 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOAD: Decoupled One Stage Action Detection Network
Apr 04, 2023



Localizing people and recognizing their actions from videos is a challenging task towards high-level video understanding. Existing methods are mostly two-stage based, with one stage for person bounding box generation and the other stage for action recognition. However, such two-stage methods are generally with low efficiency. We observe that directly unifying detection and action recognition normally suffers from (i) inferior learning due to different desired properties of context representation for detection and action recognition; (ii) optimization difficulty with insufficient training data. In this work, we present a decoupled one-stage network dubbed DOAD, to mitigate above issues and improve the efficiency for spatio-temporal action detection. To achieve it, we decouple detection and action recognition into two branches. Specifically, one branch focuses on detection representation for actor detection, and the other one for action recognition. For the action branch, we design a transformer-based module (TransPC) to model pairwise relationships between people and context. Different from commonly used vector-based dot product in self-attention, it is built upon a novel matrix-based key and value for Hadamard attention to model person-context information. It not only exploits relationships between person pairs but also takes into account context and relative position information. The results on AVA and UCF101-24 datasets show that our method is competitive with two-stage state-of-the-art methods with significant efficiency improvement.
PoseFormerV2: Exploring Frequency Domain for Efficient and Robust 3D Human Pose Estimation
Mar 30, 2023



Recently, transformer-based methods have gained significant success in sequential 2D-to-3D lifting human pose estimation. As a pioneering work, PoseFormer captures spatial relations of human joints in each video frame and human dynamics across frames with cascaded transformer layers and has achieved impressive performance. However, in real scenarios, the performance of PoseFormer and its follow-ups is limited by two factors: (a) The length of the input joint sequence; (b) The quality of 2D joint detection. Existing methods typically apply self-attention to all frames of the input sequence, causing a huge computational burden when the frame number is increased to obtain advanced estimation accuracy, and they are not robust to noise naturally brought by the limited capability of 2D joint detectors. In this paper, we propose PoseFormerV2, which exploits a compact representation of lengthy skeleton sequences in the frequency domain to efficiently scale up the receptive field and boost robustness to noisy 2D joint detection. With minimum modifications to PoseFormer, the proposed method effectively fuses features both in the time domain and frequency domain, enjoying a better speed-accuracy trade-off than its precursor. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that the proposed approach significantly outperforms the original PoseFormer and other transformer-based variants. Code is released at \url{https://github.com/QitaoZhao/PoseFormerV2}.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023



The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R
Selective Structured State-Spaces for Long-Form Video Understanding
Mar 25, 2023



Effective modeling of complex spatiotemporal dependencies in long-form videos remains an open problem. The recently proposed Structured State-Space Sequence (S4) model with its linear complexity offers a promising direction in this space. However, we demonstrate that treating all image-tokens equally as done by S4 model can adversely affect its efficiency and accuracy. To address this limitation, we present a novel Selective S4 (i.e., S5) model that employs a lightweight mask generator to adaptively select informative image tokens resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Unlike previous mask-based token reduction methods used in transformers, our S5 model avoids the dense self-attention calculation by making use of the guidance of the momentum-updated S4 model. This enables our model to efficiently discard less informative tokens and adapt to various long-form video understanding tasks more effectively. However, as is the case for most token reduction methods, the informative image tokens could be dropped incorrectly. To improve the robustness and the temporal horizon of our model, we propose a novel long-short masked contrastive learning (LSMCL) approach that enables our model to predict longer temporal context using shorter input videos. We present extensive comparative results using three challenging long-form video understanding datasets (LVU, COIN and Breakfast), demonstrating that our approach consistently outperforms the previous state-of-the-art S4 model by up to 9.6% accuracy while reducing its memory footprint by 23%.
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
Mar 22, 2023



Locating 3D objects from a single RGB image via Perspective-n-Point (PnP) is a long-standing problem in computer vision. Driven by end-to-end deep learning, recent studies suggest interpreting PnP as a differentiable layer, allowing for partial learning of 2D-3D point correspondences by backpropagating the gradients of pose loss. Yet, learning the entire correspondences from scratch is highly challenging, particularly for ambiguous pose solutions, where the globally optimal pose is theoretically non-differentiable w.r.t. the points. In this paper, we propose the EPro-PnP, a probabilistic PnP layer for general end-to-end pose estimation, which outputs a distribution of pose with differentiable probability density on the SE(3) manifold. The 2D-3D coordinates and corresponding weights are treated as intermediate variables learned by minimizing the KL divergence between the predicted and target pose distribution. The underlying principle generalizes previous approaches, and resembles the attention mechanism. EPro-PnP can enhance existing correspondence networks, closing the gap between PnP-based method and the task-specific leaders on the LineMOD 6DoF pose estimation benchmark. Furthermore, EPro-PnP helps to explore new possibilities of network design, as we demonstrate a novel deformable correspondence network with the state-of-the-art pose accuracy on the nuScenes 3D object detection benchmark. Our code is available at https://github.com/tjiiv-cprg/EPro-PnP-v2.
Revisit Parameter-Efficient Transfer Learning: A Two-Stage Paradigm
Mar 14, 2023



Parameter-Efficient Transfer Learning (PETL) aims at efficiently adapting large models pre-trained on massive data to downstream tasks with limited task-specific data. In view of the practicality of PETL, previous works focus on tuning a small set of parameters for each downstream task in an end-to-end manner while rarely considering the task distribution shift issue between the pre-training task and the downstream task. This paper proposes a novel two-stage paradigm, where the pre-trained model is first aligned to the target distribution. Then the task-relevant information is leveraged for effective adaptation. Specifically, the first stage narrows the task distribution shift by tuning the scale and shift in the LayerNorm layers. In the second stage, to efficiently learn the task-relevant information, we propose a Taylor expansion-based importance score to identify task-relevant channels for the downstream task and then only tune such a small portion of channels, making the adaptation to be parameter-efficient. Overall, we present a promising new direction for PETL, and the proposed paradigm achieves state-of-the-art performance on the average accuracy of 19 downstream tasks.
Head-Free Lightweight Semantic Segmentation with Linear Transformer
Jan 11, 2023



Existing semantic segmentation works have been mainly focused on designing effective decoders; however, the computational load introduced by the overall structure has long been ignored, which hinders their applications on resource-constrained hardwares. In this paper, we propose a head-free lightweight architecture specifically for semantic segmentation, named Adaptive Frequency Transformer. It adopts a parallel architecture to leverage prototype representations as specific learnable local descriptions which replaces the decoder and preserves the rich image semantics on high-resolution features. Although removing the decoder compresses most of the computation, the accuracy of the parallel structure is still limited by low computational resources. Therefore, we employ heterogeneous operators (CNN and Vision Transformer) for pixel embedding and prototype representations to further save computational costs. Moreover, it is very difficult to linearize the complexity of the vision Transformer from the perspective of spatial domain. Due to the fact that semantic segmentation is very sensitive to frequency information, we construct a lightweight prototype learning block with adaptive frequency filter of complexity $O(n)$ to replace standard self attention with $O(n^{2})$. Extensive experiments on widely adopted datasets demonstrate that our model achieves superior accuracy while retaining only 3M parameters. On the ADE20K dataset, our model achieves 41.8 mIoU and 4.6 GFLOPs, which is 4.4 mIoU higher than Segformer, with 45% less GFLOPs. On the Cityscapes dataset, our model achieves 78.7 mIoU and 34.4 GFLOPs, which is 2.5 mIoU higher than Segformer with 72.5% less GFLOPs. Code is available at https://github.com/dongbo811/AFFormer.
A Unified Multimodal De- and Re-coupling Framework for RGB-D Motion Recognition
Nov 16, 2022Motion recognition is a promising direction in computer vision, but the training of video classification models is much harder than images due to insufficient data and considerable parameters. To get around this, some works strive to explore multimodal cues from RGB-D data. Although improving motion recognition to some extent, these methods still face sub-optimal situations in the following aspects: (i) Data augmentation, i.e., the scale of the RGB-D datasets is still limited, and few efforts have been made to explore novel data augmentation strategies for videos; (ii) Optimization mechanism, i.e., the tightly space-time-entangled network structure brings more challenges to spatiotemporal information modeling; And (iii) cross-modal knowledge fusion, i.e., the high similarity between multimodal representations caused to insufficient late fusion. To alleviate these drawbacks, we propose to improve RGB-D-based motion recognition both from data and algorithm perspectives in this paper. In more detail, firstly, we introduce a novel video data augmentation method dubbed ShuffleMix, which acts as a supplement to MixUp, to provide additional temporal regularization for motion recognition. Secondly, a Unified Multimodal De-coupling and multi-stage Re-coupling framework, termed UMDR, is proposed for video representation learning. Finally, a novel cross-modal Complement Feature Catcher (CFCer) is explored to mine potential commonalities features in multimodal information as the auxiliary fusion stream, to improve the late fusion results. The seamless combination of these novel designs forms a robust spatiotemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Specifically, UMDR achieves unprecedented improvements of +4.5% on the Chalearn IsoGD dataset.Our code is available at https://github.com/zhoubenjia/MotionRGBD-PAMI.
Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition
Oct 06, 2022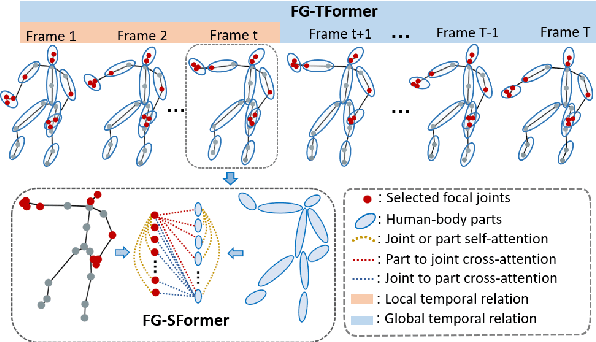
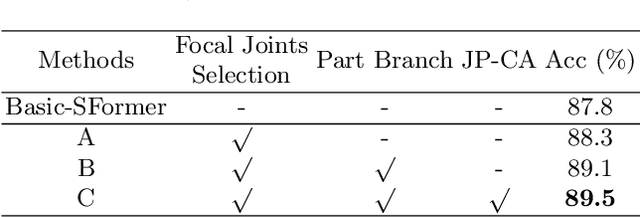
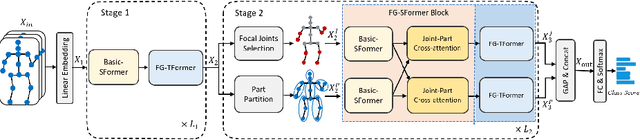

Despite great progress achieved by transformer in various vision tasks, it is still underexplored for skeleton-based action recognition with only a few attempts. Besides, these methods directly calculate the pair-wise global self-attention equally for all the joints in both the spatial and temporal dimensions, undervaluing the effect of discriminative local joints and the short-range temporal dynamics. In this work, we propose a novel Focal and Global Spatial-Temporal Transformer network (FG-STFormer), that is equipped with two key components: (1) FG-SFormer: focal joints and global parts coupling spatial transformer. It forces the network to focus on modelling correlations for both the learned discriminative spatial joints and human body parts respectively. The selective focal joints eliminate the negative effect of non-informative ones during accumulating the correlations. Meanwhile, the interactions between the focal joints and body parts are incorporated to enhance the spatial dependencies via mutual cross-attention. (2) FG-TFormer: focal and global temporal transformer. Dilated temporal convolution is integrated into the global self-attention mechanism to explicitly capture the local temporal motion patterns of joints or body parts, which is found to be vital important to make temporal transformer work. Extensive experimental results on three benchmarks, namely NTU-60, NTU-120 and NW-UCLA, show our FG-STFormer surpasses all existing transformer-based methods, and compares favourably with state-of-the art GCN-based methods.
Effective Vision Transformer Training: A Data-Centric Perspective
Sep 29, 2022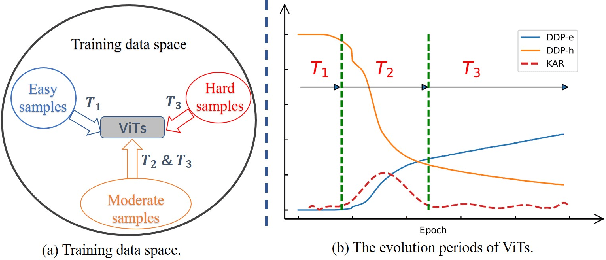
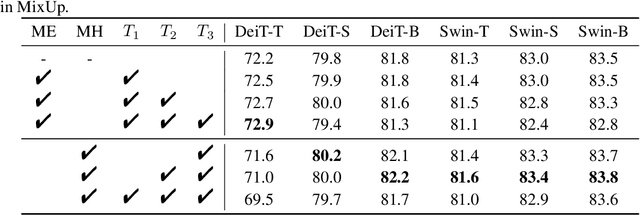
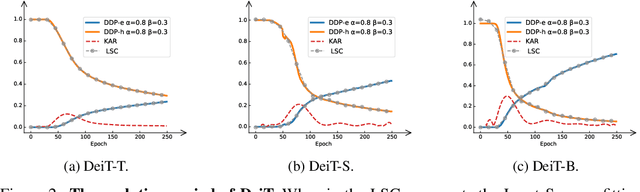
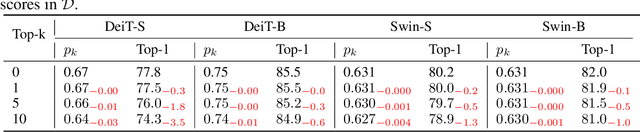
Vision Transformers (ViTs) have shown promising performance compared with Convolutional Neural Networks (CNNs), but the training of ViTs is much harder than CNNs. In this paper, we define several metrics, including Dynamic Data Proportion (DDP) and Knowledge Assimilation Rate (KAR), to investigate the training process, and divide it into three periods accordingly: formation, growth and exploration. In particular, at the last stage of training, we observe that only a tiny portion of training examples is used to optimize the model. Given the data-hungry nature of ViTs, we thus ask a simple but important question: is it possible to provide abundant ``effective'' training examples at EVERY stage of training? To address this issue, we need to address two critical questions, \ie, how to measure the ``effectiveness'' of individual training examples, and how to systematically generate enough number of ``effective'' examples when they are running out. To answer the first question, we find that the ``difficulty'' of training samples can be adopted as an indicator to measure the ``effectiveness'' of training samples. To cope with the second question, we propose to dynamically adjust the ``difficulty'' distribution of the training data in these evolution stages. To achieve these two purposes, we propose a novel data-centric ViT training framework to dynamically measure the ``difficulty'' of training samples and generate ``effective'' samples for models at different training stages. Furthermore, to further enlarge the number of ``effective'' samples and alleviate the overfitting problem in the late training stage of ViTs, we propose a patch-level erasing strategy dubbed PatchErasing. Extensive experiments demonstrate the effectiveness of the proposed data-centric ViT training framework and techniques.