 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Curriculum Learning through Value Disagreement
Jun 17, 2020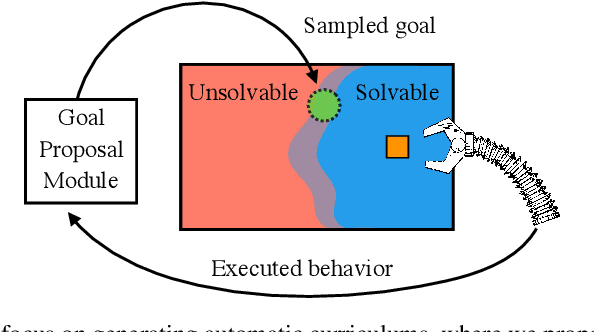
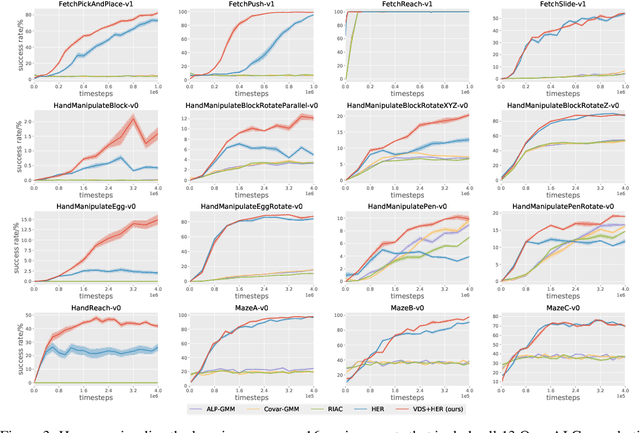
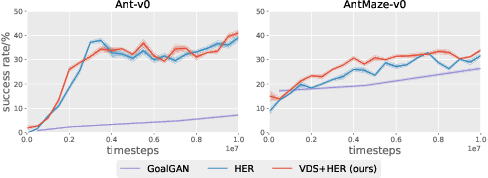
Continually solving new, unsolved tasks is the key to learning diverse behaviors. Through reinforcement learning (RL), we have made massive strides towards solving tasks that have a single goal. However, in the multi-task domain, where an agent needs to reach multiple goals, the choice of training goals can largely affect sample efficiency. When biological agents learn, there is often an organized and meaningful order to which learning happens. Inspired by this, we propose setting up an automatic curriculum for goals that the agent needs to solve. Our key insight is that if we can sample goals at the frontier of the set of goals that an agent is able to reach, it will provide a significantly stronger learning signal compared to randomly sampled goals. To operationalize this idea, we introduce a goal proposal module that prioritizes goals that maximize the epistemic uncertainty of the Q-function of the policy. This simple technique samples goals that are neither too hard nor too easy for the agent to solve, hence enabling continual improvement. We evaluate our method across 13 multi-goal robotic tasks and 5 navigation tasks, and demonstrate performance gains over current state-of-the-art methods.
Mutual Information Maximization for Robust Plannable Representations
May 16, 2020
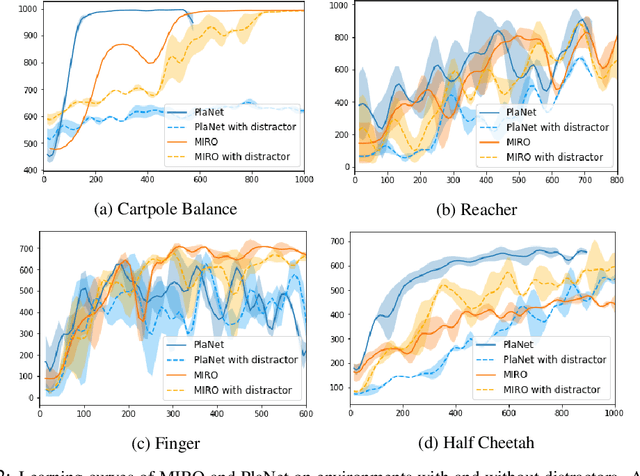
Extending the capabilities of robotics to real-world complex, unstructured environments requires the need of developing better perception systems while maintaining low sample complexity. When dealing with high-dimensional state spaces, current methods are either model-free or model-based based on reconstruction objectives. The sample inefficiency of the former constitutes a major barrier for applying them to the real-world. The later, while they present low sample complexity, they learn latent spaces that need to reconstruct every single detail of the scene. In real environments, the task typically just represents a small fraction of the scene. Reconstruction objectives suffer in such scenarios as they capture all the unnecessary components. In this work, we present MIRO, an information theoretic representational learning algorithm for model-based reinforcement learning. We design a latent space that maximizes the mutual information with the future information while being able to capture all the information needed for planning. We show that our approach is more robust than reconstruction objectives in the presence of distractors and cluttered scenes
Model-Augmented Actor-Critic: Backpropagating through Paths
May 16, 2020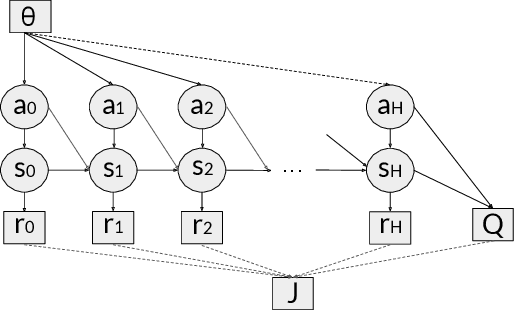

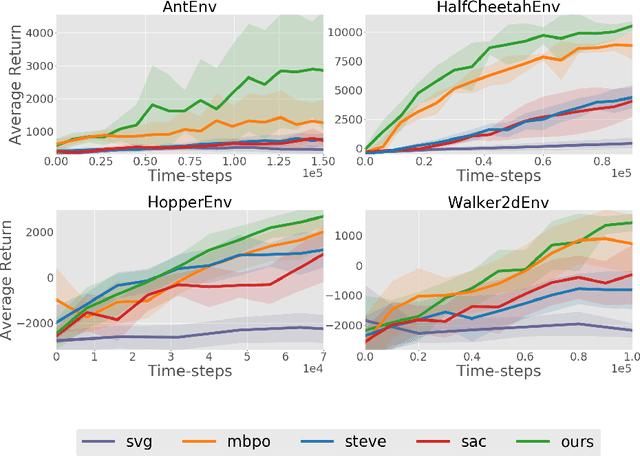

Current model-based reinforcement learning approaches use the model simply as a learned black-box simulator to augment the data for policy optimization or value function learning. In this paper, we show how to make more effective use of the model by exploiting its differentiability. We construct a policy optimization algorithm that uses the pathwise derivative of the learned model and policy across future timesteps. Instabilities of learning across many timesteps are prevented by using a terminal value function, learning the policy in an actor-critic fashion. Furthermore, we present a derivation on the monotonic improvement of our objective in terms of the gradient error in the model and value function. We show that our approach (i) is consistently more sample efficient than existing state-of-the-art model-based algorithms, (ii) matches the asymptotic performance of model-free algorithms, and (iii) scales to long horizons, a regime where typically past model-based approaches have struggled.
Planning to Explore via Self-Supervised World Models
May 12, 2020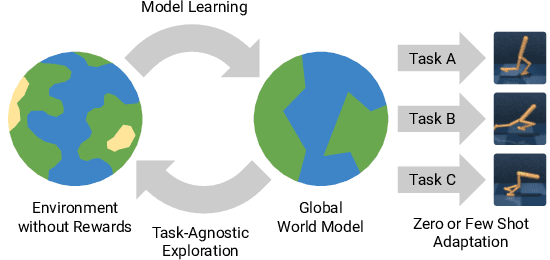
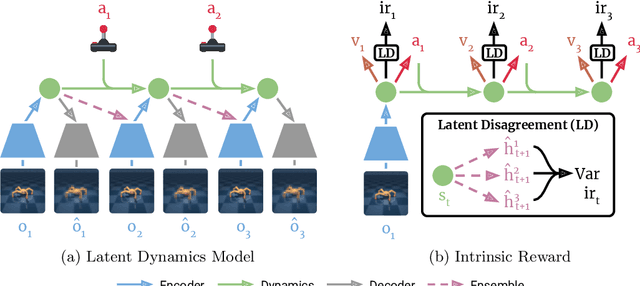
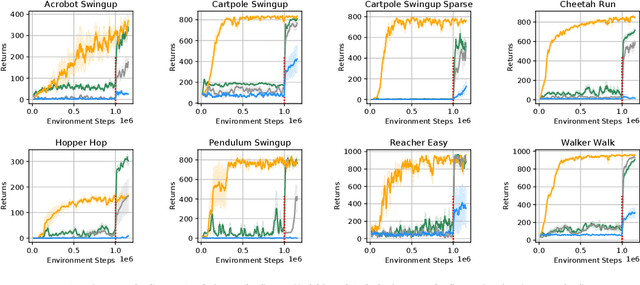
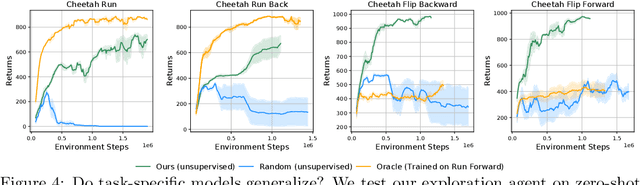
Reinforcement learning allows solving complex tasks, however, the learning tends to be task-specific and the sample efficiency remains a challenge. We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner. We evaluate on challenging control tasks from high-dimensional image inputs. Without any training supervision or task-specific interaction, Plan2Explore outperforms prior self-supervised exploration methods, and in fact, almost matches the performances oracle which has access to rewards. Videos and code at https://ramanans1.github.io/plan2explore/
Reinforcement Learning with Augmented Data
May 11, 2020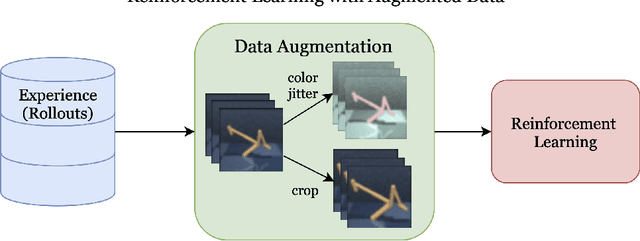
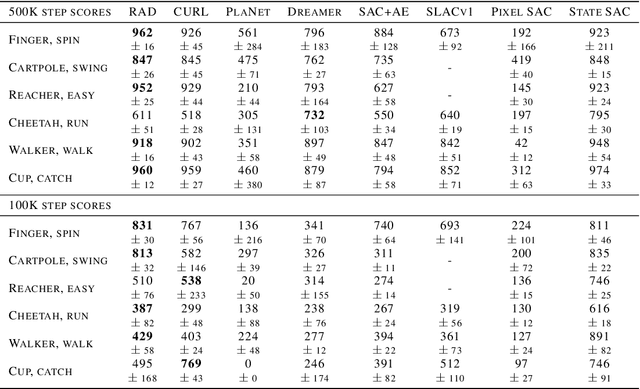

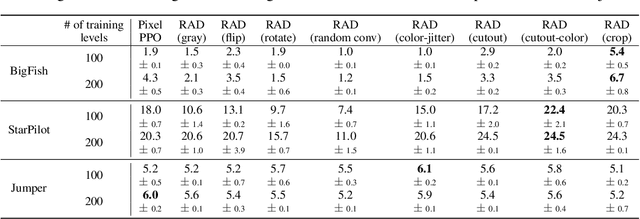
Learning from visual observations is a fundamental yet challenging problem in reinforcement learning (RL). Although algorithmic advancements combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) sample efficiency of learning and (b) generalization to new environments. To this end, we present RAD: Reinforcement Learning with Augmented Data, a simple plug-and-play module that can enhance any RL algorithm. We show that data augmentations such as random crop, color jitter, patch cutout, and random convolutions can enable simple RL algorithms to match and even outperform complex state-of-the-art methods across common benchmarks in terms of data-efficiency, generalization, and wall-clock speed. We find that data diversity alone can make agents focus on meaningful information from high-dimensional observations without any changes to the reinforcement learning method. On the DeepMind Control Suite, we show that RAD is state-of-the-art in terms of data-efficiency and performance across 15 environments. We further demonstrate that RAD can significantly improve the test-time generalization on several OpenAI ProcGen benchmarks. Finally, our customized data augmentation modules enable faster wall-clock speed compared to competing RL techniques. Our RAD module and training code are available at https://www.github.com/MishaLaskin/rad.
Plan2Vec: Unsupervised Representation Learning by Latent Plans
May 07, 2020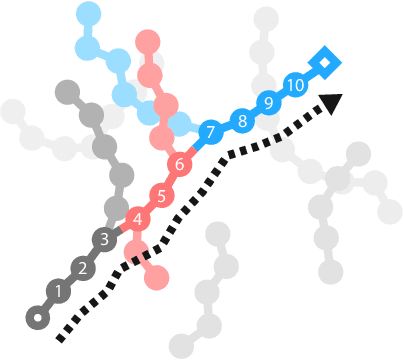
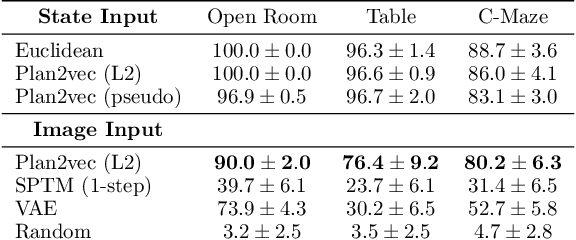

In this paper we introduce plan2vec, an unsupervised representation learning approach that is inspired by reinforcement learning. Plan2vec constructs a weighted graph on an image dataset using near-neighbor distances, and then extrapolates this local metric to a global embedding by distilling path-integral over planned path. When applied to control, plan2vec offers a way to learn goal-conditioned value estimates that are accurate over long horizons that is both compute and sample efficient. We demonstrate the effectiveness of plan2vec on one simulated and two challenging real-world image datasets. Experimental results show that plan2vec successfully amortizes the planning cost, enabling reactive planning that is linear in memory and computation complexity rather than exhaustive over the entire state space.
* code available at https://geyang.github.io/plan2vec
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Apr 28, 2020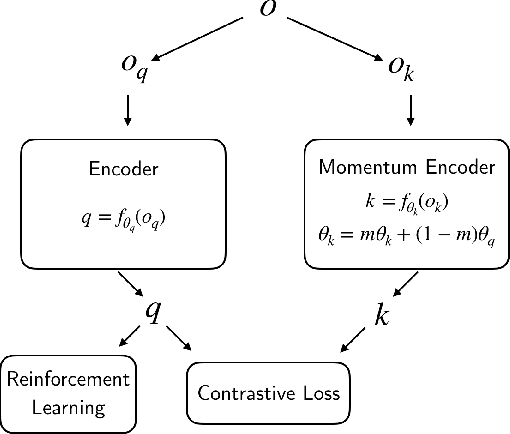
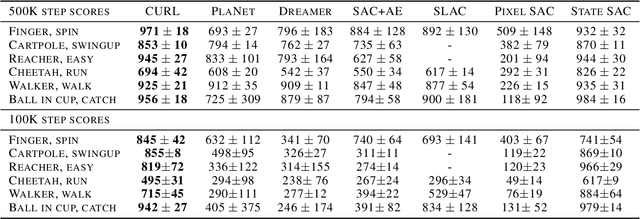
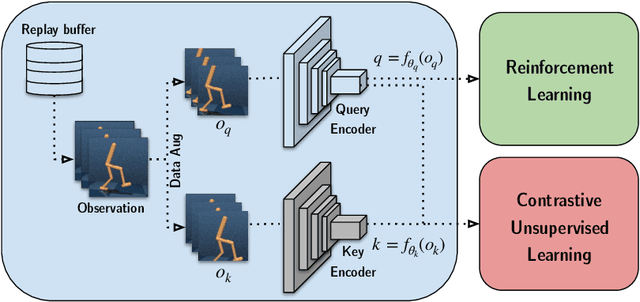
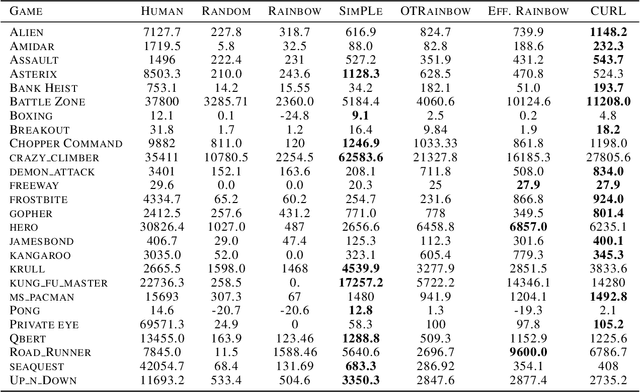
We present CURL: Contrastive Unsupervised Representations for Reinforcement Learning. CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features. CURL outperforms prior pixel-based methods, both model-based and model-free, on complex tasks in the DeepMind Control Suite and Atari Games showing 1.9x and 1.6x performance gains at the 100K environment and interaction steps benchmarks respectively. On the DeepMind Control Suite, CURL is the first image-based algorithm to nearly match the sample-efficiency and performance of methods that use state-based features.
Sparse Graphical Memory for Robust Planning
Mar 13, 2020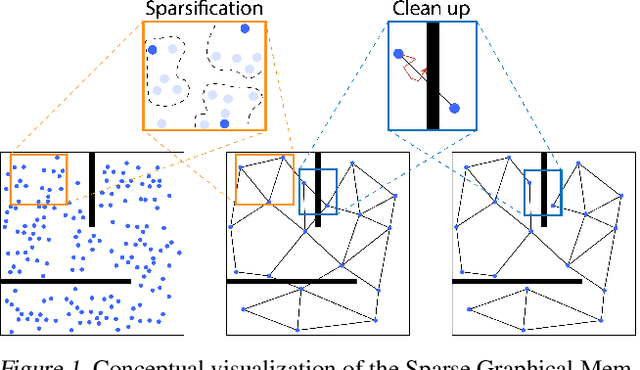
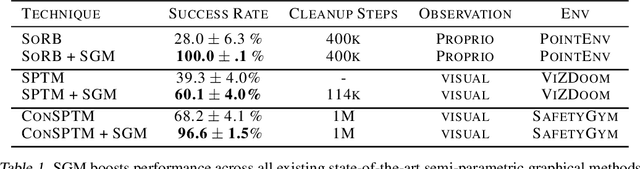
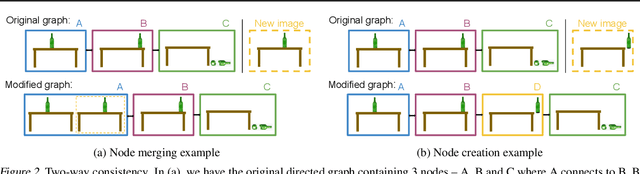
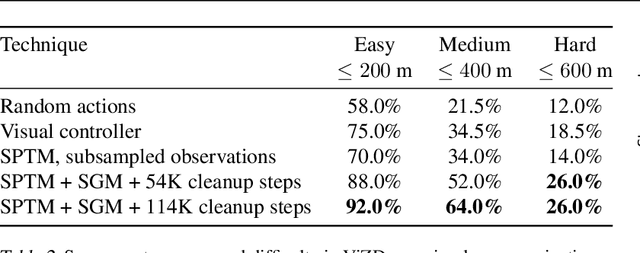
To operate effectively in the real world, artificial agents must act from raw sensory input such as images and achieve diverse goals across long time-horizons. On the one hand, recent strides in deep reinforcement and imitation learning have demonstrated impressive ability to learn goal-conditioned policies from high-dimensional image input, though only for short-horizon tasks. On the other hand, classical graphical methods like A* search are able to solve long-horizon tasks, but assume that the graph structure is abstracted away from raw sensory input and can only be constructed with task-specific priors. We wish to combine the strengths of deep learning and classical planning to solve long-horizon tasks from raw sensory input. To this end, we introduce Sparse Graphical Memory (SGM), a new data structure that stores observations and feasible transitions in a sparse memory. SGM can be combined with goal-conditioned RL or imitative agents to solve long-horizon tasks across a diverse set of domains. We show that SGM significantly outperforms current state of the art methods on long-horizon, sparse-reward visual navigation tasks. Project video and code are available at https://mishalaskin.github.io/sgm/
Learning Predictive Representations for Deformable Objects Using Contrastive Estimation
Mar 11, 2020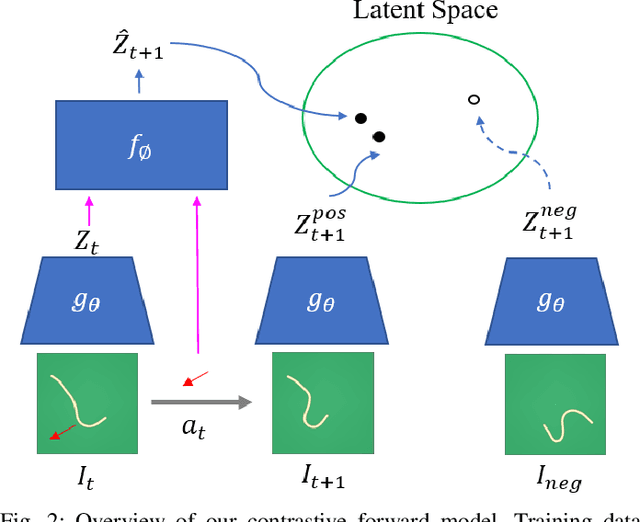

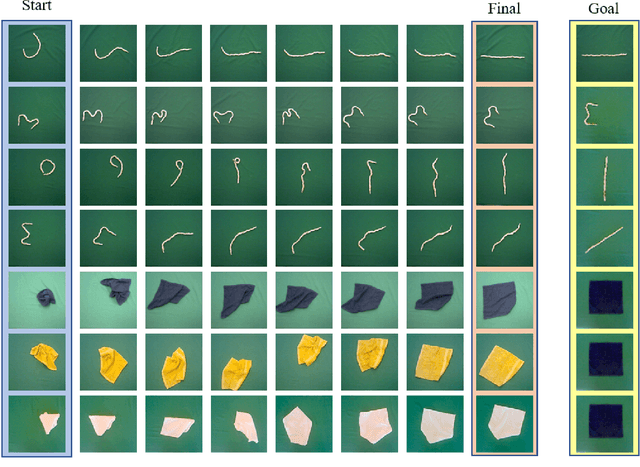

Using visual model-based learning for deformable object manipulation is challenging due to difficulties in learning plannable visual representations along with complex dynamic models. In this work, we propose a new learning framework that jointly optimizes both the visual representation model and the dynamics model using contrastive estimation. Using simulation data collected by randomly perturbing deformable objects on a table, we learn latent dynamics models for these objects in an offline fashion. Then, using the learned models, we use simple model-based planning to solve challenging deformable object manipulation tasks such as spreading ropes and cloths. Experimentally, we show substantial improvements in performance over standard model-based learning techniques across our rope and cloth manipulation suite. Finally, we transfer our visual manipulation policies trained on data purely collected in simulation to a real PR2 robot through domain randomization.
Hierarchically Decoupled Imitation for Morphological Transfer
Mar 03, 2020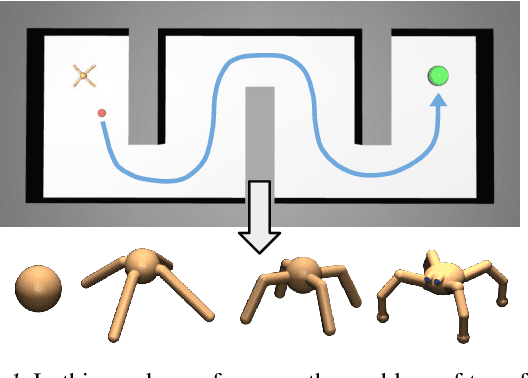

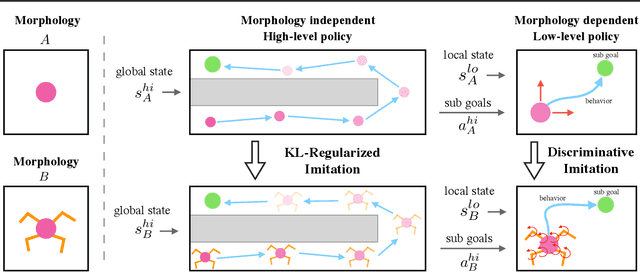

Learning long-range behaviors on complex high-dimensional agents is a fundamental problem in robot learning. For such tasks, we argue that transferring learned information from a morphologically simpler agent can massively improve the sample efficiency of a more complex one. To this end, we propose a hierarchical decoupling of policies into two parts: an independently learned low-level policy and a transferable high-level policy. To remedy poor transfer performance due to mismatch in morphologies, we contribute two key ideas. First, we show that incentivizing a complex agent's low-level to imitate a simpler agent's low-level significantly improves zero-shot high-level transfer. Second, we show that KL-regularized training of the high level stabilizes learning and prevents mode-collapse. Finally, on a suite of publicly released navigation and manipulation environments, we demonstrate the applicability of hierarchical transfer on long-range tasks across morphologies. Our code and videos can be found at https://sites.google.com/berkeley.edu/morphology-transfer.