 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical visual question answering using joint self-supervised learning
Feb 25, 2023



Visual Question Answering (VQA) becomes one of the most active research problems in the medical imaging domain. A well-known VQA challenge is the intrinsic diversity between the image and text modalities, and in the medical VQA task, there is another critical problem relying on the limited size of labelled image-question-answer data. In this study we propose an encoder-decoder framework that leverages the image-text joint representation learned from large-scaled medical image-caption data and adapted to the small-sized medical VQA task. The encoder embeds across the image-text dual modalities with self-attention mechanism and is independently pre-trained on the large-scaled medical image-caption dataset by multiple self-supervised learning tasks. Then the decoder is connected to the top of the encoder and fine-tuned using the small-sized medical VQA dataset. The experiment results present that our proposed method achieves better performance comparing with the baseline and SOTA methods.
Latency Guarantee for Ubiquitous Intelligence in 6G: A Network Calculus Approach
May 06, 2022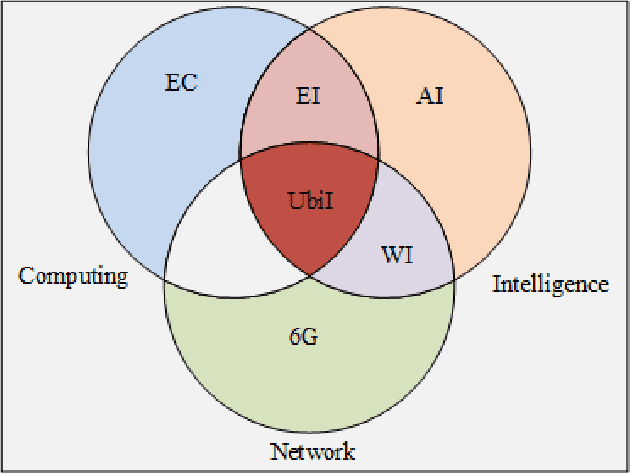
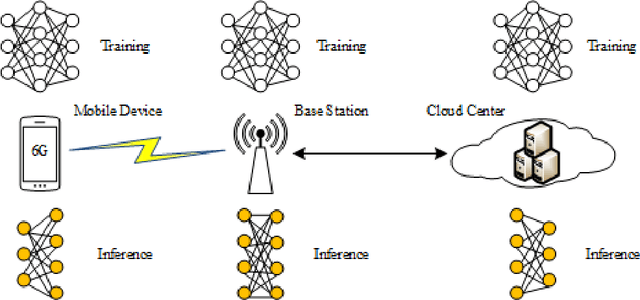
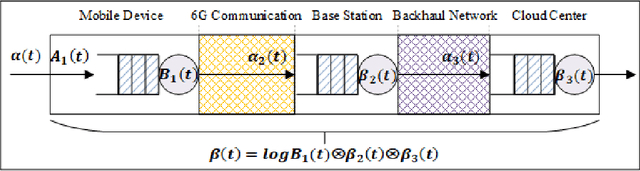
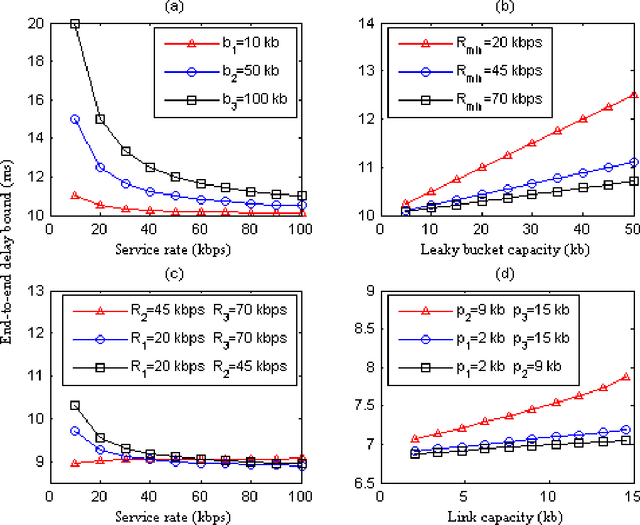
With the gradual deployment of 5G and the continuous popularization of edge intelligence (EI), the explosive growth of data on the edge of the network has promoted the rapid development of 6G and ubiquitous intelligence (UbiI). This article aims to explore a new method for modeling latency guarantees for UbiI in 6G given 6G's extremely stochastic nature in terahertz (THz) environments, THz channel tail behavior, and delay distribution tail characteristics generated by the UBiI random component, and to find the optimal solution that minimizes the end-to-end (E2E) delay of UbiI. In this article, the arrival curve and service curve of network calculus can well characterize the stochastic nature of wireless channels, the tail behavior of wireless systems and the E2E service curve of network calculus can model the tail characteristic of the delay distribution in UbiI. Specifically, we first propose demands and challenges facing 6G, edge computing (EC), edge deep learning (DL), and UbiI. Then, we propose the hierarchical architecture, the network model, and the service delay model of the UbiI system based on network calculus. In addition, two case studies demonstrate the usefulness and effectiveness of the network calculus approach in analyzing and modeling the latency guarantee for UbiI in 6G. Finally, future open research issues regarding the latency guarantee for UbiI in 6G are outlined.
Adversarial Sample Enhanced Domain Adaptation: A Case Study on Predictive Modeling with Electronic Health Records
Jan 13, 2021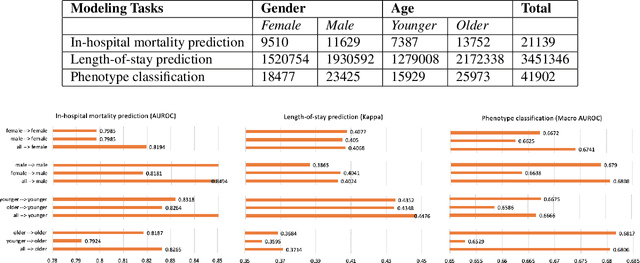
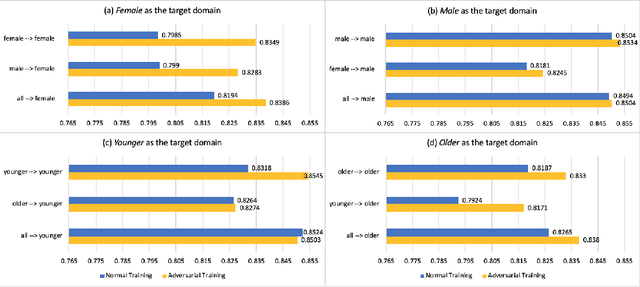
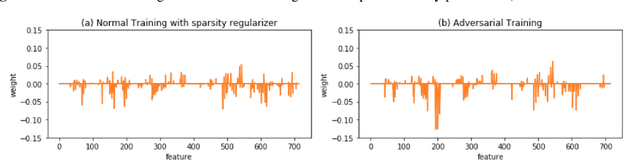
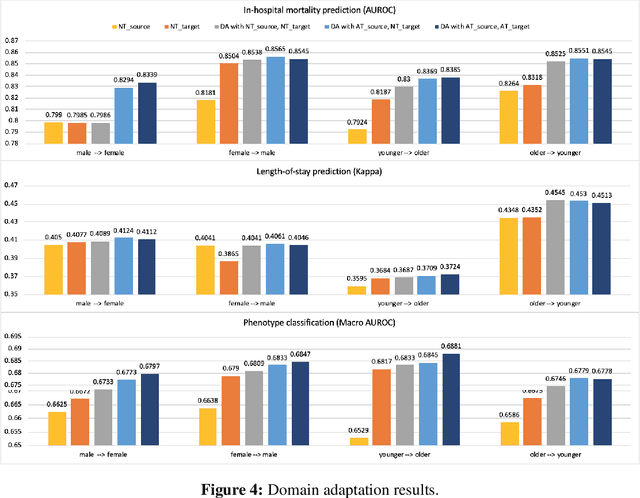
With the successful adoption of machine learning on electronic health records (EHRs), numerous computational models have been deployed to address a variety of clinical problems. However, due to the heterogeneity of EHRs, models trained on different patient groups suffer from poor generalizability. How to mitigate domain shifts between the source patient group where the model is built upon and the target one where the model will be deployed becomes a critical issue. In this paper, we propose a data augmentation method to facilitate domain adaptation, which leverages knowledge from the source patient group when training model on the target one. Specifically, adversarially generated samples are used during domain adaptation to fill the generalization gap between the two patient groups. The proposed method is evaluated by a case study on different predictive modeling tasks on MIMIC-III EHR dataset. Results confirm the effectiveness of our method and the generality on different tasks.
Dynamic Knowledge Distillation for Black-box Hypothesis Transfer Learning
Aug 07, 2020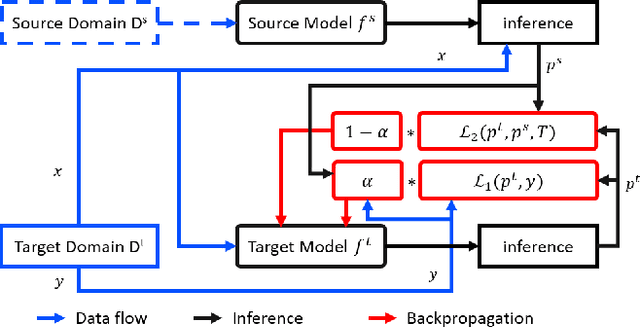
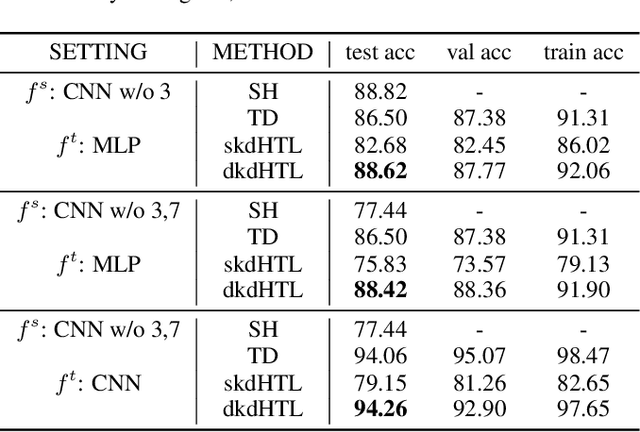
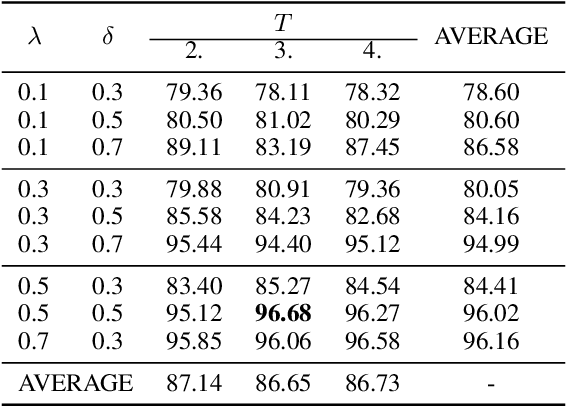

In real world applications like healthcare, it is usually difficult to build a machine learning prediction model that works universally well across different institutions. At the same time, the available model is often proprietary, i.e., neither the model parameter nor the data set used for model training is accessible. In consequence, leveraging the knowledge hidden in the available model (aka. the hypothesis) and adapting it to a local data set becomes extremely challenging. Motivated by this situation, in this paper we aim to address such a specific case within the hypothesis transfer learning framework, in which 1) the source hypothesis is a black-box model and 2) the source domain data is unavailable. In particular, we introduce a novel algorithm called dynamic knowledge distillation for hypothesis transfer learning (dkdHTL). In this method, we use knowledge distillation with instance-wise weighting mechanism to adaptively transfer the "dark" knowledge from the source hypothesis to the target domain.The weighting coefficients of the distillation loss and the standard loss are determined by the consistency between the predicted probability of the source hypothesis and the target ground-truth label.Empirical results on both transfer learning benchmark datasets and a healthcare dataset demonstrate the effectiveness of our method.
Unlocking the Power of Deep PICO Extraction: Step-wise Medical NER Identification
Apr 30, 2020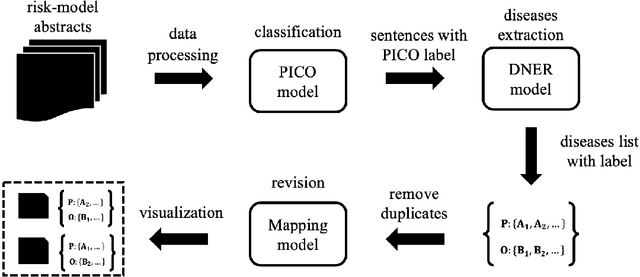



The PICO framework (Population, Intervention, Comparison, and Outcome) is usually used to formulate evidence in the medical domain. The major task of PICO extraction is to extract sentences from medical literature and classify them into each class. However, in most circumstances, there will be more than one evidences in an extracted sentence even it has been categorized to a certain class. In order to address this problem, we propose a step-wise disease Named Entity Recognition (DNER) extraction and PICO identification method. With our method, sentences in paper title and abstract are first classified into different classes of PICO, and medical entities are then identified and classified into P and O. Different kinds of deep learning frameworks are used and experimental results show that our method will achieve high performance and fine-grained extraction results comparing with conventional PICO extraction works.
Outcome-Driven Clustering of Acute Coronary Syndrome Patients using Multi-Task Neural Network with Attention
Mar 27, 2019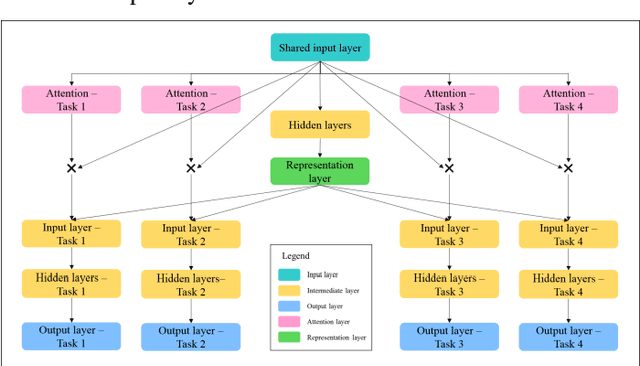
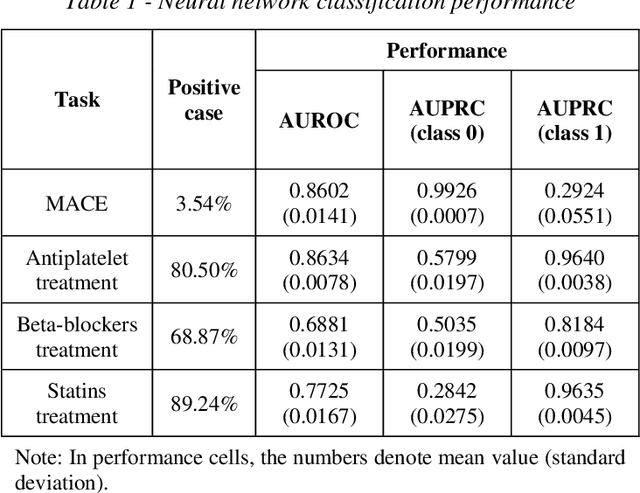
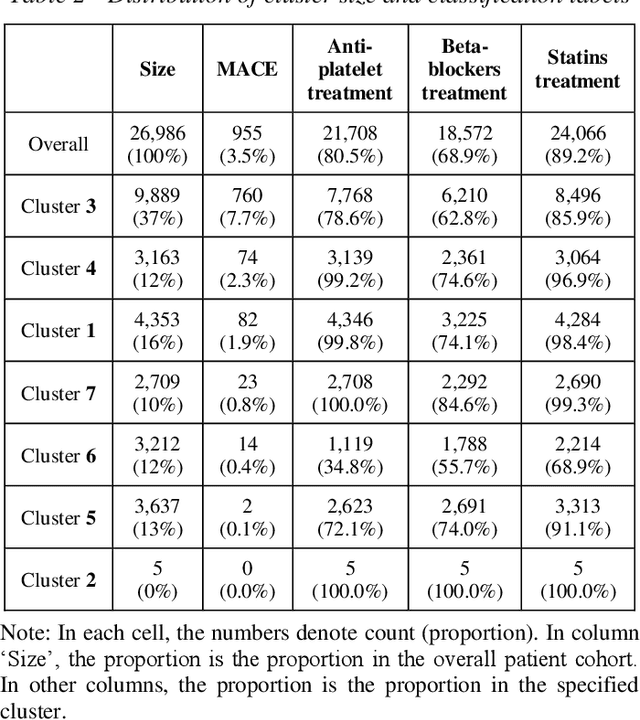
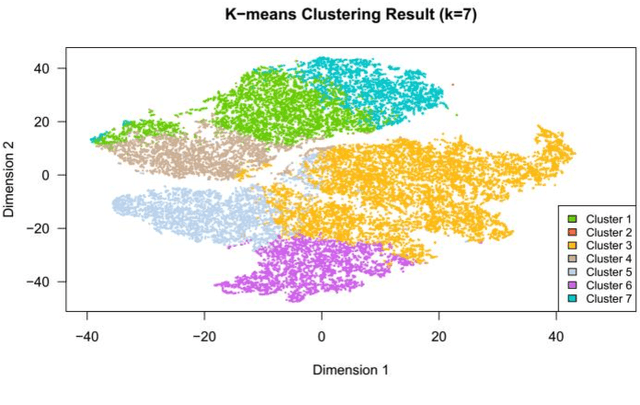
Cluster analysis aims at separating patients into phenotypically heterogenous groups and defining therapeutically homogeneous patient subclasses. It is an important approach in data-driven disease classification and subtyping. Acute coronary syndrome (ACS) is a syndrome due to sudden decrease of coronary artery blood flow, where disease classification would help to inform therapeutic strategies and provide prognostic insights. Here we conducted outcome-driven cluster analysis of ACS patients, which jointly considers treatment and patient outcome as indicators for patient state. Multi-task neural network with attention was used as a modeling framework, including learning of the patient state, cluster analysis, and feature importance profiling. Seven patient clusters were discovered. The clusters have different characteristics, as well as different risk profiles to the outcome of in-hospital major adverse cardiac events. The results demonstrate cluster analysis using outcome-driven multi-task neural network as promising for patient classification and subtyping.
Deep Diabetologist: Learning to Prescribe Hyperglycemia Medications with Hierarchical Recurrent Neural Networks
Oct 17, 2018

In healthcare, applying deep learning models to electronic health records (EHRs) has drawn considerable attention. EHR data consist of a sequence of medical visits, i.e. a multivariate time series of diagnosis, medications, physical examinations, lab tests, etc. This sequential nature makes EHR well matching the power of Recurrent Neural Network (RNN). In this paper, we propose "Deep Diabetologist" - using RNNs for EHR sequential data modelling, to provide the personalized hyperglycemia medication prediction for diabetic patients. Particularly, we develop a hierarchical RNN to capture the heterogeneous sequential information in the EHR data. Our experimental results demonstrate the improved performance, compared with a baseline classifier using logistic regression. Moreover, hierarchical RNN models outperform basic ones, providing deeper data insights for clinical decision support.
Developing Knowledge-enhanced Chronic Disease Risk Prediction Models from Regional EHR Repositories
Jul 31, 2017

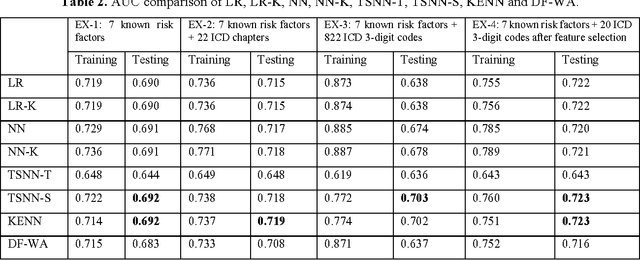
Precision medicine requires the precision disease risk prediction models. In literature, there have been a lot well-established (inter-)national risk models, but when applying them into the local population, the prediction performance becomes unsatisfactory. To address the localization issue, this paper exploits the way to develop knowledge-enhanced localized risk models. On the one hand, we tune models by learning from regional Electronic Health Record (EHR) repositories, and on the other hand, we propose knowledge injection into the EHR data learning process. For experiments, we leverage the Pooled Cohort Equations (PCE, as recommended in ACC/AHA guidelines to estimate the risk of ASCVD) to develop a localized ASCVD risk prediction model in diabetes. The experimental results show that, if directly using the PCE algorithm on our cohort, the AUC is only 0.653, while our knowledge-enhanced localized risk model can achieve higher prediction performance with AUC of 0.723 (improved by 10.7%).