 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBWave: Efficient and Scalable Neural Vocoders for Streaming Text-To-Speech on the Edge
Paper and Code
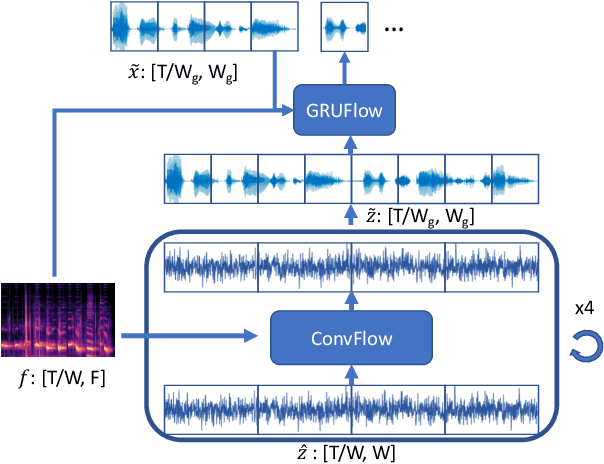
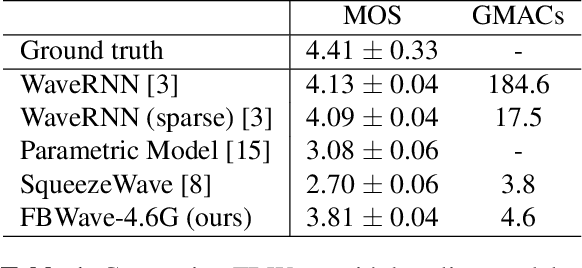
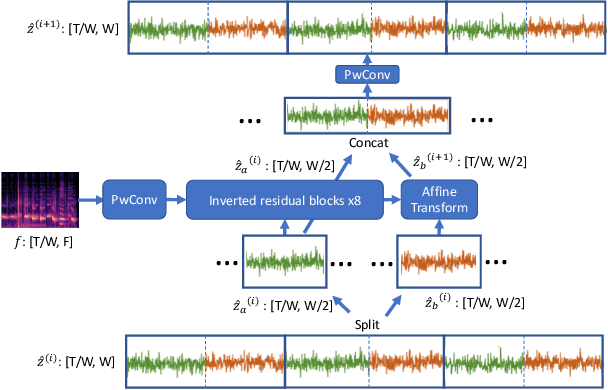

Nowadays more and more applications can benefit from edge-based text-to-speech (TTS). However, most existing TTS models are too computationally expensive and are not flexible enough to be deployed on the diverse variety of edge devices with their equally diverse computational capacities. To address this, we propose FBWave, a family of efficient and scalable neural vocoders that can achieve optimal performance-efficiency trade-offs for different edge devices. FBWave is a hybrid flow-based generative model that combines the advantages of autoregressive and non-autoregressive models. It produces high quality audio and supports streaming during inference while remaining highly computationally efficient. Our experiments show that FBWave can achieve similar audio quality to WaveRNN while reducing MACs by 40x. More efficient variants of FBWave can achieve up to 109x fewer MACs while still delivering acceptable audio quality. Audio demos are available at https://bichenwu09.github.io/vocoder_demos.