 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChromatic Learning for Sparse Datasets
Jun 06, 2020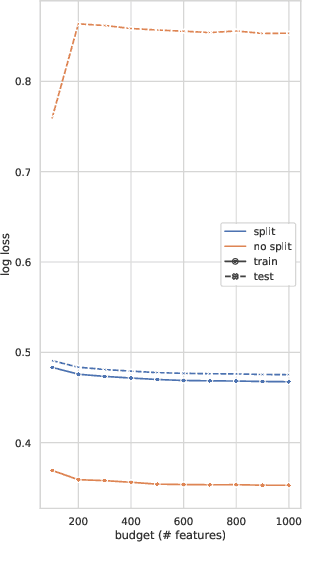
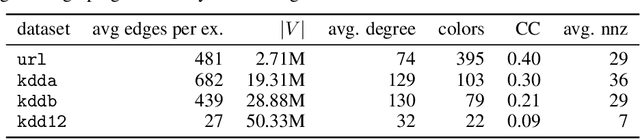
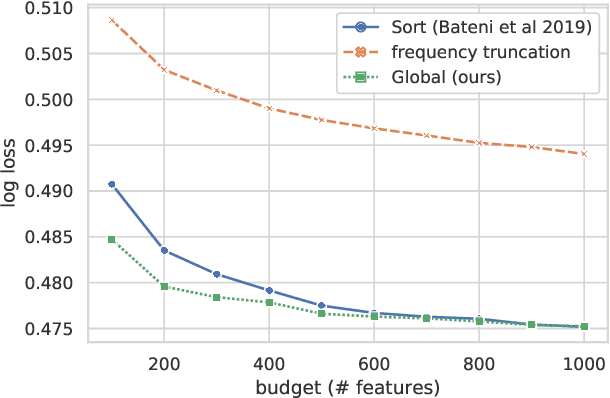
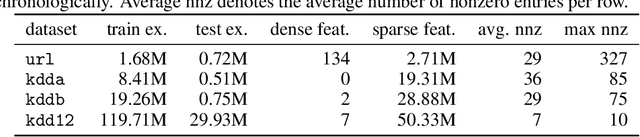
Learning over sparse, high-dimensional data frequently necessitates the use of specialized methods such as the hashing trick. In this work, we design a highly scalable alternative approach that leverages the low degree of feature co-occurrences present in many practical settings. This approach, which we call Chromatic Learning (CL), obtains a low-dimensional dense feature representation by performing graph coloring over the co-occurrence graph of features---an approach previously used as a runtime performance optimization for GBDT training. This color-based dense representation can be combined with additional dense categorical encoding approaches, e.g., submodular feature compression, to further reduce dimensionality. CL exhibits linear parallelizability and consumes memory linear in the size of the co-occurrence graph. By leveraging the structural properties of the co-occurrence graph, CL can compress sparse datasets, such as KDD Cup 2012, that contain over 50M features down to 1024, using an order of magnitude fewer features than frequency-based truncation and the hashing trick while maintaining the same test error for linear models. This compression further enables the use of deep networks in this wide, sparse setting, where CL similarly has favorable performance compared to existing baselines for budgeted input dimension.
Model Assertions for Monitoring and Improving ML Models
Mar 11, 2020

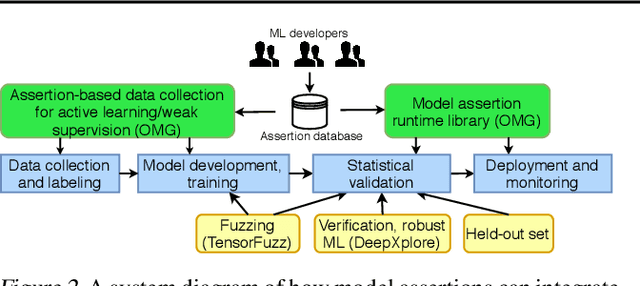

ML models are increasingly deployed in settings with real world interactions such as vehicles, but unfortunately, these models can fail in systematic ways. To prevent errors, ML engineering teams monitor and continuously improve these models. We propose a new abstraction, model assertions, that adapts the classical use of program assertions as a way to monitor and improve ML models. Model assertions are arbitrary functions over a model's input and output that indicate when errors may be occurring, e.g., a function that triggers if an object rapidly changes its class in a video. We propose methods of using model assertions at all stages of ML system deployment, including runtime monitoring, validating labels, and continuously improving ML models. For runtime monitoring, we show that model assertions can find high confidence errors, where a model returns the wrong output with high confidence, which uncertainty-based monitoring techniques would not detect. For training, we propose two methods of using model assertions. First, we propose a bandit-based active learning algorithm that can sample from data flagged by assertions and show that it can reduce labeling costs by up to 40% over traditional uncertainty-based methods. Second, we propose an API for generating "consistency assertions" (e.g., the class change example) and weak labels for inputs where the consistency assertions fail, and show that these weak labels can improve relative model quality by up to 46%. We evaluate model assertions on four real-world tasks with video, LIDAR, and ECG data.
MLPerf Training Benchmark
Oct 30, 2019
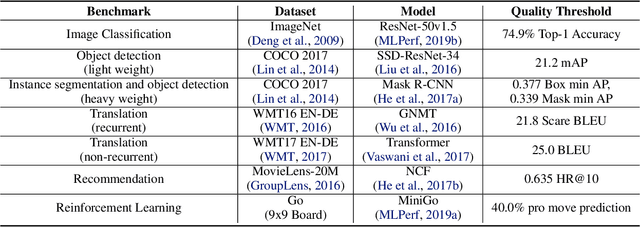
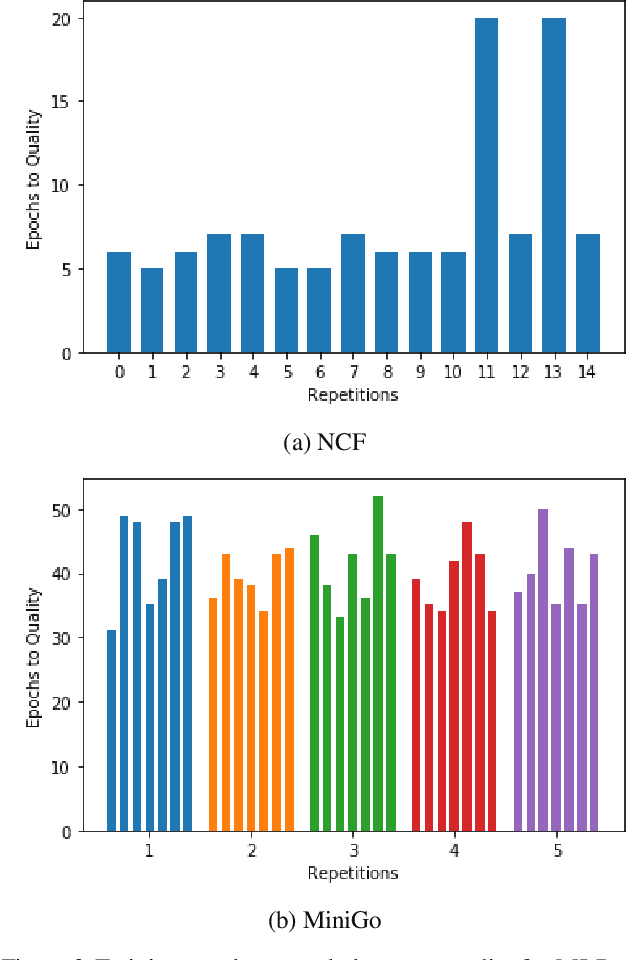
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.
Selection Via Proxy: Efficient Data Selection For Deep Learning
Jun 26, 2019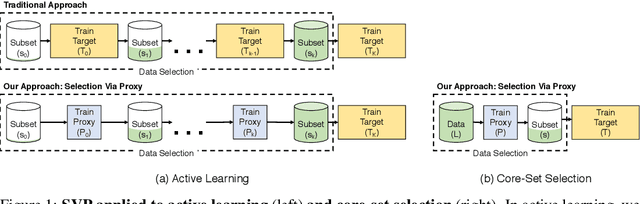
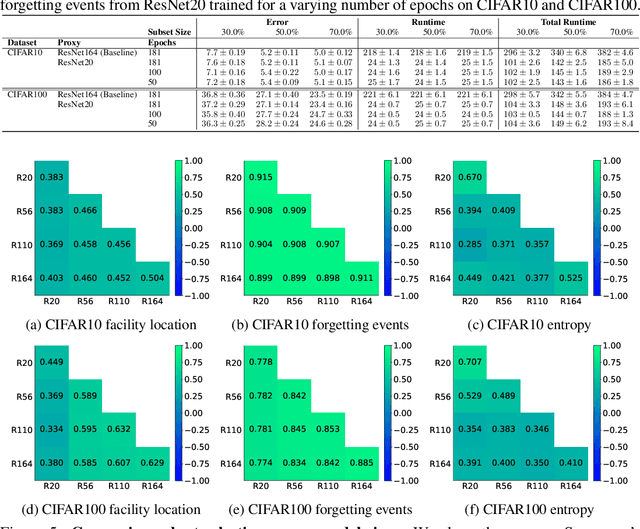
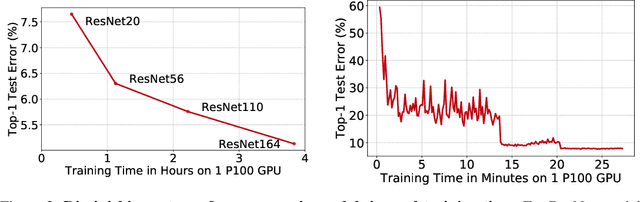
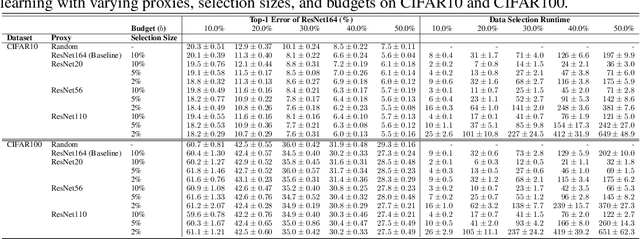
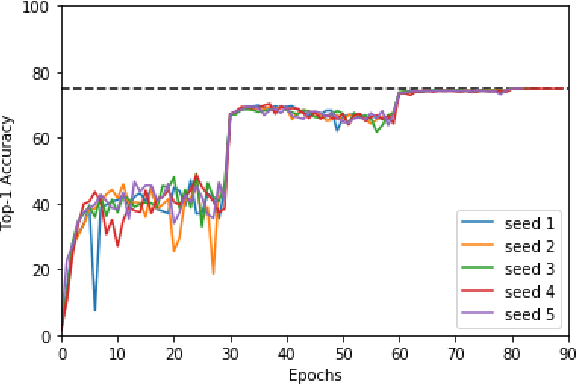
Data selection methods such as active learning and core-set selection are useful tools for machine learning on large datasets, but they can be prohibitively expensive to apply in deep learning. Unlike in other areas of machine learning, the feature representations that these techniques depend on are learned in deep learning rather than given, which takes a substantial amount of training time. In this work, we show that we can significantly improve the computational efficiency of data selection in deep learning by using a much smaller proxy model to perform data selection for tasks that will eventually require a large target model (e.g., selecting data points to label for active learning). In deep learning, we can scale down models by removing hidden layers or reducing their dimension to create proxies that are an order of magnitude faster. Although these small proxy models have significantly higher error, we find that they empirically provide useful rankings for data selection that have a high correlation with those of larger models. We evaluate this "selection via proxy" (SVP) approach on several data selection tasks. For active learning, applying SVP to Sener and Savarese [2018]'s recent method for active learning in deep learning gives a 4x improvement in execution time while yielding the same model accuracy. For core-set selection, we show that a proxy model that trains 10x faster than a target ResNet164 model on CIFAR10 can be used to remove 50% of the training data without compromising the accuracy of the target model, making end-to-end training time improvements via core-set selection possible.
Willump: A Statistically-Aware End-to-end Optimizer for Machine Learning Inference
Jun 03, 2019

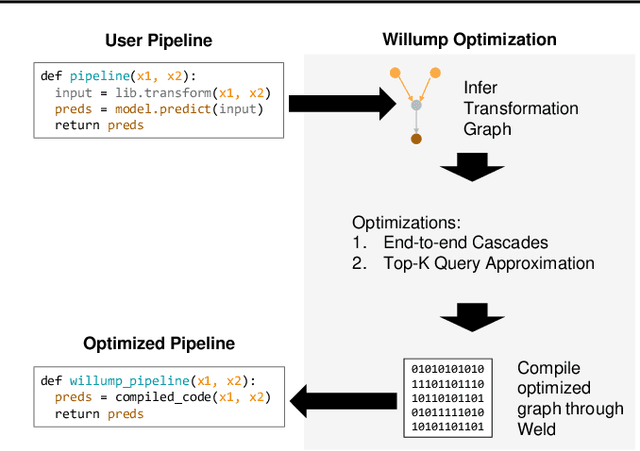
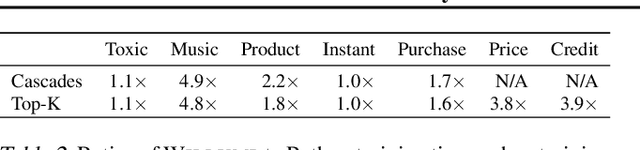
Machine learning (ML) has become increasingly important and performance-critical in modern data centers. This has led to interest in model serving systems, which perform ML inference and serve predictions to end-user applications. However, most existing model serving systems approach ML inference as an extension of conventional data serving workloads and miss critical opportunities for performance. In this paper, we present Willump, a statistically-aware optimizer for ML inference that takes advantage of key properties of ML inference not shared by traditional workloads. First, ML models can often be approximated efficiently on many "easy" inputs by judiciously using a less expensive model for these inputs (e.g., not computing all the input features). Willump automatically generates such approximations from an ML inference pipeline, providing up to 4.1$\times$ speedup without statistically significant accuracy loss. Second, ML models are often used in higher-level end-to-end queries in an ML application, such as computing the top K predictions for a recommendation model. Willump optimizes inference based on these higher-level queries by up to 5.7$\times$ over na\"ive batch inference. Willump combines these novel optimizations with standard compiler optimizations and a computation graph-aware feature caching scheme to automatically generate fast inference code for ML pipelines. We show that Willump improves performance of real-world ML inference pipelines by up to 23$\times$, with its novel optimizations giving 3.6-5.7$\times$ speedups over compilation. We also show that Willump integrates easily with existing model serving systems, such as Clipper.
CrossTrainer: Practical Domain Adaptation with Loss Reweighting
May 07, 2019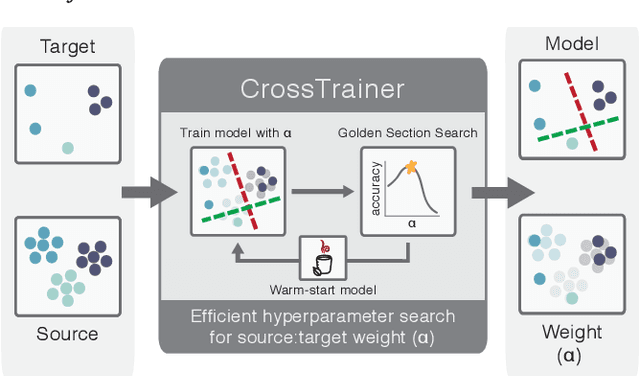
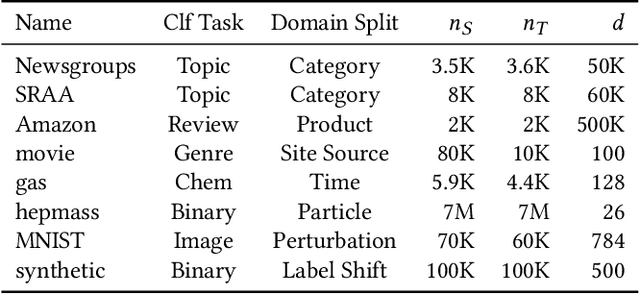

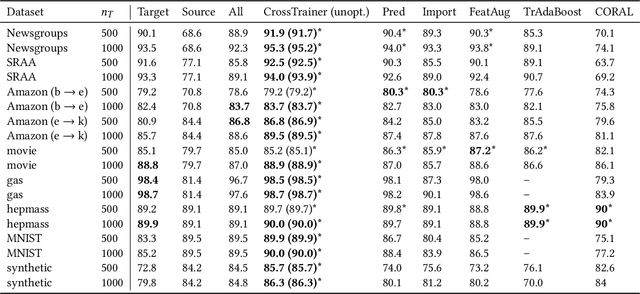
Domain adaptation provides a powerful set of model training techniques given domain-specific training data and supplemental data with unknown relevance. The techniques are useful when users need to develop models with data from varying sources, of varying quality, or from different time ranges. We build CrossTrainer, a system for practical domain adaptation. CrossTrainer utilizes loss reweighting, which provides consistently high model accuracy across a variety of datasets in our empirical analysis. However, loss reweighting is sensitive to the choice of a weight hyperparameter that is expensive to tune. We develop optimizations leveraging unique properties of loss reweighting that allow CrossTrainer to output accurate models while improving training time compared to naive hyperparameter search.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Equivariant Transformer Networks
Jan 25, 2019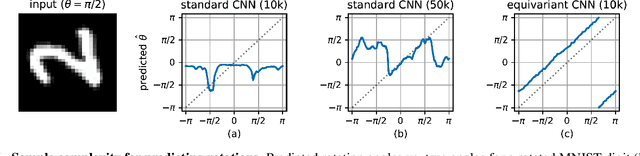
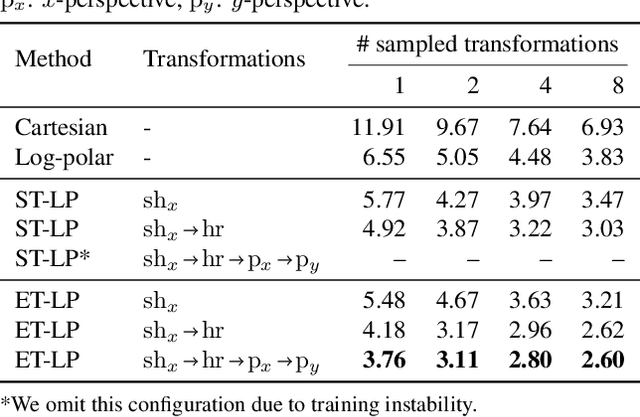
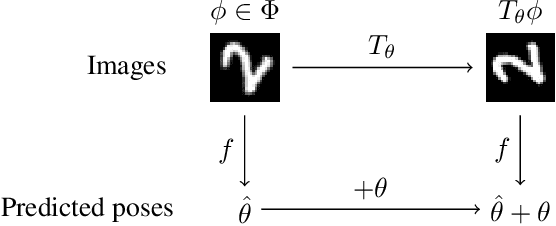
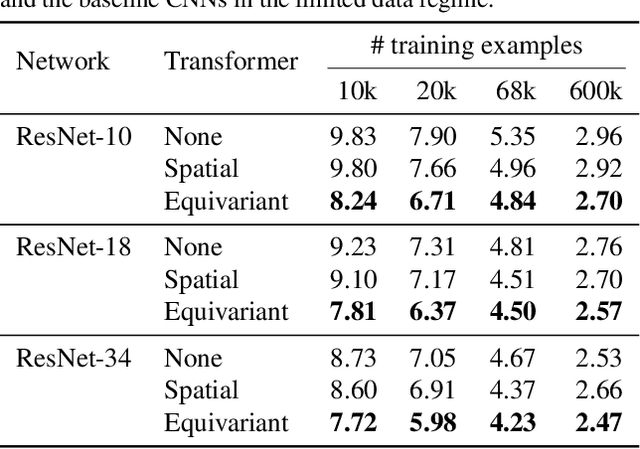
How can prior knowledge on the transformation invariances of a domain be incorporated into the architecture of a neural network? We propose Equivariant Transformers (ETs), a family of differentiable image-to-image mappings that improve the robustness of models towards pre-defined continuous transformation groups. Through the use of specially-derived canonical coordinate systems, ETs incorporate functions that are equivariant by construction with respect to these transformations. We show empirically that ETs can be flexibly composed to improve model robustness towards more complicated transformation groups in several parameters. On a real-world image classification task, ETs improve the sample efficiency of ResNet classifiers, achieving relative improvements in error rate of up to 15% in the limited data regime while increasing model parameter count by less than 1%.
LIT: Block-wise Intermediate Representation Training for Model Compression
Oct 02, 2018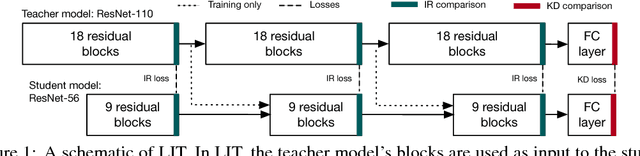

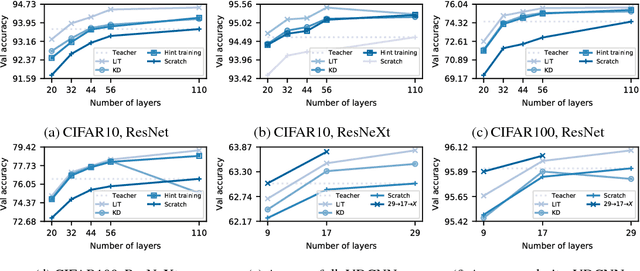

Knowledge distillation (KD) is a popular method for reducing the computational overhead of deep network inference, in which the output of a teacher model is used to train a smaller, faster student model. Hint training (i.e., FitNets) extends KD by regressing a student model's intermediate representation to a teacher model's intermediate representation. In this work, we introduce bLock-wise Intermediate representation Training (LIT), a novel model compression technique that extends the use of intermediate representations in deep network compression, outperforming KD and hint training. LIT has two key ideas: 1) LIT trains a student of the same width (but shallower depth) as the teacher by directly comparing the intermediate representations, and 2) LIT uses the intermediate representation from the previous block in the teacher model as an input to the current student block during training, avoiding unstable intermediate representations in the student network. We show that LIT provides substantial reductions in network depth without loss in accuracy -- for example, LIT can compress a ResNeXt-110 to a ResNeXt-20 (5.5x) on CIFAR10 and a VDCNN-29 to a VDCNN-9 (3.2x) on Amazon Reviews without loss in accuracy, outperforming KD and hint training in network size for a given accuracy. We also show that applying LIT to identical student/teacher architectures increases the accuracy of the student model above the teacher model, outperforming the recently-proposed Born Again Networks procedure on ResNet, ResNeXt, and VDCNN. Finally, we show that LIT can effectively compress GAN generators, which are not supported in the KD framework because GANs output pixels as opposed to probabilities.
Analysis of DAWNBench, a Time-to-Accuracy Machine Learning Performance Benchmark
Jun 04, 2018


The deep learning community has proposed optimizations spanning hardware, software, and learning theory to improve the computational performance of deep learning workloads. While some of these optimizations perform the same operations faster (e.g., switching from a NVIDIA K80 to P100), many modify the semantics of the training procedure (e.g., large minibatch training, reduced precision), which can impact a model's generalization ability. Due to a lack of standard evaluation criteria that considers these trade-offs, it has become increasingly difficult to compare these different advances. To address this shortcoming, DAWNBENCH and the upcoming MLPERF benchmarks use time-to-accuracy as the primary metric for evaluation, with the accuracy threshold set close to state-of-the-art and measured on a held-out dataset not used in training; the goal is to train to this accuracy threshold as fast as possible. In DAWNBENCH , the winning entries improved time-to-accuracy on ImageNet by two orders of magnitude over the seed entries. Despite this progress, it is unclear how sensitive time-to-accuracy is to the chosen threshold as well as the variance between independent training runs, and how well models optimized for time-to-accuracy generalize. In this paper, we provide evidence to suggest that time-to-accuracy has a low coefficient of variance and that the models tuned for it generalize nearly as well as pre-trained models. We additionally analyze the winning entries to understand the source of these speedups, and give recommendations for future benchmarking efforts.