 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating cognitive biases with attention-aware inverse planning
Oct 29, 2025



People's goal-directed behaviors are influenced by their cognitive biases, and autonomous systems that interact with people should be aware of this. For example, people's attention to objects in their environment will be biased in a way that systematically affects how they perform everyday tasks such as driving to work. Here, building on recent work in computational cognitive science, we formally articulate the attention-aware inverse planning problem, in which the goal is to estimate a person's attentional biases from their actions. We demonstrate how attention-aware inverse planning systematically differs from standard inverse reinforcement learning and how cognitive biases can be inferred from behavior. Finally, we present an approach to attention-aware inverse planning that combines deep reinforcement learning with computational cognitive modeling. We use this approach to infer the attentional strategies of RL agents in real-life driving scenarios selected from the Waymo Open Dataset, demonstrating the scalability of estimating cognitive biases with attention-aware inverse planning.
Three Dogmas of Reinforcement Learning
Jul 15, 2024


Modern reinforcement learning has been conditioned by at least three dogmas. The first is the environment spotlight, which refers to our tendency to focus on modeling environments rather than agents. The second is our treatment of learning as finding the solution to a task, rather than adaptation. The third is the reward hypothesis, which states that all goals and purposes can be well thought of as maximization of a reward signal. These three dogmas shape much of what we think of as the science of reinforcement learning. While each of the dogmas have played an important role in developing the field, it is time we bring them to the surface and reflect on whether they belong as basic ingredients of our scientific paradigm. In order to realize the potential of reinforcement learning as a canonical frame for researching intelligent agents, we suggest that it is time we shed dogmas one and two entirely, and embrace a nuanced approach to the third.
Exploring the hierarchical structure of human plans via program generation
Nov 30, 2023Human behavior is inherently hierarchical, resulting from the decomposition of a task into subtasks or an abstract action into concrete actions. However, behavior is typically measured as a sequence of actions, which makes it difficult to infer its hierarchical structure. In this paper, we explore how people form hierarchically-structured plans, using an experimental paradigm that makes hierarchical representations observable: participants create programs that produce sequences of actions in a language with explicit hierarchical structure. This task lets us test two well-established principles of human behavior: utility maximization (i.e. using fewer actions) and minimum description length (MDL; i.e. having a shorter program). We find that humans are sensitive to both metrics, but that both accounts fail to predict a qualitative feature of human-created programs, namely that people prefer programs with reuse over and above the predictions of MDL. We formalize this preference for reuse by extending the MDL account into a generative model over programs, modeling hierarchy choice as the induction of a grammar over actions. Our account can explain the preference for reuse and provides the best prediction of human behavior, going beyond simple accounts of compressibility to highlight a principle that guides hierarchical planning.
Structurally guided task decomposition in spatial navigation tasks
Oct 03, 2023

How are people able to plan so efficiently despite limited cognitive resources? We aimed to answer this question by extending an existing model of human task decomposition that can explain a wide range of simple planning problems by adding structure information to the task to facilitate planning in more complex tasks. The extended model was then applied to a more complex planning domain of spatial navigation. Our results suggest that our framework can correctly predict the navigation strategies of the majority of the participants in an online experiment.
Bayesian Reinforcement Learning with Limited Cognitive Load
May 05, 2023All biological and artificial agents must learn and make decisions given limits on their ability to process information. As such, a general theory of adaptive behavior should be able to account for the complex interactions between an agent's learning history, decisions, and capacity constraints. Recent work in computer science has begun to clarify the principles that shape these dynamics by bridging ideas from reinforcement learning, Bayesian decision-making, and rate-distortion theory. This body of work provides an account of capacity-limited Bayesian reinforcement learning, a unifying normative framework for modeling the effect of processing constraints on learning and action selection. Here, we provide an accessible review of recent algorithms and theoretical results in this setting, paying special attention to how these ideas can be applied to studying questions in the cognitive and behavioral sciences.
Humans decompose tasks by trading off utility and computational cost
Nov 07, 2022



Human behavior emerges from planning over elaborate decompositions of tasks into goals, subgoals, and low-level actions. How are these decompositions created and used? Here, we propose and evaluate a normative framework for task decomposition based on the simple idea that people decompose tasks to reduce the overall cost of planning while maintaining task performance. Analyzing 11,117 distinct graph-structured planning tasks, we find that our framework justifies several existing heuristics for task decomposition and makes predictions that can be distinguished from two alternative normative accounts. We report a behavioral study of task decomposition ($N=806$) that uses 30 randomly sampled graphs, a larger and more diverse set than that of any previous behavioral study on this topic. We find that human responses are more consistent with our framework for task decomposition than alternative normative accounts and are most consistent with a heuristic -- betweenness centrality -- that is justified by our approach. Taken together, our results provide new theoretical insight into the computational principles underlying the intelligent structuring of goal-directed behavior.
On Rate-Distortion Theory in Capacity-Limited Cognition & Reinforcement Learning
Oct 30, 2022Throughout the cognitive-science literature, there is widespread agreement that decision-making agents operating in the real world do so under limited information-processing capabilities and without access to unbounded cognitive or computational resources. Prior work has drawn inspiration from this fact and leveraged an information-theoretic model of such behaviors or policies as communication channels operating under a bounded rate constraint. Meanwhile, a parallel line of work also capitalizes on the same principles from rate-distortion theory to formalize capacity-limited decision making through the notion of a learning target, which facilitates Bayesian regret bounds for provably-efficient learning algorithms. In this paper, we aim to elucidate this latter perspective by presenting a brief survey of these information-theoretic models of capacity-limited decision making in biological and artificial agents.
Linguistic communication as (inverse) reward design
Apr 11, 2022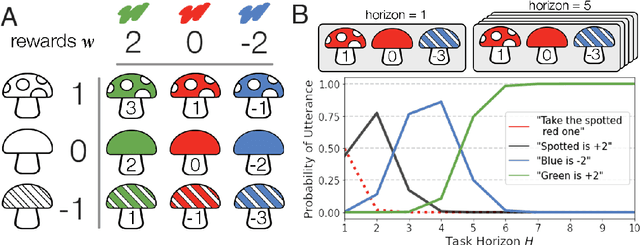
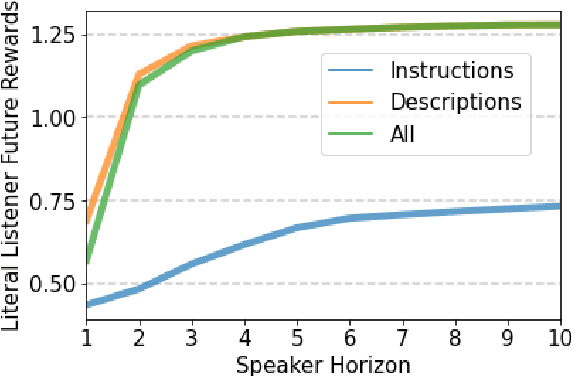
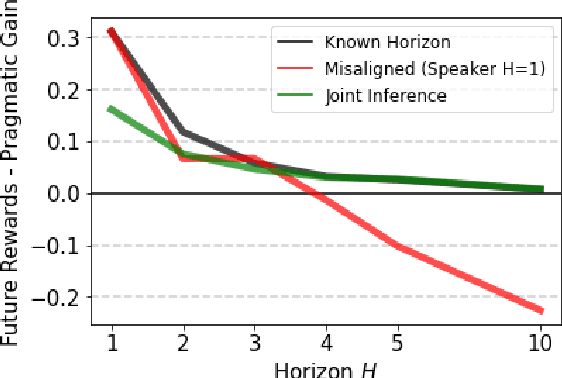
Natural language is an intuitive and expressive way to communicate reward information to autonomous agents. It encompasses everything from concrete instructions to abstract descriptions of the world. Despite this, natural language is often challenging to learn from: it is difficult for machine learning methods to make appropriate inferences from such a wide range of input. This paper proposes a generalization of reward design as a unifying principle to ground linguistic communication: speakers choose utterances to maximize expected rewards from the listener's future behaviors. We first extend reward design to incorporate reasoning about unknown future states in a linear bandit setting. We then define a speaker model which chooses utterances according to this objective. Simulations show that short-horizon speakers (reasoning primarily about a single, known state) tend to use instructions, while long-horizon speakers (reasoning primarily about unknown, future states) tend to describe the reward function. We then define a pragmatic listener which performs inverse reward design by jointly inferring the speaker's latent horizon and rewards. Our findings suggest that this extension of reward design to linguistic communication, including the notion of a latent speaker horizon, is a promising direction for achieving more robust alignment outcomes from natural language supervision.
On the Expressivity of Markov Reward
Nov 01, 2021


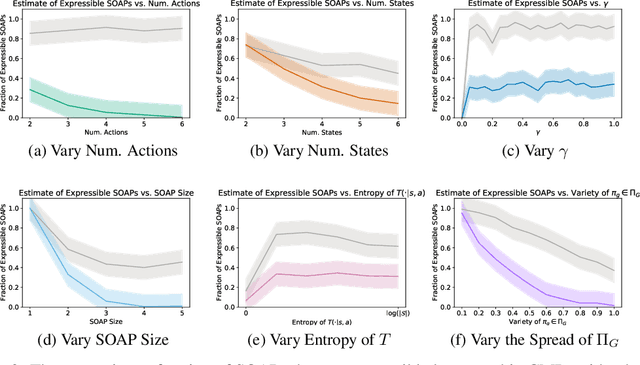
Reward is the driving force for reinforcement-learning agents. This paper is dedicated to understanding the expressivity of reward as a way to capture tasks that we would want an agent to perform. We frame this study around three new abstract notions of "task" that might be desirable: (1) a set of acceptable behaviors, (2) a partial ordering over behaviors, or (3) a partial ordering over trajectories. Our main results prove that while reward can express many of these tasks, there exist instances of each task type that no Markov reward function can capture. We then provide a set of polynomial-time algorithms that construct a Markov reward function that allows an agent to optimize tasks of each of these three types, and correctly determine when no such reward function exists. We conclude with an empirical study that corroborates and illustrates our theoretical findings.
Cognitive science as a source of forward and inverse models of human decisions for robotics and control
Sep 01, 2021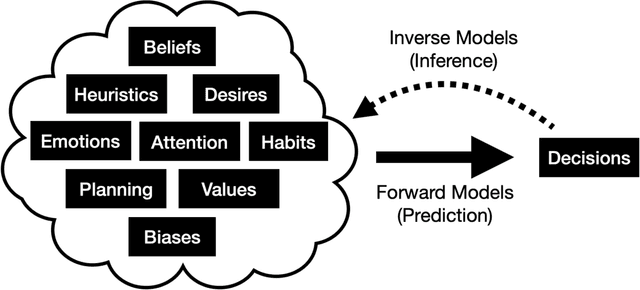
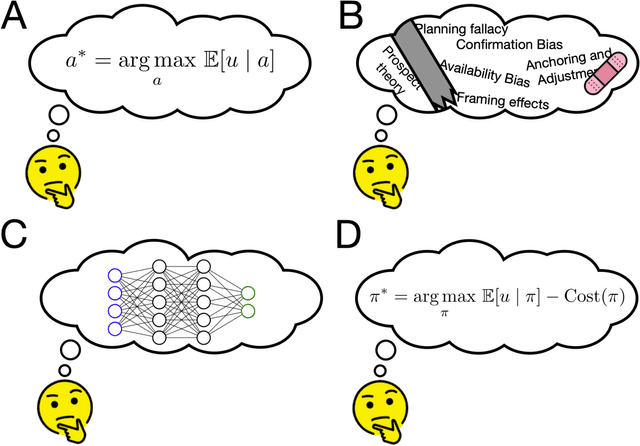
Those designing autonomous systems that interact with humans will invariably face questions about how humans think and make decisions. Fortunately, computational cognitive science offers insight into human decision-making using tools that will be familiar to those with backgrounds in optimization and control (e.g., probability theory, statistical machine learning, and reinforcement learning). Here, we review some of this work, focusing on how cognitive science can provide forward models of human decision-making and inverse models of how humans think about others' decision-making. We highlight relevant recent developments, including approaches that synthesize blackbox and theory-driven modeling, accounts that recast heuristics and biases as forms of bounded optimality, and models that characterize human theory of mind and communication in decision-theoretic terms. In doing so, we aim to provide readers with a glimpse of the range of frameworks, methodologies, and actionable insights that lie at the intersection of cognitive science and control research.