 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReprogramming Pretrained Language Models for Protein Sequence Representation Learning
Jan 05, 2023Machine Learning-guided solutions for protein learning tasks have made significant headway in recent years. However, success in scientific discovery tasks is limited by the accessibility of well-defined and labeled in-domain data. To tackle the low-data constraint, recent adaptions of deep learning models pretrained on millions of protein sequences have shown promise; however, the construction of such domain-specific large-scale model is computationally expensive. Here, we propose Representation Learning via Dictionary Learning (R2DL), an end-to-end representation learning framework in which we reprogram deep models for alternate-domain tasks that can perform well on protein property prediction with significantly fewer training samples. R2DL reprograms a pretrained English language model to learn the embeddings of protein sequences, by learning a sparse linear mapping between English and protein sequence vocabulary embeddings. Our model can attain better accuracy and significantly improve the data efficiency by up to $10^5$ times over the baselines set by pretrained and standard supervised methods. To this end, we reprogram an off-the-shelf pre-trained English language transformer and benchmark it on a set of protein physicochemical prediction tasks (secondary structure, stability, homology, stability) as well as on a biomedically relevant set of protein function prediction tasks (antimicrobial, toxicity, antibody affinity).
Reprogramming Language Models for Molecular Representation Learning
Jan 06, 2021


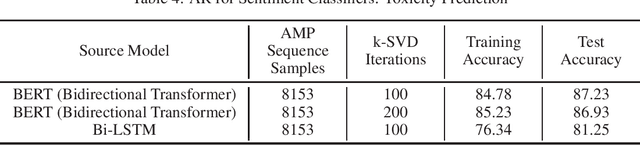
Recent advancements in transfer learning have made it a promising approach for domain adaptation via transfer of learned representations. This is especially when relevant when alternate tasks have limited samples of well-defined and labeled data, which is common in the molecule data domain. This makes transfer learning an ideal approach to solve molecular learning tasks. While Adversarial reprogramming has proven to be a successful method to repurpose neural networks for alternate tasks, most works consider source and alternate tasks within the same domain. In this work, we propose a new algorithm, Representation Reprogramming via Dictionary Learning (R2DL), for adversarially reprogramming pretrained language models for molecular learning tasks, motivated by leveraging learned representations in massive state of the art language models. The adversarial program learns a linear transformation between a dense source model input space (language data) and a sparse target model input space (e.g., chemical and biological molecule data) using a k-SVD solver to approximate a sparse representation of the encoded data, via dictionary learning. R2DL achieves the baseline established by state of the art toxicity prediction models trained on domain-specific data and outperforms the baseline in a limited training-data setting, thereby establishing avenues for domain-agnostic transfer learning for tasks with molecule data.