 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
Sep 10, 2025Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .
A Benchmark for Generalizing Across Diverse Team Strategies in Competitive Pokémon
Jun 12, 2025Developing AI agents that can robustly adapt to dramatically different strategic landscapes without retraining is a central challenge for multi-agent learning. Pok\'emon Video Game Championships (VGC) is a domain with an extraordinarily large space of possible team configurations of approximately $10^{139}$ - far larger than those of Dota or Starcraft. The highly discrete, combinatorial nature of team building in Pok\'emon VGC causes optimal strategies to shift dramatically depending on both the team being piloted and the opponent's team, making generalization uniquely challenging. To advance research on this problem, we introduce VGC-Bench: a benchmark that provides critical infrastructure, standardizes evaluation protocols, and supplies human-play datasets and a range of baselines - from large-language-model agents and behavior cloning to reinforcement learning and empirical game-theoretic methods such as self-play, fictitious play, and double oracle. In the restricted setting where an agent is trained and evaluated on a single-team configuration, our methods are able to win against a professional VGC competitor. We extensively evaluated all baseline methods over progressively larger team sets and find that even the best-performing algorithm in the single-team setting struggles at scaling up as team size grows. Thus, policy generalization across diverse team strategies remains an open challenge for the community. Our code is open sourced at https://github.com/cameronangliss/VGC-Bench.
ROTATE: Regret-driven Open-ended Training for Ad Hoc Teamwork
May 29, 2025Developing AI agents capable of collaborating with previously unseen partners is a fundamental generalization challenge in multi-agent learning, known as Ad Hoc Teamwork (AHT). Existing AHT approaches typically adopt a two-stage pipeline, where first, a fixed population of teammates is generated with the idea that they should be representative of the teammates that will be seen at deployment time, and second, an AHT agent is trained to collaborate well with agents in the population. To date, the research community has focused on designing separate algorithms for each stage. This separation has led to algorithms that generate teammate pools with limited coverage of possible behaviors, and that ignore whether the generated teammates are easy to learn from for the AHT agent. Furthermore, algorithms for training AHT agents typically treat the set of training teammates as static, thus attempting to generalize to previously unseen partner agents without assuming any control over the distribution of training teammates. In this paper, we present a unified framework for AHT by reformulating the problem as an open-ended learning process between an ad hoc agent and an adversarial teammate generator. We introduce ROTATE, a regret-driven, open-ended training algorithm that alternates between improving the AHT agent and generating teammates that probe its deficiencies. Extensive experiments across diverse AHT environments demonstrate that ROTATE significantly outperforms baselines at generalizing to an unseen set of evaluation teammates, thus establishing a new standard for robust and generalizable teamwork.
Towards Natural Language Communication for Cooperative Autonomous Driving via Self-Play
May 23, 2025



Past work has demonstrated that autonomous vehicles can drive more safely if they communicate with one another than if they do not. However, their communication has often not been human-understandable. Using natural language as a vehicle-to-vehicle (V2V) communication protocol offers the potential for autonomous vehicles to drive cooperatively not only with each other but also with human drivers. In this work, we propose a suite of traffic tasks in autonomous driving where vehicles in a traffic scenario need to communicate in natural language to facilitate coordination in order to avoid an imminent collision and/or support efficient traffic flow. To this end, this paper introduces a novel method, LLM+Debrief, to learn a message generation and high-level decision-making policy for autonomous vehicles through multi-agent discussion. To evaluate LLM agents for driving, we developed a gym-like simulation environment that contains a range of driving scenarios. Our experimental results demonstrate that LLM+Debrief is more effective at generating meaningful and human-understandable natural language messages to facilitate cooperation and coordination than a zero-shot LLM agent. Our code and demo videos are available at https://talking-vehicles.github.io/.
Minimum Coverage Sets for Training Robust Ad Hoc Teamwork Agents
Aug 18, 2023Robustly cooperating with unseen agents and human partners presents significant challenges due to the diverse cooperative conventions these partners may adopt. Existing Ad Hoc Teamwork (AHT) methods address this challenge by training an agent with a population of diverse teammate policies obtained through maximizing specific diversity metrics. However, these heuristic diversity metrics do not always maximize the agent's robustness in all cooperative problems. In this work, we first propose that maximizing an AHT agent's robustness requires it to emulate policies in the minimum coverage set (MCS), the set of best-response policies to any partner policies in the environment. We then introduce the L-BRDiv algorithm that generates a set of teammate policies that, when used for AHT training, encourage agents to emulate policies from the MCS. L-BRDiv works by solving a constrained optimization problem to jointly train teammate policies for AHT training and approximating AHT agent policies that are members of the MCS. We empirically demonstrate that L-BRDiv produces more robust AHT agents than state-of-the-art methods in a broader range of two-player cooperative problems without the need for extensive hyperparameter tuning for its objectives. Our study shows that L-BRDiv outperforms the baseline methods by prioritizing discovering distinct members of the MCS instead of repeatedly finding redundant policies.
COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles
May 04, 2022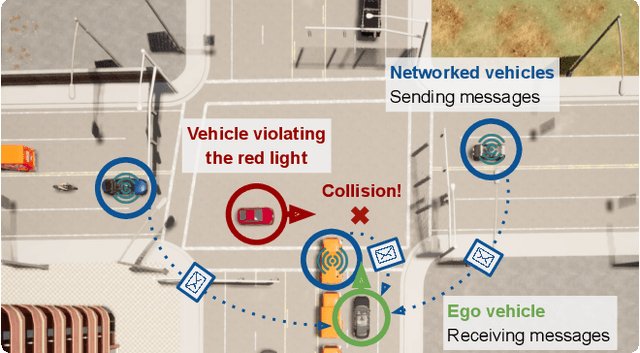

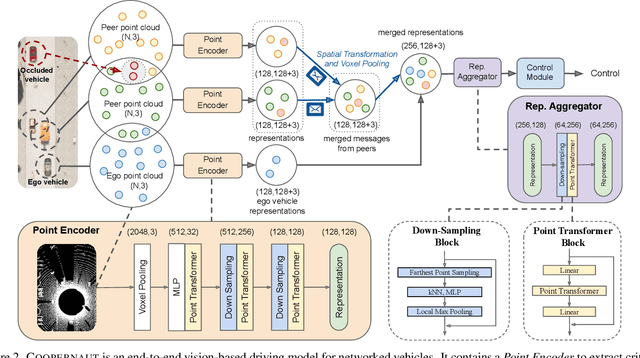

Optical sensors and learning algorithms for autonomous vehicles have dramatically advanced in the past few years. Nonetheless, the reliability of today's autonomous vehicles is hindered by the limited line-of-sight sensing capability and the brittleness of data-driven methods in handling extreme situations. With recent developments of telecommunication technologies, cooperative perception with vehicle-to-vehicle communications has become a promising paradigm to enhance autonomous driving in dangerous or emergency situations. We introduce COOPERNAUT, an end-to-end learning model that uses cross-vehicle perception for vision-based cooperative driving. Our model encodes LiDAR information into compact point-based representations that can be transmitted as messages between vehicles via realistic wireless channels. To evaluate our model, we develop AutoCastSim, a network-augmented driving simulation framework with example accident-prone scenarios. Our experiments on AutoCastSim suggest that our cooperative perception driving models lead to a 40% improvement in average success rate over egocentric driving models in these challenging driving situations and a 5 times smaller bandwidth requirement than prior work V2VNet. COOPERNAUT and AUTOCASTSIM are available at https://ut-austin-rpl.github.io/Coopernaut/.
Learning a Robust Multiagent Driving Policy for Traffic Congestion Reduction
Dec 03, 2021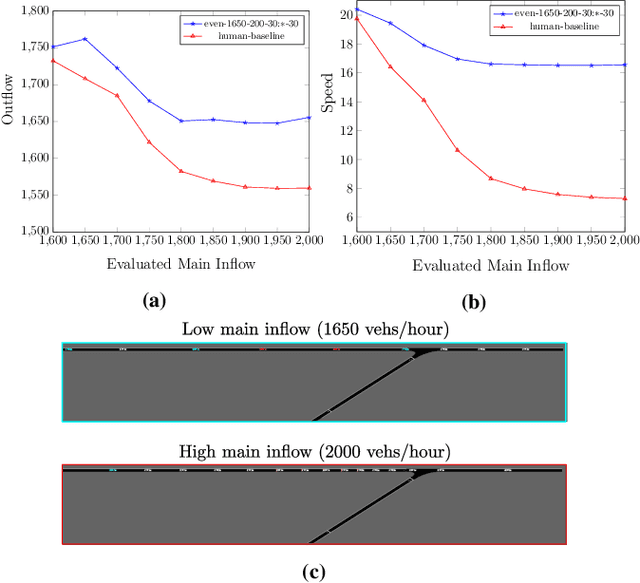
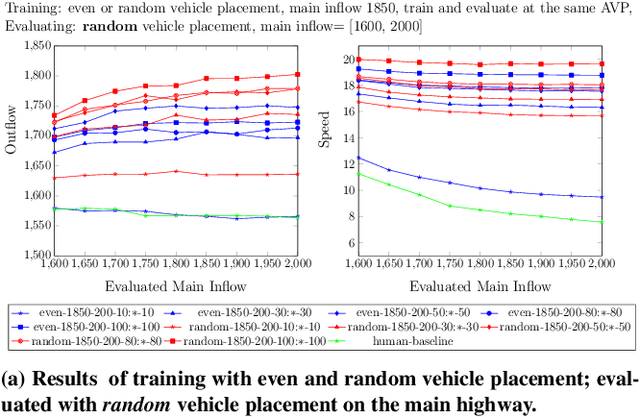

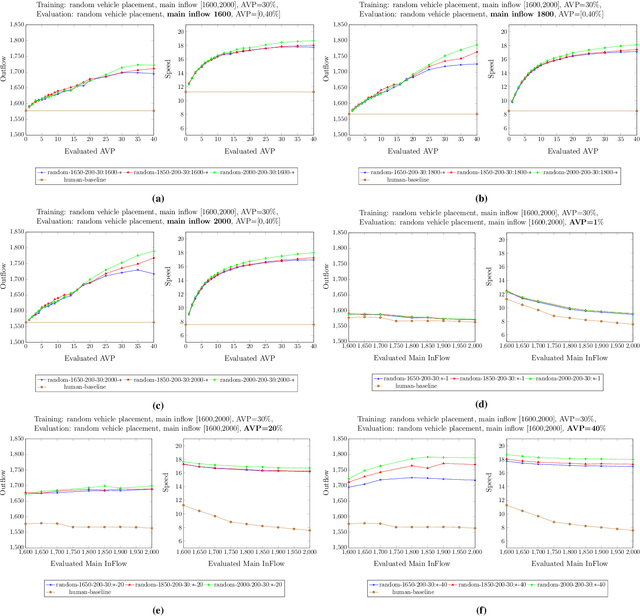
The advent of automated and autonomous vehicles (AVs) creates opportunities to achieve system-level goals using multiple AVs, such as traffic congestion reduction. Past research has shown that multiagent congestion-reducing driving policies can be learned in a variety of simulated scenarios. While initial proofs of concept were in small, closed traffic networks with a centralized controller, recently successful results have been demonstrated in more realistic settings with distributed control policies operating in open road networks where vehicles enter and leave. However, these driving policies were mostly tested under the same conditions they were trained on, and have not been thoroughly tested for robustness to different traffic conditions, which is a critical requirement in real-world scenarios. This paper presents a learned multiagent driving policy that is robust to a variety of open-network traffic conditions, including vehicle flows, the fraction of AVs in traffic, AV placement, and different merging road geometries. A thorough empirical analysis investigates the sensitivity of such a policy to the amount of AVs in both a simple merge network and a more complex road with two merging ramps. It shows that the learned policy achieves significant improvement over simulated human-driven policies even with AV penetration as low as 2%. The same policy is also shown to be capable of reducing traffic congestion in more complex roads with two merging ramps.
Scalable Multiagent Driving Policies For Reducing Traffic Congestion
Feb 26, 2021

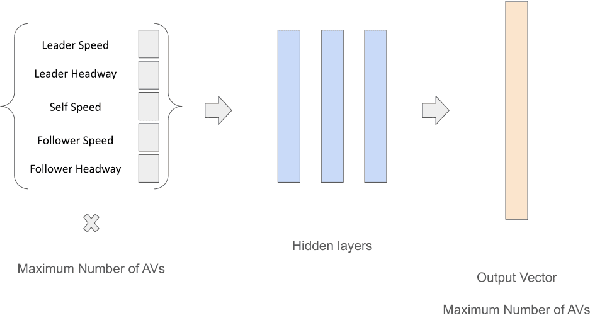

Traffic congestion is a major challenge in modern urban settings. The industry-wide development of autonomous and automated vehicles (AVs) motivates the question of how can AVs contribute to congestion reduction. Past research has shown that in small scale mixed traffic scenarios with both AVs and human-driven vehicles, a small fraction of AVs executing a controlled multiagent driving policy can mitigate congestion. In this paper, we scale up existing approaches and develop new multiagent driving policies for AVs in scenarios with greater complexity. We start by showing that a congestion metric used by past research is manipulable in open road network scenarios where vehicles dynamically join and leave the road. We then propose using a different metric that is robust to manipulation and reflects open network traffic efficiency. Next, we propose a modular transfer reinforcement learning approach, and use it to scale up a multiagent driving policy to outperform human-like traffic and existing approaches in a simulated realistic scenario, which is an order of magnitude larger than past scenarios (hundreds instead of tens of vehicles). Additionally, our modular transfer learning approach saves up to 80% of the training time in our experiments, by focusing its data collection on key locations in the network. Finally, we show for the first time a distributed multiagent policy that improves congestion over human-driven traffic. The distributed approach is more realistic and practical, as it relies solely on existing sensing and actuation capabilities, and does not require adding new communication infrastructure.