 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting Transformer for 3D Human Pose Estimation in Video
Apr 16, 2021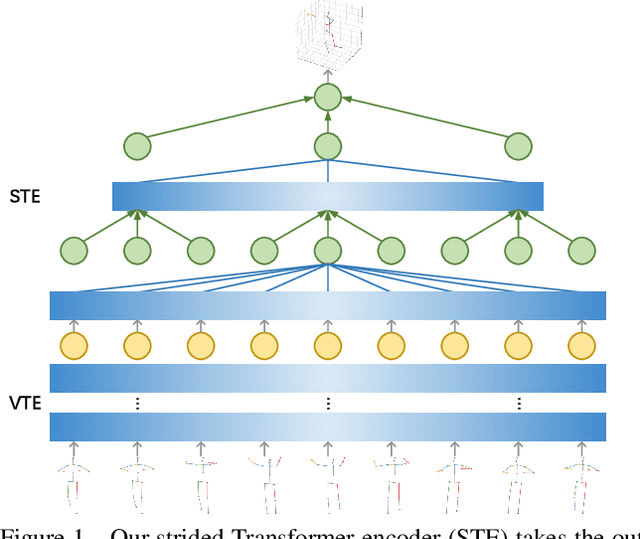
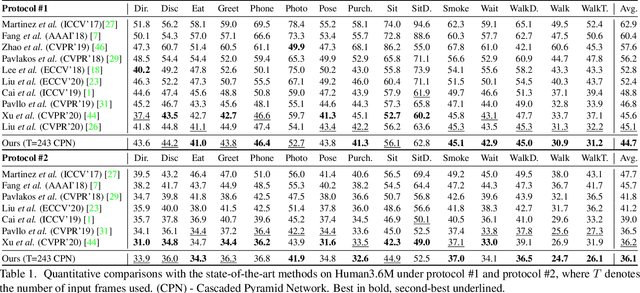
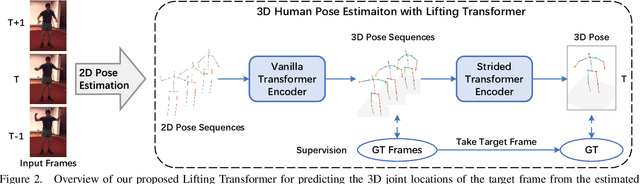
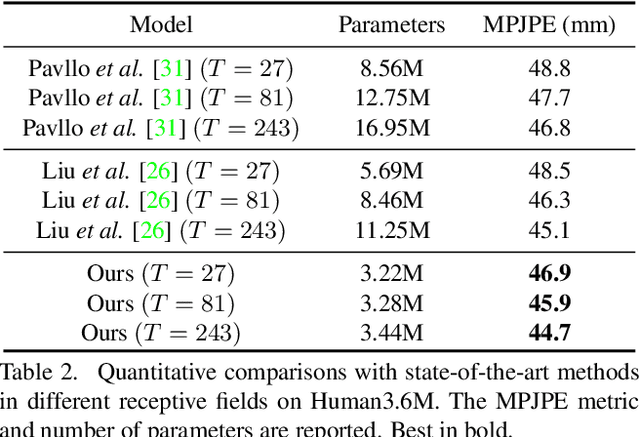
Despite great progress in video-based 3D human pose estimation, it is still challenging to learn a discriminative single-pose representation from redundant sequences. To this end, we propose a novel Transformer-based architecture, called Lifting Transformer, for 3D human pose estimation to lift a sequence of 2D joint locations to a 3D pose. Specifically, a vanilla Transformer encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce redundancy of the sequence and aggregate information from local context, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively reduce the sequence length. The modified VTE is termed as strided Transformer encoder (STE) and it is built upon the outputs of VTE. STE not only significantly reduces the computation cost but also effectively aggregates information to a single-vector representation in a global and local fashion. Moreover, a full-to-single supervision scheme is employed at both the full sequence scale and single target frame scale, applying to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision. The proposed architecture is evaluated on two challenging benchmark datasets, namely, Human3.6M and HumanEva-I, and achieves state-of-the-art results with much fewer parameters.
TransRPPG: Remote Photoplethysmography Transformer for 3D Mask Face Presentation Attack Detection
Apr 15, 2021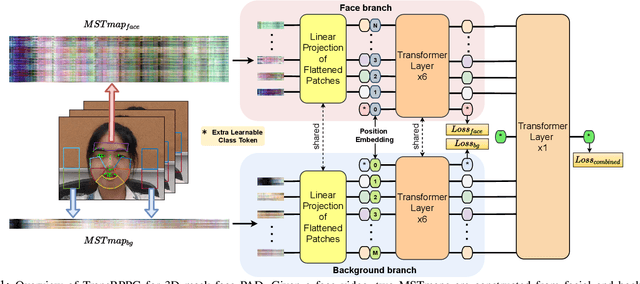

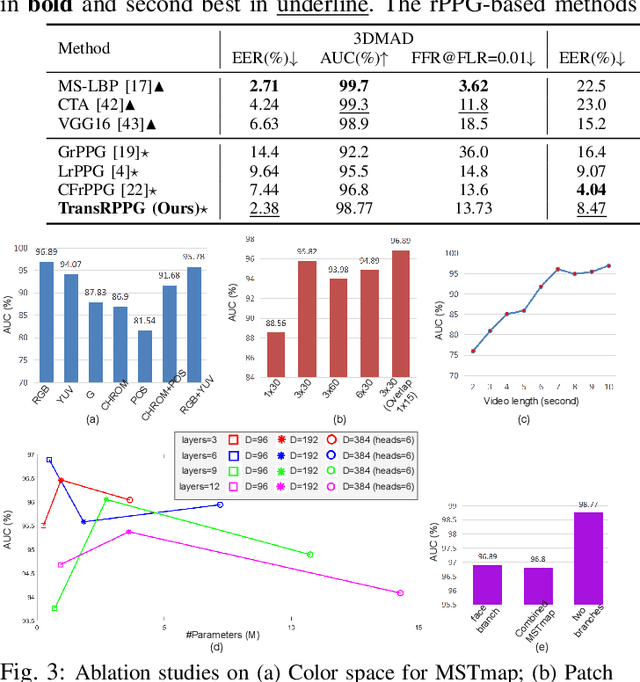

3D mask face presentation attack detection (PAD) plays a vital role in securing face recognition systems from emergent 3D mask attacks. Recently, remote photoplethysmography (rPPG) has been developed as an intrinsic liveness clue for 3D mask PAD without relying on the mask appearance. However, the rPPG features for 3D mask PAD are still needed expert knowledge to design manually, which limits its further progress in the deep learning and big data era. In this letter, we propose a pure rPPG transformer (TransRPPG) framework for learning intrinsic liveness representation efficiently. At first, rPPG-based multi-scale spatial-temporal maps (MSTmap) are constructed from facial skin and background regions. Then the transformer fully mines the global relationship within MSTmaps for liveness representation, and gives a binary prediction for 3D mask detection. Comprehensive experiments are conducted on two benchmark datasets to demonstrate the efficacy of the TransRPPG on both intra- and cross-dataset testings. Our TransRPPG is lightweight and efficient (with only 547K parameters and 763M FLOPs), which is promising for mobile-level applications.
Augmented Transformer with Adaptive Graph for Temporal Action Proposal Generation
Mar 30, 2021



Temporal action proposal generation (TAPG) is a fundamental and challenging task in video understanding, especially in temporal action detection. Most previous works focus on capturing the local temporal context and can well locate simple action instances with clean frames and clear boundaries. However, they generally fail in complicated scenarios where interested actions involve irrelevant frames and background clutters, and the local temporal context becomes less effective. To deal with these problems, we present an augmented transformer with adaptive graph network (ATAG) to exploit both long-range and local temporal contexts for TAPG. Specifically, we enhance the vanilla transformer by equipping a snippet actionness loss and a front block, dubbed augmented transformer, and it improves the abilities of capturing long-range dependencies and learning robust feature for noisy action instances.Moreover, an adaptive graph convolutional network (GCN) is proposed to build local temporal context by mining the position information and difference between adjacent features. The features from the two modules carry rich semantic information of the video, and are fused for effective sequential proposal generation. Extensive experiments are conducted on two challenging datasets, THUMOS14 and ActivityNet1.3, and the results demonstrate that our method outperforms state-of-the-art TAPG methods. Our code will be released soon.
TransReID: Transformer-based Object Re-Identification
Feb 08, 2021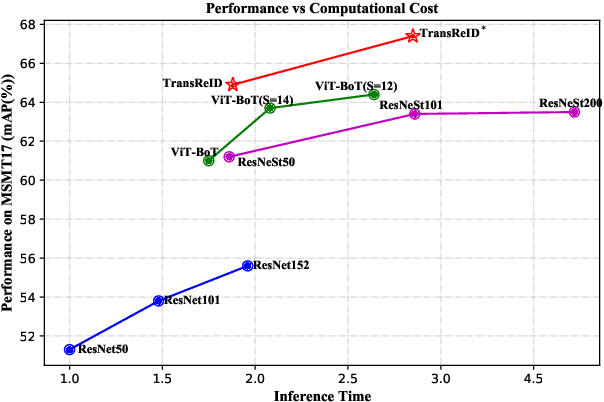
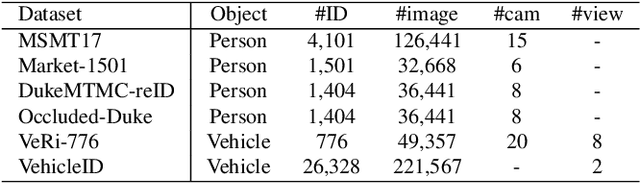
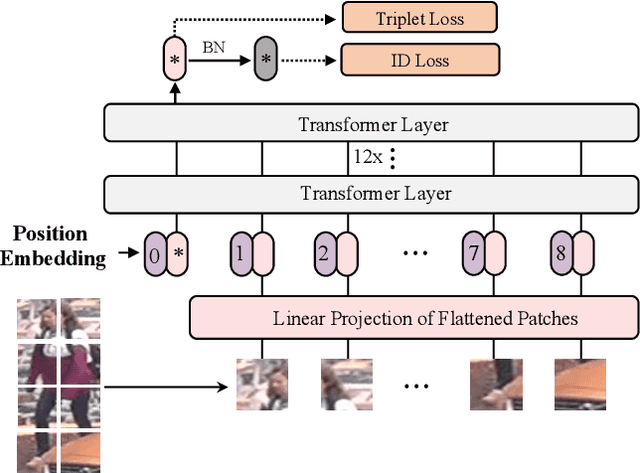
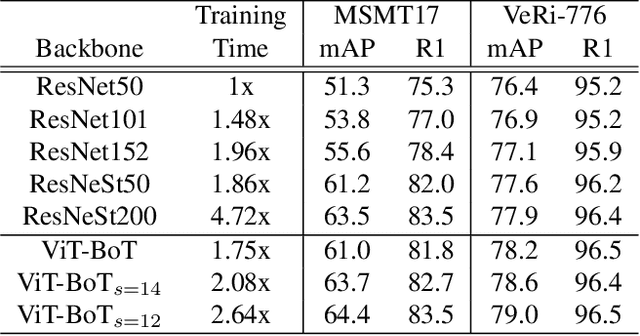
In this paper, we explore the Vision Transformer (ViT), a pure transformer-based model, for the object re-identification (ReID) task. With several adaptations, a strong baseline ViT-BoT is constructed with ViT as backbone, which achieves comparable results to convolution neural networks- (CNN-) based frameworks on several ReID benchmarks. Furthermore, two modules are designed in consideration of the specialties of ReID data: (1) It is super natural and simple for Transformer to encode non-visual information such as camera or viewpoint into vector embedding representations. Plugging into these embeddings, ViT holds the ability to eliminate the bias caused by diverse cameras or viewpoints.(2) We design a Jigsaw branch, parallel with the Global branch, to facilitate the training of the model in a two-branch learning framework. In the Jigsaw branch, a jigsaw patch module is designed to learn robust feature representation and help the training of transformer by shuffling the patches. With these novel modules, we propose a pure-transformer framework dubbed as TransReID, which is the first work to use a pure Transformer for ReID research to the best of our knowledge. Experimental results of TransReID are superior promising, which achieve state-of-the-art performance on both person and vehicle ReID benchmarks.
Zen-NAS: A Zero-Shot NAS for High-Performance Deep Image Recognition
Feb 01, 2021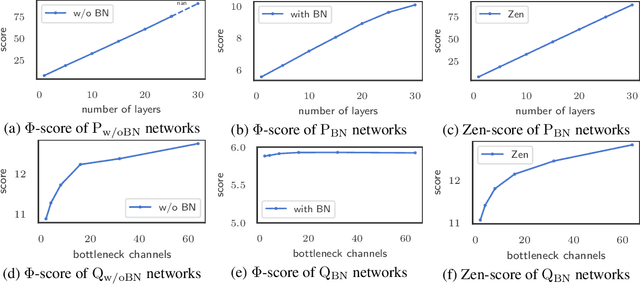
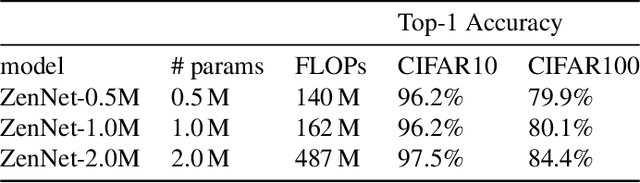
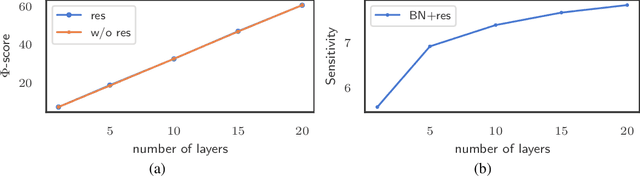
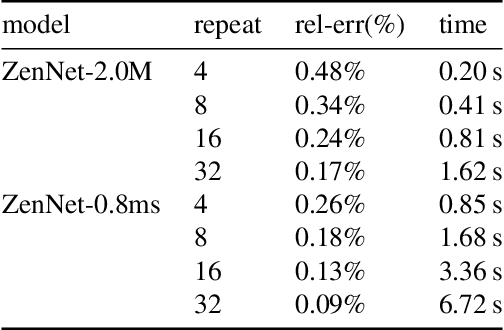
A key component in Neural Architecture Search (NAS) is an accuracy predictor which asserts the accuracy of a queried architecture. To build a high quality accuracy predictor, conventional NAS algorithms rely on training a mass of architectures or a big supernet. This step often consumes hundreds to thousands of GPU days, dominating the total search cost. To address this issue, we propose to replace the accuracy predictor with a novel model-complexity index named Zen-score. Instead of predicting model accuracy, Zen-score directly asserts the model complexity of a network without training its parameters. This is inspired by recent advances in deep learning theories which show that model complexity of a network positively correlates to its accuracy on the target dataset. The computation of Zen-score only takes a few forward inferences through a randomly initialized network using random Gaussian input. It is applicable to any Vanilla Convolutional Neural Networks (VCN-networks) or compatible variants, covering a majority of networks popular in real-world applications. When combining Zen-score with Evolutionary Algorithm, we obtain a novel Zero-Shot NAS algorithm named Zen-NAS. We conduct extensive experiments on CIFAR10/CIFAR100 and ImageNet. In summary, Zen-NAS is able to design high performance architectures in less than half GPU day (12 GPU hours). The resultant networks, named ZenNets, achieve up to $83.0\%$ top-1 accuracy on ImageNet. Comparing to EfficientNets-B3/B5 of the same or better accuracies, ZenNets are up to $5.6$ times faster on NVIDIA V100, $11$ times faster on NVIDIA T4, $2.6$ times faster on Google Pixel2 and uses $50\%$ less FLOPs. Our source code and pre-trained models are released on https://github.com/idstcv/ZenNAS.
Trear: Transformer-based RGB-D Egocentric Action Recognition
Jan 05, 2021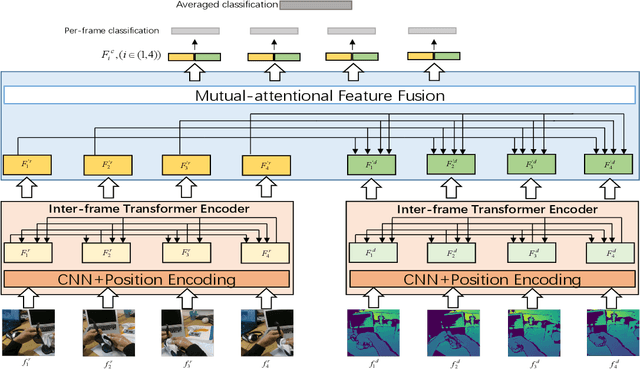
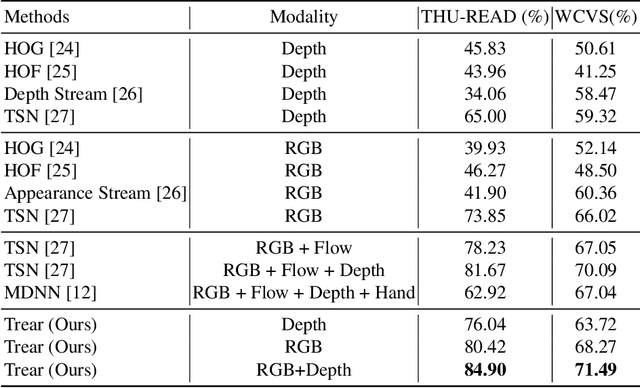
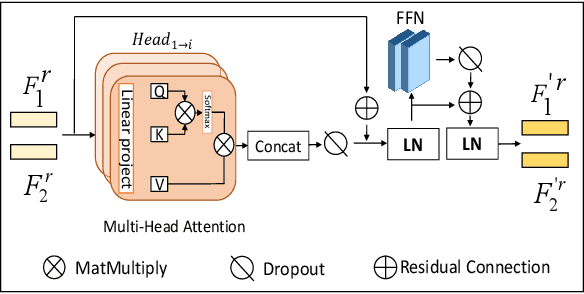
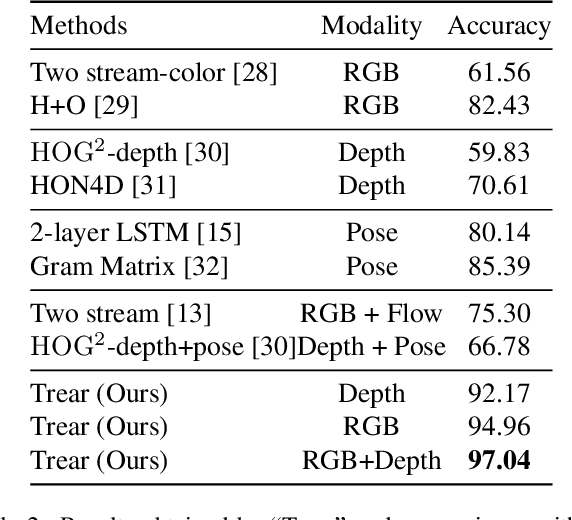
In this paper, we propose a \textbf{Tr}ansformer-based RGB-D \textbf{e}gocentric \textbf{a}ction \textbf{r}ecognition framework, called Trear. It consists of two modules, inter-frame attention encoder and mutual-attentional fusion block. Instead of using optical flow or recurrent units, we adopt self-attention mechanism to model the temporal structure of the data from different modalities. Input frames are cropped randomly to mitigate the effect of the data redundancy. Features from each modality are interacted through the proposed fusion block and combined through a simple yet effective fusion operation to produce a joint RGB-D representation. Empirical experiments on two large egocentric RGB-D datasets, THU-READ and FPHA, and one small dataset, WCVS, have shown that the proposed method outperforms the state-of-the-art results by a large margin.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020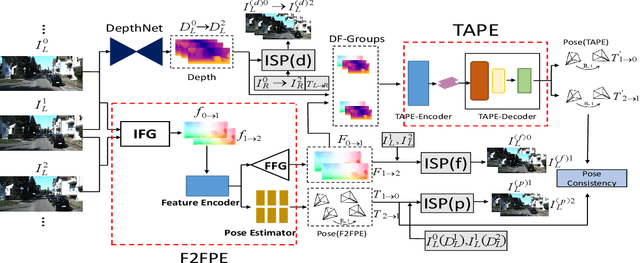
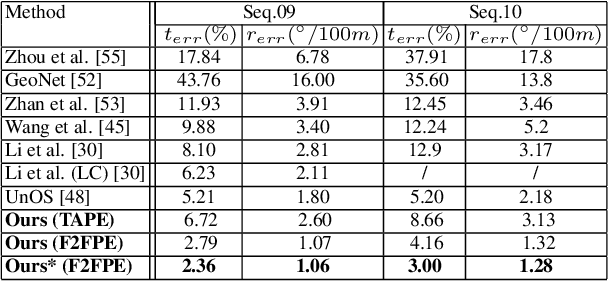
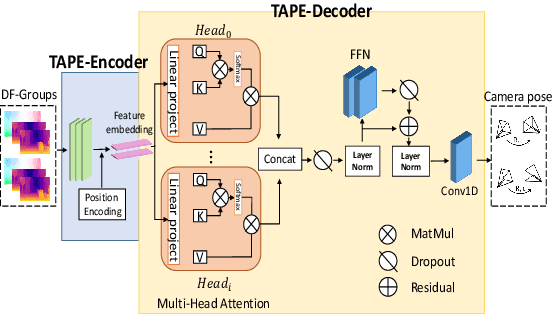
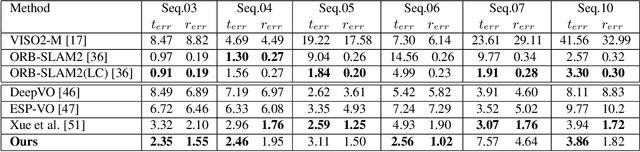
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.
SAR-NAS: Skeleton-based Action Recognition via Neural Architecture Searching
Oct 29, 2020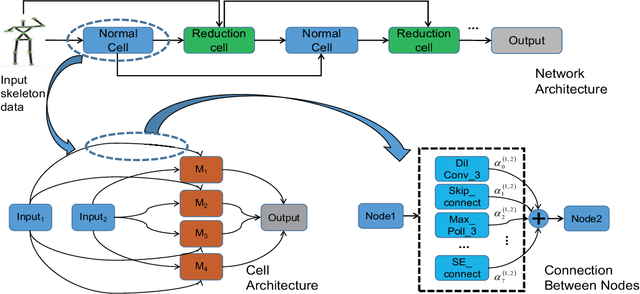
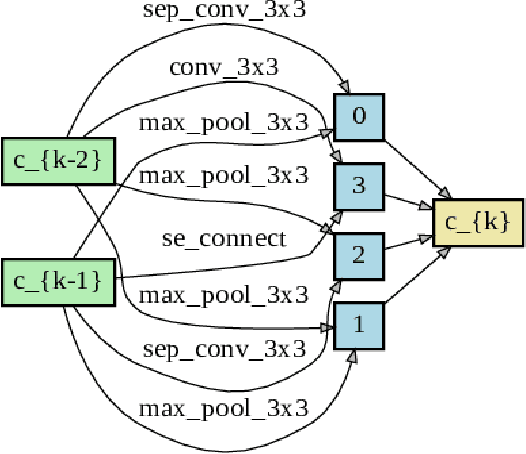
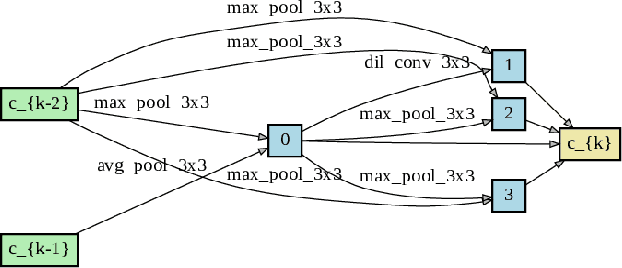

This paper presents a study of automatic design of neural network architectures for skeleton-based action recognition. Specifically, we encode a skeleton-based action instance into a tensor and carefully define a set of operations to build two types of network cells: normal cells and reduction cells. The recently developed DARTS (Differentiable Architecture Search) is adopted to search for an effective network architecture that is built upon the two types of cells. All operations are 2D based in order to reduce the overall computation and search space. Experiments on the challenging NTU RGB+D and Kinectics datasets have verified that most of the networks developed to date for skeleton-based action recognition are likely not compact and efficient. The proposed method provides an approach to search for such a compact network that is able to achieve comparative or even better performance than the state-of-the-art methods.
Searching Multi-Rate and Multi-Modal Temporal Enhanced Networks for Gesture Recognition
Aug 21, 2020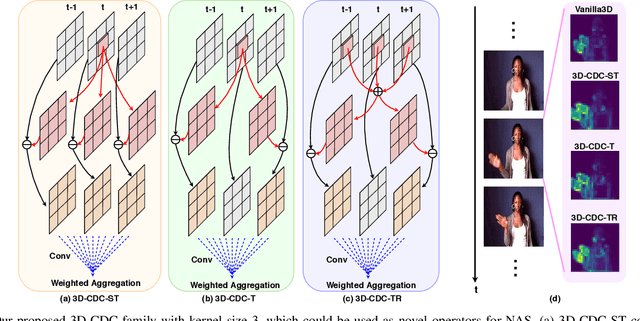
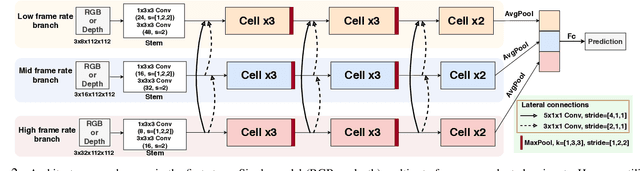
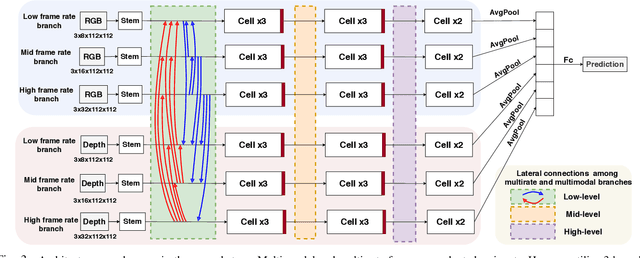
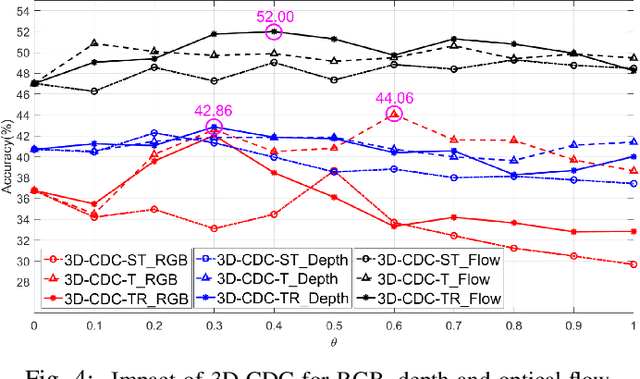
Gesture recognition has attracted considerable attention owing to its great potential in applications. Although the great progress has been made recently in multi-modal learning methods, existing methods still lack effective integration to fully explore synergies among spatio-temporal modalities effectively for gesture recognition. The problems are partially due to the fact that the existing manually designed network architectures have low efficiency in the joint learning of multi-modalities. In this paper, we propose the first neural architecture search (NAS)-based method for RGB-D gesture recognition. The proposed method includes two key components: 1) enhanced temporal representation via the proposed 3D Central Difference Convolution (3D-CDC) family, which is able to capture rich temporal context via aggregating temporal difference information; and 2) optimized backbones for multi-sampling-rate branches and lateral connections among varied modalities. The resultant multi-modal multi-rate network provides a new perspective to understand the relationship between RGB and depth modalities and their temporal dynamics. Comprehensive experiments are performed on three benchmark datasets (IsoGD, NvGesture, and EgoGesture), demonstrating the state-of-the-art performance in both single- and multi-modality settings.The code is available at https://github.com/ZitongYu/3DCDC-NAS
RobustTAD: Robust Time Series Anomaly Detection via Decomposition and Convolutional Neural Networks
Feb 21, 2020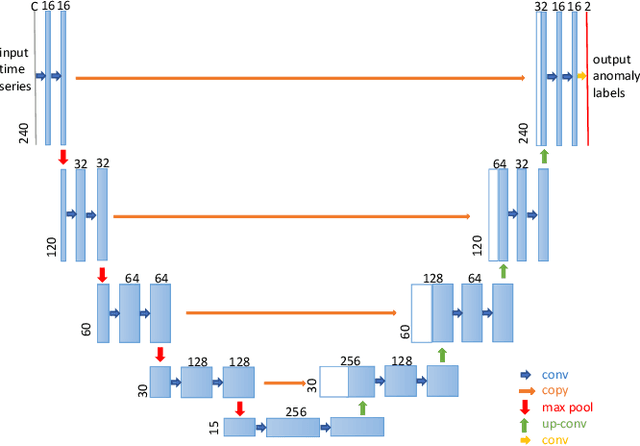
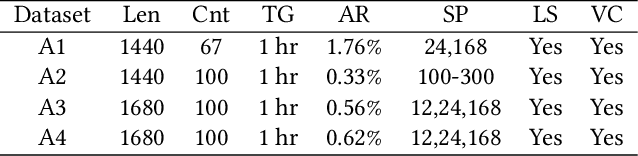
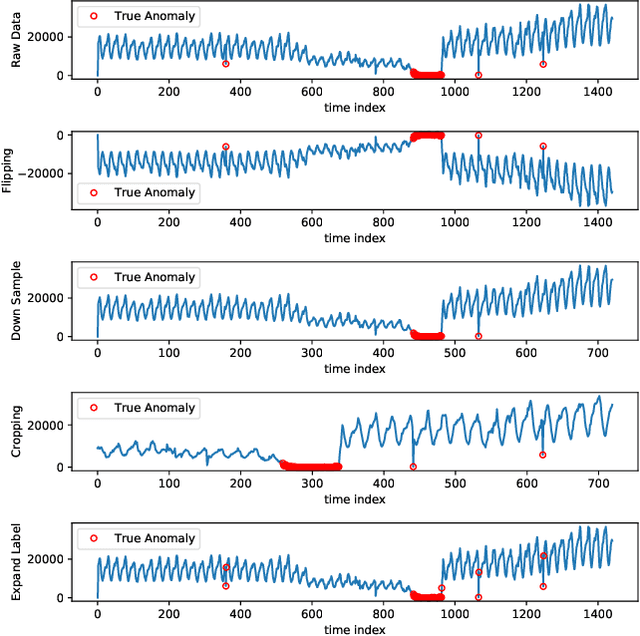
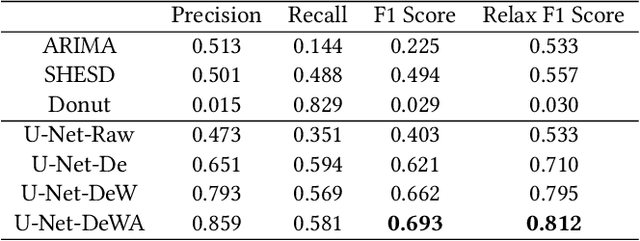
The monitoring and management of numerous and diverse time series data at Alibaba Group calls for an effective and scalable time series anomaly detection service. In this paper, we propose RobustTAD, a Robust Time series Anomaly Detection framework by integrating robust seasonal-trend decomposition and convolutional neural network for time series data. The seasonal-trend decomposition can effectively handle complicated patterns in time series, and meanwhile significantly simplifies the architecture of the neural network, which is an encoder-decoder architecture with skip connections. This architecture can effectively capture the multi-scale information from time series, which is very useful in anomaly detection. Due to the limited labeled data in time series anomaly detection, we systematically investigate data augmentation methods in both time and frequency domains. We also introduce label-based weight and value-based weight in the loss function by utilizing the unbalanced nature of the time series anomaly detection problem. Compared with the widely used forecasting-based anomaly detection algorithms, decomposition-based algorithms, traditional statistical algorithms, as well as recent neural network based algorithms, RobustTAD performs significantly better on public benchmark datasets. It is deployed as a public online service and widely adopted in different business scenarios at Alibaba Group.