 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Transformers: Token-based Image Representation and Processing for Computer Vision
Paper and Code
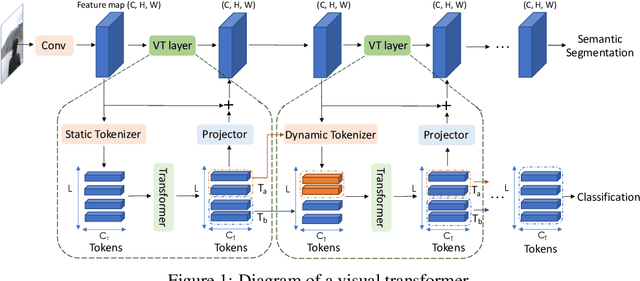
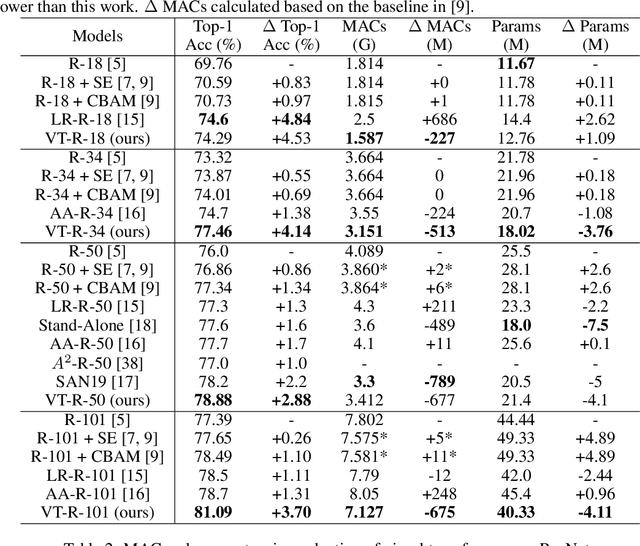
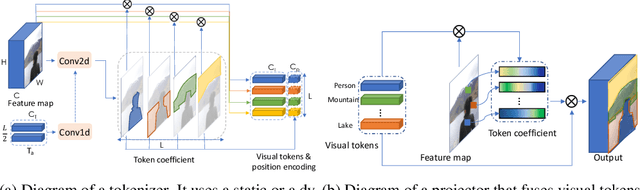

Computer vision has achieved great success using standardized image representations -- pixel arrays, and the corresponding deep learning operators -- convolutions. In this work, we challenge this paradigm: we instead (a) represent images as a set of visual tokens and (b) apply visual transformers to find relationships between visual semantic concepts. Given an input image, we dynamically extract a set of visual tokens from the image to obtain a compact representation for high-level semantics. We then use visual transformers to operate over the visual tokens to densely model relationships between them. We find that this paradigm of token-based image representation and processing drastically outperforms its convolutional counterparts on image classification and semantic segmentation. To demonstrate the power of this approach on ImageNet classification, we use ResNet as a convenient baseline and use visual transformers to replace the last stage of convolutions. This reduces the stage's MACs by up to 6.9x, while attaining up to 4.53 points higher top-1 accuracy. For semantic segmentation, we use a visual-transformer-based FPN (VT-FPN) module to replace a convolution-based FPN, saving 6.5x fewer MACs while achieving up to 0.35 points higher mIoU on LIP and COCO-stuff.