 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARBEN: Composite Adversarial Robustness Benchmark
Jul 16, 2022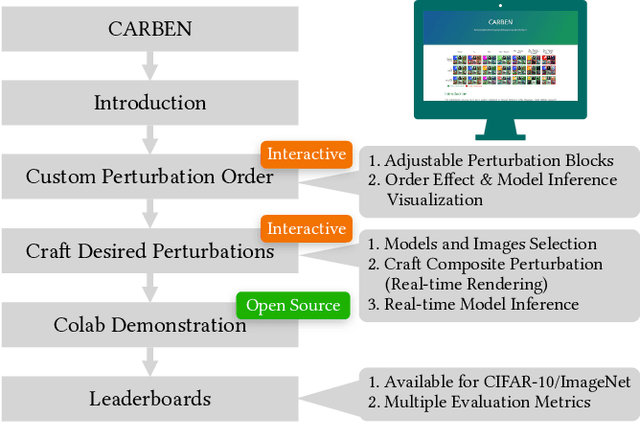



Prior literature on adversarial attack methods has mainly focused on attacking with and defending against a single threat model, e.g., perturbations bounded in Lp ball. However, multiple threat models can be combined into composite perturbations. One such approach, composite adversarial attack (CAA), not only expands the perturbable space of the image, but also may be overlooked by current modes of robustness evaluation. This paper demonstrates how CAA's attack order affects the resulting image, and provides real-time inferences of different models, which will facilitate users' configuration of the parameters of the attack level and their rapid evaluation of model prediction. A leaderboard to benchmark adversarial robustness against CAA is also introduced.
Generalization Guarantee of Training Graph Convolutional Networks with Graph Topology Sampling
Jul 07, 2022
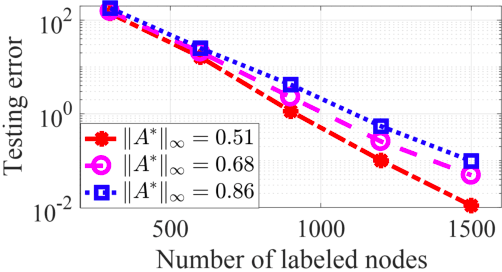
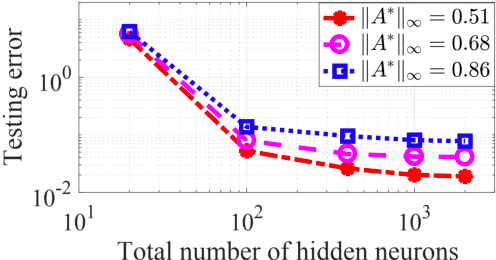

Graph convolutional networks (GCNs) have recently achieved great empirical success in learning graph-structured data. To address its scalability issue due to the recursive embedding of neighboring features, graph topology sampling has been proposed to reduce the memory and computational cost of training GCNs, and it has achieved comparable test performance to those without topology sampling in many empirical studies. To the best of our knowledge, this paper provides the first theoretical justification of graph topology sampling in training (up to) three-layer GCNs for semi-supervised node classification. We formally characterize some sufficient conditions on graph topology sampling such that GCN training leads to a diminishing generalization error. Moreover, our method tackles the nonconvex interaction of weights across layers, which is under-explored in the existing theoretical analyses of GCNs. This paper characterizes the impact of graph structures and topology sampling on the generalization performance and sample complexity explicitly, and the theoretical findings are also justified through numerical experiments.
On Certifying and Improving Generalization to Unseen Domains
Jun 24, 2022
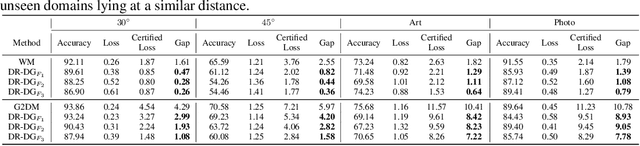
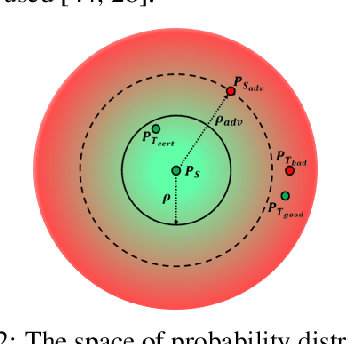
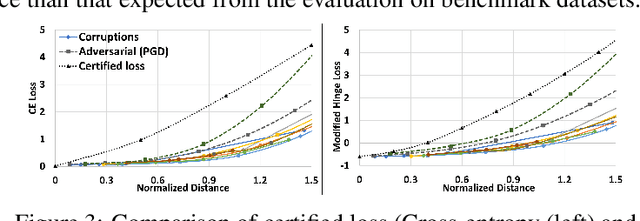
Domain Generalization (DG) aims to learn models whose performance remains high on unseen domains encountered at test-time by using data from multiple related source domains. Many existing DG algorithms reduce the divergence between source distributions in a representation space to potentially align the unseen domain close to the sources. This is motivated by the analysis that explains generalization to unseen domains using distributional distance (such as the Wasserstein distance) to the sources. However, due to the openness of the DG objective, it is challenging to evaluate DG algorithms comprehensively using a few benchmark datasets. In particular, we demonstrate that the accuracy of the models trained with DG methods varies significantly across unseen domains, generated from popular benchmark datasets. This highlights that the performance of DG methods on a few benchmark datasets may not be representative of their performance on unseen domains in the wild. To overcome this roadblock, we propose a universal certification framework based on distributionally robust optimization (DRO) that can efficiently certify the worst-case performance of any DG method. This enables a data-independent evaluation of a DG method complementary to the empirical evaluations on benchmark datasets. Furthermore, we propose a training algorithm that can be used with any DG method to provably improve their certified performance. Our empirical evaluation demonstrates the effectiveness of our method at significantly improving the worst-case loss (i.e., reducing the risk of failure of these models in the wild) without incurring a significant performance drop on benchmark datasets.
Linearity Grafting: Relaxed Neuron Pruning Helps Certifiable Robustness
Jun 15, 2022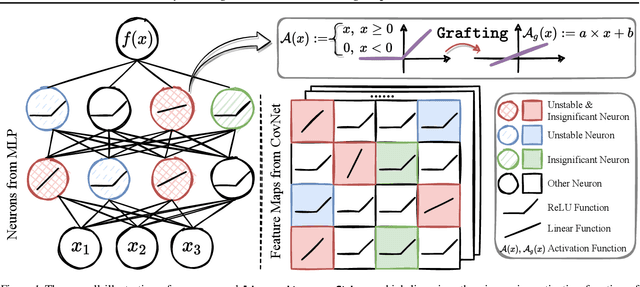
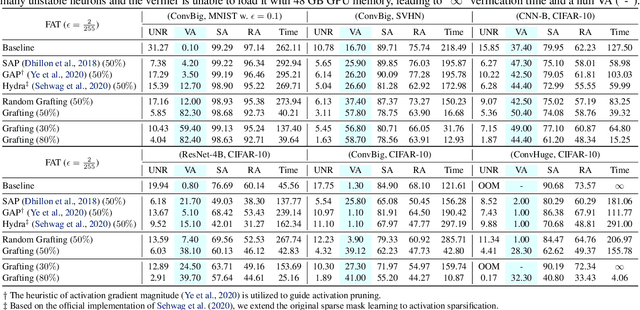
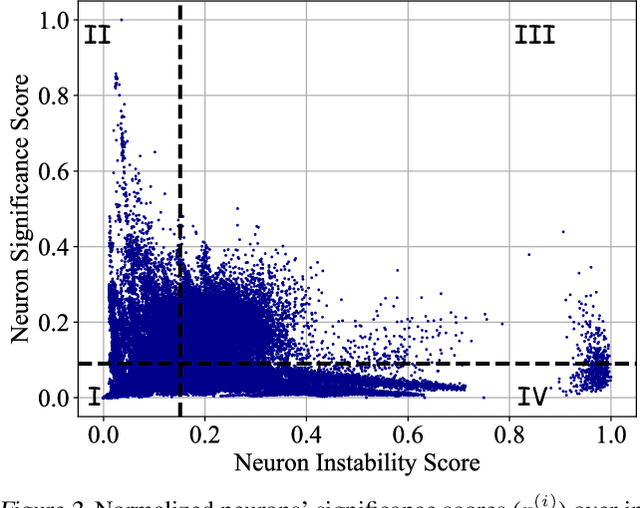
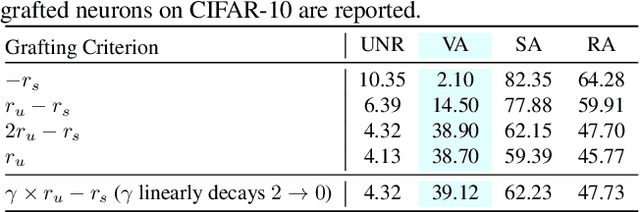
Certifiable robustness is a highly desirable property for adopting deep neural networks (DNNs) in safety-critical scenarios, but often demands tedious computations to establish. The main hurdle lies in the massive amount of non-linearity in large DNNs. To trade off the DNN expressiveness (which calls for more non-linearity) and robustness certification scalability (which prefers more linearity), we propose a novel solution to strategically manipulate neurons, by "grafting" appropriate levels of linearity. The core of our proposal is to first linearize insignificant ReLU neurons, to eliminate the non-linear components that are both redundant for DNN performance and harmful to its certification. We then optimize the associated slopes and intercepts of the replaced linear activations for restoring model performance while maintaining certifiability. Hence, typical neuron pruning could be viewed as a special case of grafting a linear function of the fixed zero slopes and intercept, that might overly restrict the network flexibility and sacrifice its performance. Extensive experiments on multiple datasets and network backbones show that our linearity grafting can (1) effectively tighten certified bounds; (2) achieve competitive certifiable robustness without certified robust training (i.e., over 30% improvements on CIFAR-10 models); and (3) scale up complete verification to large adversarially trained models with 17M parameters. Codes are available at https://github.com/VITA-Group/Linearity-Grafting.
Distributed Adversarial Training to Robustify Deep Neural Networks at Scale
Jun 13, 2022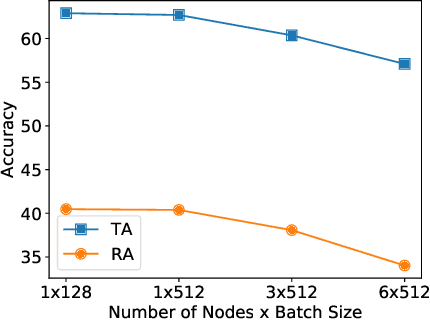
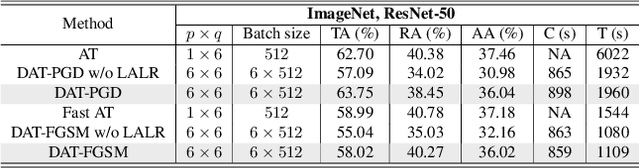
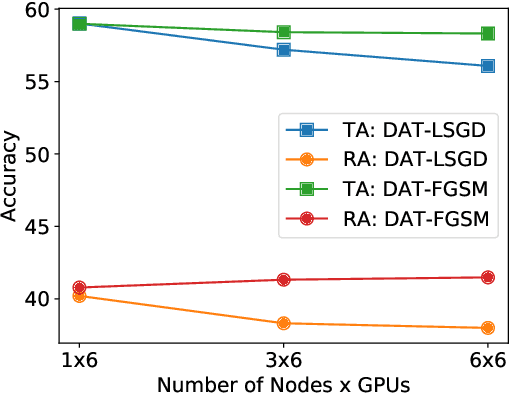
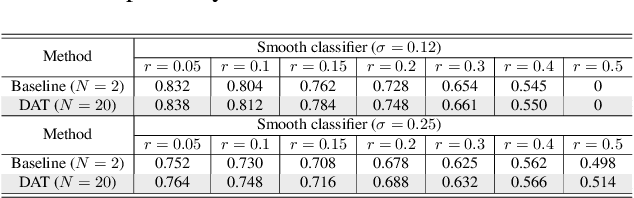
Current deep neural networks (DNNs) are vulnerable to adversarial attacks, where adversarial perturbations to the inputs can change or manipulate classification. To defend against such attacks, an effective and popular approach, known as adversarial training (AT), has been shown to mitigate the negative impact of adversarial attacks by virtue of a min-max robust training method. While effective, it remains unclear whether it can successfully be adapted to the distributed learning context. The power of distributed optimization over multiple machines enables us to scale up robust training over large models and datasets. Spurred by that, we propose distributed adversarial training (DAT), a large-batch adversarial training framework implemented over multiple machines. We show that DAT is general, which supports training over labeled and unlabeled data, multiple types of attack generation methods, and gradient compression operations favored for distributed optimization. Theoretically, we provide, under standard conditions in the optimization theory, the convergence rate of DAT to the first-order stationary points in general non-convex settings. Empirically, we demonstrate that DAT either matches or outperforms state-of-the-art robust accuracies and achieves a graceful training speedup (e.g., on ResNet-50 under ImageNet). Codes are available at https://github.com/dat-2022/dat.
Sharp-MAML: Sharpness-Aware Model-Agnostic Meta Learning
Jun 10, 2022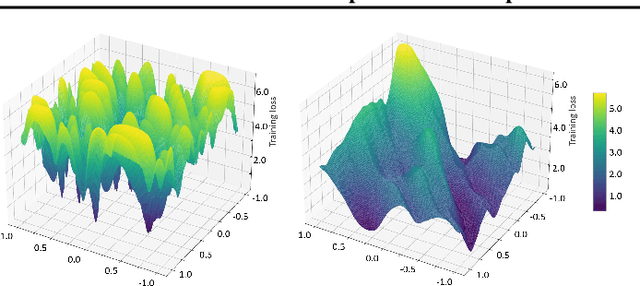
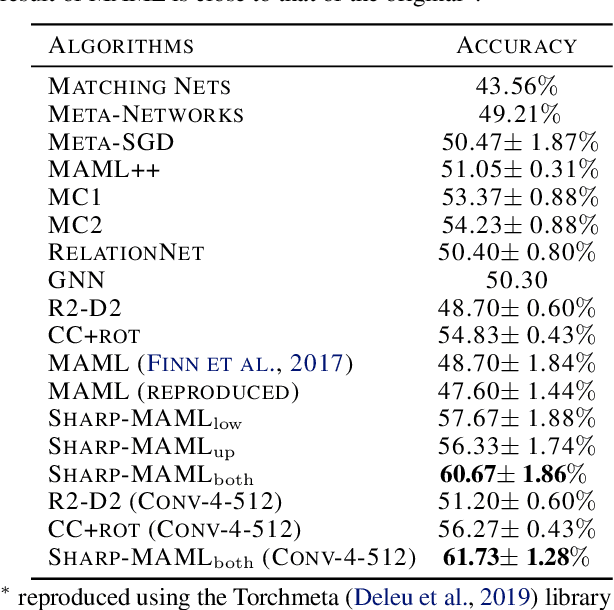
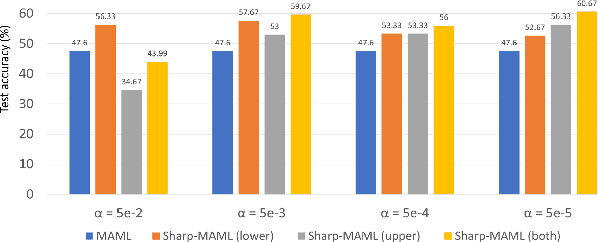
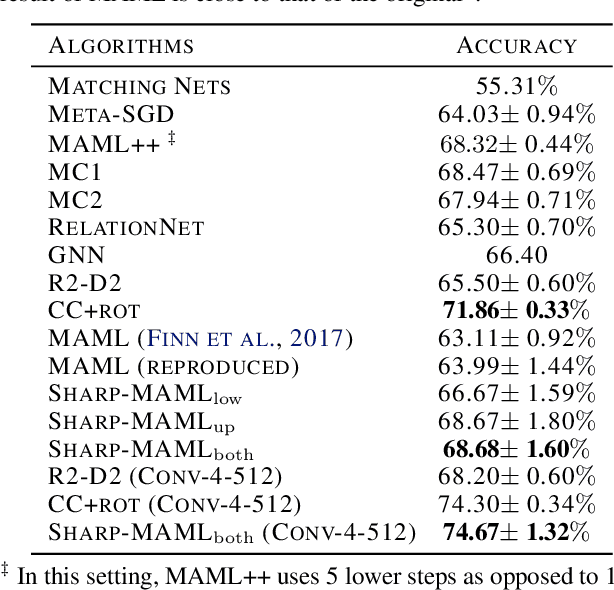
Model-agnostic meta learning (MAML) is currently one of the dominating approaches for few-shot meta-learning. Albeit its effectiveness, the optimization of MAML can be challenging due to the innate bilevel problem structure. Specifically, the loss landscape of MAML is much more complex with possibly more saddle points and local minimizers than its empirical risk minimization counterpart. To address this challenge, we leverage the recently invented sharpness-aware minimization and develop a sharpness-aware MAML approach that we term Sharp-MAML. We empirically demonstrate that Sharp-MAML and its computation-efficient variant can outperform popular existing MAML baselines (e.g., $+12\%$ accuracy on Mini-Imagenet). We complement the empirical study with the convergence rate analysis and the generalization bound of Sharp-MAML. To the best of our knowledge, this is the first empirical and theoretical study on sharpness-aware minimization in the context of bilevel learning. The code is available at https://github.com/mominabbass/Sharp-MAML.
Theoretical Error Performance Analysis for Variational Quantum Circuit Based Functional Regression
Jun 08, 2022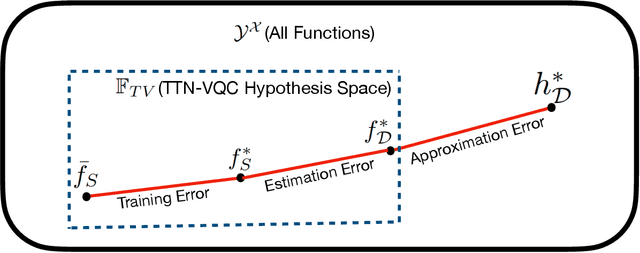

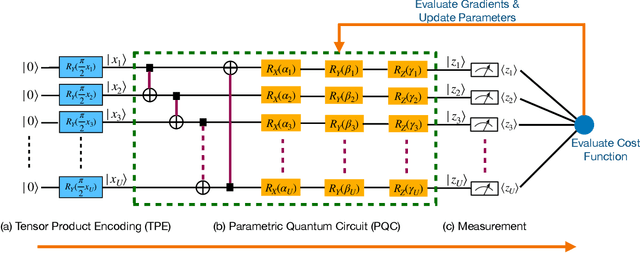
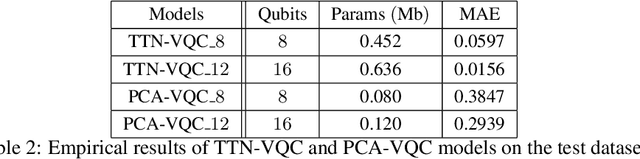
The noisy intermediate-scale quantum (NISQ) devices enable the implementation of the variational quantum circuit (VQC) for quantum neural networks (QNN). Although the VQC-based QNN has succeeded in many machine learning tasks, the representation and generalization powers of VQC still require further investigation, particularly when the dimensionality reduction of classical inputs is concerned. In this work, we first put forth an end-to-end quantum neural network, namely, TTN-VQC, which consists of a quantum tensor network based on a tensor-train network (TTN) for dimensionality reduction and a VQC for functional regression. Then, we aim at the error performance analysis for the TTN-VQC in terms of representation and generalization powers. We also characterize the optimization properties of TTN-VQC by leveraging the Polyak-Lojasiewicz (PL) condition. Moreover, we conduct the experiments of functional regression on a handwritten digit classification dataset to justify our theoretical analysis.
Learning Geometrically Disentangled Representations of Protein Folding Simulations
May 20, 2022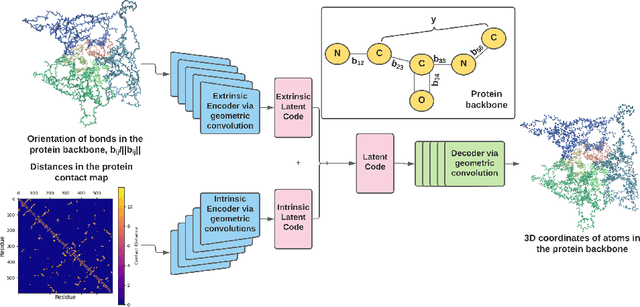
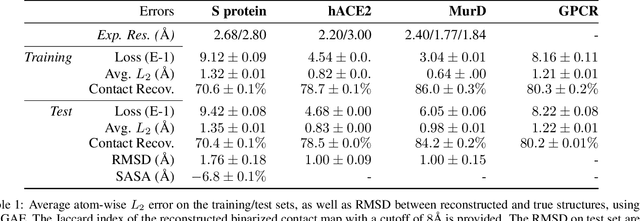
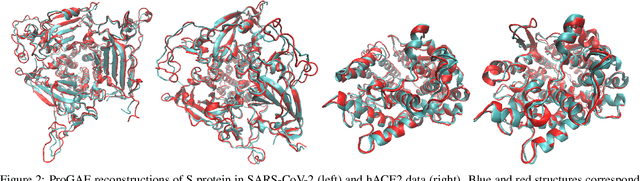

Massive molecular simulations of drug-target proteins have been used as a tool to understand disease mechanism and develop therapeutics. This work focuses on learning a generative neural network on a structural ensemble of a drug-target protein, e.g. SARS-CoV-2 Spike protein, obtained from computationally expensive molecular simulations. Model tasks involve characterizing the distinct structural fluctuations of the protein bound to various drug molecules, as well as efficient generation of protein conformations that can serve as an complement of a molecular simulation engine. Specifically, we present a geometric autoencoder framework to learn separate latent space encodings of the intrinsic and extrinsic geometries of the protein structure. For this purpose, the proposed Protein Geometric AutoEncoder (ProGAE) model is trained on the protein contact map and the orientation of the backbone bonds of the protein. Using ProGAE latent embeddings, we reconstruct and generate the conformational ensemble of a protein at or near the experimental resolution, while gaining better interpretability and controllability in term of protein structure generation from the learned latent space. Additionally, ProGAE models are transferable to a different state of the same protein or to a new protein of different size, where only the dense layer decoding from the latent representation needs to be retrained. Results show that our geometric learning-based method enjoys both accuracy and efficiency for generating complex structural variations, charting the path toward scalable and improved approaches for analyzing and enhancing high-cost simulations of drug-target proteins.
A Word is Worth A Thousand Dollars: Adversarial Attack on Tweets Fools Stock Prediction
May 11, 2022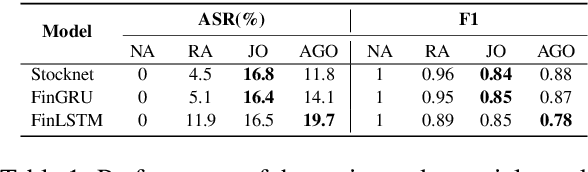
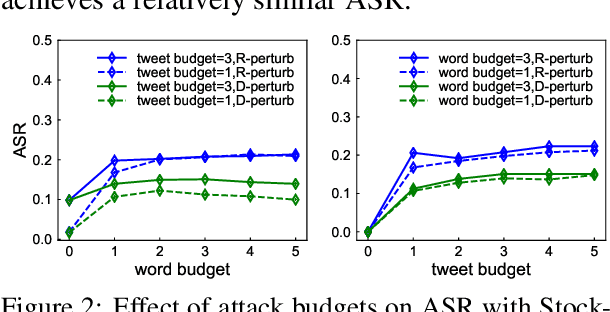
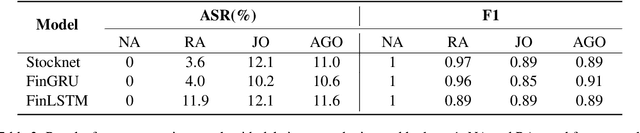
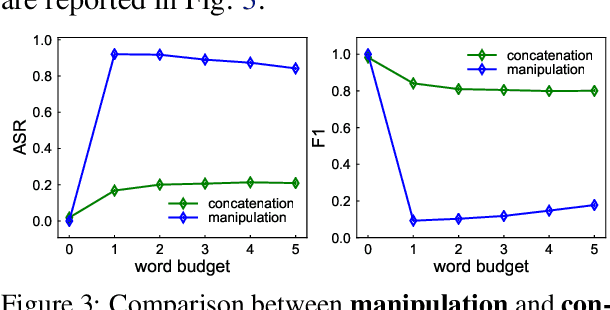
More and more investors and machine learning models rely on social media (e.g., Twitter and Reddit) to gather real-time information and sentiment to predict stock price movements. Although text-based models are known to be vulnerable to adversarial attacks, whether stock prediction models have similar vulnerability is underexplored. In this paper, we experiment with a variety of adversarial attack configurations to fool three stock prediction victim models. We address the task of adversarial generation by solving combinatorial optimization problems with semantics and budget constraints. Our results show that the proposed attack method can achieve consistent success rates and cause significant monetary loss in trading simulation by simply concatenating a perturbed but semantically similar tweet.
Evaluating the Adversarial Robustness for Fourier Neural Operators
Apr 08, 2022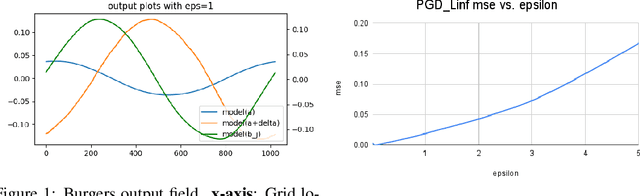
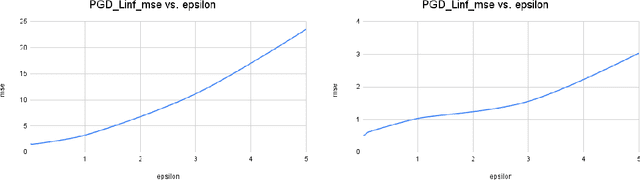
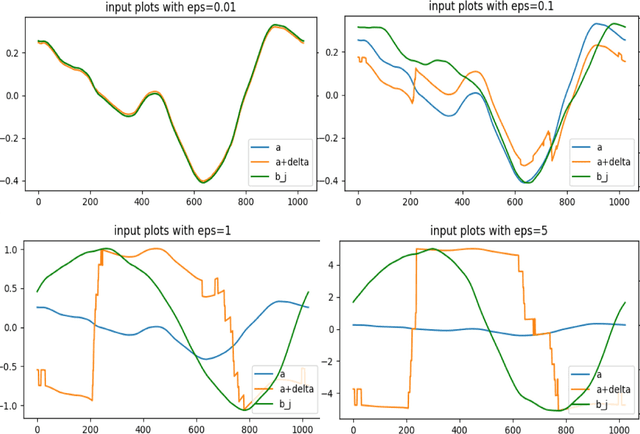
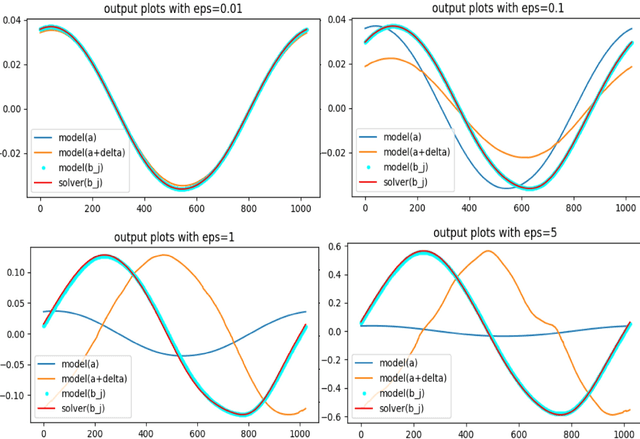
In recent years, Machine-Learning (ML)-driven approaches have been widely used in scientific discovery domains. Among them, the Fourier Neural Operator (FNO) was the first to simulate turbulent flow with zero-shot super-resolution and superior accuracy, which significantly improves the speed when compared to traditional partial differential equation (PDE) solvers. To inspect the trustworthiness, we provide the first study on the adversarial robustness of scientific discovery models by generating adversarial examples for FNO, based on norm-bounded data input perturbations. Evaluated on the mean squared error between the FNO model's output and the PDE solver's output, our results show that the model's robustness degrades rapidly with increasing perturbation levels, particularly in non-simplistic cases like the 2D Darcy and the Navier cases. Our research provides a sensitivity analysis tool and evaluation principles for assessing the adversarial robustness of ML-based scientific discovery models.