 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Symbolic Models from Deep Learning with Inductive Biases
Jun 19, 2020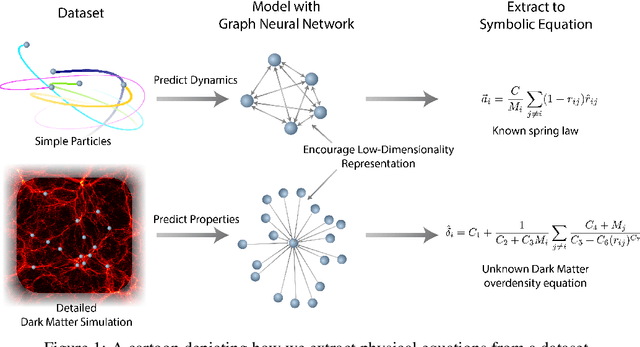


We develop a general approach to distill symbolic representations of a learned deep model by introducing strong inductive biases. We focus on Graph Neural Networks (GNNs). The technique works as follows: we first encourage sparse latent representations when we train a GNN in a supervised setting, then we apply symbolic regression to components of the learned model to extract explicit physical relations. We find the correct known equations, including force laws and Hamiltonians, can be extracted from the neural network. We then apply our method to a non-trivial cosmology example-a detailed dark matter simulation-and discover a new analytic formula which can predict the concentration of dark matter from the mass distribution of nearby cosmic structures. The symbolic expressions extracted from the GNN using our technique also generalized to out-of-distribution data better than the GNN itself. Our approach offers alternative directions for interpreting neural networks and discovering novel physical principles from the representations they learn.
Lagrangian Neural Networks
Mar 10, 2020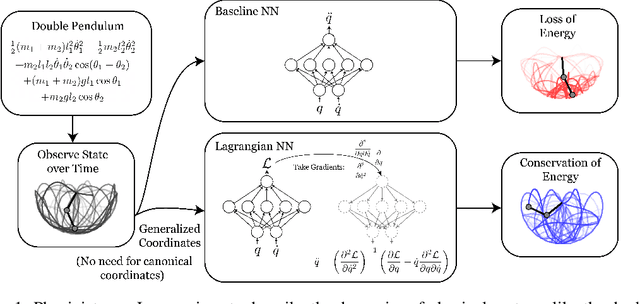
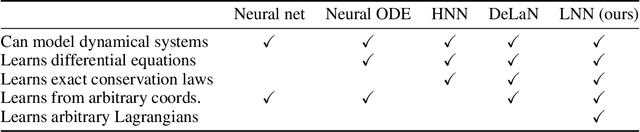
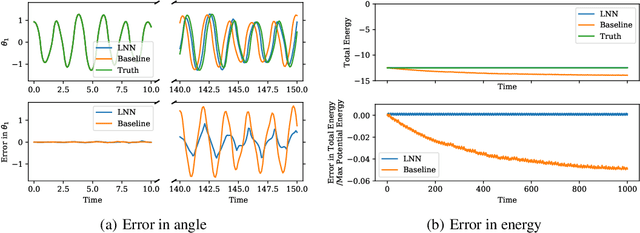
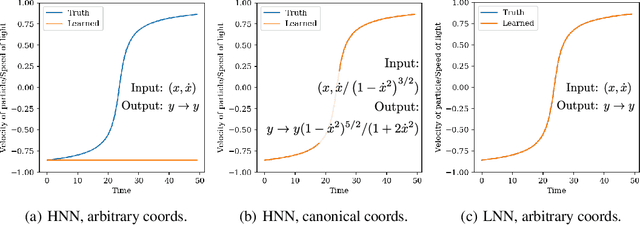
Accurate models of the world are built upon notions of its underlying symmetries. In physics, these symmetries correspond to conservation laws, such as for energy and momentum. Yet even though neural network models see increasing use in the physical sciences, they struggle to learn these symmetries. In this paper, we propose Lagrangian Neural Networks (LNNs), which can parameterize arbitrary Lagrangians using neural networks. In contrast to models that learn Hamiltonians, LNNs do not require canonical coordinates, and thus perform well in situations where canonical momenta are unknown or difficult to compute. Unlike previous approaches, our method does not restrict the functional form of learned energies and will produce energy-conserving models for a variety of tasks. We test our approach on a double pendulum and a relativistic particle, demonstrating energy conservation where a baseline approach incurs dissipation and modeling relativity without canonical coordinates where a Hamiltonian approach fails. Finally, we show how this model can be applied to graphs and continuous systems using a Lagrangian Graph Network, and demonstrate it on the 1D wave equation.
Hamiltonian Graph Networks with ODE Integrators
Sep 27, 2019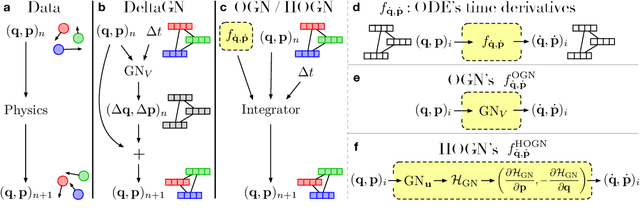
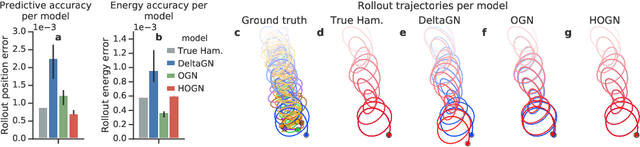
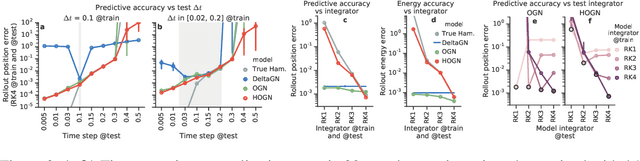
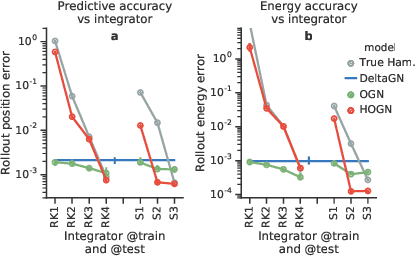
We introduce an approach for imposing physically informed inductive biases in learned simulation models. We combine graph networks with a differentiable ordinary differential equation integrator as a mechanism for predicting future states, and a Hamiltonian as an internal representation. We find that our approach outperforms baselines without these biases in terms of predictive accuracy, energy accuracy, and zero-shot generalization to time-step sizes and integrator orders not experienced during training. This advances the state-of-the-art of learned simulation, and in principle is applicable beyond physical domains.
Learning Symbolic Physics with Graph Networks
Sep 12, 2019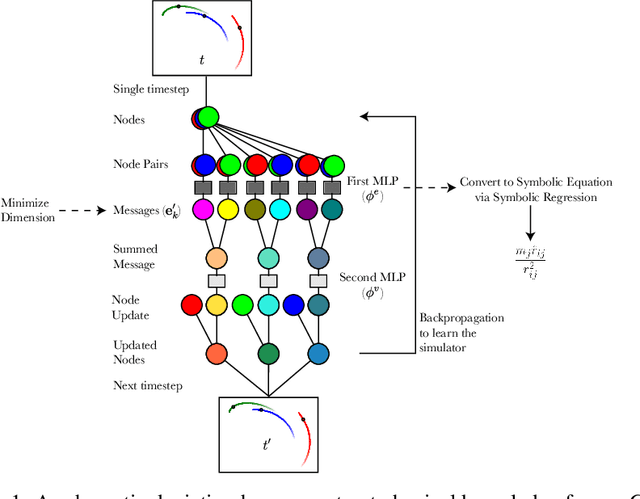
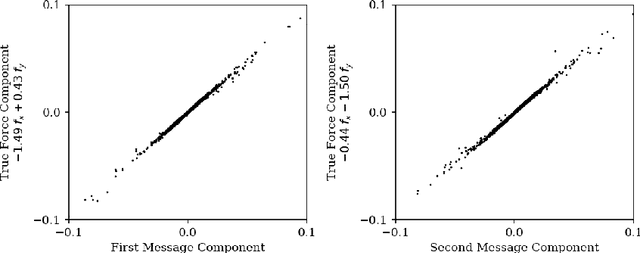
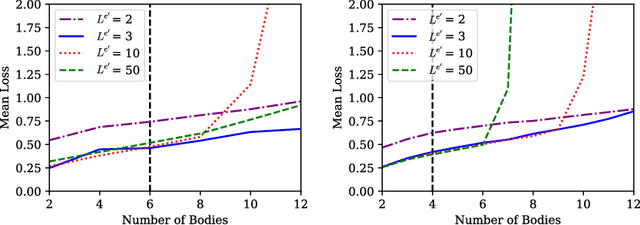
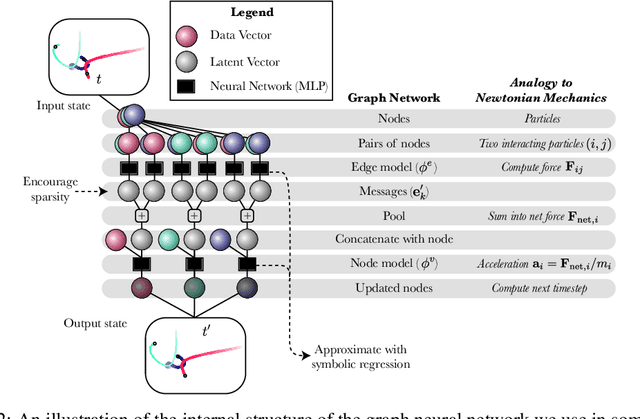
We introduce an approach for imposing physically motivated inductive biases on graph networks to learn interpretable representations and improved zero-shot generalization. Our experiments show that our graph network models, which implement this inductive bias, can learn message representations equivalent to the true force vector when trained on n-body gravitational and spring-like simulations. We use symbolic regression to fit explicit algebraic equations to our trained model's message function and recover the symbolic form of Newton's law of gravitation without prior knowledge. We also show that our model generalizes better at inference time to systems with more bodies than had been experienced during training. Our approach is extensible, in principle, to any unknown interaction law learned by a graph network, and offers a valuable technique for interpreting and inferring explicit causal theories about the world from implicit knowledge captured by deep learning.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019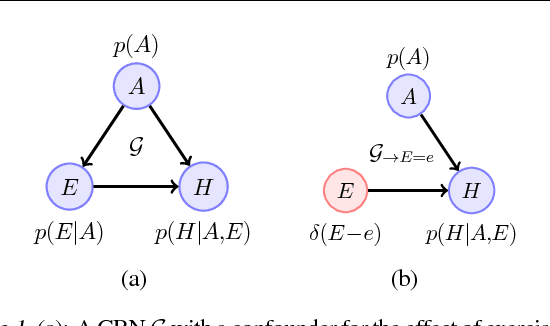


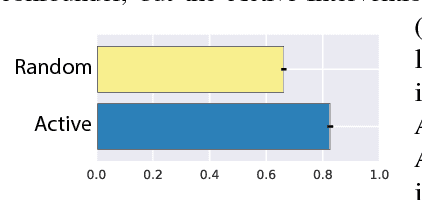
Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
Compositional Imitation Learning: Explaining and executing one task at a time
Dec 04, 2018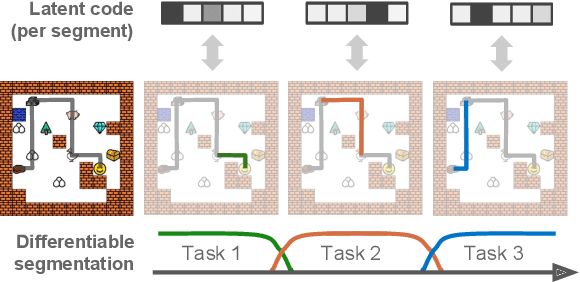
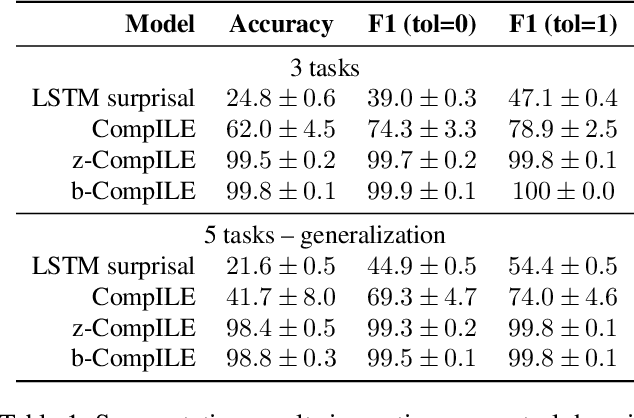
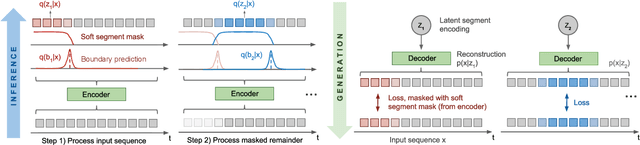
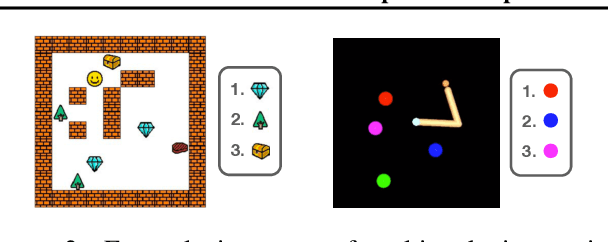
We introduce a framework for Compositional Imitation Learning and Execution (CompILE) of hierarchically-structured behavior. CompILE learns reusable, variable-length segments of behavior from demonstration data using a novel unsupervised, fully-differentiable sequence segmentation module. These learned behaviors can then be re-composed and executed to perform new tasks. At training time, CompILE auto-encodes observed behavior into a sequence of latent codes, each corresponding to a variable-length segment in the input sequence. Once trained, our model generalizes to sequences of longer length and from environment instances not seen during training. We evaluate our model in a challenging 2D multi-task environment and show that CompILE can find correct task boundaries and event encodings in an unsupervised manner without requiring annotated demonstration data. Latent codes and associated behavior policies discovered by CompILE can be used by a hierarchical agent, where the high-level policy selects actions in the latent code space, and the low-level, task-specific policies are simply the learned decoders. We found that our agent could learn given only sparse rewards, where agents without task-specific policies struggle.
Modeling human intuitions about liquid flow with particle-based simulation
Sep 05, 2018
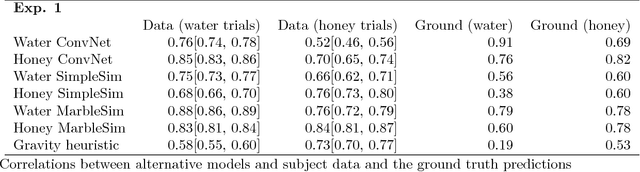

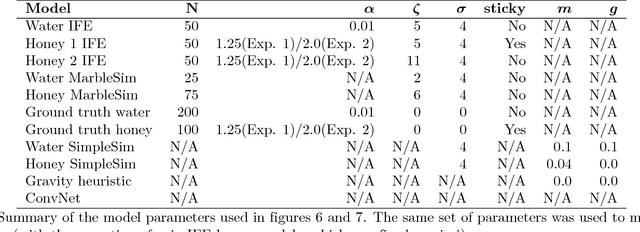
Humans can easily describe, imagine, and, crucially, predict a wide variety of behaviors of liquids--splashing, squirting, gushing, sloshing, soaking, dripping, draining, trickling, pooling, and pouring--despite tremendous variability in their material and dynamical properties. Here we propose and test a computational model of how people perceive and predict these liquid dynamics, based on coarse approximate simulations of fluids as collections of interacting particles. Our model is analogous to a "game engine in the head", drawing on techniques for interactive simulations (as in video games) that optimize for efficiency and natural appearance rather than physical accuracy. In two behavioral experiments, we found that the model accurately captured people's predictions about how liquids flow among complex solid obstacles, and was significantly better than two alternatives based on simple heuristics and deep neural networks. Our model was also able to explain how people's predictions varied as a function of the liquids' properties (e.g., viscosity and stickiness). Together, the model and empirical results extend the recent proposal that human physical scene understanding for the dynamics of rigid, solid objects can be supported by approximate probabilistic simulation, to the more complex and unexplored domain of fluid dynamics.
Learning Visual Question Answering by Bootstrapping Hard Attention
Aug 01, 2018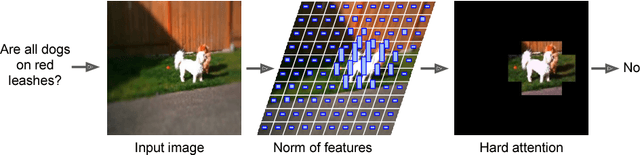
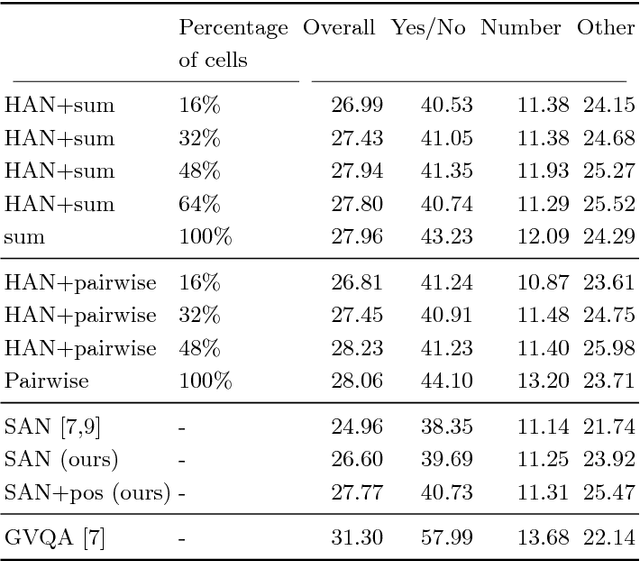
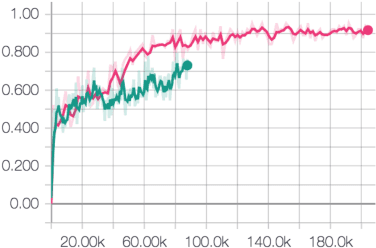
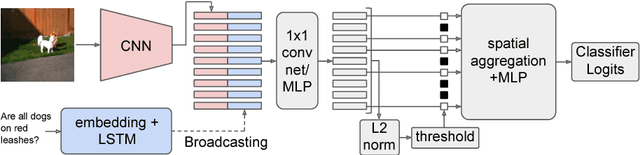
Attention mechanisms in biological perception are thought to select subsets of perceptual information for more sophisticated processing which would be prohibitive to perform on all sensory inputs. In computer vision, however, there has been relatively little exploration of hard attention, where some information is selectively ignored, in spite of the success of soft attention, where information is re-weighted and aggregated, but never filtered out. Here, we introduce a new approach for hard attention and find it achieves very competitive performance on a recently-released visual question answering datasets, equalling and in some cases surpassing similar soft attention architectures while entirely ignoring some features. Even though the hard attention mechanism is thought to be non-differentiable, we found that the feature magnitudes correlate with semantic relevance, and provide a useful signal for our mechanism's attentional selection criterion. Because hard attention selects important features of the input information, it can also be more efficient than analogous soft attention mechanisms. This is especially important for recent approaches that use non-local pairwise operations, whereby computational and memory costs are quadratic in the size of the set of features.
Relational Deep Reinforcement Learning
Jun 28, 2018
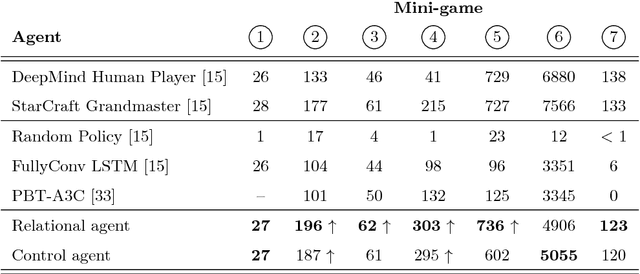
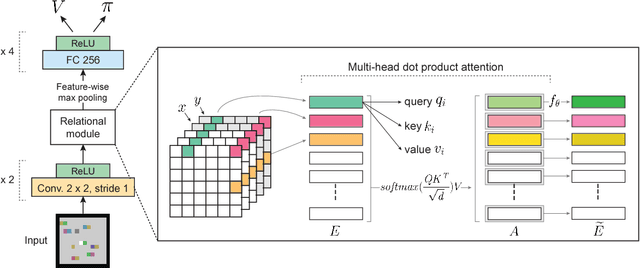
We introduce an approach for deep reinforcement learning (RL) that improves upon the efficiency, generalization capacity, and interpretability of conventional approaches through structured perception and relational reasoning. It uses self-attention to iteratively reason about the relations between entities in a scene and to guide a model-free policy. Our results show that in a novel navigation and planning task called Box-World, our agent finds interpretable solutions that improve upon baselines in terms of sample complexity, ability to generalize to more complex scenes than experienced during training, and overall performance. In the StarCraft II Learning Environment, our agent achieves state-of-the-art performance on six mini-games -- surpassing human grandmaster performance on four. By considering architectural inductive biases, our work opens new directions for overcoming important, but stubborn, challenges in deep RL.
Unsupervised Learning of 3D Structure from Images
Jun 19, 2018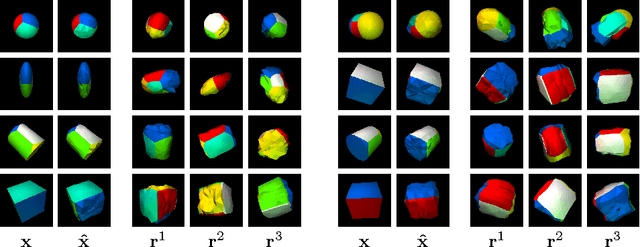
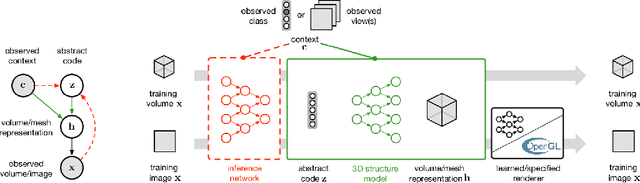


A key goal of computer vision is to recover the underlying 3D structure from 2D observations of the world. In this paper we learn strong deep generative models of 3D structures, and recover these structures from 3D and 2D images via probabilistic inference. We demonstrate high-quality samples and report log-likelihoods on several datasets, including ShapeNet [2], and establish the first benchmarks in the literature. We also show how these models and their inference networks can be trained end-to-end from 2D images. This demonstrates for the first time the feasibility of learning to infer 3D representations of the world in a purely unsupervised manner.