 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-Order Hybrid Gradient Descent: Towards A Principled Black-Box Optimization Framework
Paper and Code
Dec 21, 2020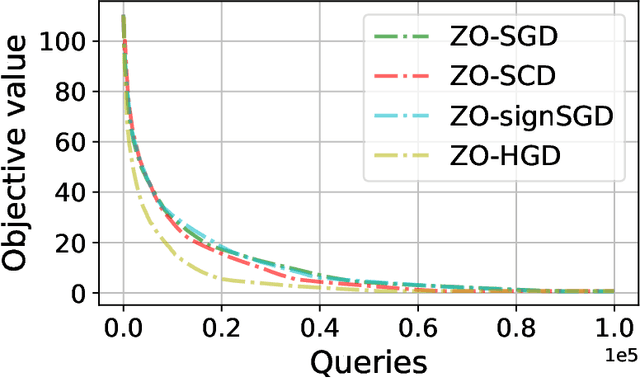
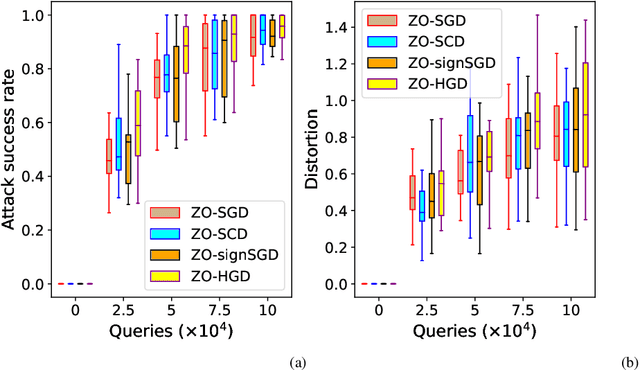
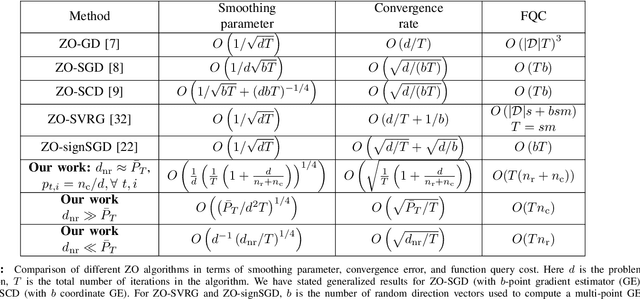

In this work, we focus on the study of stochastic zeroth-order (ZO) optimization which does not require first-order gradient information and uses only function evaluations. The problem of ZO optimization has emerged in many recent machine learning applications, where the gradient of the objective function is either unavailable or difficult to compute. In such cases, we can approximate the full gradients or stochastic gradients through function value based gradient estimates. Here, we propose a novel hybrid gradient estimator (HGE), which takes advantage of the query-efficiency of random gradient estimates as well as the variance-reduction of coordinate-wise gradient estimates. We show that with a graceful design in coordinate importance sampling, the proposed HGE-based ZO optimization method is efficient both in terms of iteration complexity as well as function query cost. We provide a thorough theoretical analysis of the convergence of our proposed method for non-convex, convex, and strongly-convex optimization. We show that the convergence rate that we derive generalizes the results for some prominent existing methods in the nonconvex case, and matches the optimal result in the convex case. We also corroborate the theory with a real-world black-box attack generation application to demonstrate the empirical advantage of our method over state-of-the-art ZO optimization approaches.