 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRG-Net: Interactive Joint Learning of Multi-lesion Segmentation and Classification for Diabetic Retinopathy Grading
Dec 30, 2022



Diabetic Retinopathy (DR) is a leading cause of vision loss in the world, and early DR detection is necessary to prevent vision loss and support an appropriate treatment. In this work, we leverage interactive machine learning and introduce a joint learning framework, termed DRG-Net, to effectively learn both disease grading and multi-lesion segmentation. Our DRG-Net consists of two modules: (i) DRG-AI-System to classify DR Grading, localize lesion areas, and provide visual explanations; (ii) DRG-Expert-Interaction to receive feedback from user-expert and improve the DRG-AI-System. To deal with sparse data, we utilize transfer learning mechanisms to extract invariant feature representations by using Wasserstein distance and adversarial learning-based entropy minimization. Besides, we propose a novel attention strategy at both low- and high-level features to automatically select the most significant lesion information and provide explainable properties. In terms of human interaction, we further develop DRG-Net as a tool that enables expert users to correct the system's predictions, which may then be used to update the system as a whole. Moreover, thanks to the attention mechanism and loss functions constraint between lesion features and classification features, our approach can be robust given a certain level of noise in the feedback of users. We have benchmarked DRG-Net on the two largest DR datasets, i.e., IDRID and FGADR, and compared it to various state-of-the-art deep learning networks. In addition to outperforming other SOTA approaches, DRG-Net is effectively updated using user feedback, even in a weakly-supervised manner.
Joint Self-Supervised Image-Volume Representation Learning with Intra-Inter Contrastive Clustering
Dec 04, 2022



Collecting large-scale medical datasets with fully annotated samples for training of deep networks is prohibitively expensive, especially for 3D volume data. Recent breakthroughs in self-supervised learning (SSL) offer the ability to overcome the lack of labeled training samples by learning feature representations from unlabeled data. However, most current SSL techniques in the medical field have been designed for either 2D images or 3D volumes. In practice, this restricts the capability to fully leverage unlabeled data from numerous sources, which may include both 2D and 3D data. Additionally, the use of these pre-trained networks is constrained to downstream tasks with compatible data dimensions. In this paper, we propose a novel framework for unsupervised joint learning on 2D and 3D data modalities. Given a set of 2D images or 2D slices extracted from 3D volumes, we construct an SSL task based on a 2D contrastive clustering problem for distinct classes. The 3D volumes are exploited by computing vectored embedding at each slice and then assembling a holistic feature through deformable self-attention mechanisms in Transformer, allowing incorporating long-range dependencies between slices inside 3D volumes. These holistic features are further utilized to define a novel 3D clustering agreement-based SSL task and masking embedding prediction inspired by pre-trained language models. Experiments on downstream tasks, such as 3D brain segmentation, lung nodule detection, 3D heart structures segmentation, and abnormal chest X-ray detection, demonstrate the effectiveness of our joint 2D and 3D SSL approach. We improve plain 2D Deep-ClusterV2 and SwAV by a significant margin and also surpass various modern 2D and 3D SSL approaches.
Type Information Utilized Event Detection via Multi-Channel GNNs in Electrical Power Systems
Nov 15, 2022Event detection in power systems aims to identify triggers and event types, which helps relevant personnel respond to emergencies promptly and facilitates the optimization of power supply strategies. However, the limited length of short electrical record texts causes severe information sparsity, and numerous domain-specific terminologies of power systems makes it difficult to transfer knowledge from language models pre-trained on general-domain texts. Traditional event detection approaches primarily focus on the general domain and ignore these two problems in the power system domain. To address the above issues, we propose a Multi-Channel graph neural network utilizing Type information for Event Detection in power systems, named MC-TED, leveraging a semantic channel and a topological channel to enrich information interaction from short texts. Concretely, the semantic channel refines textual representations with semantic similarity, building the semantic information interaction among potential event-related words. The topological channel generates a relation-type-aware graph modeling word dependencies, and a word-type-aware graph integrating part-of-speech tags. To further reduce errors worsened by professional terminologies in type analysis, a type learning mechanism is designed for updating the representations of both the word type and relation type in the topological channel. In this way, the information sparsity and professional term occurrence problems can be alleviated by enabling interaction between topological and semantic information. Furthermore, to address the lack of labeled data in power systems, we built a Chinese event detection dataset based on electrical Power Event texts, named PoE. In experiments, our model achieves compelling results not only on the PoE dataset, but on general-domain event detection datasets including ACE 2005 and MAVEN.
Betty: An Automatic Differentiation Library for Multilevel Optimization
Jul 05, 2022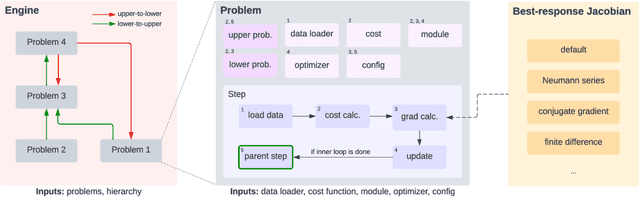
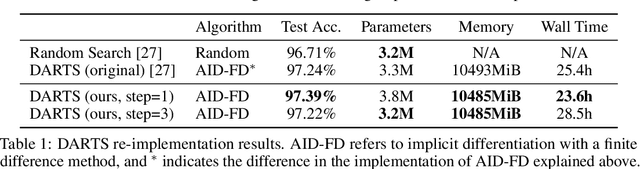
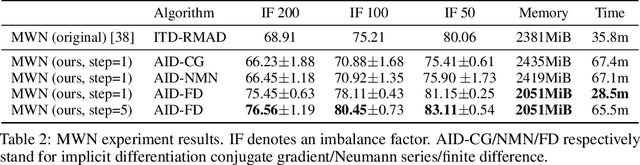

Multilevel optimization has been widely adopted as a mathematical foundation for a myriad of machine learning problems, such as hyperparameter optimization, meta-learning, and reinforcement learning, to name a few. Nonetheless, implementing multilevel optimization programs oftentimes requires expertise in both mathematics and programming, stunting research in this field. We take an initial step towards closing this gap by introducing Betty, a high-level software library for gradient-based multilevel optimization. To this end, we develop an automatic differentiation procedure based on a novel interpretation of multilevel optimization as a dataflow graph. We further abstract the main components of multilevel optimization as Python classes, to enable easy, modular, and maintainable programming. We empirically demonstrate that Betty can be used as a high-level programming interface for an array of multilevel optimization programs, while also observing up to 11\% increase in test accuracy, 14\% decrease in GPU memory usage, and 20\% decrease in wall time over existing implementations on multiple benchmarks. The code is available at http://github.com/leopard-ai/betty .
Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations
Feb 16, 2022

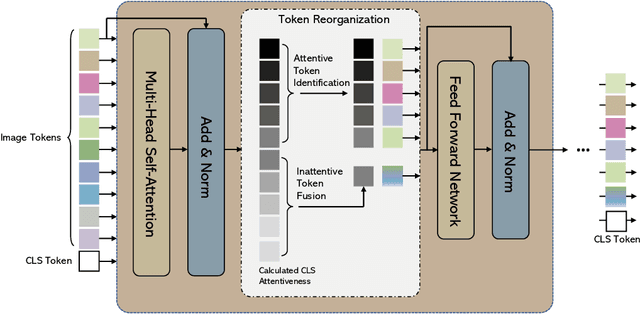
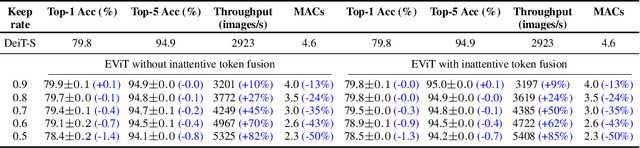
Vision Transformers (ViTs) take all the image patches as tokens and construct multi-head self-attention (MHSA) among them. Complete leverage of these image tokens brings redundant computations since not all the tokens are attentive in MHSA. Examples include that tokens containing semantically meaningless or distractive image backgrounds do not positively contribute to the ViT predictions. In this work, we propose to reorganize image tokens during the feed-forward process of ViT models, which is integrated into ViT during training. For each forward inference, we identify the attentive image tokens between MHSA and FFN (i.e., feed-forward network) modules, which is guided by the corresponding class token attention. Then, we reorganize image tokens by preserving attentive image tokens and fusing inattentive ones to expedite subsequent MHSA and FFN computations. To this end, our method EViT improves ViTs from two perspectives. First, under the same amount of input image tokens, our method reduces MHSA and FFN computation for efficient inference. For instance, the inference speed of DeiT-S is increased by 50% while its recognition accuracy is decreased by only 0.3% for ImageNet classification. Second, by maintaining the same computational cost, our method empowers ViTs to take more image tokens as input for recognition accuracy improvement, where the image tokens are from higher resolution images. An example is that we improve the recognition accuracy of DeiT-S by 1% for ImageNet classification at the same computational cost of a vanilla DeiT-S. Meanwhile, our method does not introduce more parameters to ViTs. Experiments on the standard benchmarks show the effectiveness of our method. The code is available at https://github.com/youweiliang/evit
Self-directed Machine Learning
Jan 08, 2022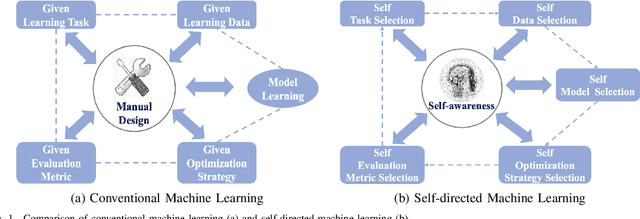
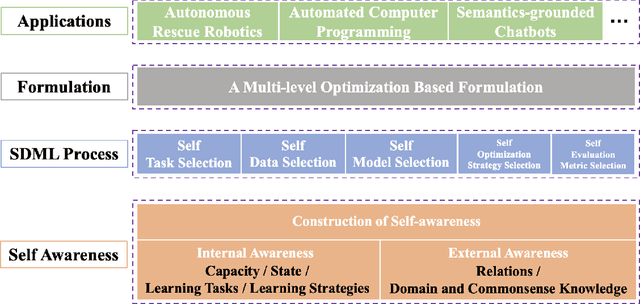
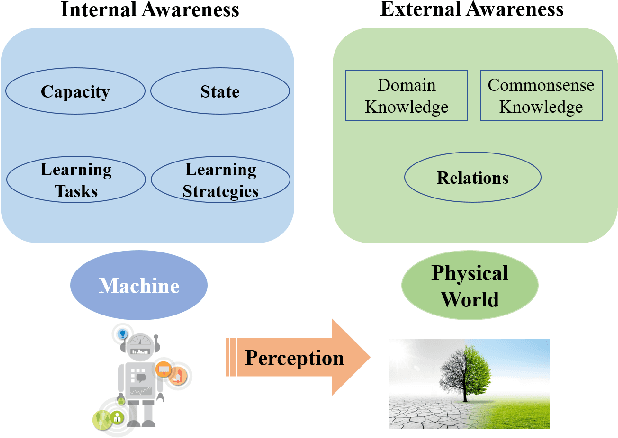
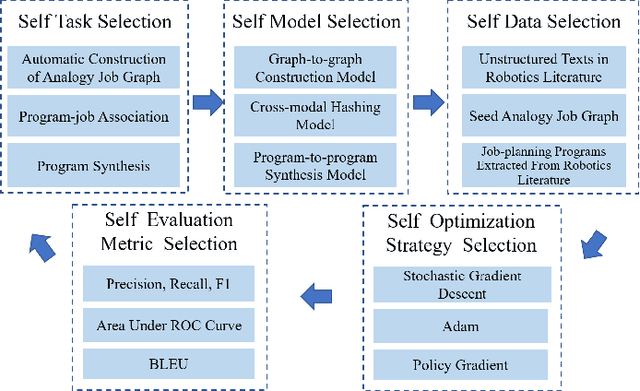
Conventional machine learning (ML) relies heavily on manual design from machine learning experts to decide learning tasks, data, models, optimization algorithms, and evaluation metrics, which is labor-intensive, time-consuming, and cannot learn autonomously like humans. In education science, self-directed learning, where human learners select learning tasks and materials on their own without requiring hands-on guidance, has been shown to be more effective than passive teacher-guided learning. Inspired by the concept of self-directed human learning, we introduce the principal concept of Self-directed Machine Learning (SDML) and propose a framework for SDML. Specifically, we design SDML as a self-directed learning process guided by self-awareness, including internal awareness and external awareness. Our proposed SDML process benefits from self task selection, self data selection, self model selection, self optimization strategy selection and self evaluation metric selection through self-awareness without human guidance. Meanwhile, the learning performance of the SDML process serves as feedback to further improve self-awareness. We propose a mathematical formulation for SDML based on multi-level optimization. Furthermore, we present case studies together with potential applications of SDML, followed by discussing future research directions. We expect that SDML could enable machines to conduct human-like self-directed learning and provide a new perspective towards artificial general intelligence.
Learning from Mistakes based on Class Weighting with Application to Neural Architecture Search
Dec 01, 2021

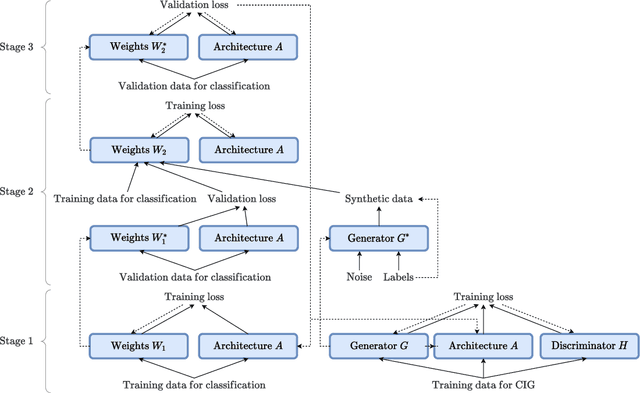
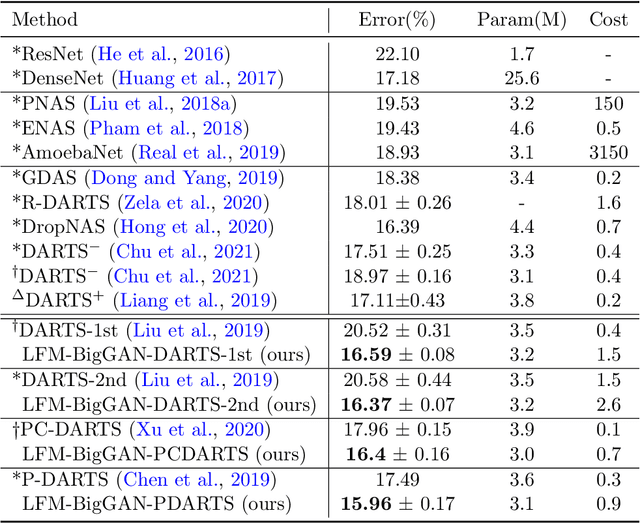
Learning from mistakes is an effective learning approach widely used in human learning, where a learner pays greater focus on mistakes to circumvent them in the future. It aids in improving the overall learning outcomes. In this work, we aim to investigate how effectively this exceptional learning ability can be used to improve machine learning models as well. We propose a simple and effective multi-level optimization framework called learning from mistakes (LFM), inspired by mistake-driven learning to train better machine learning models. Our LFM framework consists of a formulation involving three learning stages. The primary objective is to train a model to perform effectively on target tasks by using a re-weighting technique to prevent similar mistakes in the future. In this formulation, we learn the class weights by minimizing the validation loss of the model and re-train the model with the synthetic data from the image generator weighted by class-wise performance and real data. We apply our LFM framework for differential architecture search methods on image classification datasets such as CIFAR and ImageNet, where the results demonstrate the effectiveness of our proposed strategy.
Improving Differentiable Architecture Search with a Generative Model
Nov 30, 2021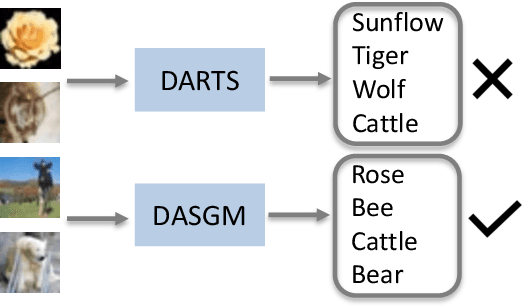


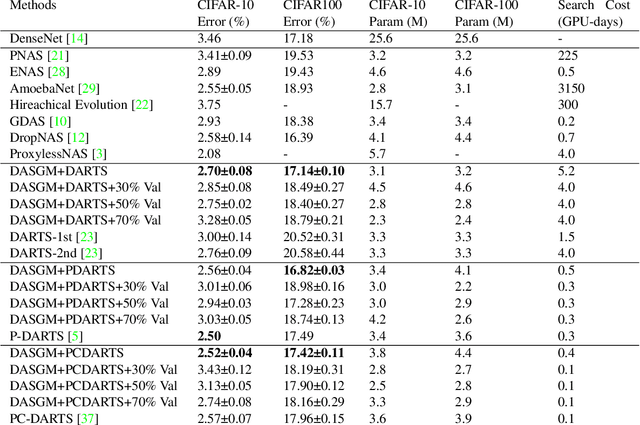
In differentiable neural architecture search (NAS) algorithms like DARTS, the training set used to update model weight and the validation set used to update model architectures are sampled from the same data distribution. Thus, the uncommon features in the dataset fail to receive enough attention during training. In this paper, instead of introducing more complex NAS algorithms, we explore the idea that adding quality synthesized datasets into training can help the classification model identify its weakness and improve recognition accuracy. We introduce a training strategy called ``Differentiable Architecture Search with a Generative Model(DASGM)." In DASGM, the training set is used to update the classification model weight, while a synthesized dataset is used to train its architecture. The generated images have different distributions from the training set, which can help the classification model learn better features to identify its weakness. We formulate DASGM into a multi-level optimization framework and develop an effective algorithm to solve it. Experiments on CIFAR-10, CIFAR-100, and ImageNet have demonstrated the effectiveness of DASGM. Code will be made available.
Learning from Mistakes -- A Framework for Neural Architecture Search
Nov 11, 2021



Learning from one's mistakes is an effective human learning technique where the learners focus more on the topics where mistakes were made, so as to deepen their understanding. In this paper, we investigate if this human learning strategy can be applied in machine learning. We propose a novel machine learning method called Learning From Mistakes (LFM), wherein the learner improves its ability to learn by focusing more on the mistakes during revision. We formulate LFM as a three-stage optimization problem: 1) learner learns; 2) learner re-learns focusing on the mistakes, and; 3) learner validates its learning. We develop an efficient algorithm to solve the LFM problem. We apply the LFM framework to neural architecture search on CIFAR-10, CIFAR-100, and Imagenet. Experimental results strongly demonstrate the effectiveness of our model.
Learning by Examples Based on Multi-level Optimization
Sep 22, 2021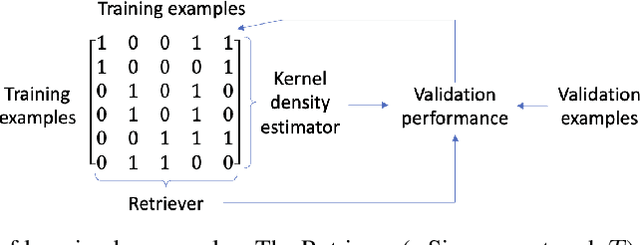
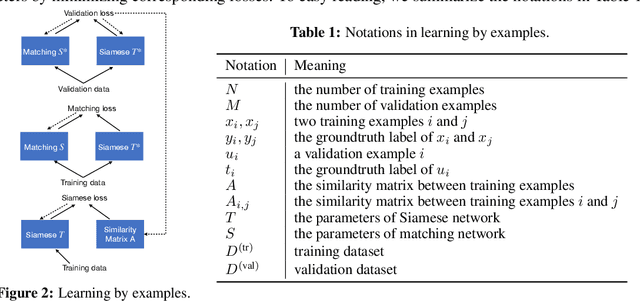
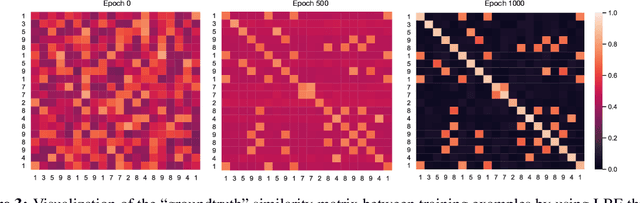
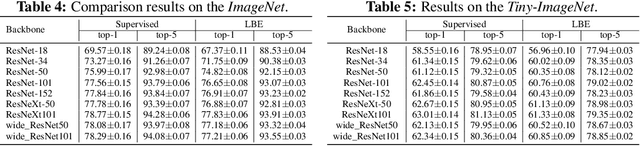
Learning by examples, which learns to solve a new problem by looking into how similar problems are solved, is an effective learning method in human learning. When a student learns a new topic, he/she finds out exemplar topics that are similar to this new topic and studies the exemplar topics to deepen the understanding of the new topic. We aim to investigate whether this powerful learning skill can be borrowed from humans to improve machine learning as well. In this work, we propose a novel learning approach called Learning By Examples (LBE). Our approach automatically retrieves a set of training examples that are similar to query examples and predicts labels for query examples by using class labels of the retrieved examples. We propose a three-level optimization framework to formulate LBE which involves three stages of learning: learning a Siamese network to retrieve similar examples; learning a matching network to make predictions on query examples by leveraging class labels of retrieved similar examples; learning the ``ground-truth'' similarities between training examples by minimizing the validation loss. We develop an efficient algorithm to solve the LBE problem and conduct extensive experiments on various benchmarks where the results demonstrate the effectiveness of our method on both supervised and few-shot learning.