 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time landmark detection for precise endoscopic submucosal dissection via shape-aware relation network
Nov 08, 2021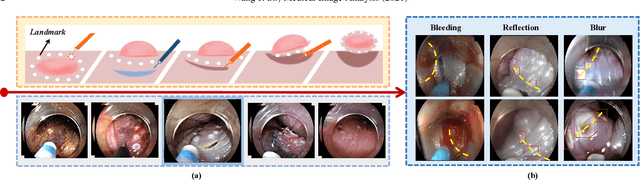
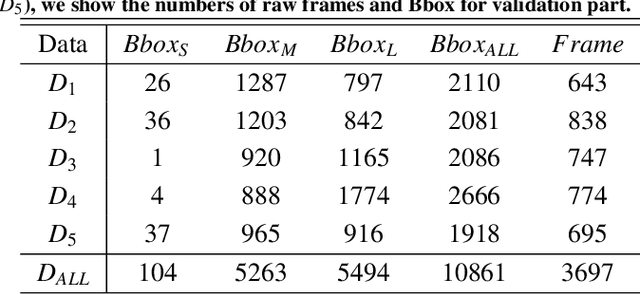
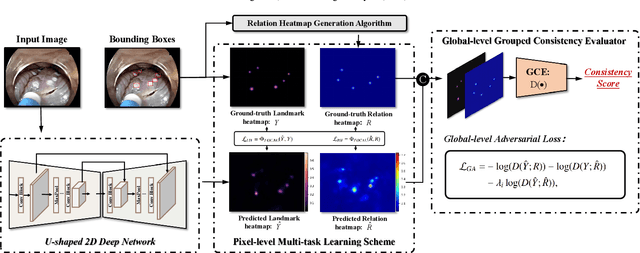
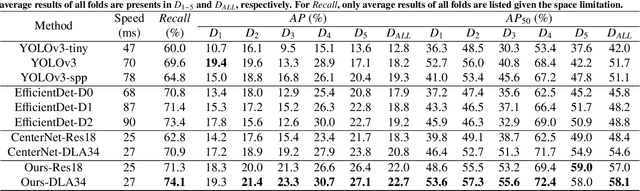
We propose a novel shape-aware relation network for accurate and real-time landmark detection in endoscopic submucosal dissection (ESD) surgery. This task is of great clinical significance but extremely challenging due to bleeding, lighting reflection, and motion blur in the complicated surgical environment. Compared with existing solutions, which either neglect geometric relationships among targeting objects or capture the relationships by using complicated aggregation schemes, the proposed network is capable of achieving satisfactory accuracy while maintaining real-time performance by taking full advantage of the spatial relations among landmarks. We first devise an algorithm to automatically generate relation keypoint heatmaps, which are able to intuitively represent the prior knowledge of spatial relations among landmarks without using any extra manual annotation efforts. We then develop two complementary regularization schemes to progressively incorporate the prior knowledge into the training process. While one scheme introduces pixel-level regularization by multi-task learning, the other integrates global-level regularization by harnessing a newly designed grouped consistency evaluator, which adds relation constraints to the proposed network in an adversarial manner. Both schemes are beneficial to the model in training, and can be readily unloaded in inference to achieve real-time detection. We establish a large in-house dataset of ESD surgery for esophageal cancer to validate the effectiveness of our proposed method. Extensive experimental results demonstrate that our approach outperforms state-of-the-art methods in terms of accuracy and efficiency, achieving better detection results faster. Promising results on two downstream applications further corroborate the great potential of our method in ESD clinical practice.
Efficient Global-Local Memory for Real-time Instrument Segmentation of Robotic Surgical Video
Sep 28, 2021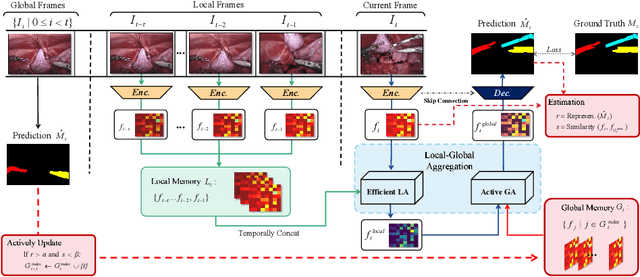
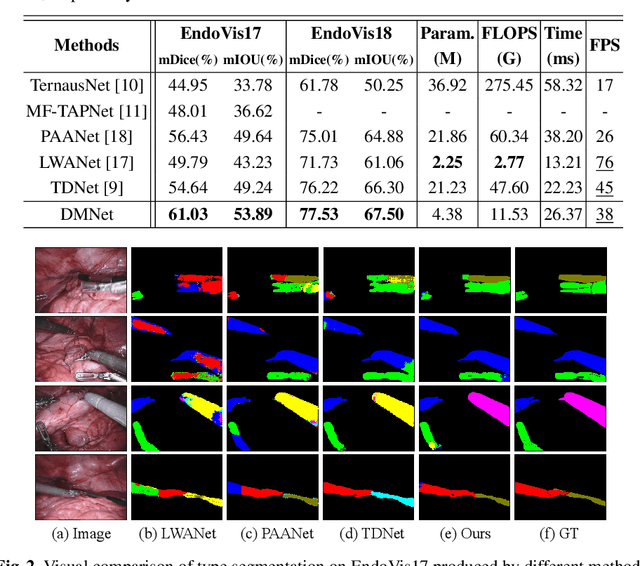
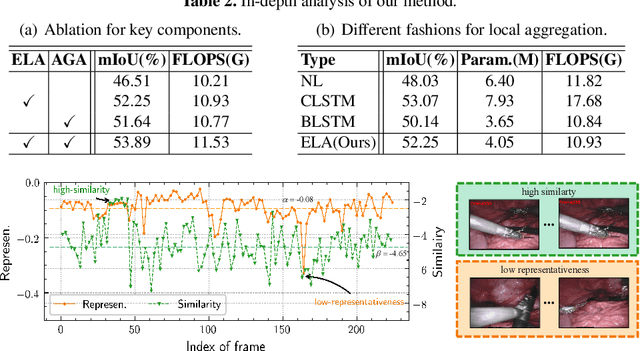
Performing a real-time and accurate instrument segmentation from videos is of great significance for improving the performance of robotic-assisted surgery. We identify two important clues for surgical instrument perception, including local temporal dependency from adjacent frames and global semantic correlation in long-range duration. However, most existing works perform segmentation purely using visual cues in a single frame. Optical flow is just used to model the motion between only two frames and brings heavy computational cost. We propose a novel dual-memory network (DMNet) to wisely relate both global and local spatio-temporal knowledge to augment the current features, boosting the segmentation performance and retaining the real-time prediction capability. We propose, on the one hand, an efficient local memory by taking the complementary advantages of convolutional LSTM and non-local mechanisms towards the relating reception field. On the other hand, we develop an active global memory to gather the global semantic correlation in long temporal range to current one, in which we gather the most informative frames derived from model uncertainty and frame similarity. We have extensively validated our method on two public benchmark surgical video datasets. Experimental results demonstrate that our method largely outperforms the state-of-the-art works on segmentation accuracy while maintaining a real-time speed.