporal captures from the year 2022, with (1) multi-spectral optical imagery from Sentinel-2 and Landsat 8/9, (2) synthetic aperture radar (SAR) imagery from Sentinel-1, and (3) auxiliary remote sensing products such as cloud masks and land cover maps. We validate the effectiveness of our dataset by benchmarking performance, demonstrating the scaling law -- the PSNR rises from $28.47$ to $33.87$ with $30\times$ more data, and conducting ablation studies on the temporal length and the importance of individual modalities. This dataset aims to provide comprehensive coverage of the Earth's surface and promote better cloud removal results.
Counter-Current Learning: A Biologically Plausible Dual Network Approach for Deep Learning
Sep 30, 2024Despite its widespread use in neural networks, error backpropagation has faced criticism for its lack of biological plausibility, suffering from issues such as the backward locking problem and the weight transport problem. These limitations have motivated researchers to explore more biologically plausible learning algorithms that could potentially shed light on how biological neural systems adapt and learn. Inspired by the counter-current exchange mechanisms observed in biological systems, we propose counter-current learning (CCL), a biologically plausible framework for credit assignment in neural networks. This framework employs a feedforward network to process input data and a feedback network to process targets, with each network enhancing the other through anti-parallel signal propagation. By leveraging the more informative signals from the bottom layer of the feedback network to guide the updates of the top layer of the feedforward network and vice versa, CCL enables the simultaneous transformation of source inputs to target outputs and the dynamic mutual influence of these transformations. Experimental results on MNIST, FashionMNIST, CIFAR10, and CIFAR100 datasets using multi-layer perceptrons and convolutional neural networks demonstrate that CCL achieves comparable performance to other biologically plausible algorithms while offering a more biologically realistic learning mechanism. Furthermore, we showcase the applicability of our approach to an autoencoder task, underscoring its potential for unsupervised representation learning. Our work presents a direction for biologically inspired and plausible learning algorithms, offering an alternative mechanisms of learning and adaptation in neural networks.
Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
Mar 05, 2024



Large-scale sequence modeling has sparked rapid advances that now extend into biology and genomics. However, modeling genomic sequences introduces challenges such as the need to model long-range token interactions, the effects of upstream and downstream regions of the genome, and the reverse complementarity (RC) of DNA. Here, we propose an architecture motivated by these challenges that builds off the long-range Mamba block, and extends it to a BiMamba component that supports bi-directionality, and to a MambaDNA block that additionally supports RC equivariance. We use MambaDNA as the basis of Caduceus, the first family of RC equivariant bi-directional long-range DNA language models, and we introduce pre-training and fine-tuning strategies that yield Caduceus DNA foundation models. Caduceus outperforms previous long-range models on downstream benchmarks; on a challenging long-range variant effect prediction task, Caduceus exceeds the performance of 10x larger models that do not leverage bi-directionality or equivariance.
FedBug: A Bottom-Up Gradual Unfreezing Framework for Federated Learning
Jul 19, 2023Federated Learning (FL) offers a collaborative training framework, allowing multiple clients to contribute to a shared model without compromising data privacy. Due to the heterogeneous nature of local datasets, updated client models may overfit and diverge from one another, commonly known as the problem of client drift. In this paper, we propose FedBug (Federated Learning with Bottom-Up Gradual Unfreezing), a novel FL framework designed to effectively mitigate client drift. FedBug adaptively leverages the client model parameters, distributed by the server at each global round, as the reference points for cross-client alignment. Specifically, on the client side, FedBug begins by freezing the entire model, then gradually unfreezes the layers, from the input layer to the output layer. This bottom-up approach allows models to train the newly thawed layers to project data into a latent space, wherein the separating hyperplanes remain consistent across all clients. We theoretically analyze FedBug in a novel over-parameterization FL setup, revealing its superior convergence rate compared to FedAvg. Through comprehensive experiments, spanning various datasets, training conditions, and network architectures, we validate the efficacy of FedBug. Our contributions encompass a novel FL framework, theoretical analysis, and empirical validation, demonstrating the wide potential and applicability of FedBug.
MAML is a Noisy Contrastive Learner
Jun 29, 2021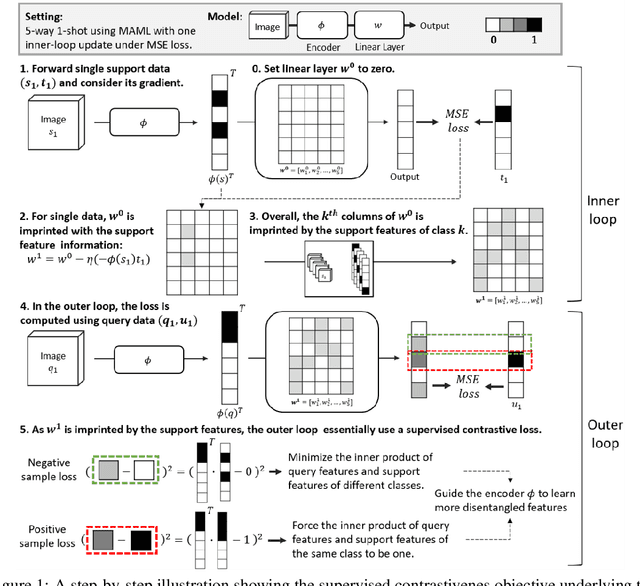
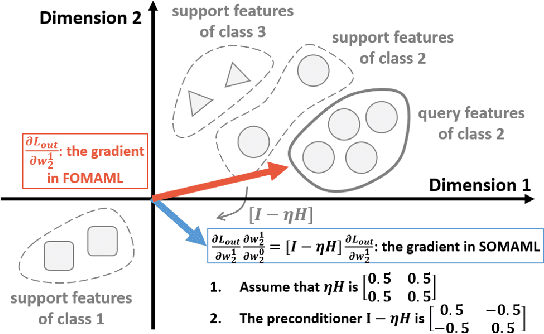
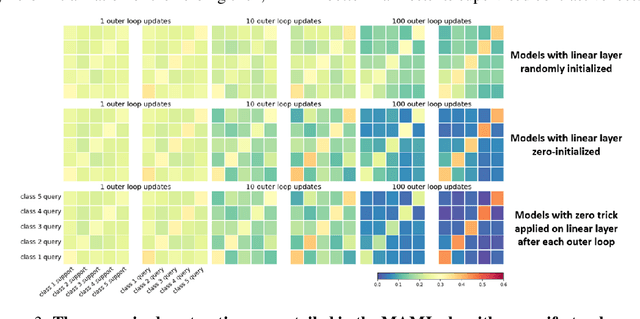
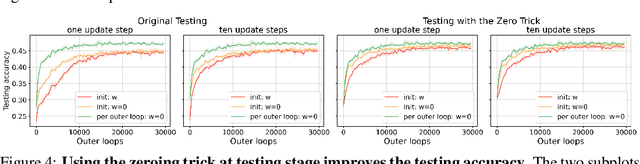
Model-agnostic meta-learning (MAML) is one of the most popular and widely-adopted meta-learning algorithms nowadays, which achieves remarkable success in various learning problems. Yet, with the unique design of nested inner-loop and outer-loop updates which respectively govern the task-specific and meta-model-centric learning, the underlying learning objective of MAML still remains implicit and thus impedes a more straightforward understanding of it. In this paper, we provide a new perspective to the working mechanism of MAML and discover that: MAML is analogous to a meta-learner using a supervised contrastive objective function, where the query features are pulled towards the support features of the same class and against those of different classes, in which such contrastiveness is experimentally verified via an analysis based on the cosine similarity. Moreover, our analysis reveals that the vanilla MAML algorithm has an undesirable interference term originating from the random initialization and the cross-task interaction. We therefore propose a simple but effective technique, zeroing trick, to alleviate such interference, where the extensive experiments are then conducted on both miniImagenet and Omniglot datasets to demonstrate the consistent improvement brought by our proposed technique thus well validating its effectiveness.