 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Part-aware Instance Segmentation for Industrial Bin Picking
Mar 05, 2022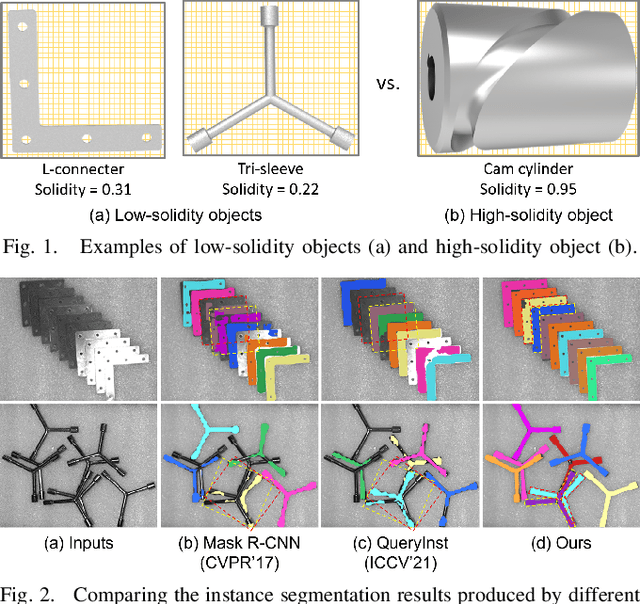

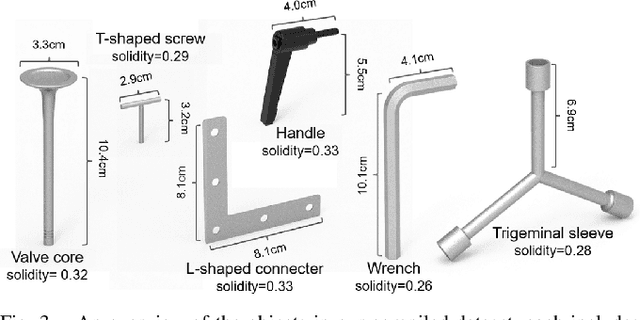
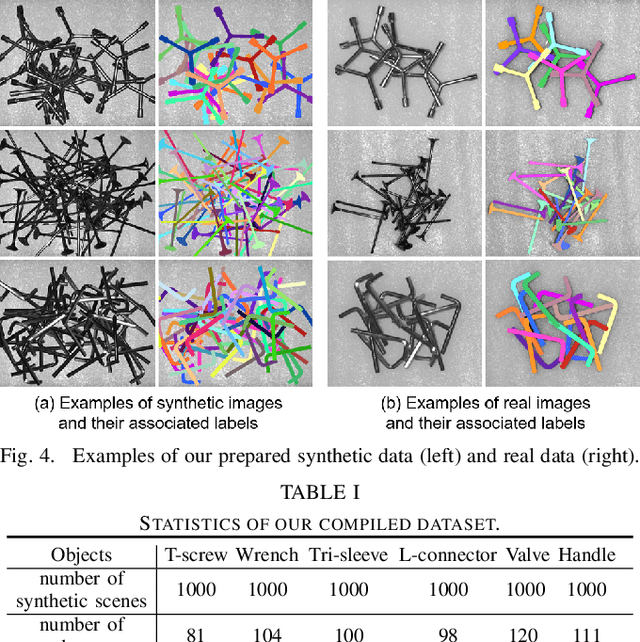
Industrial bin picking is a challenging task that requires accurate and robust segmentation of individual object instances. Particularly, industrial objects can have irregular shapes, that is, thin and concave, whereas in bin-picking scenarios, objects are often closely packed with strong occlusion. To address these challenges, we formulate a novel part-aware instance segmentation pipeline. The key idea is to decompose industrial objects into correlated approximate convex parts and enhance the object-level segmentation with part-level segmentation. We design a part-aware network to predict part masks and part-to-part offsets, followed by a part aggregation module to assemble the recognized parts into instances. To guide the network learning, we also propose an automatic label decoupling scheme to generate ground-truth part-level labels from instance-level labels. Finally, we contribute the first instance segmentation dataset, which contains a variety of industrial objects that are thin and have non-trivial shapes. Extensive experimental results on various industrial objects demonstrate that our method can achieve the best segmentation results compared with the state-of-the-art approaches.
TraSeTR: Track-to-Segment Transformer with Contrastive Query for Instance-level Instrument Segmentation in Robotic Surgery
Feb 17, 2022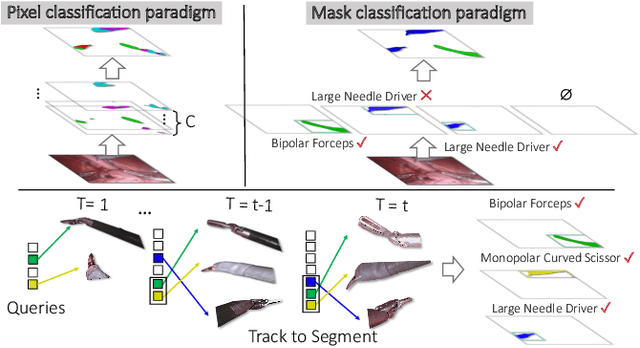
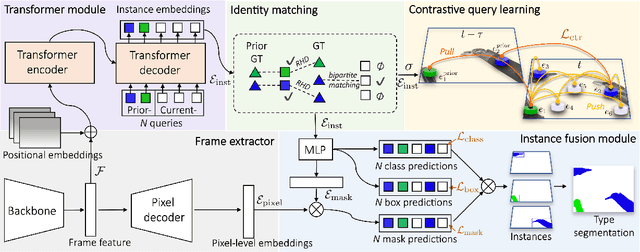
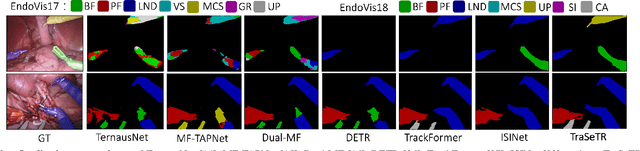
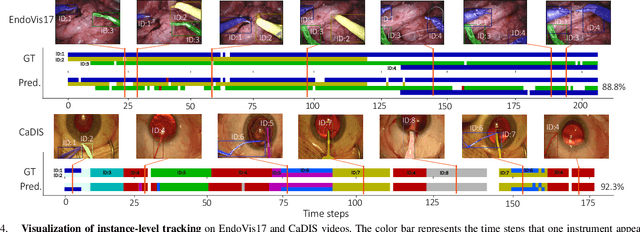
Surgical instrument segmentation -- in general a pixel classification task -- is fundamentally crucial for promoting cognitive intelligence in robot-assisted surgery (RAS). However, previous methods are struggling with discriminating instrument types and instances. To address the above issues, we explore a mask classification paradigm that produces per-segment predictions. We propose TraSeTR, a novel Track-to-Segment Transformer that wisely exploits tracking cues to assist surgical instrument segmentation. TraSeTR jointly reasons about the instrument type, location, and identity with instance-level predictions i.e., a set of class-bbox-mask pairs, by decoding query embeddings. Specifically, we introduce the prior query that encoded with previous temporal knowledge, to transfer tracking signals to current instances via identity matching. A contrastive query learning strategy is further applied to reshape the query feature space, which greatly alleviates the tracking difficulty caused by large temporal variations. The effectiveness of our method is demonstrated with state-of-the-art instrument type segmentation results on three public datasets, including two RAS benchmarks from EndoVis Challenges and one cataract surgery dataset CaDIS.
Hepatic vessel segmentation based on 3D swin-transformer with inductive biased multi-head self-attention
Nov 22, 2021
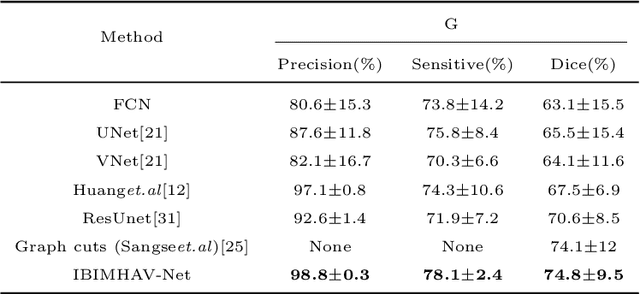
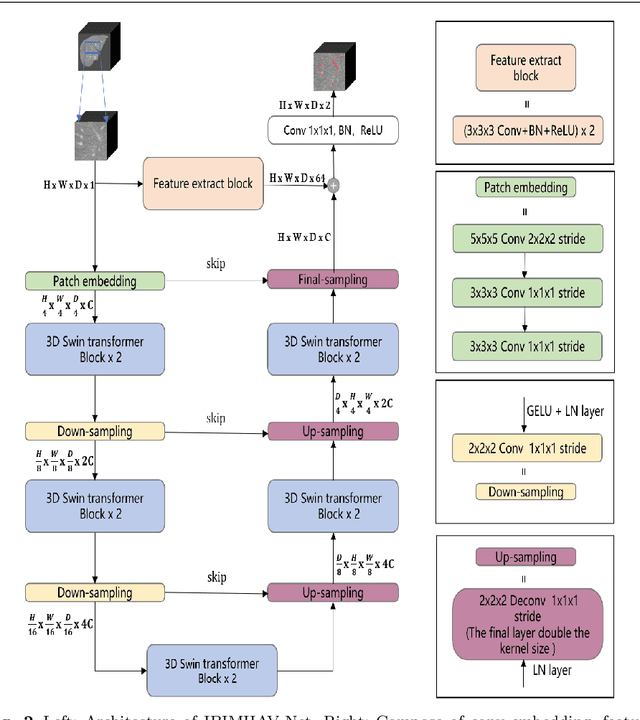
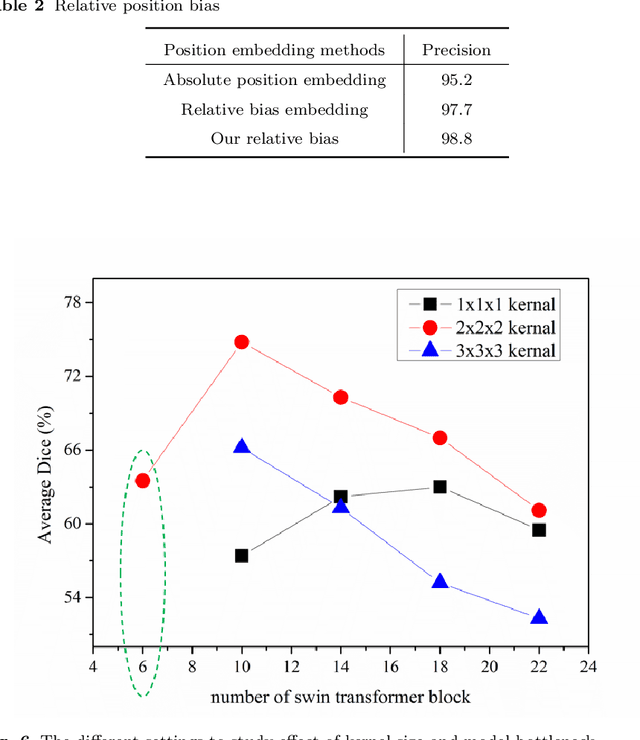
Purpose: Segmentation of liver vessels from CT images is indispensable prior to surgical planning and aroused broad range of interests in the medical image analysis community. Due to the complex structure and low contrast background, automatic liver vessel segmentation remains particularly challenging. Most of the related researches adopt FCN, U-net, and V-net variants as a backbone. However, these methods mainly focus on capturing multi-scale local features which may produce misclassified voxels due to the convolutional operator's limited locality reception field. Methods: We propose a robust end-to-end vessel segmentation network called Inductive BIased Multi-Head Attention Vessel Net(IBIMHAV-Net) by expanding swin transformer to 3D and employing an effective combination of convolution and self-attention. In practice, we introduce the voxel-wise embedding rather than patch-wise embedding to locate precise liver vessel voxels, and adopt multi-scale convolutional operators to gain local spatial information. On the other hand, we propose the inductive biased multi-head self-attention which learns inductive biased relative positional embedding from initialized absolute position embedding. Based on this, we can gain a more reliable query and key matrix. To validate the generalization of our model, we test on samples which have different structural complexity. Results: We conducted experiments on the 3DIRCADb datasets. The average dice and sensitivity of the four tested cases were 74.8% and 77.5%, which exceed results of existing deep learning methods and improved graph cuts method. Conclusion: The proposed model IBIMHAV-Net provides an automatic, accurate 3D liver vessel segmentation with an interleaved architecture that better utilizes both global and local spatial features in CT volumes. It can be further extended for other clinical data.
Real-time landmark detection for precise endoscopic submucosal dissection via shape-aware relation network
Nov 08, 2021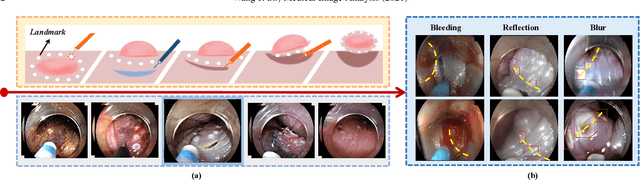
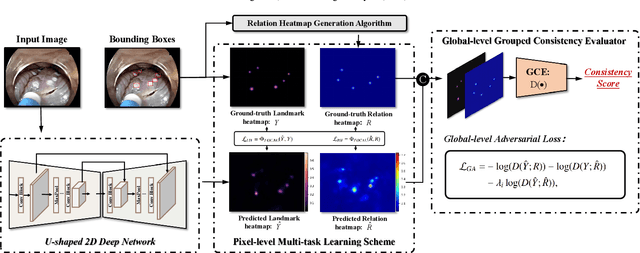
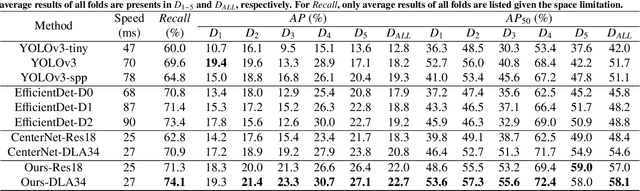
We propose a novel shape-aware relation network for accurate and real-time landmark detection in endoscopic submucosal dissection (ESD) surgery. This task is of great clinical significance but extremely challenging due to bleeding, lighting reflection, and motion blur in the complicated surgical environment. Compared with existing solutions, which either neglect geometric relationships among targeting objects or capture the relationships by using complicated aggregation schemes, the proposed network is capable of achieving satisfactory accuracy while maintaining real-time performance by taking full advantage of the spatial relations among landmarks. We first devise an algorithm to automatically generate relation keypoint heatmaps, which are able to intuitively represent the prior knowledge of spatial relations among landmarks without using any extra manual annotation efforts. We then develop two complementary regularization schemes to progressively incorporate the prior knowledge into the training process. While one scheme introduces pixel-level regularization by multi-task learning, the other integrates global-level regularization by harnessing a newly designed grouped consistency evaluator, which adds relation constraints to the proposed network in an adversarial manner. Both schemes are beneficial to the model in training, and can be readily unloaded in inference to achieve real-time detection. We establish a large in-house dataset of ESD surgery for esophageal cancer to validate the effectiveness of our proposed method. Extensive experimental results demonstrate that our approach outperforms state-of-the-art methods in terms of accuracy and efficiency, achieving better detection results faster. Promising results on two downstream applications further corroborate the great potential of our method in ESD clinical practice.
Flattening Sharpness for Dynamic Gradient Projection Memory Benefits Continual Learning
Oct 09, 2021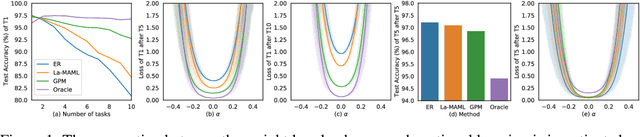
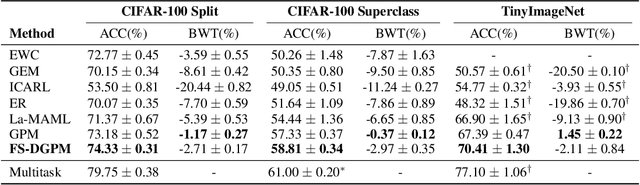
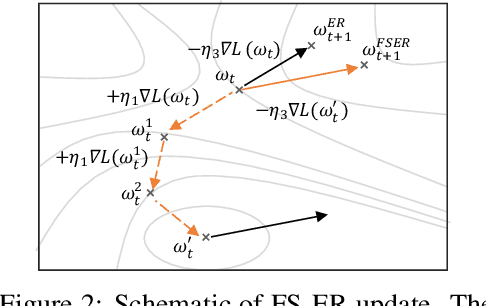
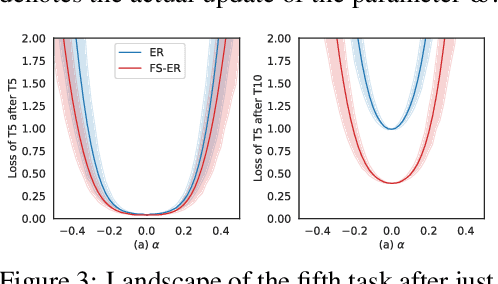
The backpropagation networks are notably susceptible to catastrophic forgetting, where networks tend to forget previously learned skills upon learning new ones. To address such the 'sensitivity-stability' dilemma, most previous efforts have been contributed to minimizing the empirical risk with different parameter regularization terms and episodic memory, but rarely exploring the usages of the weight loss landscape. In this paper, we investigate the relationship between the weight loss landscape and sensitivity-stability in the continual learning scenario, based on which, we propose a novel method, Flattening Sharpness for Dynamic Gradient Projection Memory (FS-DGPM). In particular, we introduce a soft weight to represent the importance of each basis representing past tasks in GPM, which can be adaptively learned during the learning process, so that less important bases can be dynamically released to improve the sensitivity of new skill learning. We further introduce Flattening Sharpness (FS) to reduce the generalization gap by explicitly regulating the flatness of the weight loss landscape of all seen tasks. As demonstrated empirically, our proposed method consistently outperforms baselines with the superior ability to learn new skills while alleviating forgetting effectively.
Efficient Global-Local Memory for Real-time Instrument Segmentation of Robotic Surgical Video
Sep 28, 2021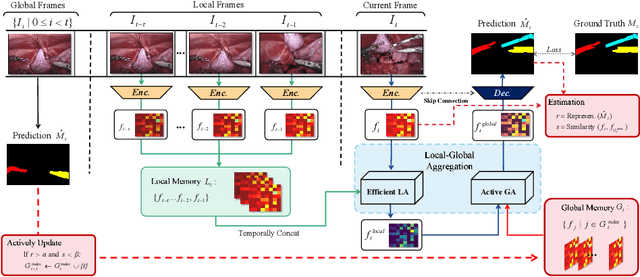
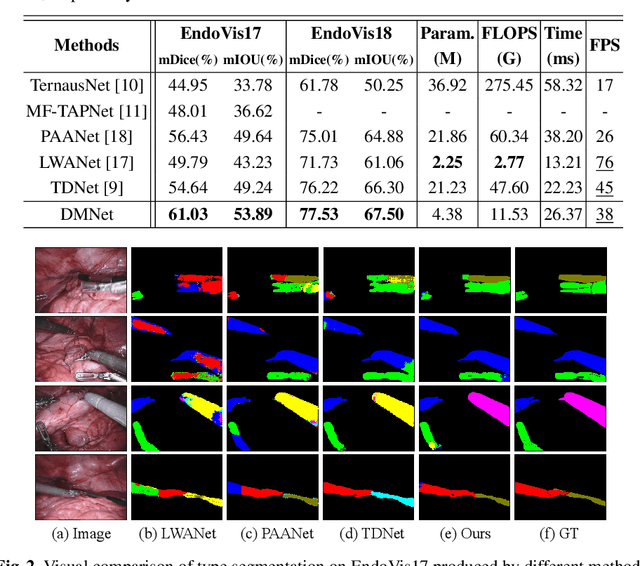
Performing a real-time and accurate instrument segmentation from videos is of great significance for improving the performance of robotic-assisted surgery. We identify two important clues for surgical instrument perception, including local temporal dependency from adjacent frames and global semantic correlation in long-range duration. However, most existing works perform segmentation purely using visual cues in a single frame. Optical flow is just used to model the motion between only two frames and brings heavy computational cost. We propose a novel dual-memory network (DMNet) to wisely relate both global and local spatio-temporal knowledge to augment the current features, boosting the segmentation performance and retaining the real-time prediction capability. We propose, on the one hand, an efficient local memory by taking the complementary advantages of convolutional LSTM and non-local mechanisms towards the relating reception field. On the other hand, we develop an active global memory to gather the global semantic correlation in long temporal range to current one, in which we gather the most informative frames derived from model uncertainty and frame similarity. We have extensively validated our method on two public benchmark surgical video datasets. Experimental results demonstrate that our method largely outperforms the state-of-the-art works on segmentation accuracy while maintaining a real-time speed.
Modelling Neighbor Relation in Joint Space-Time Graph for Video Correspondence Learning
Sep 28, 2021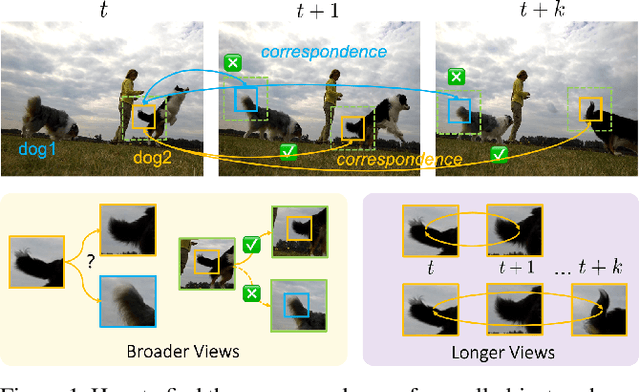
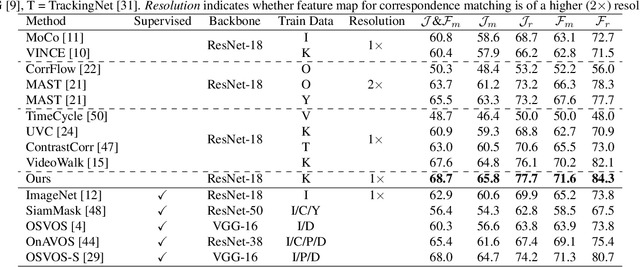
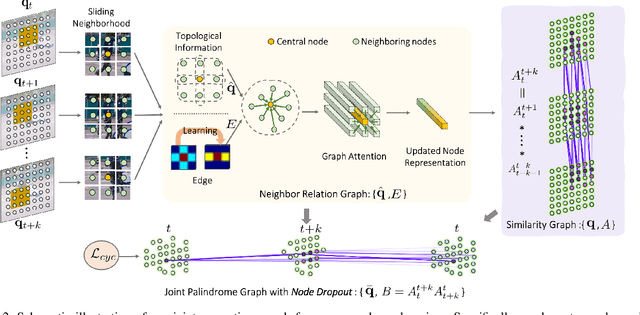
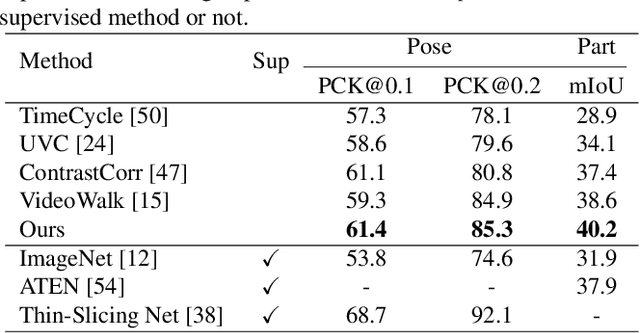
This paper presents a self-supervised method for learning reliable visual correspondence from unlabeled videos. We formulate the correspondence as finding paths in a joint space-time graph, where nodes are grid patches sampled from frames, and are linked by two types of edges: (i) neighbor relations that determine the aggregation strength from intra-frame neighbors in space, and (ii) similarity relations that indicate the transition probability of inter-frame paths across time. Leveraging the cycle-consistency in videos, our contrastive learning objective discriminates dynamic objects from both their neighboring views and temporal views. Compared with prior works, our approach actively explores the neighbor relations of central instances to learn a latent association between center-neighbor pairs (e.g., "hand -- arm") across time, thus improving the instance discrimination. Without fine-tuning, our learned representation outperforms the state-of-the-art self-supervised methods on a variety of visual tasks including video object propagation, part propagation, and pose keypoint tracking. Our self-supervised method also surpasses some fully supervised algorithms designed for the specific tasks.
Source-Free Domain Adaptive Fundus Image Segmentation with Denoised Pseudo-Labeling
Sep 19, 2021
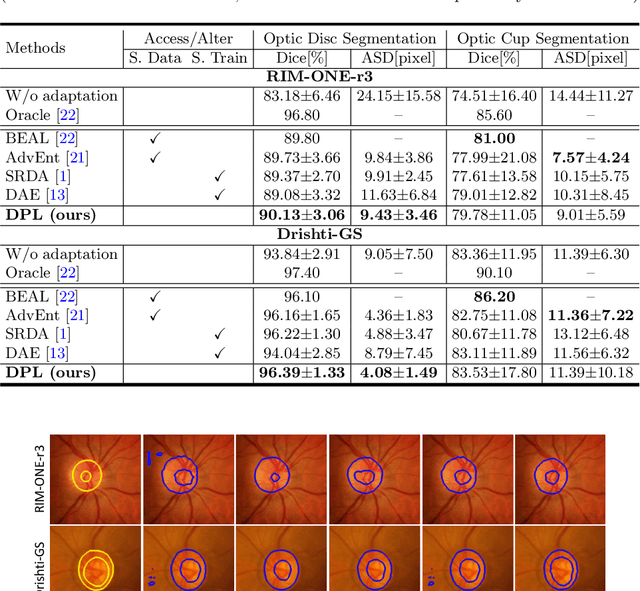

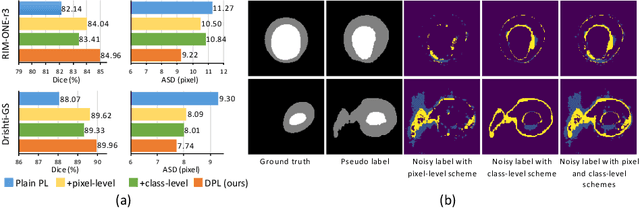
Domain adaptation typically requires to access source domain data to utilize their distribution information for domain alignment with the target data. However, in many real-world scenarios, the source data may not be accessible during the model adaptation in the target domain due to privacy issue. This paper studies the practical yet challenging source-free unsupervised domain adaptation problem, in which only an existing source model and the unlabeled target data are available for model adaptation. We present a novel denoised pseudo-labeling method for this problem, which effectively makes use of the source model and unlabeled target data to promote model self-adaptation from pseudo labels. Importantly, considering that the pseudo labels generated from source model are inevitably noisy due to domain shift, we further introduce two complementary pixel-level and class-level denoising schemes with uncertainty estimation and prototype estimation to reduce noisy pseudo labels and select reliable ones to enhance the pseudo-labeling efficacy. Experimental results on cross-domain fundus image segmentation show that without using any source images or altering source training, our approach achieves comparable or even higher performance than state-of-the-art source-dependent unsupervised domain adaptation methods.
HCDG: A Hierarchical Consistency Framework for Domain Generalization on Medical Image Segmentation
Sep 13, 2021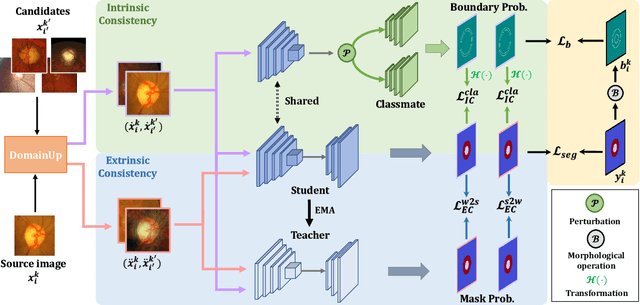
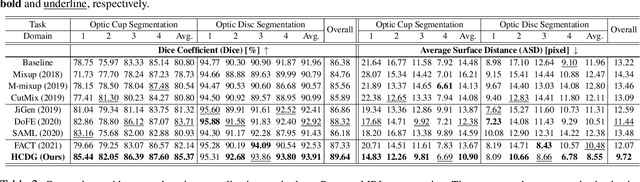
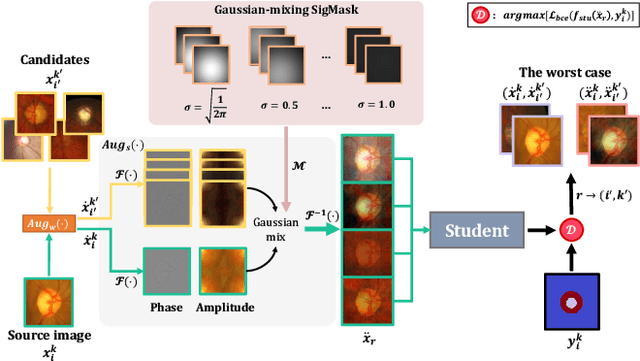
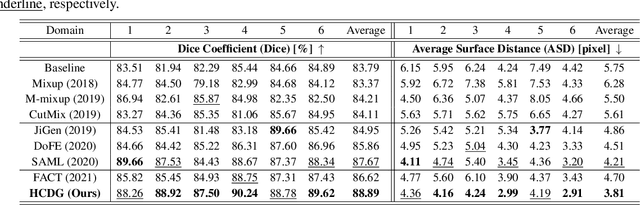
Modern deep neural networks struggle to transfer knowledge and generalize across domains when deploying to real-world applications. Domain generalization (DG) aims to learn a universal representation from multiple source domains to improve the network generalization ability on unseen target domains. Previous DG methods mostly focus on the data-level consistency scheme to advance the generalization capability of deep networks, without considering the synergistic regularization of different consistency schemes. In this paper, we present a novel Hierarchical Consistency framework for Domain Generalization (HCDG) by ensembling Extrinsic Consistency and Intrinsic Consistency. Particularly, for Extrinsic Consistency, we leverage the knowledge across multiple source domains to enforce data-level consistency. Also, we design a novel Amplitude Gaussian-mixing strategy for Fourier-based data augmentation to enhance such consistency. For Intrinsic Consistency, we perform task-level consistency for the same instance under the dual-task form. We evaluate the proposed HCDG framework on two medical image segmentation tasks, i.e., optic cup/disc segmentation on fundus images and prostate MRI segmentation. Extensive experimental results manifest the effectiveness and versatility of our HCDG framework. Code will be available once accept.
SurRoL: An Open-source Reinforcement Learning Centered and dVRK Compatible Platform for Surgical Robot Learning
Aug 30, 2021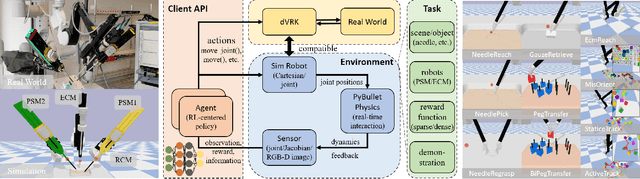
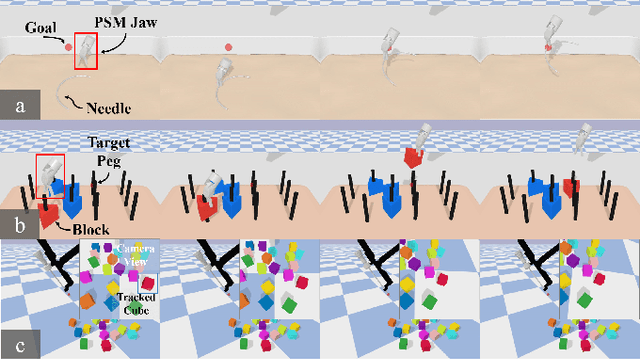
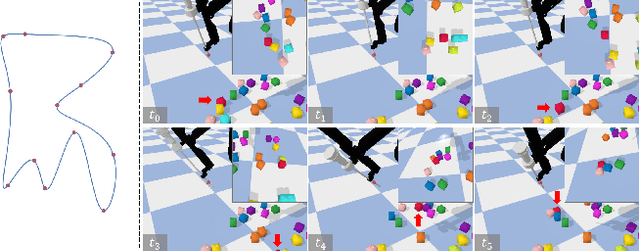
Autonomous surgical execution relieves tedious routines and surgeon's fatigue. Recent learning-based methods, especially reinforcement learning (RL) based methods, achieve promising performance for dexterous manipulation, which usually requires the simulation to collect data efficiently and reduce the hardware cost. The existing learning-based simulation platforms for medical robots suffer from limited scenarios and simplified physical interactions, which degrades the real-world performance of learned policies. In this work, we designed SurRoL, an RL-centered simulation platform for surgical robot learning compatible with the da Vinci Research Kit (dVRK). The designed SurRoL integrates a user-friendly RL library for algorithm development and a real-time physics engine, which is able to support more PSM/ECM scenarios and more realistic physical interactions. Ten learning-based surgical tasks are built in the platform, which are common in the real autonomous surgical execution. We evaluate SurRoL using RL algorithms in simulation, provide in-depth analysis, deploy the trained policies on the real dVRK, and show that our SurRoL achieves better transferability in the real world.