 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Perceptual Hallucination for Multi-Robot Navigation in Narrow Hallways
Sep 27, 2022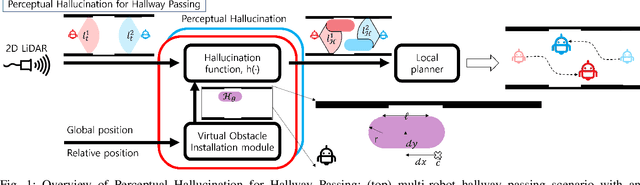
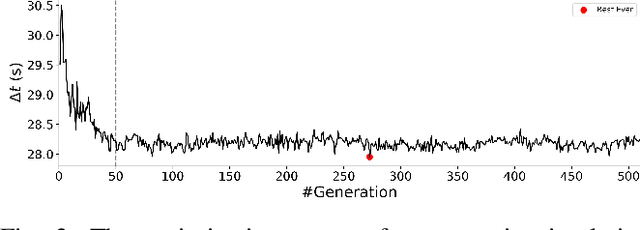
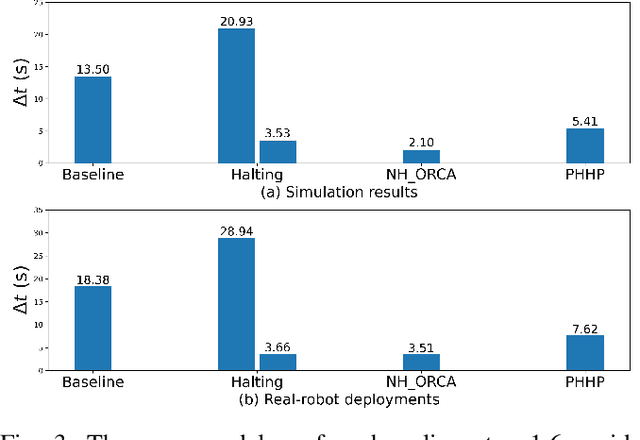
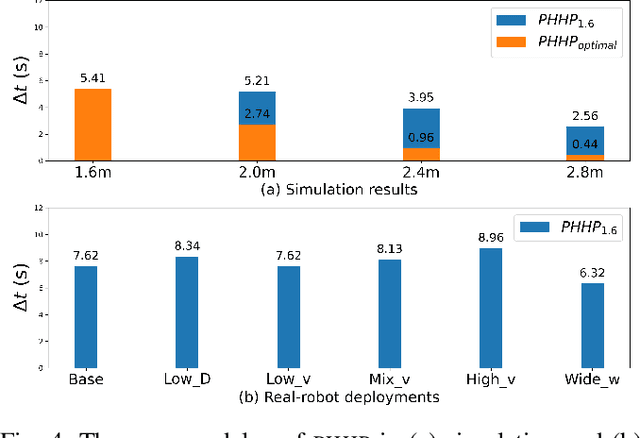
While current systems for autonomous robot navigation can produce safe and efficient motion plans in static environments, they usually generate suboptimal behaviors when multiple robots must navigate together in confined spaces. For example, when two robots meet each other in a narrow hallway, they may either turn around to find an alternative route or collide with each other. This paper presents a new approach to navigation that allows two robots to pass each other in a narrow hallway without colliding, stopping, or waiting. Our approach, Perceptual Hallucination for Hallway Passing (PHHP), learns to synthetically generate virtual obstacles (i.e., perceptual hallucination) to facilitate passing in narrow hallways by multiple robots that utilize otherwise standard autonomous navigation systems. Our experiments on physical robots in a variety of hallways show improved performance compared to multiple baselines.
BOME! Bilevel Optimization Made Easy: A Simple First-Order Approach
Sep 19, 2022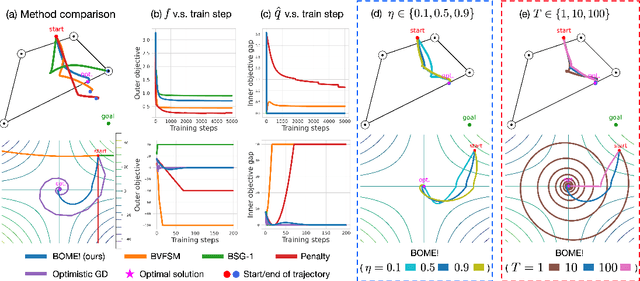
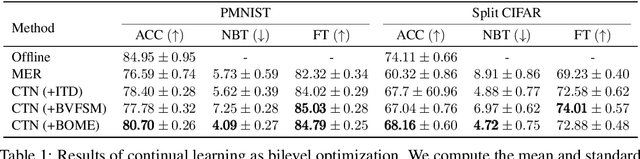
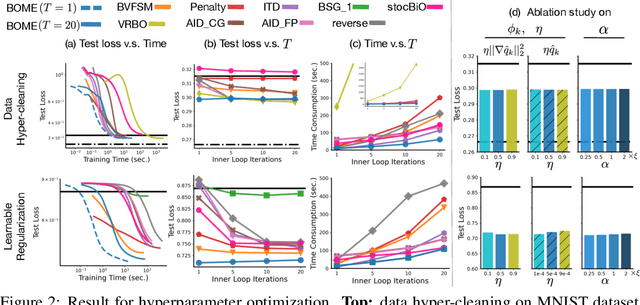
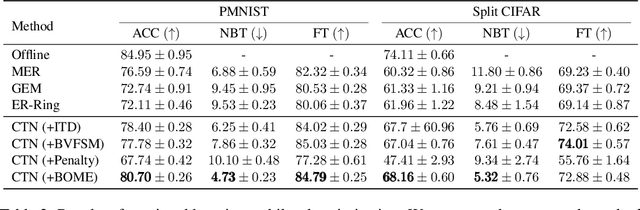
Bilevel optimization (BO) is useful for solving a variety of important machine learning problems including but not limited to hyperparameter optimization, meta-learning, continual learning, and reinforcement learning. Conventional BO methods need to differentiate through the low-level optimization process with implicit differentiation, which requires expensive calculations related to the Hessian matrix. There has been a recent quest for first-order methods for BO, but the methods proposed to date tend to be complicated and impractical for large-scale deep learning applications. In this work, we propose a simple first-order BO algorithm that depends only on first-order gradient information, requires no implicit differentiation, and is practical and efficient for large-scale non-convex functions in deep learning. We provide non-asymptotic convergence analysis of the proposed method to stationary points for non-convex objectives and present empirical results that show its superior practical performance.
Autonomous Ground Navigation in Highly Constrained Spaces: Lessons learned from The BARN Challenge at ICRA 2022
Aug 22, 2022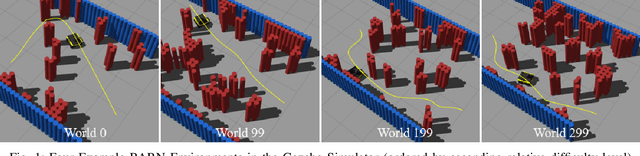


The BARN (Benchmark Autonomous Robot Navigation) Challenge took place at the 2022 IEEE International Conference on Robotics and Automation (ICRA 2022) in Philadelphia, PA. The aim of the challenge was to evaluate state-of-the-art autonomous ground navigation systems for moving robots through highly constrained environments in a safe and efficient manner. Specifically, the task was to navigate a standardized, differential-drive ground robot from a predefined start location to a goal location as quickly as possible without colliding with any obstacles, both in simulation and in the real world. Five teams from all over the world participated in the qualifying simulation competition, three of which were invited to compete with each other at a set of physical obstacle courses at the conference center in Philadelphia. The competition results suggest that autonomous ground navigation in highly constrained spaces, despite seeming ostensibly simple even for experienced roboticists, is actually far from being a solved problem. In this article, we discuss the challenge, the approaches used by the top three winning teams, and lessons learned to direct future research.
Metric Residual Networks for Sample Efficient Goal-conditioned Reinforcement Learning
Aug 17, 2022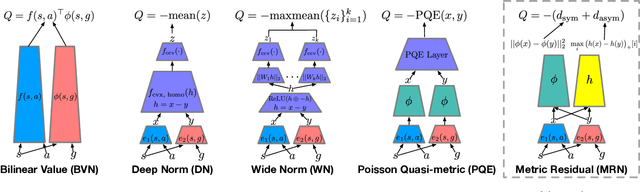
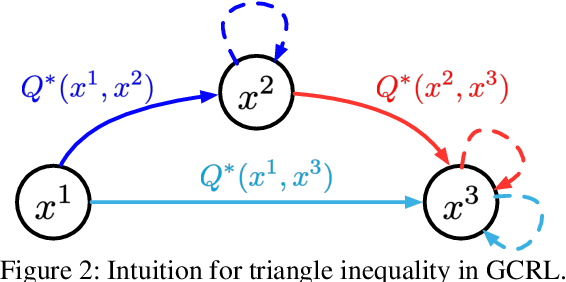
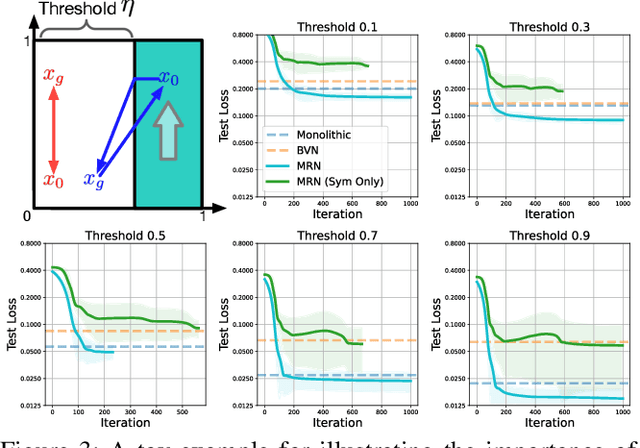
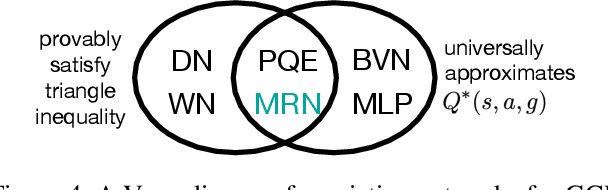
Goal-conditioned reinforcement learning (GCRL) has a wide range of potential real-world applications, including manipulation and navigation problems in robotics. Especially in such robotics task, sample efficiency is of the utmost importance for GCRL since, by default, the agent is only rewarded when it reaches its goal. While several methods have been proposed to improve the sample efficiency of GCRL, one relatively under-studied approach is the design of neural architectures to support sample efficiency. In this work, we introduce a novel neural architecture for GCRL that achieves significantly better sample efficiency than the commonly-used monolithic network architecture. They key insight is that the optimal action value function Q^*(s, a, g) must satisfy the triangle inequality in a specific sense. Furthermore, we introduce the metric residual network (MRN) that deliberately decomposes the action-value function Q(s,a,g) into the negated summation of a metric plus a residual asymmetric component. MRN provably approximates any optimal action-value function Q^*(s,a,g), thus making it a fitting neural architecture for GCRL. We conduct comprehensive experiments across 12 standard benchmark environments in GCRL. The empirical results demonstrate that MRN uniformly outperforms other state-of-the-art GCRL neural architectures in terms of sample efficiency.
Causal Dynamics Learning for Task-Independent State Abstraction
Jun 27, 2022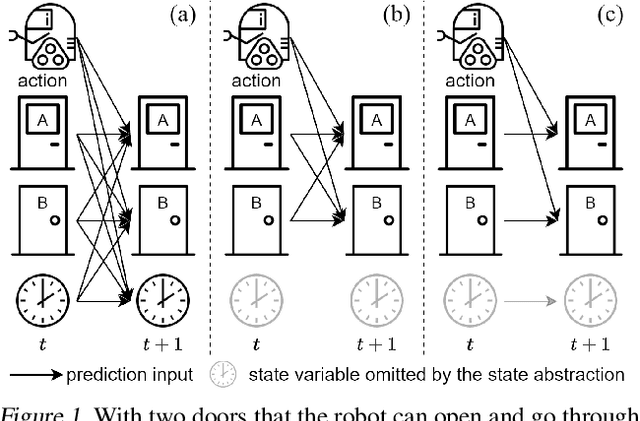
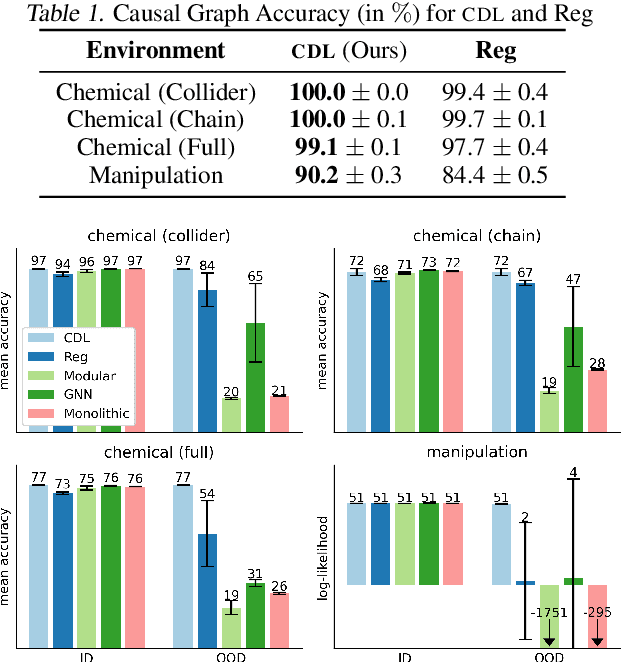
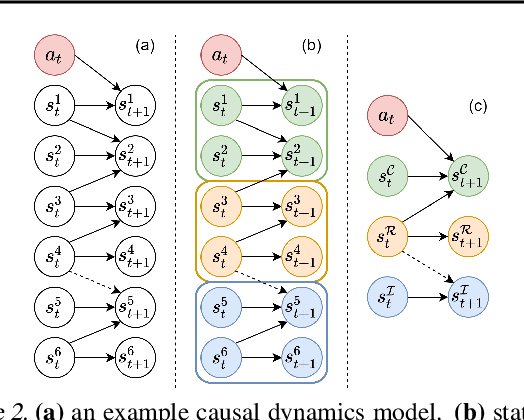

Learning dynamics models accurately is an important goal for Model-Based Reinforcement Learning (MBRL), but most MBRL methods learn a dense dynamics model which is vulnerable to spurious correlations and therefore generalizes poorly to unseen states. In this paper, we introduce Causal Dynamics Learning for Task-Independent State Abstraction (CDL), which first learns a theoretically proved causal dynamics model that removes unnecessary dependencies between state variables and the action, thus generalizing well to unseen states. A state abstraction can then be derived from the learned dynamics, which not only improves sample efficiency but also applies to a wider range of tasks than existing state abstraction methods. Evaluated on two simulated environments and downstream tasks, both the dynamics model and policies learned by the proposed method generalize well to unseen states and the derived state abstraction improves sample efficiency compared to learning without it.
Value Function Decomposition for Iterative Design of Reinforcement Learning Agents
Jun 24, 2022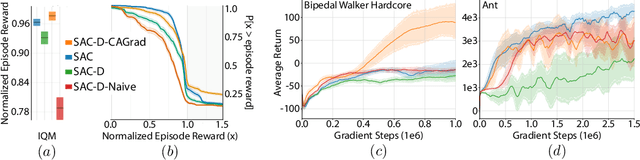

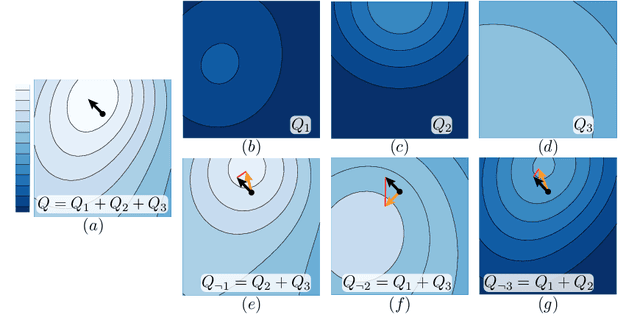

Designing reinforcement learning (RL) agents is typically a difficult process that requires numerous design iterations. Learning can fail for a multitude of reasons, and standard RL methods provide too few tools to provide insight into the exact cause. In this paper, we show how to integrate value decomposition into a broad class of actor-critic algorithms and use it to assist in the iterative agent-design process. Value decomposition separates a reward function into distinct components and learns value estimates for each. These value estimates provide insight into an agent's learning and decision-making process and enable new training methods to mitigate common problems. As a demonstration, we introduce SAC-D, a variant of soft actor-critic (SAC) adapted for value decomposition. SAC-D maintains similar performance to SAC, while learning a larger set of value predictions. We also introduce decomposition-based tools that exploit this information, including a new reward influence metric, which measures each reward component's effect on agent decision-making. Using these tools, we provide several demonstrations of decomposition's use in identifying and addressing problems in the design of both environments and agents. Value decomposition is broadly applicable and easy to incorporate into existing algorithms and workflows, making it a powerful tool in an RL practitioner's toolbox.
High-Speed Accurate Robot Control using Learned Forward Kinodynamics and Non-linear Least Squares Optimization
Jun 16, 2022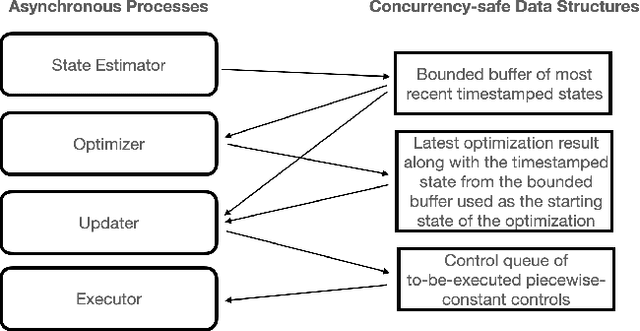
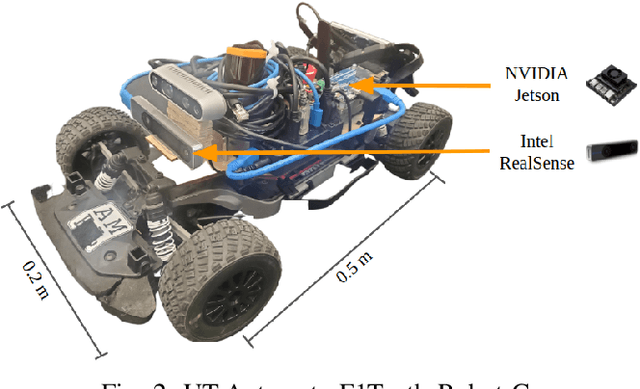
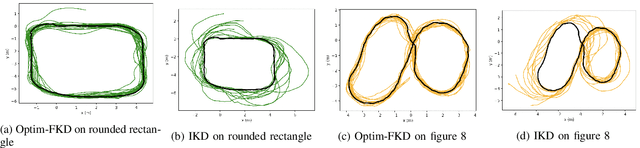
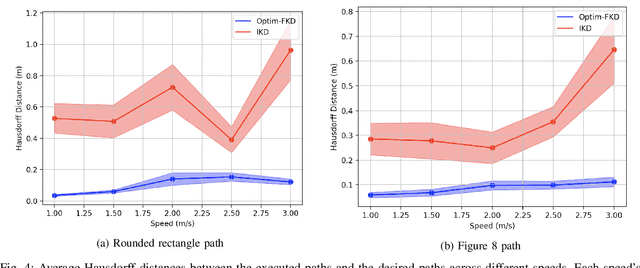
Accurate control of robots in the real world requires a control system that is capable of taking into account the kinodynamic interactions of the robot with its environment. At high speeds, the dependence of the movement of the robot on these kinodynamic interactions becomes more pronounced, making high-speed, accurate robot control a challenging problem. Previous work has shown that learning the inverse kinodynamics (IKD) of the robot can be helpful for high-speed robot control. However a learned inverse kinodynamic model can only be applied to a limited class of control problems, and different control problems require the learning of a new IKD model. In this work we present a new formulation for accurate, high-speed robot control that makes use of a learned forward kinodynamic (FKD) model and non-linear least squares optimization. By nature of the formulation, this approach is extensible to a wide array of control problems without requiring the retraining of a new model. We demonstrate the ability of this approach to accurately control a scale one-tenth robot car at high speeds, and show improved results over baselines.
Models of human preference for learning reward functions
Jun 05, 2022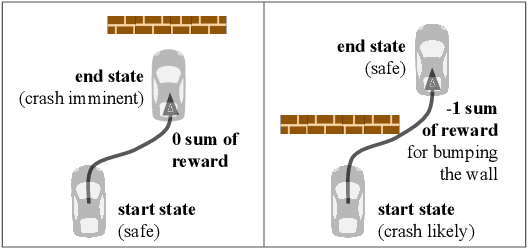
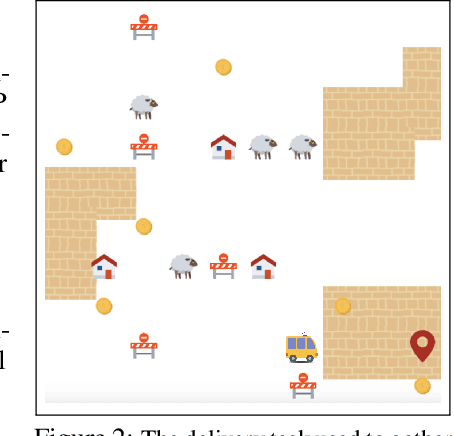
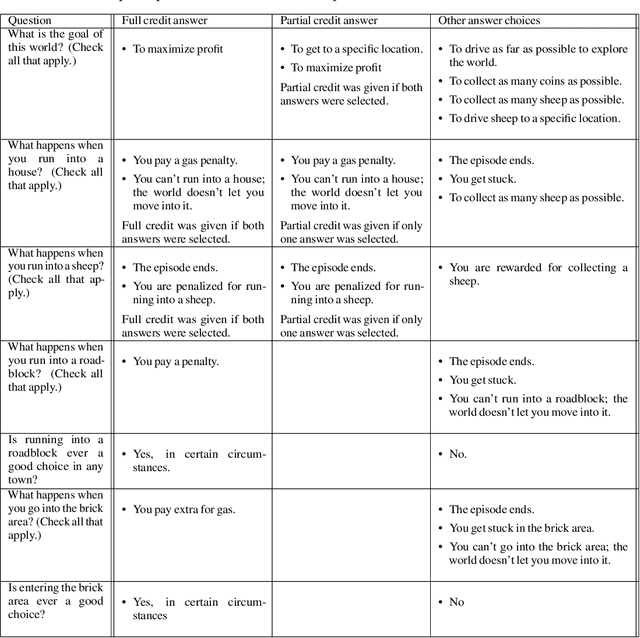
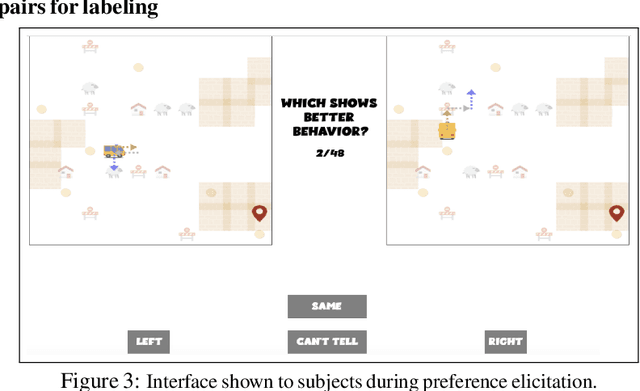
The utility of reinforcement learning is limited by the alignment of reward functions with the interests of human stakeholders. One promising method for alignment is to learn the reward function from human-generated preferences between pairs of trajectory segments. These human preferences are typically assumed to be informed solely by partial return, the sum of rewards along each segment. We find this assumption to be flawed and propose modeling preferences instead as arising from a different statistic: each segment's regret, a measure of a segment's deviation from optimal decision-making. Given infinitely many preferences generated according to regret, we prove that we can identify a reward function equivalent to the reward function that generated those preferences. We also prove that the previous partial return model lacks this identifiability property without preference noise that reveals rewards' relative proportions, and we empirically show that our proposed regret preference model outperforms it with finite training data in otherwise the same setting. Additionally, our proposed regret preference model better predicts real human preferences and also learns reward functions from these preferences that lead to policies that are better human-aligned. Overall, this work establishes that the choice of preference model is impactful, and our proposed regret preference model provides an improvement upon a core assumption of recent research.
DM$^2$: Distributed Multi-Agent Reinforcement Learning for Distribution Matching
Jun 01, 2022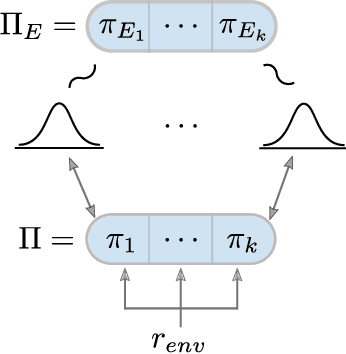

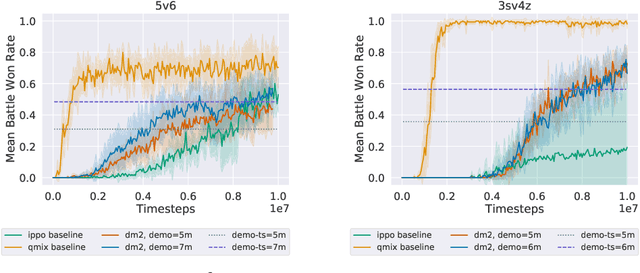
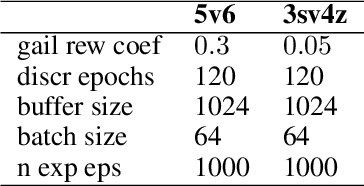
Current approaches to multi-agent cooperation rely heavily on centralized mechanisms or explicit communication protocols to ensure convergence. This paper studies the problem of distributed multi-agent learning without resorting to explicit coordination schemes. The proposed algorithm (DM$^2$) leverages distribution matching to facilitate independent agents' coordination. Each individual agent matches a target distribution of concurrently sampled trajectories from a joint expert policy. The theoretical analysis shows that under some conditions, if each agent optimizes their individual distribution matching objective, the agents increase a lower bound on the objective of matching the joint expert policy, allowing convergence to the joint expert policy. Further, if the distribution matching objective is aligned with a joint task, a combination of environment reward and distribution matching reward leads to the same equilibrium. Experimental validation on the StarCraft domain shows that combining the reward for distribution matching with the environment reward allows agents to outperform a fully distributed baseline. Additional experiments probe the conditions under which expert demonstrations need to be sampled in order to outperform the fully distributed baseline.
COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles
May 04, 2022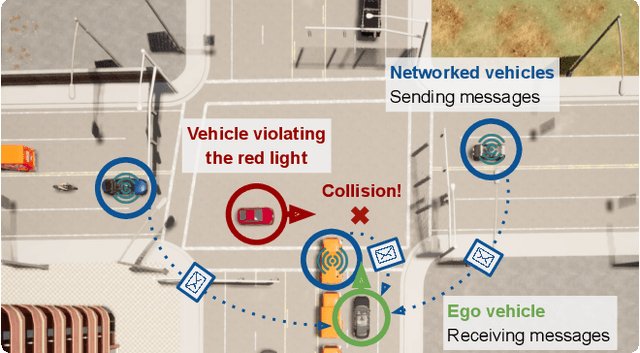

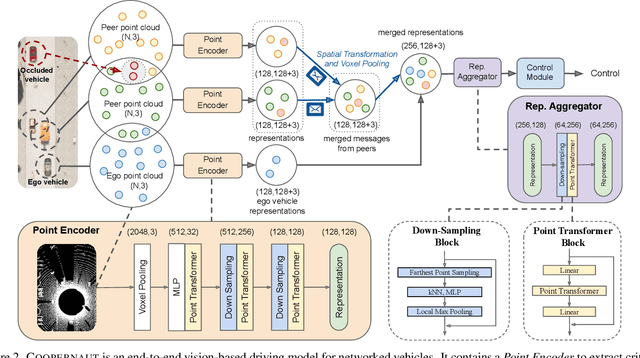

Optical sensors and learning algorithms for autonomous vehicles have dramatically advanced in the past few years. Nonetheless, the reliability of today's autonomous vehicles is hindered by the limited line-of-sight sensing capability and the brittleness of data-driven methods in handling extreme situations. With recent developments of telecommunication technologies, cooperative perception with vehicle-to-vehicle communications has become a promising paradigm to enhance autonomous driving in dangerous or emergency situations. We introduce COOPERNAUT, an end-to-end learning model that uses cross-vehicle perception for vision-based cooperative driving. Our model encodes LiDAR information into compact point-based representations that can be transmitted as messages between vehicles via realistic wireless channels. To evaluate our model, we develop AutoCastSim, a network-augmented driving simulation framework with example accident-prone scenarios. Our experiments on AutoCastSim suggest that our cooperative perception driving models lead to a 40% improvement in average success rate over egocentric driving models in these challenging driving situations and a 5 times smaller bandwidth requirement than prior work V2VNet. COOPERNAUT and AUTOCASTSIM are available at https://ut-austin-rpl.github.io/Coopernaut/.