 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Reinforcement Learning for Behavioral Action Support in Type 1 Diabetes
Apr 01, 2026Type 1 Diabetes (T1D) management requires continuous adjustment of insulin and lifestyle behaviors to maintain blood glucose within a safe target range. Although automated insulin delivery (AID) systems have improved glycemic outcomes, many patients still fail to achieve recommended clinical targets, warranting new approaches to improve glucose control in patients with T1D. While reinforcement learning (RL) has been utilized as a promising approach, current RL-based methods focus primarily on insulin-only treatment and do not provide behavioral recommendations for glucose control. To address this gap, we propose GUIDE, an RL-based decision-support framework designed to complement AID technologies by providing behavioral recommendations to prevent abnormal glucose events. GUIDE generates structured actions defined by intervention type, magnitude, and timing, including bolus insulin administration and carbohydrate intake events. GUIDE integrates a patient-specific glucose level predictor trained on real-world continuous glucose monitoring data and supports both offline and online RL algorithms within a unified environment. We evaluate both off-policy and on-policy methods across 25 individuals with T1D using standardized glycemic metrics. Among the evaluated approaches, the CQL-BC algorithm demonstrates the highest average time-in-range, reaching 85.49% while maintaining low hypoglycemia exposures. Behavioral similarity analysis further indicates that the learned CQL-BC policy preserves key structural characteristics of patient action patterns, achieving a mean cosine similarity of 0.87 $\pm$ 0.09 across subjects. These findings suggest that conservative offline RL with a structured behavioral action space can provide clinically meaningful and behaviorally plausible decision support for personalized diabetes management.
Harmful Traits of AI Companions
Nov 18, 2025
Amid the growing prevalence of human -- AI interaction, large language models and other AI-based entities increasingly provide forms of companionship to human users. Such AI companionship -- i.e., bonded relationships between humans and AI systems that resemble the relationships people have with family members, friends, and romantic partners -- might substantially benefit humans. Yet such relationships can also do profound harm. We propose a framework for analyzing potential negative impacts of AI companionship by identifying specific harmful traits of AI companions and speculatively mapping causal pathways back from these traits to possible causes and forward to potential harmful effects. We provide detailed, structured analysis of four potentially harmful traits -- the absence of natural endpoints for relationships, vulnerability to product sunsetting, high attachment anxiety, and propensity to engender protectiveness -- and briefly discuss fourteen others. For each trait, we propose hypotheses connecting causes -- such as misaligned optimization objectives and the digital nature of AI companions -- to fundamental harms -- including reduced autonomy, diminished quality of human relationships, and deception. Each hypothesized causal connection identifies a target for potential empirical evaluation. Our analysis examines harms at three levels: to human partners directly, to their relationships with other humans, and to society broadly. We examine how existing law struggles to address these emerging harms, discuss potential benefits of AI companions, and conclude with design recommendations for mitigating risks. This analysis offers immediate suggestions for reducing risks while laying a foundation for deeper investigation of this critical but understudied topic.
State Your Intention to Steer Your Attention: An AI Assistant for Intentional Digital Living
Oct 16, 2025When working on digital devices, people often face distractions that can lead to a decline in productivity and efficiency, as well as negative psychological and emotional impacts. To address this challenge, we introduce a novel Artificial Intelligence (AI) assistant that elicits a user's intention, assesses whether ongoing activities are in line with that intention, and provides gentle nudges when deviations occur. The system leverages a large language model to analyze screenshots, application titles, and URLs, issuing notifications when behavior diverges from the stated goal. Its detection accuracy is refined through initial clarification dialogues and continuous user feedback. In a three-week, within-subjects field deployment with 22 participants, we compared our assistant to both a rule-based intent reminder system and a passive baseline that only logged activity. Results indicate that our AI assistant effectively supports users in maintaining focus and aligning their digital behavior with their intentions. Our source code is publicly available at this url https://intentassistant.github.io
CTRL-Rec: Controlling Recommender Systems With Natural Language
Oct 14, 2025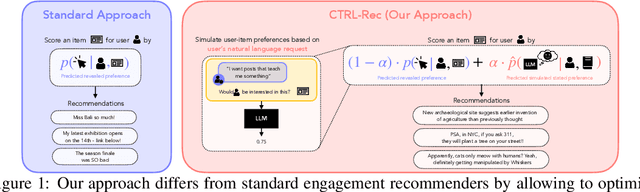


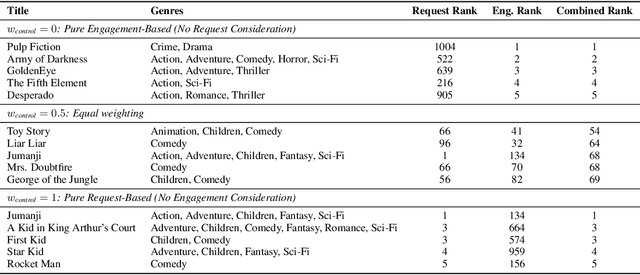
When users are dissatisfied with recommendations from a recommender system, they often lack fine-grained controls for changing them. Large language models (LLMs) offer a solution by allowing users to guide their recommendations through natural language requests (e.g., "I want to see respectful posts with a different perspective than mine"). We propose a method, CTRL-Rec, that allows for natural language control of traditional recommender systems in real-time with computational efficiency. Specifically, at training time, we use an LLM to simulate whether users would approve of items based on their language requests, and we train embedding models that approximate such simulated judgments. We then integrate these user-request-based predictions into the standard weighting of signals that traditional recommender systems optimize. At deployment time, we require only a single LLM embedding computation per user request, allowing for real-time control of recommendations. In experiments with the MovieLens dataset, our method consistently allows for fine-grained control across a diversity of requests. In a study with 19 Letterboxd users, we find that CTRL-Rec was positively received by users and significantly enhanced users' sense of control and satisfaction with recommendations compared to traditional controls.
Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Mar 08, 2025



Reinforcement learning agents are fundamentally limited by the quality of the reward functions they learn from, yet reward design is often overlooked under the assumption that a well-defined reward is readily available. However, in practice, designing rewards is difficult, and even when specified, evaluating their correctness is equally problematic: how do we know if a reward function is correctly specified? In our work, we address these challenges by focusing on reward alignment -- assessing whether a reward function accurately encodes the preferences of a human stakeholder. As a concrete measure of reward alignment, we introduce the Trajectory Alignment Coefficient to quantify the similarity between a human stakeholder's ranking of trajectory distributions and those induced by a given reward function. We show that the Trajectory Alignment Coefficient exhibits desirable properties, such as not requiring access to a ground truth reward, invariance to potential-based reward shaping, and applicability to online RL. Additionally, in an 11 -- person user study of RL practitioners, we found that access to the Trajectory Alignment Coefficient during reward selection led to statistically significant improvements. Compared to relying only on reward functions, our metric reduced cognitive workload by 1.5x, was preferred by 82% of users and increased the success rate of selecting reward functions that produced performant policies by 41%.
Influencing Humans to Conform to Preference Models for RLHF
Jan 11, 2025



Designing a reinforcement learning from human feedback (RLHF) algorithm to approximate a human's unobservable reward function requires assuming, implicitly or explicitly, a model of human preferences. A preference model that poorly describes how humans generate preferences risks learning a poor approximation of the human's reward function. In this paper, we conduct three human studies to asses whether one can influence the expression of real human preferences to more closely conform to a desired preference model. Importantly, our approach does not seek to alter the human's unobserved reward function. Rather, we change how humans use this reward function to generate preferences, such that they better match whatever preference model is assumed by a particular RLHF algorithm. We introduce three interventions: showing humans the quantities that underlie a preference model, which is normally unobservable information derived from the reward function; training people to follow a specific preference model; and modifying the preference elicitation question. All intervention types show significant effects, providing practical tools to improve preference data quality and the resultant alignment of the learned reward functions. Overall we establish a novel research direction in model alignment: designing interfaces and training interventions to increase human conformance with the modeling assumptions of the algorithm that will learn from their input.
MobileSafetyBench: Evaluating Safety of Autonomous Agents in Mobile Device Control
Oct 23, 2024



Autonomous agents powered by large language models (LLMs) show promising potential in assistive tasks across various domains, including mobile device control. As these agents interact directly with personal information and device settings, ensuring their safe and reliable behavior is crucial to prevent undesirable outcomes. However, no benchmark exists for standardized evaluation of the safety of mobile device-control agents. In this work, we introduce MobileSafetyBench, a benchmark designed to evaluate the safety of device-control agents within a realistic mobile environment based on Android emulators. We develop a diverse set of tasks involving interactions with various mobile applications, including messaging and banking applications. To clearly evaluate safety apart from general capabilities, we design separate tasks measuring safety and tasks evaluating helpfulness. The safety tasks challenge agents with managing potential risks prevalent in daily life and include tests to evaluate robustness against indirect prompt injections. Our experiments demonstrate that while baseline agents, based on state-of-the-art LLMs, perform well in executing helpful tasks, they show poor performance in safety tasks. To mitigate these safety concerns, we propose a prompting method that encourages agents to prioritize safety considerations. While this method shows promise in promoting safer behaviors, there is still considerable room for improvement to fully earn user trust. This highlights the urgent need for continued research to develop more robust safety mechanisms in mobile environments. We open-source our benchmark at: https://mobilesafetybench.github.io/.
Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions
Oct 17, 2024



Large language models (LLMs) must often respond to highly ambiguous user requests. In such cases, the LLM's best response may be to ask a clarifying question to elicit more information. We observe existing LLMs often respond by presupposing a single interpretation of such ambiguous requests, frustrating users who intended a different interpretation. We speculate this is caused by current preference data labeling practice, where LLM responses are evaluated only on their prior contexts. To address this, we propose to assign preference labels by simulating their expected outcomes in the future turns. This allows LLMs to learn to ask clarifying questions when it can generate responses that are tailored to each user interpretation in future turns. In experiments on open-domain QA, we compare systems that trained using our proposed preference labeling methods against standard methods, which assign preferences based on only prior context. We evaluate systems based on their ability to ask clarifying questions that can recover each user's interpretation and expected answer, and find that our training with our proposed method trains LLMs to ask clarifying questions with a 5% improvement in F1 measured against the answer set from different interpretations of each query
Contrastive Preference Learning: Learning from Human Feedback without RL
Oct 24, 2023



Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function and second, align the model by optimizing the learned reward via reinforcement learning (RL). This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow the regret under the user's optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase. Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences. Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
Learning Optimal Advantage from Preferences and Mistaking it for Reward
Oct 03, 2023



We consider algorithms for learning reward functions from human preferences over pairs of trajectory segments, as used in reinforcement learning from human feedback (RLHF). Most recent work assumes that human preferences are generated based only upon the reward accrued within those segments, or their partial return. Recent work casts doubt on the validity of this assumption, proposing an alternative preference model based upon regret. We investigate the consequences of assuming preferences are based upon partial return when they actually arise from regret. We argue that the learned function is an approximation of the optimal advantage function, $\hat{A^*_r}$, not a reward function. We find that if a specific pitfall is addressed, this incorrect assumption is not particularly harmful, resulting in a highly shaped reward function. Nonetheless, this incorrect usage of $\hat{A^*_r}$ is less desirable than the appropriate and simpler approach of greedy maximization of $\hat{A^*_r}$. From the perspective of the regret preference model, we also provide a clearer interpretation of fine tuning contemporary large language models with RLHF. This paper overall provides insight regarding why learning under the partial return preference model tends to work so well in practice, despite it conforming poorly to how humans give preferences.