 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Revenue Maximization with Popular and Profitable Products
Feb 26, 2022

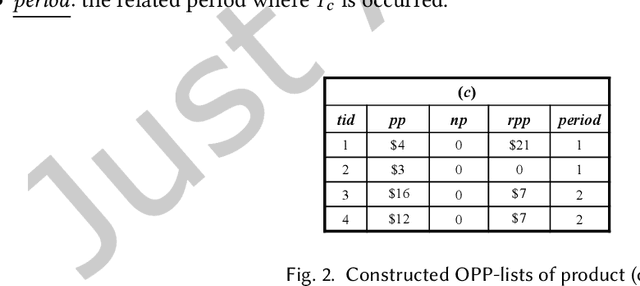
Economic-wise, a common goal for companies conducting marketing is to maximize the return revenue/profit by utilizing the various effective marketing strategies. Consumer behavior is crucially important in economy and targeted marketing, in which behavioral economics can provide valuable insights to identify the biases and profit from customers. Finding credible and reliable information on products' profitability is, however, quite difficult since most products tends to peak at certain times w.r.t. seasonal sales cycle in a year. On-Shelf Availability (OSA) plays a key factor for performance evaluation. Besides, staying ahead of hot product trends means we can increase marketing efforts without selling out the inventory. To fulfill this gap, in this paper, we first propose a general profit-oriented framework to address the problem of revenue maximization based on economic behavior, and compute the 0n-shelf Popular and most Profitable Products (OPPPs) for the targeted marketing. To tackle the revenue maximization problem, we model the k-satisfiable product concept and propose an algorithmic framework for searching OPPP and its variants. Extensive experiments are conducted on several real-world datasets to evaluate the effectiveness and efficiency of the proposed algorithm.
Graph Neural Networks for Graphs with Heterophily: A Survey
Feb 14, 2022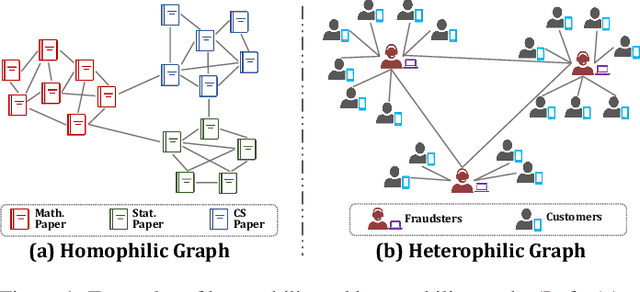
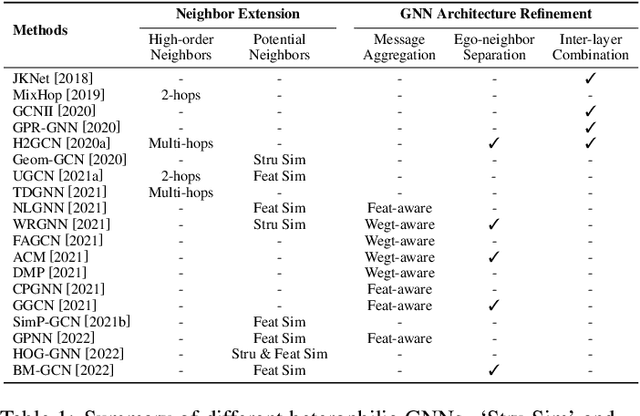
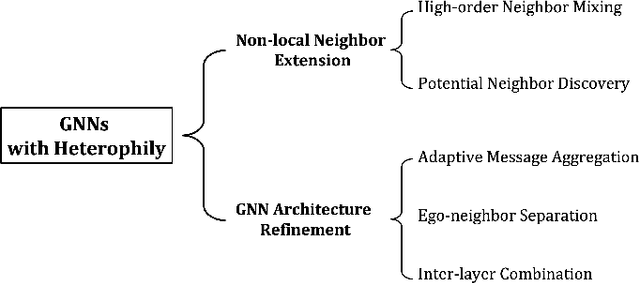
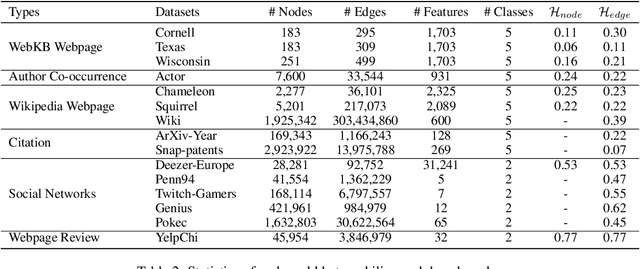
Recent years have witnessed fast developments of graph neural networks (GNNs) that have benefited myriads of graph analytic tasks and applications. In general, most GNNs depend on the homophily assumption that nodes belonging to the same class are more likely to be connected. However, as a ubiquitous graph property in numerous real-world scenarios, heterophily, i.e., nodes with different labels tend to be linked, significantly limits the performance of tailor-made homophilic GNNs. Hence, \textit{GNNs for heterophilic graphs} are gaining increasing attention in this community. To the best of our knowledge, in this paper, we provide a comprehensive review of GNNs for heterophilic graphs for the first time. Specifically, we propose a systematic taxonomy that essentially governs existing heterophilic GNN models, along with a general summary and detailed analysis. Furthermore, we summarize the mainstream heterophilic graph benchmarks to facilitate robust and fair evaluations. In the end, we point out the potential directions to advance and stimulate future research and applications on heterophilic graphs.
Large-scale Personalized Video Game Recommendation via Social-aware Contextualized Graph Neural Network
Feb 11, 2022
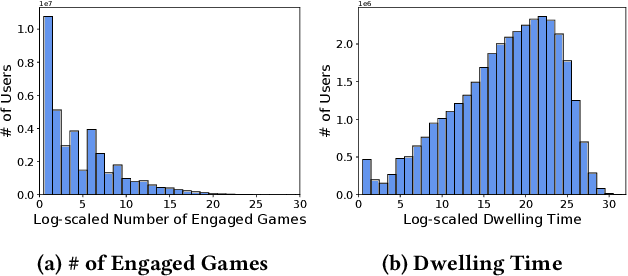
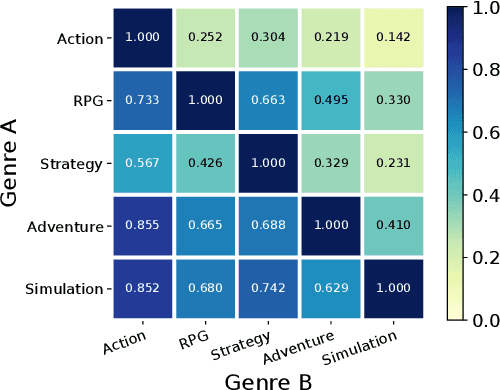
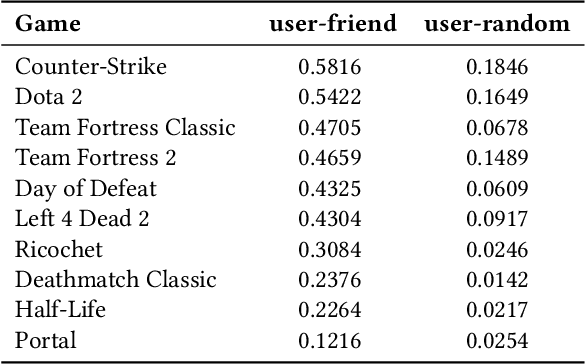
Because of the large number of online games available nowadays, online game recommender systems are necessary for users and online game platforms. The former can discover more potential online games of their interests, and the latter can attract users to dwell longer in the platform. This paper investigates the characteristics of user behaviors with respect to the online games on the Steam platform. Based on the observations, we argue that a satisfying recommender system for online games is able to characterize: personalization, game contextualization and social connection. However, simultaneously solving all is rather challenging for game recommendation. Firstly, personalization for game recommendation requires the incorporation of the dwelling time of engaged games, which are ignored in existing methods. Secondly, game contextualization should reflect the complex and high-order properties of those relations. Last but not least, it is problematic to use social connections directly for game recommendations due to the massive noise within social connections. To this end, we propose a Social-aware Contextualized Graph Neural Recommender System (SCGRec), which harnesses three perspectives to improve game recommendation. We conduct a comprehensive analysis of users' online game behaviors, which motivates the necessity of handling those three characteristics in the online game recommendation.
Deep learning for drug repurposing: methods, databases, and applications
Feb 08, 2022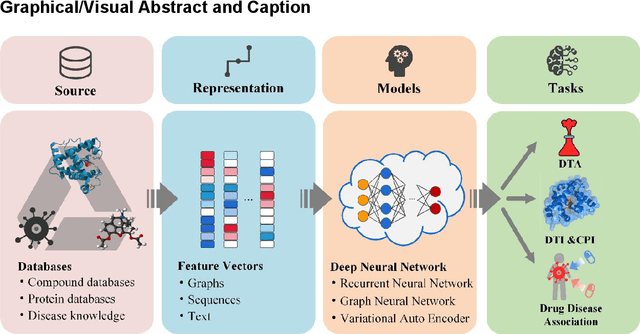
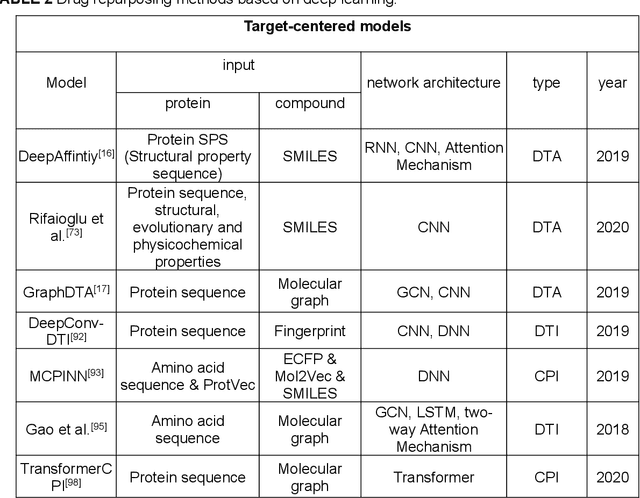
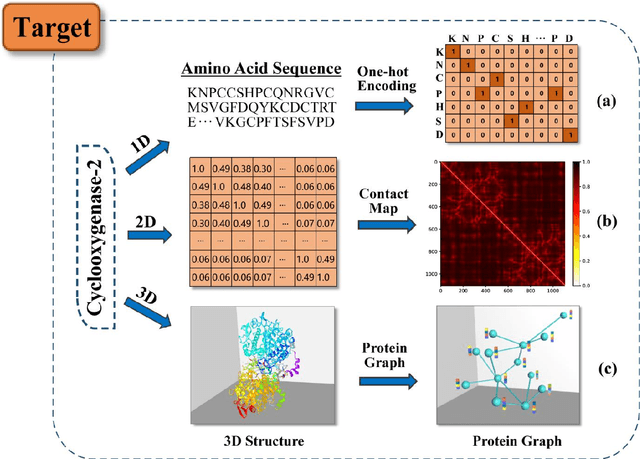
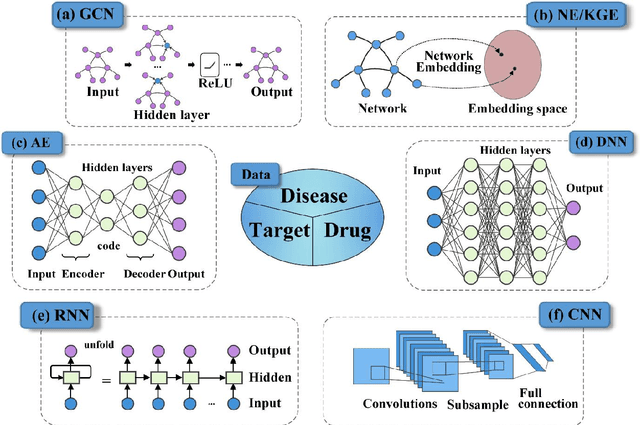
Drug development is time-consuming and expensive. Repurposing existing drugs for new therapies is an attractive solution that accelerates drug development at reduced experimental costs, specifically for Coronavirus Disease 2019 (COVID-19), an infectious disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). However, comprehensively obtaining and productively integrating available knowledge and big biomedical data to effectively advance deep learning models is still challenging for drug repurposing in other complex diseases. In this review, we introduce guidelines on how to utilize deep learning methodologies and tools for drug repurposing. We first summarized the commonly used bioinformatics and pharmacogenomics databases for drug repurposing. Next, we discuss recently developed sequence-based and graph-based representation approaches as well as state-of-the-art deep learning-based methods. Finally, we present applications of drug repurposing to fight the COVID-19 pandemic, and outline its future challenges.
Link Prediction with Contextualized Self-Supervision
Jan 25, 2022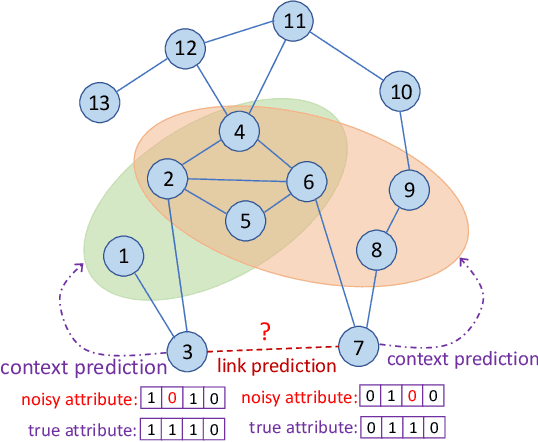
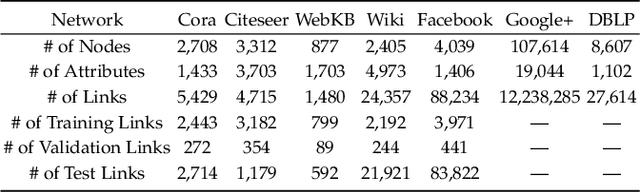
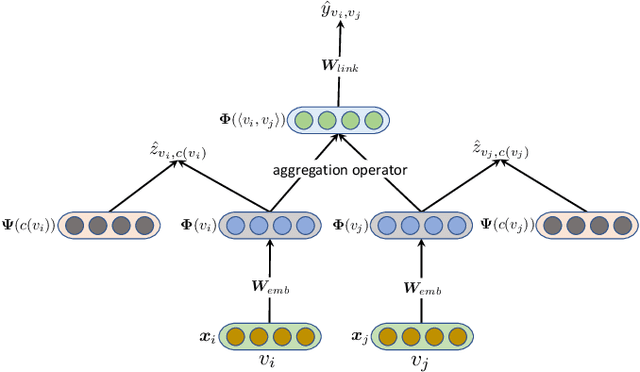
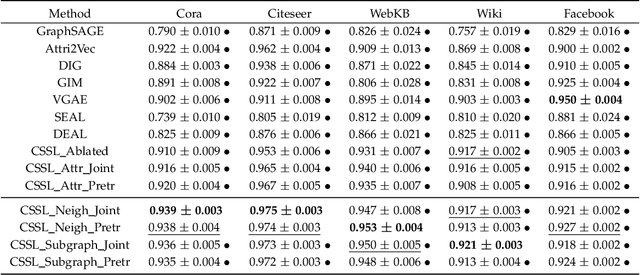
Link prediction aims to infer the existence of a link between two nodes in a network. Despite their wide application, the success of traditional link prediction algorithms is hindered by three major challenges -- link sparsity, node attribute noise and network dynamics -- that are faced by real-world networks. To overcome these challenges, we propose a Contextualized Self-Supervised Learning (CSSL) framework that fully exploits structural context prediction for link prediction. The proposed CSSL framework forms edge embeddings through aggregating pairs of node embeddings constructed via a transformation on node attributes, which are used to predict the link existence probability. To generate node embeddings tailored for link prediction, structural context prediction is leveraged as a self-supervised learning task to boost link prediction. Two types of structural contexts are investigated, i.e., context nodes collected from random walks vs. context subgraphs. The CSSL framework can be trained in an end-to-end manner, with the learning of node and edge embeddings supervised by link prediction and the self-supervised learning task. The proposed CSSL is a generic and flexible framework in the sense that it can handle both transductive and inductive link prediction settings, and both attributed and non-attributed networks. Extensive experiments and ablation studies on seven real-world benchmark graph datasets demonstrate the superior performance of the proposed self-supervision based link prediction algorithm over state-of-the-art baselines on different types of networks under both transductive and inductive settings. The proposed CSSL also yields competitive performance in terms of its robustness to node attribute noise and scalability over large-scale networks.
Dual Space Graph Contrastive Learning
Jan 19, 2022

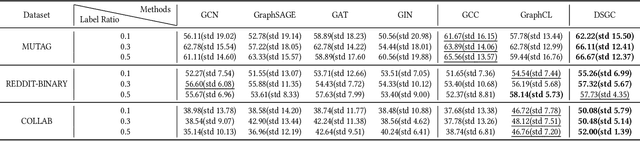
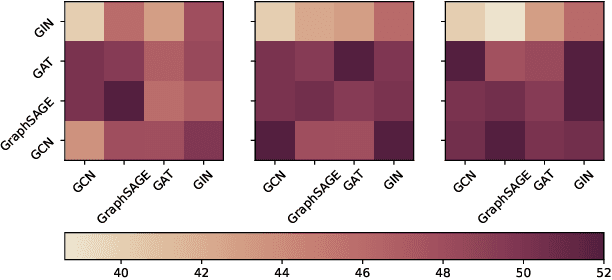
Unsupervised graph representation learning has emerged as a powerful tool to address real-world problems and achieves huge success in the graph learning domain. Graph contrastive learning is one of the unsupervised graph representation learning methods, which recently attracts attention from researchers and has achieved state-of-the-art performances on various tasks. The key to the success of graph contrastive learning is to construct proper contrasting pairs to acquire the underlying structural semantics of the graph. However, this key part is not fully explored currently, most of the ways generating contrasting pairs focus on augmenting or perturbating graph structures to obtain different views of the input graph. But such strategies could degrade the performances via adding noise into the graph, which may narrow down the field of the applications of graph contrastive learning. In this paper, we propose a novel graph contrastive learning method, namely \textbf{D}ual \textbf{S}pace \textbf{G}raph \textbf{C}ontrastive (DSGC) Learning, to conduct graph contrastive learning among views generated in different spaces including the hyperbolic space and the Euclidean space. Since both spaces have their own advantages to represent graph data in the embedding spaces, we hope to utilize graph contrastive learning to bridge the spaces and leverage advantages from both sides. The comparison experiment results show that DSGC achieves competitive or better performances among all the datasets. In addition, we conduct extensive experiments to analyze the impact of different graph encoders on DSGC, giving insights about how to better leverage the advantages of contrastive learning between different spaces.
Sequential Recommendation via Stochastic Self-Attention
Jan 16, 2022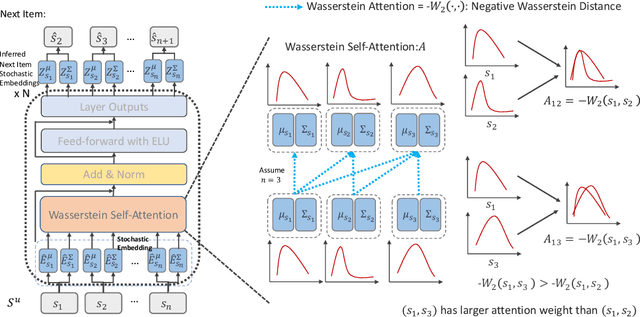
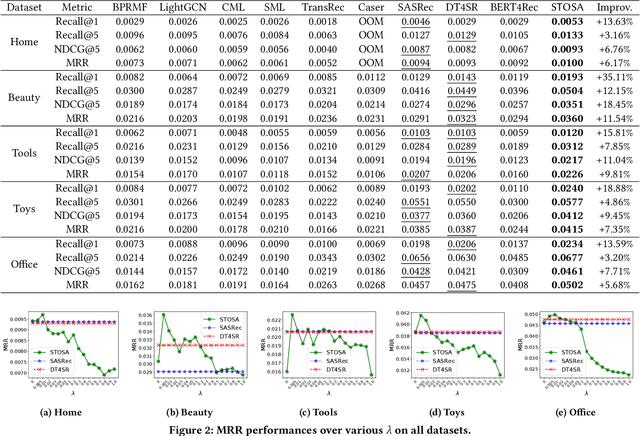

Sequential recommendation models the dynamics of a user's previous behaviors in order to forecast the next item, and has drawn a lot of attention. Transformer-based approaches, which embed items as vectors and use dot-product self-attention to measure the relationship between items, demonstrate superior capabilities among existing sequential methods. However, users' real-world sequential behaviors are \textit{\textbf{uncertain}} rather than deterministic, posing a significant challenge to present techniques. We further suggest that dot-product-based approaches cannot fully capture \textit{\textbf{collaborative transitivity}}, which can be derived in item-item transitions inside sequences and is beneficial for cold start items. We further argue that BPR loss has no constraint on positive and sampled negative items, which misleads the optimization. We propose a novel \textbf{STO}chastic \textbf{S}elf-\textbf{A}ttention~(STOSA) to overcome these issues. STOSA, in particular, embeds each item as a stochastic Gaussian distribution, the covariance of which encodes the uncertainty. We devise a novel Wasserstein Self-Attention module to characterize item-item position-wise relationships in sequences, which effectively incorporates uncertainty into model training. Wasserstein attentions also enlighten the collaborative transitivity learning as it satisfies triangle inequality. Moreover, we introduce a novel regularization term to the ranking loss, which assures the dissimilarity between positive and the negative items. Extensive experiments on five real-world benchmark datasets demonstrate the superiority of the proposed model over state-of-the-art baselines, especially on cold start items. The code is available in \url{https://github.com/zfan20/STOSA}.
Multi-Sparse-Domain Collaborative Recommendation via Enhanced Comprehensive Aspect Preference Learning
Jan 16, 2022
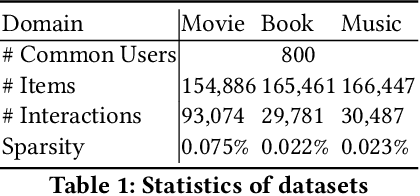
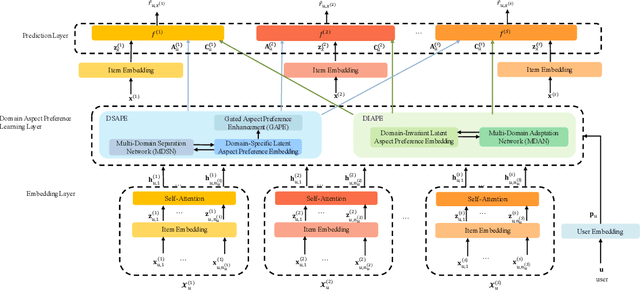
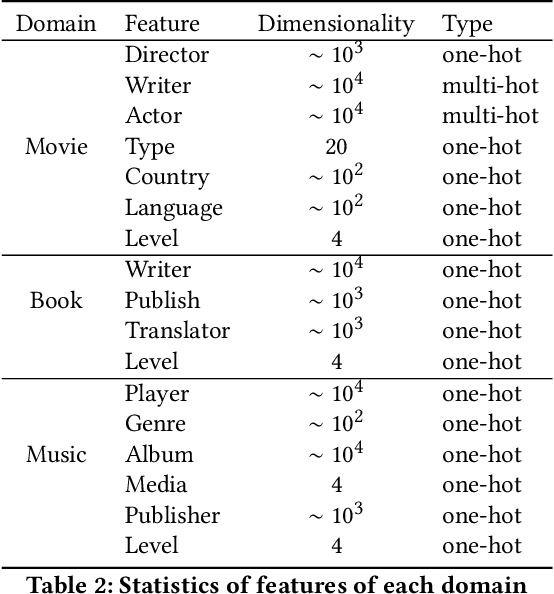
Cross-domain recommendation (CDR) has been attracting increasing attention of researchers for its ability to alleviate the data sparsity problem in recommender systems. However, the existing single-target or dual-target CDR methods often suffer from two drawbacks, the assumption of at least one rich domain and the heavy dependence on domain-invariant preference, which are impractical in real world where sparsity is ubiquitous and might degrade the user preference learning. To overcome these issues, we propose a Multi-Sparse-Domain Collaborative Recommendation (MSDCR) model for multi-target cross-domain recommendation. Unlike traditional CDR methods, MSDCR treats the multiple relevant domains as all sparse and can simultaneously improve the recommendation performance in each domain. We propose a Multi-Domain Separation Network (MDSN) and a Gated Aspect Preference Enhancement (GAPE) module for MSDCR to enhance a user's domain-specific aspect preferences in a domain by transferring the complementary aspect preferences in other domains, during which the uniqueness of the domain-specific preference can be preserved through the adversarial training offered by MDSN and the complementarity can be adaptively determined by GAPE. Meanwhile, we propose a Multi-Domain Adaptation Network (MDAN) for MSDCR to capture a user's domain-invariant aspect preference. With the integration of the enhanced domain-specific aspect preference and the domain-invariant aspect preference, MSDCR can reach a comprehensive understanding of a user's preference in each sparse domain. At last, the extensive experiments conducted on real datasets demonstrate the remarkable superiority of MSDCR over the state-of-the-art single-domain recommendation models and CDR models.
Learning from Atypical Behavior: Temporary Interest Aware Recommendation Based on Reinforcement Learning
Jan 16, 2022Traditional robust recommendation methods view atypical user-item interactions as noise and aim to reduce their impact with some kind of noise filtering technique, which often suffers from two challenges. First, in real world, atypical interactions may signal users' temporary interest different from their general preference. Therefore, simply filtering out the atypical interactions as noise may be inappropriate and degrade the personalization of recommendations. Second, it is hard to acquire the temporary interest since there are no explicit supervision signals to indicate whether an interaction is atypical or not. To address this challenges, we propose a novel model called Temporary Interest Aware Recommendation (TIARec), which can distinguish atypical interactions from normal ones without supervision and capture the temporary interest as well as the general preference of users. Particularly, we propose a reinforcement learning framework containing a recommender agent and an auxiliary classifier agent, which are jointly trained with the objective of maximizing the cumulative return of the recommendations made by the recommender agent. During the joint training process, the classifier agent can judge whether the interaction with an item recommended by the recommender agent is atypical, and the knowledge about learning temporary interest from atypical interactions can be transferred to the recommender agent, which makes the recommender agent able to alone make recommendations that balance the general preference and temporary interest of users. At last, the experiments conducted on real world datasets verify the effectiveness of TIARec.
Translational Concept Embedding for Generalized Compositional Zero-shot Learning
Dec 20, 2021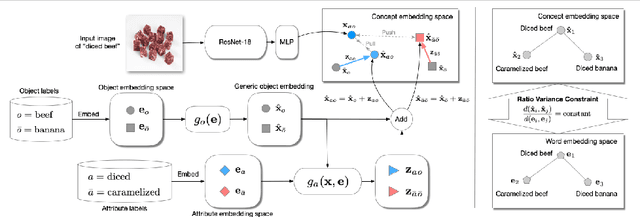
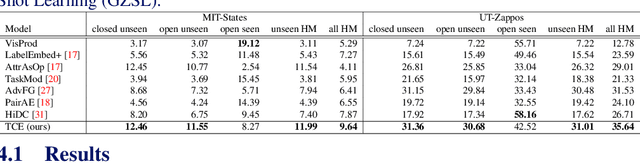
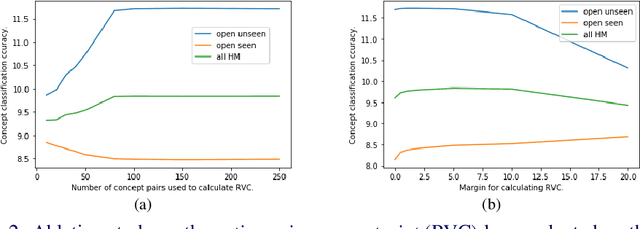
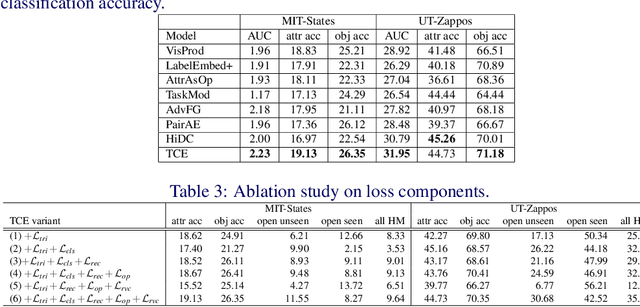
Generalized compositional zero-shot learning means to learn composed concepts of attribute-object pairs in a zero-shot fashion, where a model is trained on a set of seen concepts and tested on a combined set of seen and unseen concepts. This task is very challenging because of not only the gap between seen and unseen concepts but also the contextual dependency between attributes and objects. This paper introduces a new approach, termed translational concept embedding, to solve these two difficulties in a unified framework. It models the effect of applying an attribute to an object as adding a translational attribute feature to an object prototype. We explicitly take into account of the contextual dependency between attributes and objects by generating translational attribute features conditionally dependent on the object prototypes. Furthermore, we design a ratio variance constraint loss to promote the model's generalization ability on unseen concepts. It regularizes the distances between concepts by utilizing knowledge from their pretrained word embeddings. We evaluate the performance of our model under both the unbiased and biased concept classification tasks, and show that our model is able to achieve good balance in predicting unseen and seen concepts.