 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Tokens Do 3D Point Cloud Transformer Architectures Really Need?
Nov 07, 2025Recent advances in 3D point cloud transformers have led to state-of-the-art results in tasks such as semantic segmentation and reconstruction. However, these models typically rely on dense token representations, incurring high computational and memory costs during training and inference. In this work, we present the finding that tokens are remarkably redundant, leading to substantial inefficiency. We introduce gitmerge3D, a globally informed graph token merging method that can reduce the token count by up to 90-95% while maintaining competitive performance. This finding challenges the prevailing assumption that more tokens inherently yield better performance and highlights that many current models are over-tokenized and under-optimized for scalability. We validate our method across multiple 3D vision tasks and show consistent improvements in computational efficiency. This work is the first to assess redundancy in large-scale 3D transformer models, providing insights into the development of more efficient 3D foundation architectures. Our code and checkpoints are publicly available at https://gitmerge3d.github.io
InFL-UX: A Toolkit for Web-Based Interactive Federated Learning
Mar 06, 2025

This paper presents InFL-UX, an interactive, proof-of-concept browser-based Federated Learning (FL) toolkit designed to integrate user contributions seamlessly into the machine learning (ML) workflow. InFL-UX enables users across multiple devices to upload datasets, define classes, and collaboratively train classification models directly in the browser using modern web technologies. Unlike traditional FL toolkits, which often focus on backend simulations, InFL-UX provides a simple user interface for researchers to explore how users interact with and contribute to FL systems in real-world, interactive settings. By prioritising usability and decentralised model training, InFL-UX bridges the gap between FL and Interactive Machine Learning (IML), empowering non-technical users to actively participate in ML classification tasks.
A look under the hood of the Interactive Deep Learning Enterprise (No-IDLE)
Jun 27, 2024This DFKI technical report presents the anatomy of the No-IDLE prototype system (funded by the German Federal Ministry of Education and Research) that provides not only basic and fundamental research in interactive machine learning, but also reveals deeper insights into users' behaviours, needs, and goals. Machine learning and deep learning should become accessible to millions of end users. No-IDLE's goals and scienfific challenges centre around the desire to increase the reach of interactive deep learning solutions for non-experts in machine learning. One of the key innovations described in this technical report is a methodology for interactive machine learning combined with multimodal interaction which will become central when we start interacting with semi-intelligent machines in the upcoming area of neural networks and large language models.
I-MPN: Inductive Message Passing Network for Effective and Efficient Human-in-the-Loop Annotation of Mobile Eye Tracking Data
Jun 10, 2024



Understanding human visual processing in dynamic environments is essential for psychology and human-centered interaction design. Mobile eye-tracking systems, combining egocentric video and gaze signals, offer valuable insights. However, manual analysis of these recordings is time-intensive. In this work, we present a novel human-centered learning algorithm designed for automated object recognition within mobile eye-tracking settings. Our approach seamlessly integrates an object detector with an inductive message-passing network technique (I-MPN), harnessing node features such as node profile information and positions. This integration enables our algorithm to learn embedding functions capable of generalizing to new object angle views, thereby facilitating rapid adaptation and efficient reasoning in dynamic contexts as users navigate through their environment. Through experiments conducted on three distinct video sequences, our \textit{interactive-based method} showcases significant performance improvements over fixed training/testing algorithms, even when trained on considerably smaller annotated samples collected through user feedback. Furthermore, we showcase exceptional efficiency in data annotation processes, surpassing approaches that use complete object detectors, combine detectors with convolutional networks, or employ interactive video segmentation.
DRG-Net: Interactive Joint Learning of Multi-lesion Segmentation and Classification for Diabetic Retinopathy Grading
Dec 30, 2022



Diabetic Retinopathy (DR) is a leading cause of vision loss in the world, and early DR detection is necessary to prevent vision loss and support an appropriate treatment. In this work, we leverage interactive machine learning and introduce a joint learning framework, termed DRG-Net, to effectively learn both disease grading and multi-lesion segmentation. Our DRG-Net consists of two modules: (i) DRG-AI-System to classify DR Grading, localize lesion areas, and provide visual explanations; (ii) DRG-Expert-Interaction to receive feedback from user-expert and improve the DRG-AI-System. To deal with sparse data, we utilize transfer learning mechanisms to extract invariant feature representations by using Wasserstein distance and adversarial learning-based entropy minimization. Besides, we propose a novel attention strategy at both low- and high-level features to automatically select the most significant lesion information and provide explainable properties. In terms of human interaction, we further develop DRG-Net as a tool that enables expert users to correct the system's predictions, which may then be used to update the system as a whole. Moreover, thanks to the attention mechanism and loss functions constraint between lesion features and classification features, our approach can be robust given a certain level of noise in the feedback of users. We have benchmarked DRG-Net on the two largest DR datasets, i.e., IDRID and FGADR, and compared it to various state-of-the-art deep learning networks. In addition to outperforming other SOTA approaches, DRG-Net is effectively updated using user feedback, even in a weakly-supervised manner.
Incremental Improvement of a Question Answering System by Re-ranking Answer Candidates using Machine Learning
Aug 27, 2019
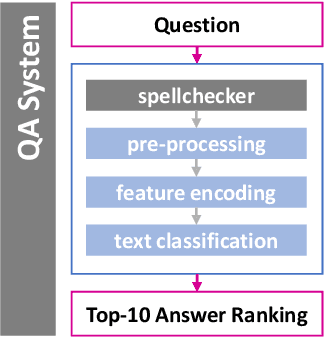

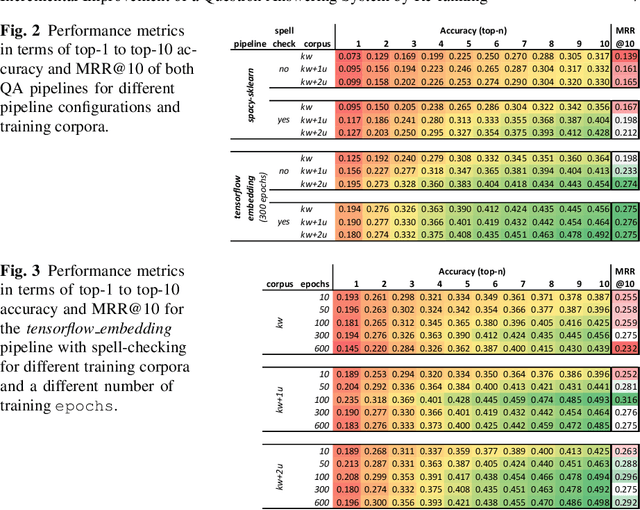
We implement a method for re-ranking top-10 results of a state-of-the-art question answering (QA) system. The goal of our re-ranking approach is to improve the answer selection given the user question and the top-10 candidates. We focus on improving deployed QA systems that do not allow re-training or re-training comes at a high cost. Our re-ranking approach learns a similarity function using n-gram based features using the query, the answer and the initial system confidence as input. Our contributions are: (1) we generate a QA training corpus starting from 877 answers from the customer care domain of T-Mobile Austria, (2) we implement a state-of-the-art QA pipeline using neural sentence embeddings that encode queries in the same space than the answer index, and (3) we evaluate the QA pipeline and our re-ranking approach using a separately provided test set. The test set can be considered to be available after deployment of the system, e.g., based on feedback of users. Our results show that the system performance, in terms of top-n accuracy and the mean reciprocal rank, benefits from re-ranking using gradient boosted regression trees. On average, the mean reciprocal rank improves by 9.15%.
A categorisation and implementation of digital pen features for behaviour characterisation
Oct 01, 2018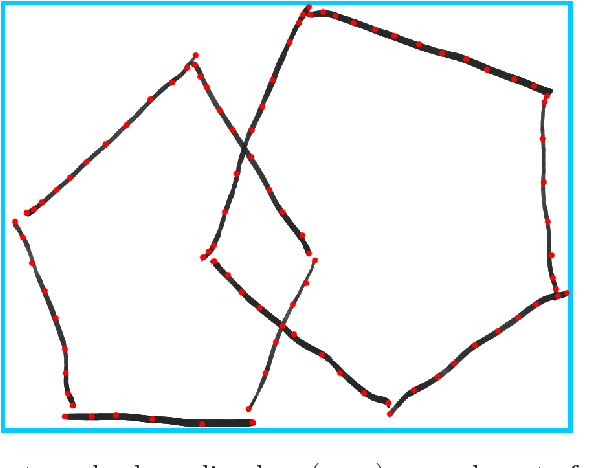
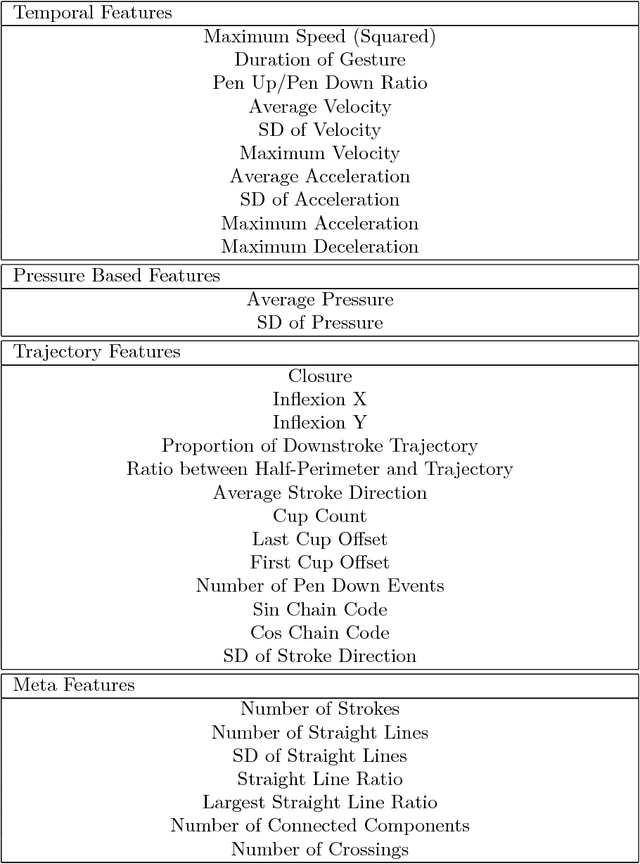
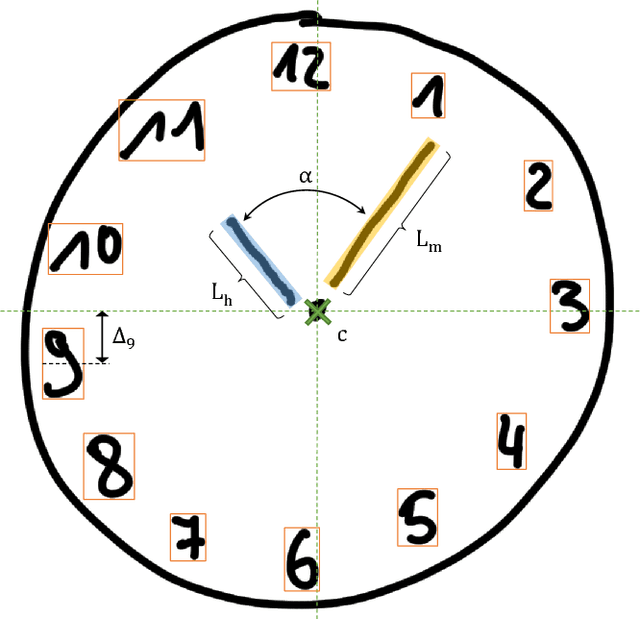
In this paper we provide a categorisation and implementation of digital ink features for behaviour characterisation. Based on four feature sets taken from literature, we provide a categorisation in different classes of syntactic and semantic features. We implemented a publicly available framework to calculate these features and show its deployment in the use case of analysing cognitive assessments performed using a digital pen.
A Survey on Deep Learning Toolkits and Libraries for Intelligent User Interfaces
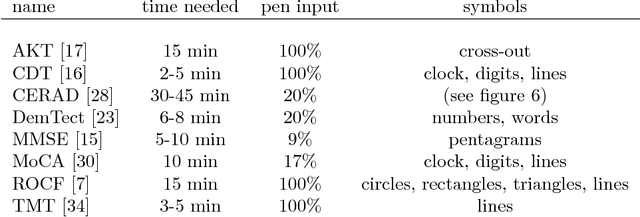
Mar 14, 2018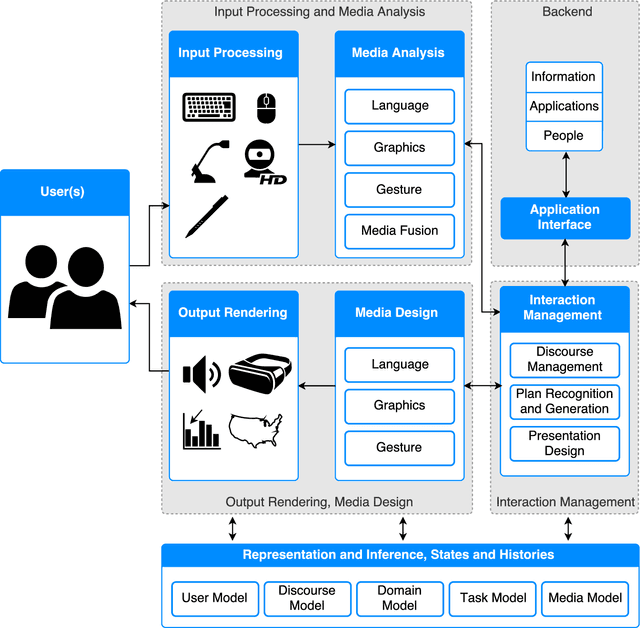
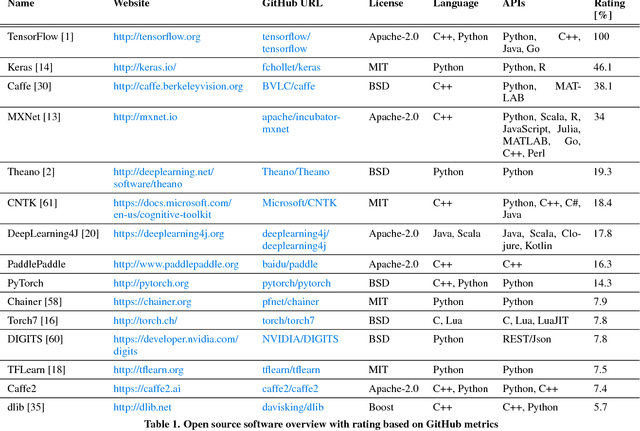
This paper provides an overview of prominent deep learning toolkits and, in particular, reports on recent publications that contributed open source software for implementing tasks that are common in intelligent user interfaces (IUI). We provide a scientific reference for researchers and software engineers who plan to utilise deep learning techniques within their IUI research and development projects.
Fine-tuning deep CNN models on specific MS COCO categories
Sep 05, 2017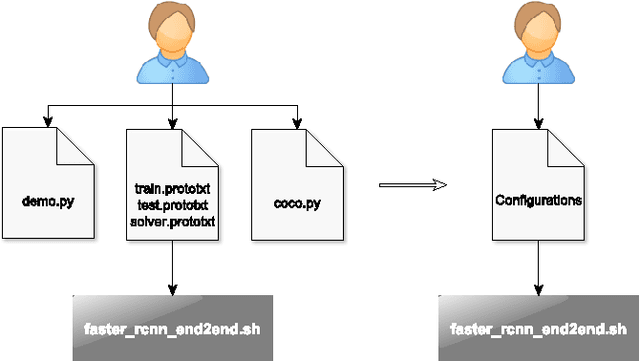
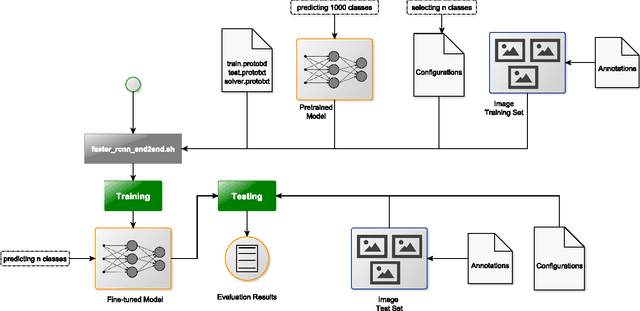

Fine-tuning of a deep convolutional neural network (CNN) is often desired. This paper provides an overview of our publicly available py-faster-rcnn-ft software library that can be used to fine-tune the VGG_CNN_M_1024 model on custom subsets of the Microsoft Common Objects in Context (MS COCO) dataset. For example, we improved the procedure so that the user does not have to look for suitable image files in the dataset by hand which can then be used in the demo program. Our implementation randomly selects images that contain at least one object of the categories on which the model is fine-tuned.