 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Reinforcement Learning Policies through Counterfactual Trajectories
Jan 29, 2022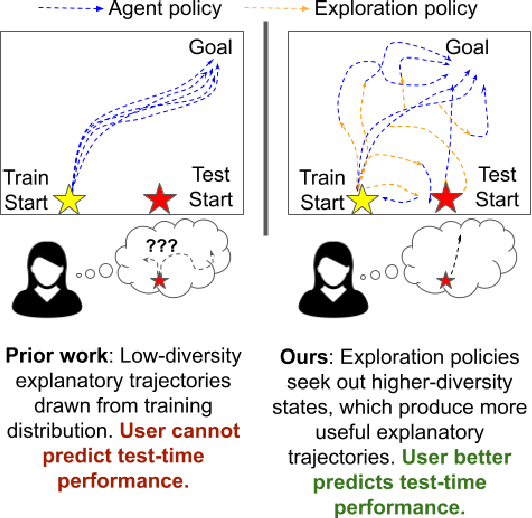
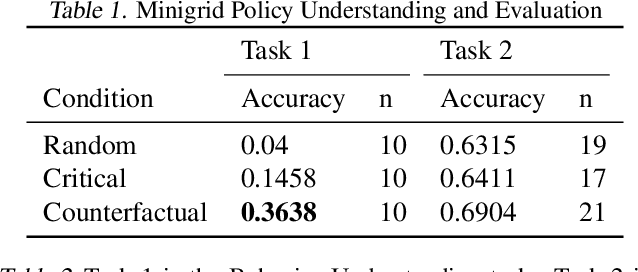
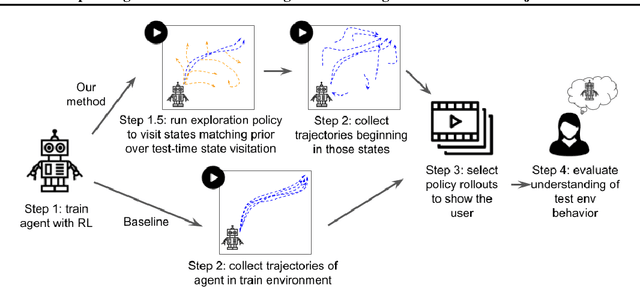
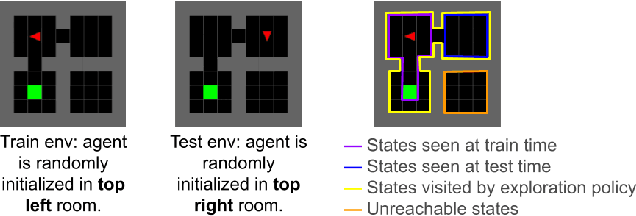
In order for humans to confidently decide where to employ RL agents for real-world tasks, a human developer must validate that the agent will perform well at test-time. Some policy interpretability methods facilitate this by capturing the policy's decision making in a set of agent rollouts. However, even the most informative trajectories of training time behavior may give little insight into the agent's behavior out of distribution. In contrast, our method conveys how the agent performs under distribution shifts by showing the agent's behavior across a wider trajectory distribution. We generate these trajectories by guiding the agent to more diverse unseen states and showing the agent's behavior there. In a user study, we demonstrate that our method enables users to score better than baseline methods on one of two agent validation tasks.
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
Jan 18, 2022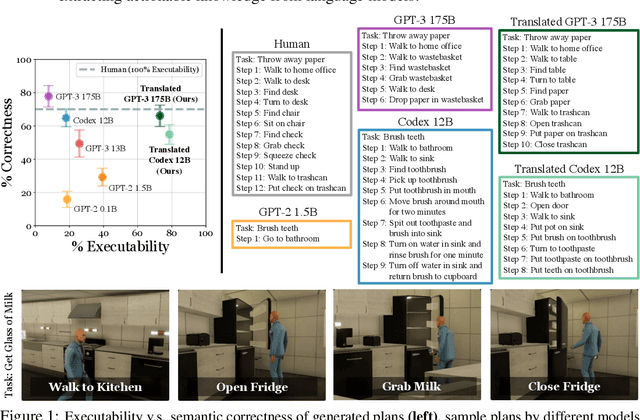
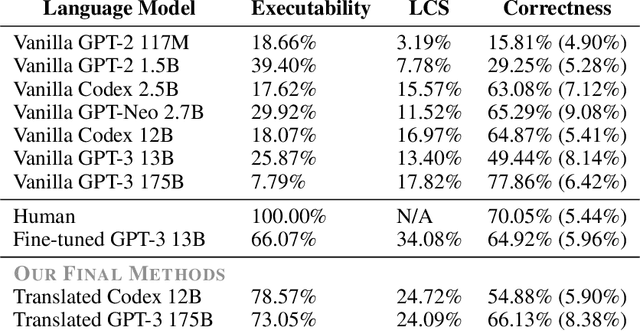
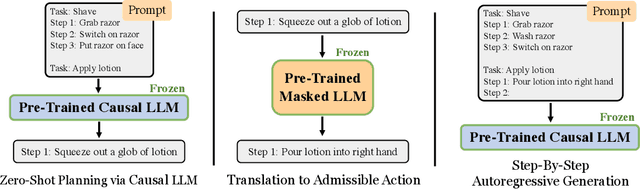
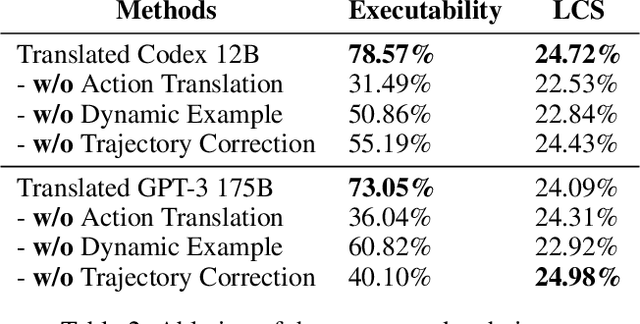
Can world knowledge learned by large language models (LLMs) be used to act in interactive environments? In this paper, we investigate the possibility of grounding high-level tasks, expressed in natural language (e.g. "make breakfast"), to a chosen set of actionable steps (e.g. "open fridge"). While prior work focused on learning from explicit step-by-step examples of how to act, we surprisingly find that if pre-trained LMs are large enough and prompted appropriately, they can effectively decompose high-level tasks into low-level plans without any further training. However, the plans produced naively by LLMs often cannot map precisely to admissible actions. We propose a procedure that conditions on existing demonstrations and semantically translates the plans to admissible actions. Our evaluation in the recent VirtualHome environment shows that the resulting method substantially improves executability over the LLM baseline. The conducted human evaluation reveals a trade-off between executability and correctness but shows a promising sign towards extracting actionable knowledge from language models. Website at https://huangwl18.github.io/language-planner
Target Entropy Annealing for Discrete Soft Actor-Critic
Dec 06, 2021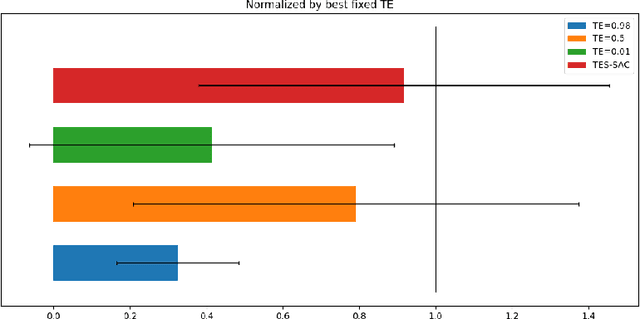
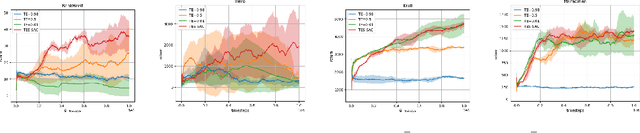
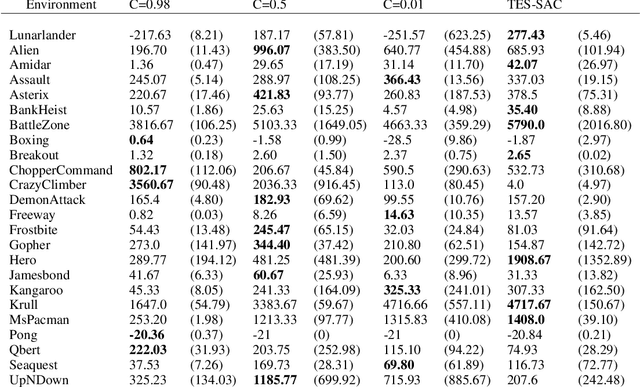
Soft Actor-Critic (SAC) is considered the state-of-the-art algorithm in continuous action space settings. It uses the maximum entropy framework for efficiency and stability, and applies a heuristic temperature Lagrange term to tune the temperature $\alpha$, which determines how "soft" the policy should be. It is counter-intuitive that empirical evidence shows SAC does not perform well in discrete domains. In this paper we investigate the possible explanations for this phenomenon and propose Target Entropy Scheduled SAC (TES-SAC), an annealing method for the target entropy parameter applied on SAC. Target entropy is a constant in the temperature Lagrange term and represents the target policy entropy in discrete SAC. We compare our method on Atari 2600 games with different constant target entropy SAC, and analyze on how our scheduling affects SAC.
Zero-Shot Text-Guided Object Generation with Dream Fields
Dec 02, 2021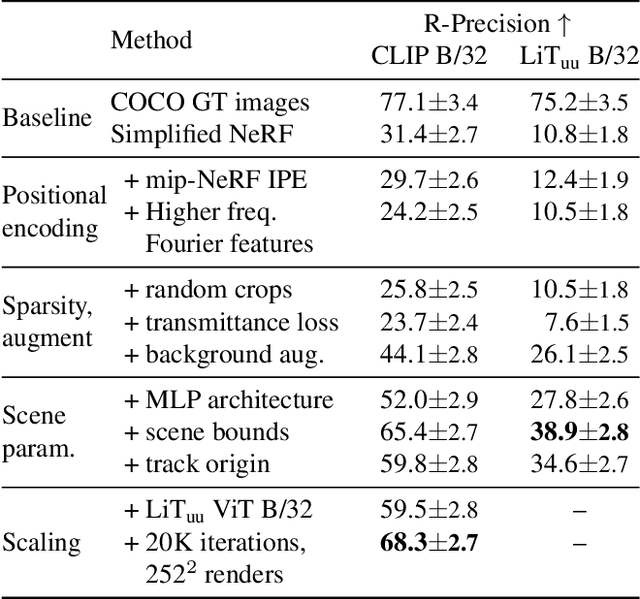

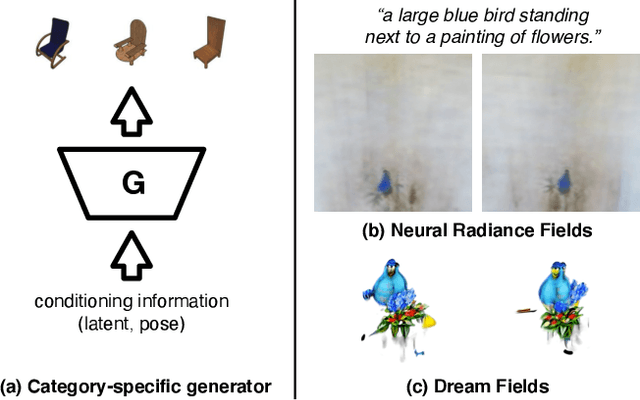
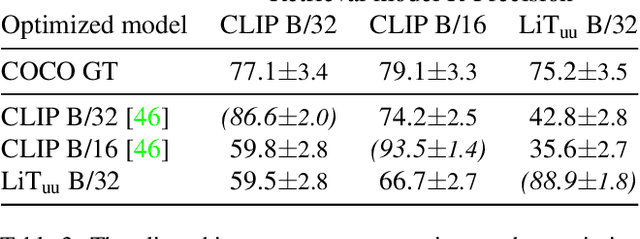
We combine neural rendering with multi-modal image and text representations to synthesize diverse 3D objects solely from natural language descriptions. Our method, Dream Fields, can generate the geometry and color of a wide range of objects without 3D supervision. Due to the scarcity of diverse, captioned 3D data, prior methods only generate objects from a handful of categories, such as ShapeNet. Instead, we guide generation with image-text models pre-trained on large datasets of captioned images from the web. Our method optimizes a Neural Radiance Field from many camera views so that rendered images score highly with a target caption according to a pre-trained CLIP model. To improve fidelity and visual quality, we introduce simple geometric priors, including sparsity-inducing transmittance regularization, scene bounds, and new MLP architectures. In experiments, Dream Fields produce realistic, multi-view consistent object geometry and color from a variety of natural language captions.
Hindsight Task Relabelling: Experience Replay for Sparse Reward Meta-RL
Dec 02, 2021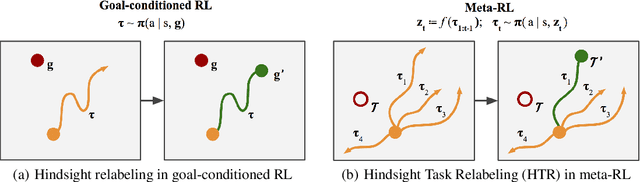

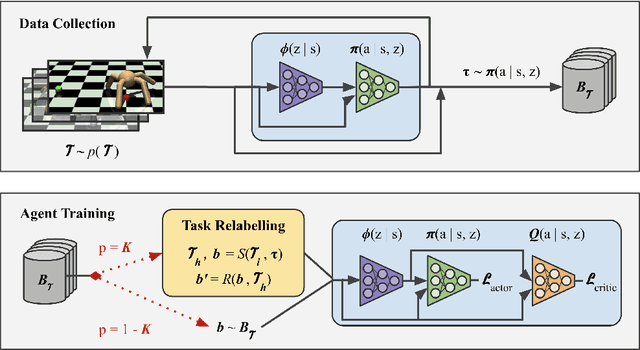
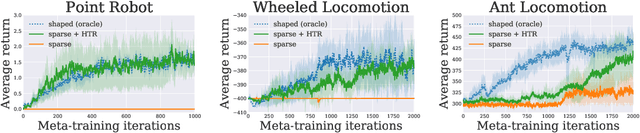
Meta-reinforcement learning (meta-RL) has proven to be a successful framework for leveraging experience from prior tasks to rapidly learn new related tasks, however, current meta-RL approaches struggle to learn in sparse reward environments. Although existing meta-RL algorithms can learn strategies for adapting to new sparse reward tasks, the actual adaptation strategies are learned using hand-shaped reward functions, or require simple environments where random exploration is sufficient to encounter sparse reward. In this paper, we present a formulation of hindsight relabeling for meta-RL, which relabels experience during meta-training to enable learning to learn entirely using sparse reward. We demonstrate the effectiveness of our approach on a suite of challenging sparse reward goal-reaching environments that previously required dense reward during meta-training to solve. Our approach solves these environments using the true sparse reward function, with performance comparable to training with a proxy dense reward function.
Count-Based Temperature Scheduling for Maximum Entropy Reinforcement Learning
Nov 28, 2021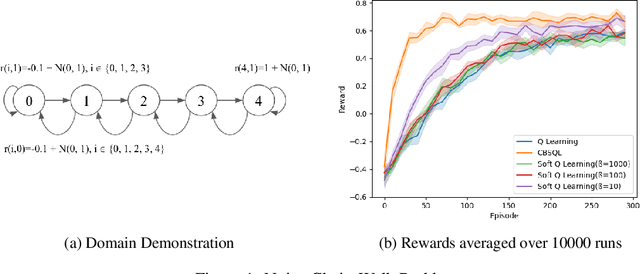

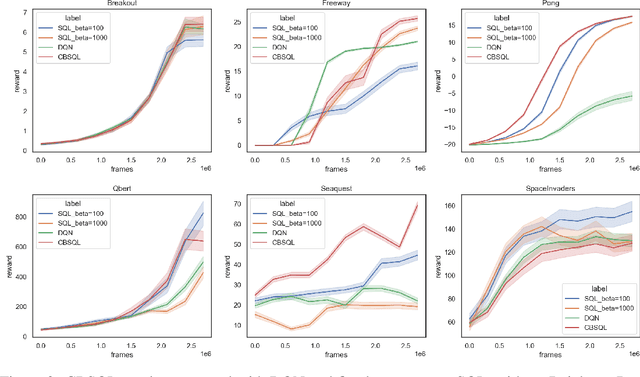
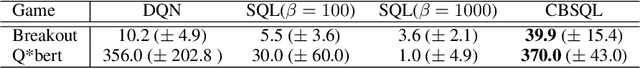
Maximum Entropy Reinforcement Learning (MaxEnt RL) algorithms such as Soft Q-Learning (SQL) and Soft Actor-Critic trade off reward and policy entropy, which has the potential to improve training stability and robustness. Most MaxEnt RL methods, however, use a constant tradeoff coefficient (temperature), contrary to the intuition that the temperature should be high early in training to avoid overfitting to noisy value estimates and decrease later in training as we increasingly trust high value estimates to truly lead to good rewards. Moreover, our confidence in value estimates is state-dependent, increasing every time we use more evidence to update an estimate. In this paper, we present a simple state-based temperature scheduling approach, and instantiate it for SQL as Count-Based Soft Q-Learning (CBSQL). We evaluate our approach on a toy domain as well as in several Atari 2600 domains and show promising results.
Generalization in Dexterous Manipulation via Geometry-Aware Multi-Task Learning
Nov 04, 2021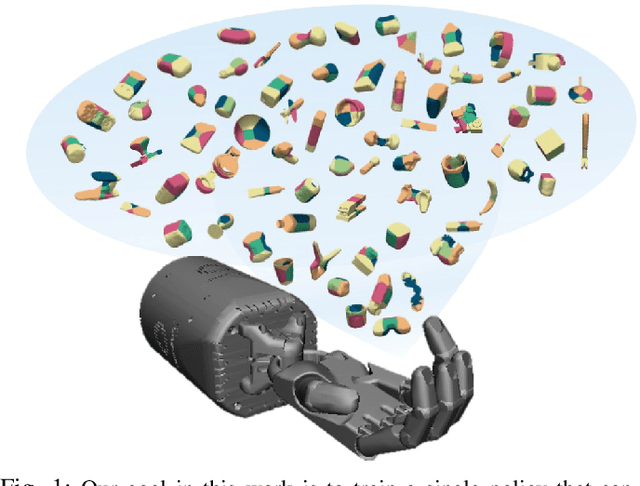
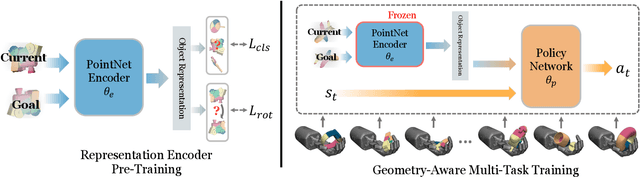
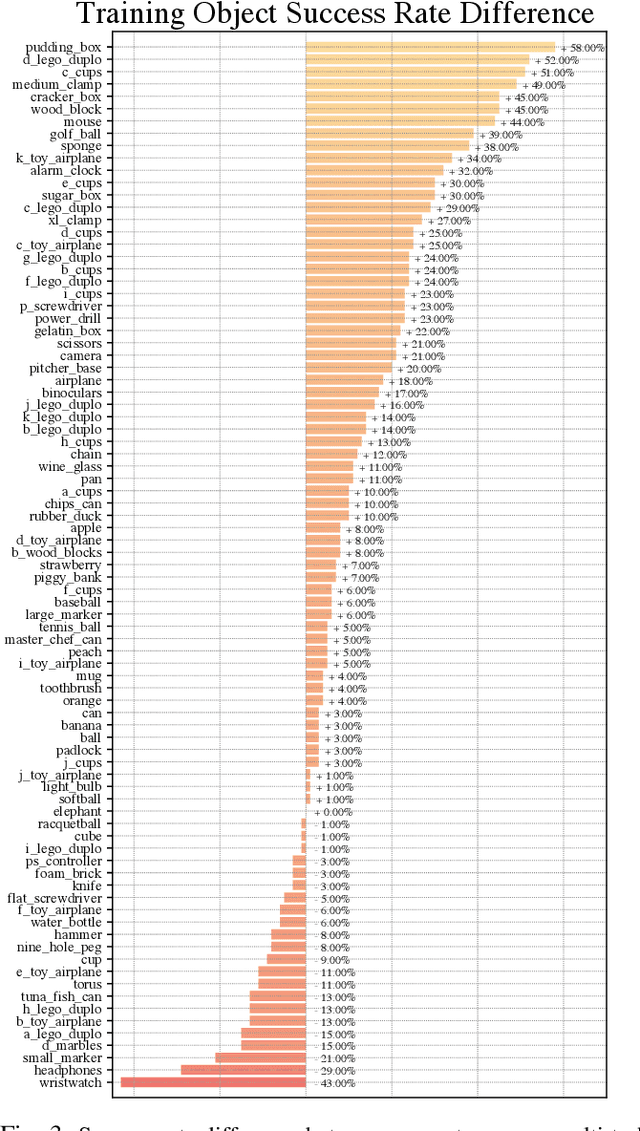
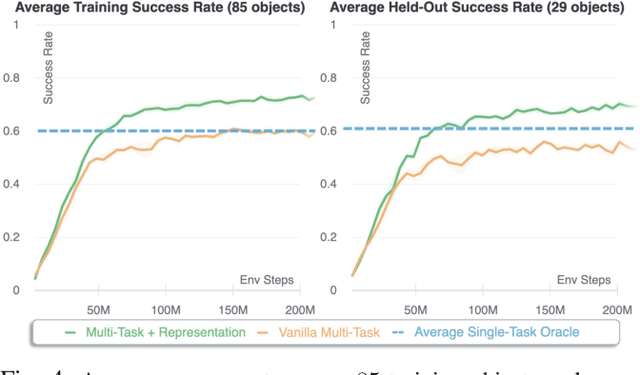
Dexterous manipulation of arbitrary objects, a fundamental daily task for humans, has been a grand challenge for autonomous robotic systems. Although data-driven approaches using reinforcement learning can develop specialist policies that discover behaviors to control a single object, they often exhibit poor generalization to unseen ones. In this work, we show that policies learned by existing reinforcement learning algorithms can in fact be generalist when combined with multi-task learning and a well-chosen object representation. We show that a single generalist policy can perform in-hand manipulation of over 100 geometrically-diverse real-world objects and generalize to new objects with unseen shape or size. Interestingly, we find that multi-task learning with object point cloud representations not only generalizes better but even outperforms the single-object specialist policies on both training as well as held-out test objects. Video results at https://huangwl18.github.io/geometry-dex
B-Pref: Benchmarking Preference-Based Reinforcement Learning
Nov 04, 2021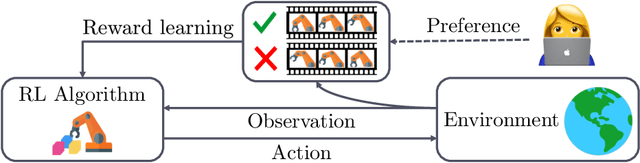
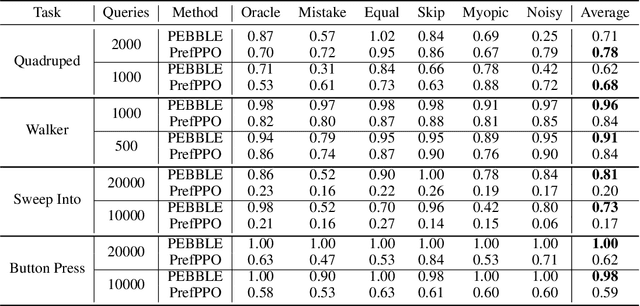
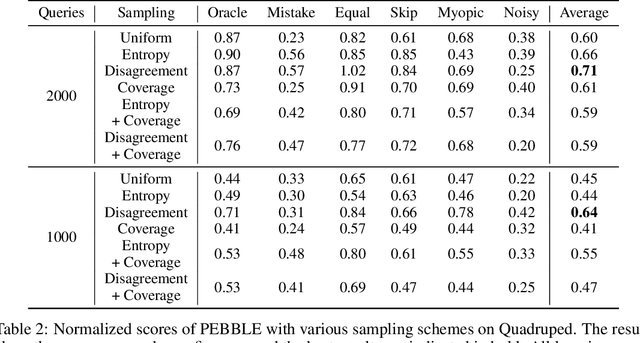
Reinforcement learning (RL) requires access to a reward function that incentivizes the right behavior, but these are notoriously hard to specify for complex tasks. Preference-based RL provides an alternative: learning policies using a teacher's preferences without pre-defined rewards, thus overcoming concerns associated with reward engineering. However, it is difficult to quantify the progress in preference-based RL due to the lack of a commonly adopted benchmark. In this paper, we introduce B-Pref: a benchmark specially designed for preference-based RL. A key challenge with such a benchmark is providing the ability to evaluate candidate algorithms quickly, which makes relying on real human input for evaluation prohibitive. At the same time, simulating human input as giving perfect preferences for the ground truth reward function is unrealistic. B-Pref alleviates this by simulating teachers with a wide array of irrationalities, and proposes metrics not solely for performance but also for robustness to these potential irrationalities. We showcase the utility of B-Pref by using it to analyze algorithmic design choices, such as selecting informative queries, for state-of-the-art preference-based RL algorithms. We hope that B-Pref can serve as a common starting point to study preference-based RL more systematically. Source code is available at https://github.com/rll-research/B-Pref.
Mastering Atari Games with Limited Data
Oct 30, 2021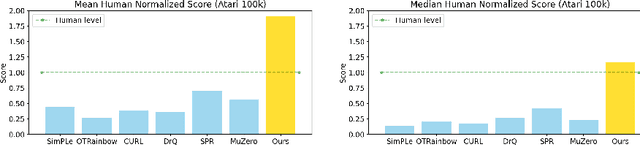
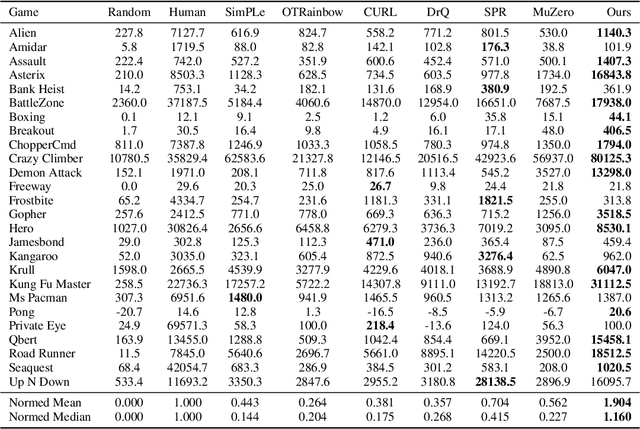
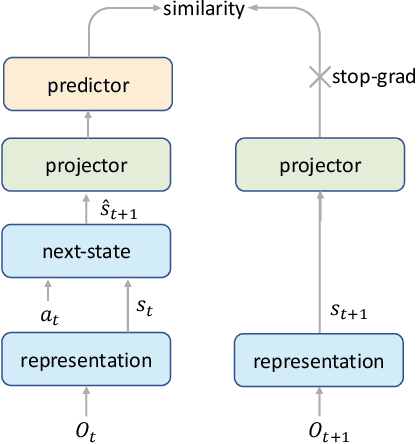

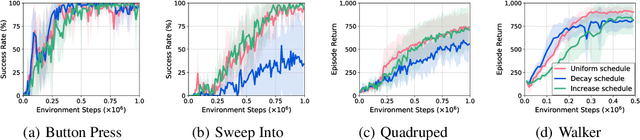
Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal. We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data. EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at https://github.com/YeWR/EfficientZero. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
URLB: Unsupervised Reinforcement Learning Benchmark
Oct 28, 2021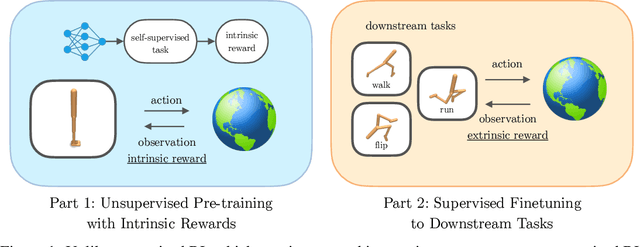
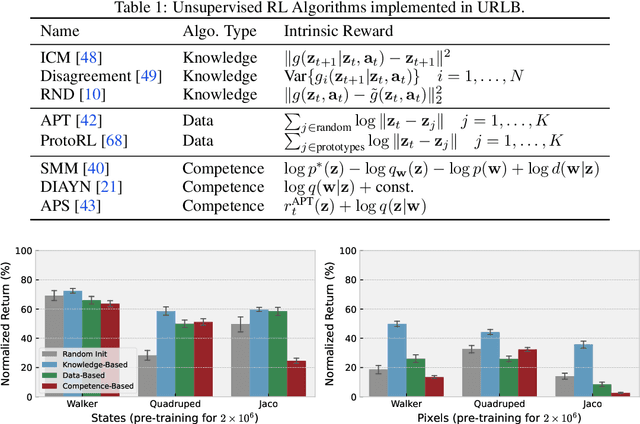
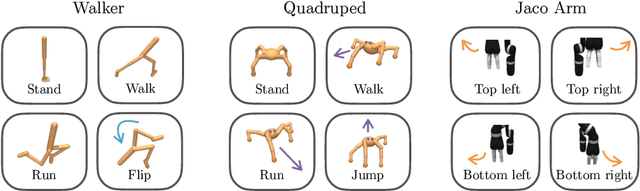

Deep Reinforcement Learning (RL) has emerged as a powerful paradigm to solve a range of complex yet specific control tasks. Yet training generalist agents that can quickly adapt to new tasks remains an outstanding challenge. Recent advances in unsupervised RL have shown that pre-training RL agents with self-supervised intrinsic rewards can result in efficient adaptation. However, these algorithms have been hard to compare and develop due to the lack of a unified benchmark. To this end, we introduce the Unsupervised Reinforcement Learning Benchmark (URLB). URLB consists of two phases: reward-free pre-training and downstream task adaptation with extrinsic rewards. Building on the DeepMind Control Suite, we provide twelve continuous control tasks from three domains for evaluation and open-source code for eight leading unsupervised RL methods. We find that the implemented baselines make progress but are not able to solve URLB and propose directions for future research.