 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCastling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference
Nov 18, 2022



Vision Transformers (ViTs) have shown impressive performance but still require a high computation cost as compared to convolutional neural networks (CNNs), due to the global similarity measurements and thus a quadratic complexity with the input tokens. Existing efficient ViTs adopt local attention (e.g., Swin) or linear attention (e.g., Performer), which sacrifice ViTs' capabilities of capturing either global or local context. In this work, we ask an important research question: Can ViTs learn both global and local context while being more efficient during inference? To this end, we propose a framework called Castling-ViT, which trains ViTs using both linear-angular attention and masked softmax-based quadratic attention, but then switches to having only linear angular attention during ViT inference. Our Castling-ViT leverages angular kernels to measure the similarities between queries and keys via spectral angles. And we further simplify it with two techniques: (1) a novel linear-angular attention mechanism: we decompose the angular kernels into linear terms and high-order residuals, and only keep the linear terms; and (2) we adopt two parameterized modules to approximate high-order residuals: a depthwise convolution and an auxiliary masked softmax attention to help learn both global and local information, where the masks for softmax attention are regularized to gradually become zeros and thus incur no overhead during ViT inference. Extensive experiments and ablation studies on three tasks consistently validate the effectiveness of the proposed Castling-ViT, e.g., achieving up to a 1.8% higher accuracy or 40% MACs reduction on ImageNet classification and 1.2 higher mAP on COCO detection under comparable FLOPs, as compared to ViTs with vanilla softmax-based attentions.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022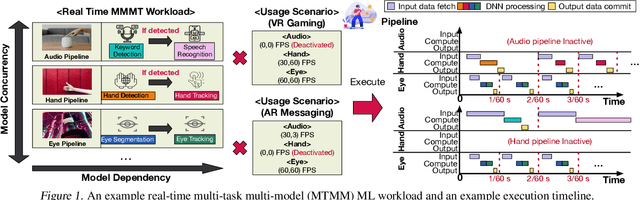
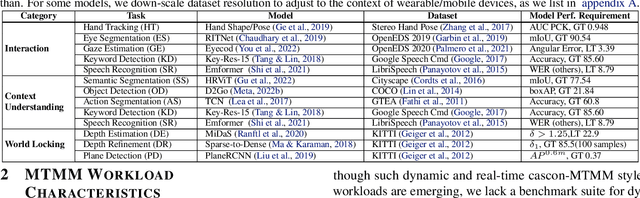

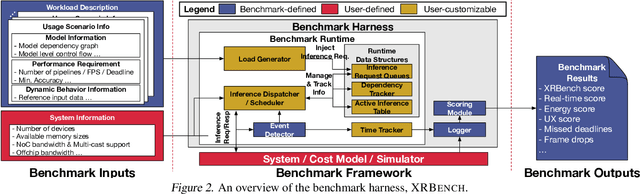
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.
3D-Aware Encoding for Style-based Neural Radiance Fields
Nov 12, 2022



We tackle the task of NeRF inversion for style-based neural radiance fields, (e.g., StyleNeRF). In the task, we aim to learn an inversion function to project an input image to the latent space of a NeRF generator and then synthesize novel views of the original image based on the latent code. Compared with GAN inversion for 2D generative models, NeRF inversion not only needs to 1) preserve the identity of the input image, but also 2) ensure 3D consistency in generated novel views. This requires the latent code obtained from the single-view image to be invariant across multiple views. To address this new challenge, we propose a two-stage encoder for style-based NeRF inversion. In the first stage, we introduce a base encoder that converts the input image to a latent code. To ensure the latent code is view-invariant and is able to synthesize 3D consistent novel view images, we utilize identity contrastive learning to train the base encoder. Second, to better preserve the identity of the input image, we introduce a refining encoder to refine the latent code and add finer details to the output image. Importantly note that the novelty of this model lies in the design of its first-stage encoder which produces the closest latent code lying on the latent manifold and thus the refinement in the second stage would be close to the NeRF manifold. Through extensive experiments, we demonstrate that our proposed two-stage encoder qualitatively and quantitatively exhibits superiority over the existing encoders for inversion in both image reconstruction and novel-view rendering.
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
Oct 09, 2022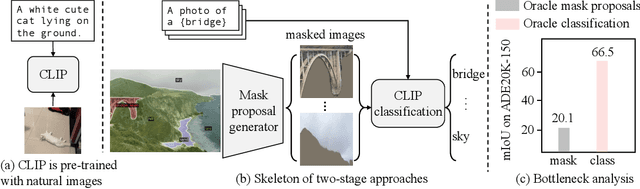
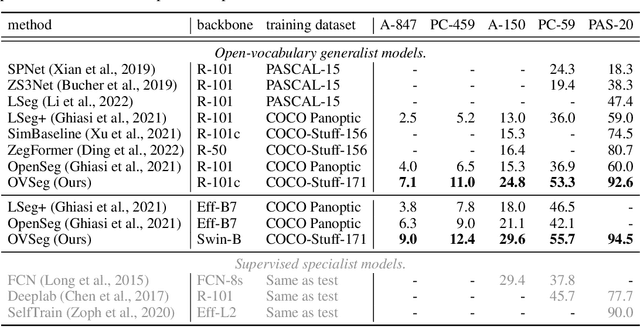
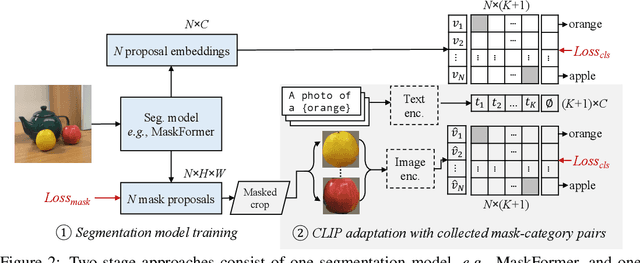
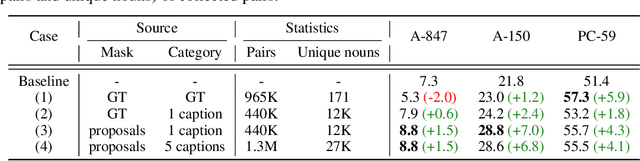
Open-vocabulary semantic segmentation aims to segment an image into semantic regions according to text descriptions, which may not have been seen during training. Recent two-stage methods first generate class-agnostic mask proposals and then leverage pre-trained vision-language models, e.g., CLIP, to classify masked regions. We identify the performance bottleneck of this paradigm to be the pre-trained CLIP model, since it does not perform well on masked images. To address this, we propose to finetune CLIP on a collection of masked image regions and their corresponding text descriptions. We collect training data by mining an existing image-caption dataset (e.g., COCO Captions), using CLIP to match masked image regions to nouns in the image captions. Compared with the more precise and manually annotated segmentation labels with fixed classes (e.g., COCO-Stuff), we find our noisy but diverse dataset can better retain CLIP's generalization ability. Along with finetuning the entire model, we utilize the "blank" areas in masked images using a method we dub mask prompt tuning. Experiments demonstrate mask prompt tuning brings significant improvement without modifying any weights of CLIP, and it can further improve a fully finetuned model. In particular, when trained on COCO and evaluated on ADE20K-150, our best model achieves 29.6% mIoU, which is +8.5% higher than the previous state-of-the-art. For the first time, open-vocabulary generalist models match the performance of supervised specialist models in 2017 without dataset-specific adaptations.
Open-Set Semi-Supervised Object Detection
Aug 29, 2022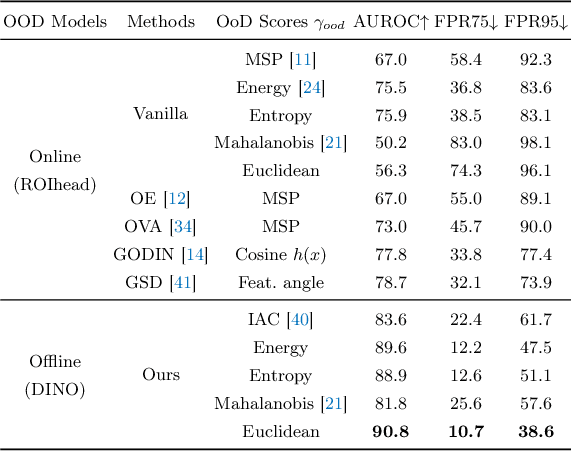



Recent developments for Semi-Supervised Object Detection (SSOD) have shown the promise of leveraging unlabeled data to improve an object detector. However, thus far these methods have assumed that the unlabeled data does not contain out-of-distribution (OOD) classes, which is unrealistic with larger-scale unlabeled datasets. In this paper, we consider a more practical yet challenging problem, Open-Set Semi-Supervised Object Detection (OSSOD). We first find the existing SSOD method obtains a lower performance gain in open-set conditions, and this is caused by the semantic expansion, where the distracting OOD objects are mispredicted as in-distribution pseudo-labels for the semi-supervised training. To address this problem, we consider online and offline OOD detection modules, which are integrated with SSOD methods. With the extensive studies, we found that leveraging an offline OOD detector based on a self-supervised vision transformer performs favorably against online OOD detectors due to its robustness to the interference of pseudo-labeling. In the experiment, our proposed framework effectively addresses the semantic expansion issue and shows consistent improvements on many OSSOD benchmarks, including large-scale COCO-OpenImages. We also verify the effectiveness of our framework under different OSSOD conditions, including varying numbers of in-distribution classes, different degrees of supervision, and different combinations of unlabeled sets.
Data Efficient Language-supervised Zero-shot Recognition with Optimal Transport Distillation
Dec 20, 2021



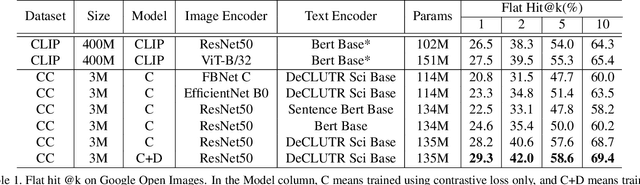
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use InfoNCE loss to train a model to predict the pairing between images and text captions. CLIP, however, is data hungry and requires more than 400M image-text pairs for training. The inefficiency can be partially attributed to the fact that the image-text pairs are noisy. To address this, we propose OTTER (Optimal TransporT distillation for Efficient zero-shot Recognition), which uses online entropic optimal transport to find a soft image-text match as labels for contrastive learning. Based on pretrained image and text encoders, models trained with OTTER achieve strong performance with only 3M image text pairs. Compared with InfoNCE loss, label smoothing, and knowledge distillation, OTTER consistently outperforms these baselines in zero shot evaluation on Google Open Images (19,958 classes) and multi-labeled ImageNet 10K (10032 classes) from Tencent ML-Images. Over 42 evaluations on 7 different dataset/architecture settings x 6 metrics, OTTER outperforms (32) or ties (2) all baselines in 34 of them.
FBNetV5: Neural Architecture Search for Multiple Tasks in One Run
Nov 30, 2021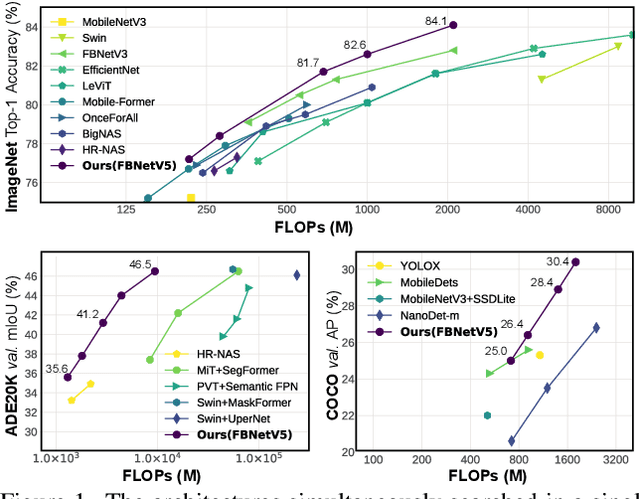
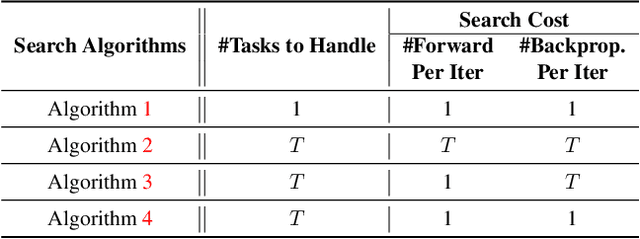
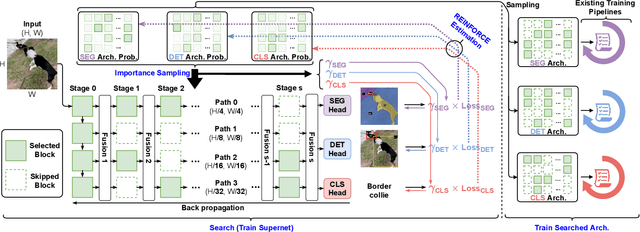
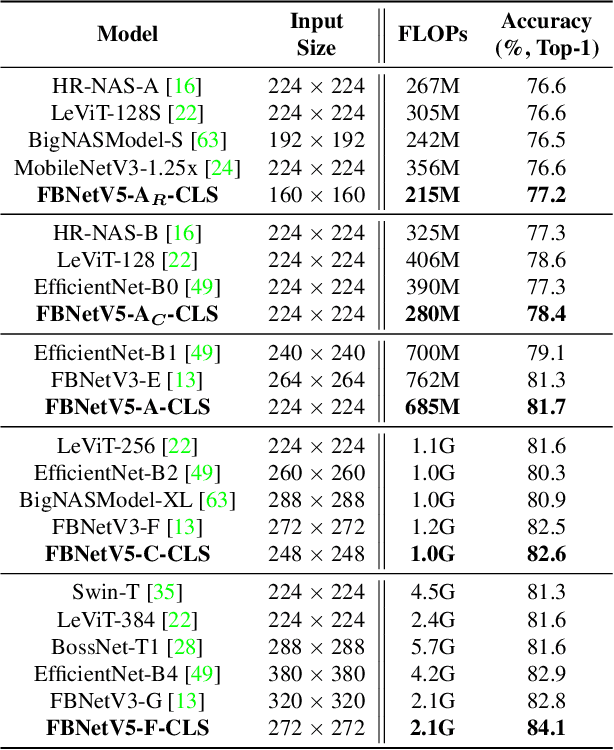
Neural Architecture Search (NAS) has been widely adopted to design accurate and efficient image classification models. However, applying NAS to a new computer vision task still requires a huge amount of effort. This is because 1) previous NAS research has been over-prioritized on image classification while largely ignoring other tasks; 2) many NAS works focus on optimizing task-specific components that cannot be favorably transferred to other tasks; and 3) existing NAS methods are typically designed to be "proxyless" and require significant effort to be integrated with each new task's training pipelines. To tackle these challenges, we propose FBNetV5, a NAS framework that can search for neural architectures for a variety of vision tasks with much reduced computational cost and human effort. Specifically, we design 1) a search space that is simple yet inclusive and transferable; 2) a multitask search process that is disentangled with target tasks' training pipeline; and 3) an algorithm to simultaneously search for architectures for multiple tasks with a computational cost agnostic to the number of tasks. We evaluate the proposed FBNetV5 targeting three fundamental vision tasks -- image classification, object detection, and semantic segmentation. Models searched by FBNetV5 in a single run of search have outperformed the previous stateof-the-art in all the three tasks: image classification (e.g., +1.3% ImageNet top-1 accuracy under the same FLOPs as compared to FBNetV3), semantic segmentation (e.g., +1.8% higher ADE20K val. mIoU than SegFormer with 3.6x fewer FLOPs), and object detection (e.g., +1.1% COCO val. mAP with 1.2x fewer FLOPs as compared to YOLOX).
Image2Point: 3D Point-Cloud Understanding with Pretrained 2D ConvNets
Jun 08, 2021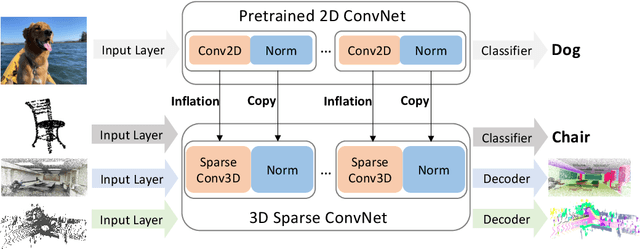
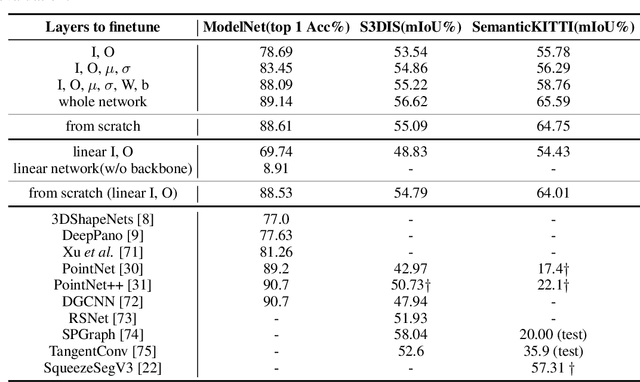


3D point-clouds and 2D images are different visual representations of the physical world. While human vision can understand both representations, computer vision models designed for 2D image and 3D point-cloud understanding are quite different. Our paper investigates the potential for transferability between these two representations by empirically investigating whether this approach works, what factors affect the transfer performance, and how to make it work even better. We discovered that we can indeed use the same neural net model architectures to understand both images and point-clouds. Moreover, we can transfer pretrained weights from image models to point-cloud models with minimal effort. Specifically, based on a 2D ConvNet pretrained on an image dataset, we can transfer the image model to a point-cloud model by \textit{inflating} 2D convolutional filters to 3D then finetuning its input, output, and optionally normalization layers. The transferred model can achieve competitive performance on 3D point-cloud classification, indoor and driving scene segmentation, even beating a wide range of point-cloud models that adopt task-specific architectures and use a variety of tricks.
Data-Efficient Language-Supervised Zero-Shot Learning with Self-Distillation
Apr 18, 2021
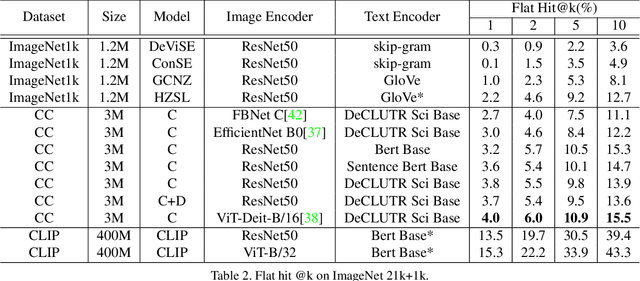
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use a simple pretraining task of predicting the pairings between images and text captions. CLIP, however, is data hungry and requires more than 400M image text pairs for training. We propose a data-efficient contrastive distillation method that uses soft labels to learn from noisy image-text pairs. Our model transfers knowledge from pretrained image and sentence encoders and achieves strong performance with only 3M image text pairs, 133x smaller than CLIP. Our method exceeds the previous SoTA of general zero-shot learning on ImageNet 21k+1k by 73% relatively with a ResNet50 image encoder and DeCLUTR text encoder. We also beat CLIP by 10.5% relatively on zero-shot evaluation on Google Open Images (19,958 classes).
You Only Group Once: Efficient Point-Cloud Processing with Token Representation and Relation Inference Module
Mar 24, 2021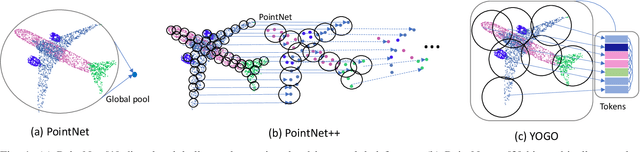
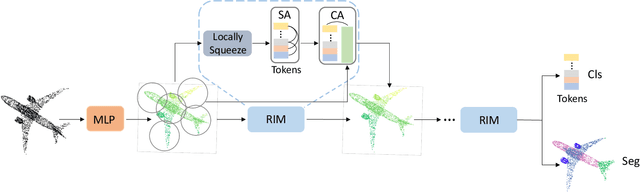
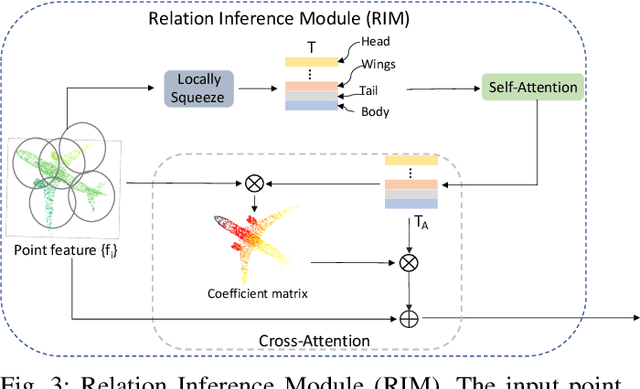
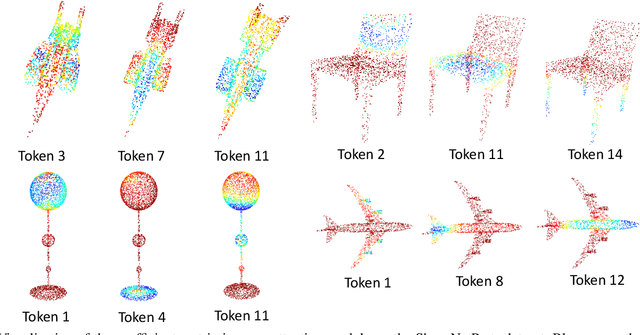
3D point-cloud-based perception is a challenging but crucial computer vision task. A point-cloud consists of a sparse, unstructured, and unordered set of points. To understand a point-cloud, previous point-based methods, such as PointNet++, extract visual features through hierarchically aggregation of local features. However, such methods have several critical limitations: 1) Such methods require several sampling and grouping operations, which slow down the inference speed. 2) Such methods spend an equal amount of computation on each points in a point-cloud, though many of points are redundant. 3) Such methods aggregate local features together through downsampling, which leads to information loss and hurts the perception performance. To overcome these challenges, we propose a novel, simple, and elegant deep learning model called YOGO (You Only Group Once). Compared with previous methods, YOGO only needs to sample and group a point-cloud once, so it is very efficient. Instead of operating on points, YOGO operates on a small number of tokens, each of which summarizes the point features in a sub-region. This allows us to avoid computing on the redundant points and thus boosts efficiency.Moreover, YOGO preserves point-wise features by projecting token features to point features although the computation is performed on tokens. This avoids information loss and can improve point-wise perception performance. We conduct thorough experiments to demonstrate that YOGO achieves at least 3.0x speedup over point-based baselines while delivering competitive classification and segmentation performance on the ModelNet, ShapeNetParts and S3DIS datasets.