 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional Skipping: Towards Finer-Grained Dynamic CNN Inference
Jan 03, 2020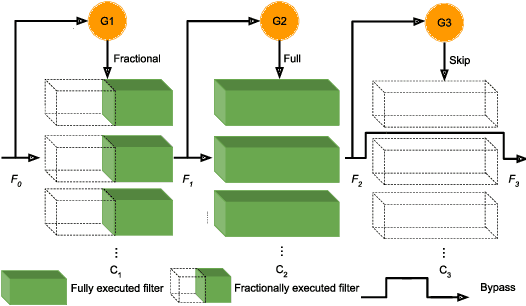

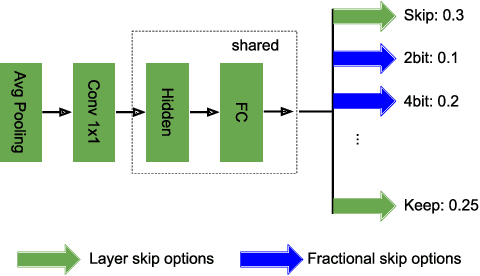
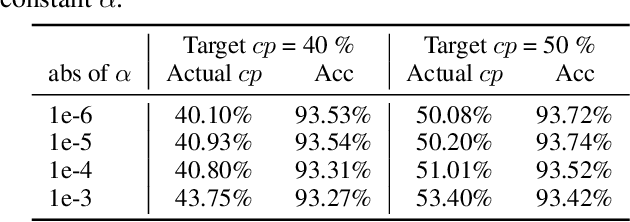
While increasingly deep networks are still in general desired for achieving state-of-the-art performance, for many specific inputs a simpler network might already suffice. Existing works exploited this observation by learning to skip convolutional layers in an input-dependent manner. However, we argue their binary decision scheme, i.e., either fully executing or completely bypassing one layer for a specific input, can be enhanced by introducing finer-grained, "softer" decisions. We therefore propose a Dynamic Fractional Skipping (DFS) framework. The core idea of DFS is to hypothesize layer-wise quantization (to different bitwidths) as intermediate "soft" choices to be made between fully utilizing and skipping a layer. For each input, DFS dynamically assigns a bitwidth to both weights and activations of each layer, where fully executing and skipping could be viewed as two "extremes" (i.e., full bitwidth and zero bitwidth). In this way, DFS can "fractionally" exploit a layer's expressive power during input-adaptive inference, enabling finer-grained accuracy-computational cost trade-offs. It presents a unified view to link input-adaptive layer skipping and input-adaptive hybrid quantization. Extensive experimental results demonstrate the superior tradeoff between computational cost and model expressive power (accuracy) achieved by DFS. More visualizations also indicate a smooth and consistent transition in the DFS behaviors, especially the learned choices between layer skipping and different quantizations when the total computational budgets vary, validating our hypothesis that layer quantization could be viewed as intermediate variants of layer skipping. Our source code and supplementary material are available at \link{https://github.com/Torment123/DFS}.
E2-Train: Training State-of-the-art CNNs with Over 80% Energy Savings
Dec 06, 2019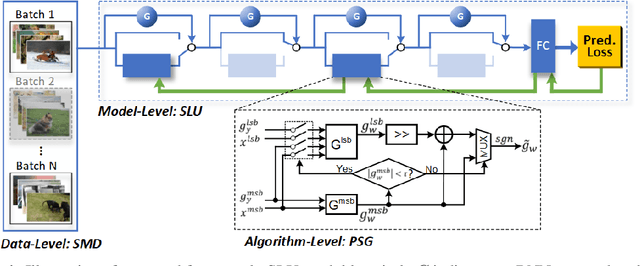

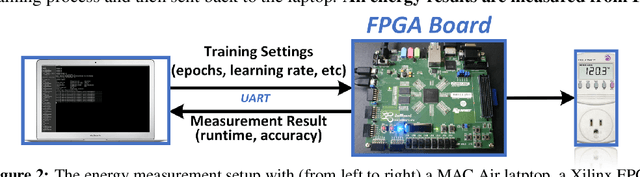

Convolutional neural networks (CNNs) have been increasingly deployed to edge devices. Hence, many efforts have been made towards efficient CNN inference in resource-constrained platforms. This paper attempts to explore an orthogonal direction: how to conduct more energy-efficient training of CNNs, so as to enable on-device training. We strive to reduce the energy cost during training, by dropping unnecessary computations from three complementary levels: stochastic mini-batch dropping on the data level; selective layer update on the model level; and sign prediction for low-cost, low-precision back-propagation, on the algorithm level. Extensive simulations and ablation studies, with real energy measurements from an FPGA board, confirm the superiority of our proposed strategies and demonstrate remarkable energy savings for training. For example, when training ResNet-74 on CIFAR-10, we achieve aggressive energy savings of >90% and >60%, while incurring a top-1 accuracy loss of only about 2% and 1.2%, respectively. When training ResNet-110 on CIFAR-100, an over 84% training energy saving is achieved without degrading inference accuracy.
Multi-source Distilling Domain Adaptation
Nov 22, 2019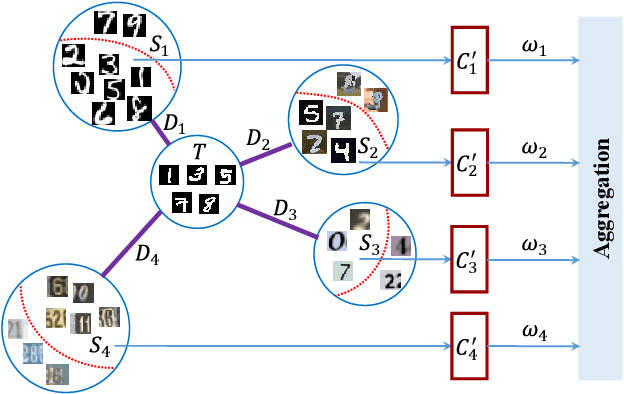
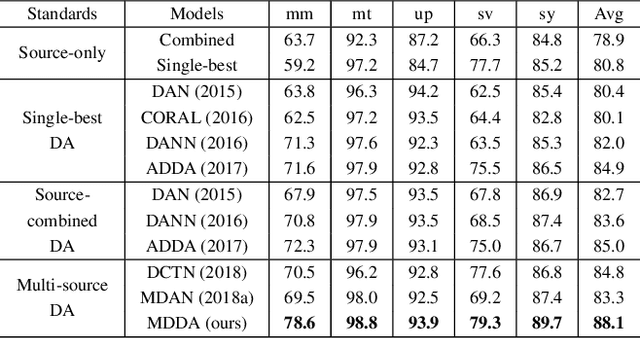
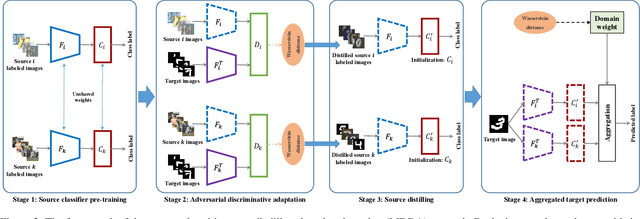
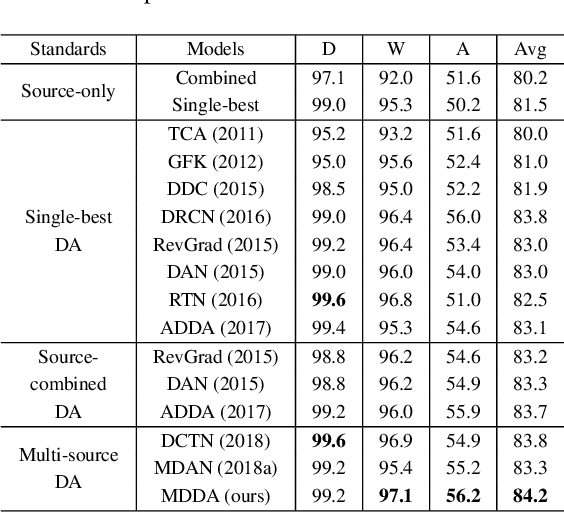
Deep neural networks suffer from performance decay when there is domain shift between the labeled source domain and unlabeled target domain, which motivates the research on domain adaptation (DA). Conventional DA methods usually assume that the labeled data is sampled from a single source distribution. However, in practice, labeled data may be collected from multiple sources, while naive application of the single-source DA algorithms may lead to suboptimal solutions. In this paper, we propose a novel multi-source distilling domain adaptation (MDDA) network, which not only considers the different distances among multiple sources and the target, but also investigates the different similarities of the source samples to the target ones. Specifically, the proposed MDDA includes four stages: (1) pre-train the source classifiers separately using the training data from each source; (2) adversarially map the target into the feature space of each source respectively by minimizing the empirical Wasserstein distance between source and target; (3) select the source training samples that are closer to the target to fine-tune the source classifiers; and (4) classify each encoded target feature by corresponding source classifier, and aggregate different predictions using respective domain weight, which corresponds to the discrepancy between each source and target. Extensive experiments are conducted on public DA benchmarks, and the results demonstrate that the proposed MDDA significantly outperforms the state-of-the-art approaches. Our source code is released at: https://github.com/daoyuan98/MDDA.
Multi-source Domain Adaptation for Semantic Segmentation
Oct 27, 2019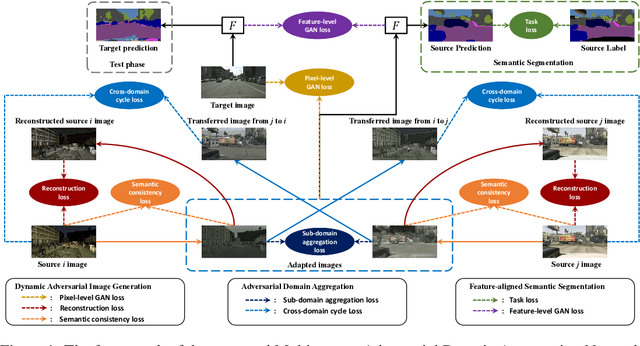

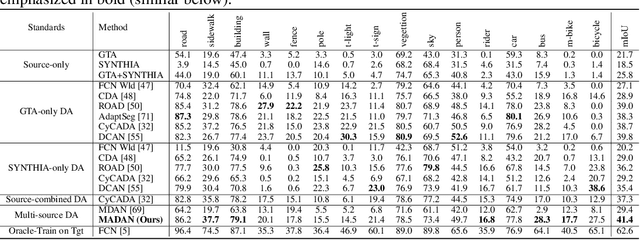

Simulation-to-real domain adaptation for semantic segmentation has been actively studied for various applications such as autonomous driving. Existing methods mainly focus on a single-source setting, which cannot easily handle a more practical scenario of multiple sources with different distributions. In this paper, we propose to investigate multi-source domain adaptation for semantic segmentation. Specifically, we design a novel framework, termed Multi-source Adversarial Domain Aggregation Network (MADAN), which can be trained in an end-to-end manner. First, we generate an adapted domain for each source with dynamic semantic consistency while aligning at the pixel-level cycle-consistently towards the target. Second, we propose sub-domain aggregation discriminator and cross-domain cycle discriminator to make different adapted domains more closely aggregated. Finally, feature-level alignment is performed between the aggregated domain and target domain while training the segmentation network. Extensive experiments from synthetic GTA and SYNTHIA to real Cityscapes and BDDS datasets demonstrate that the proposed MADAN model outperforms state-of-the-art approaches. Our source code is released at: https://github.com/Luodian/MADAN.
Drawing early-bird tickets: Towards more efficient training of deep networks
Sep 26, 2019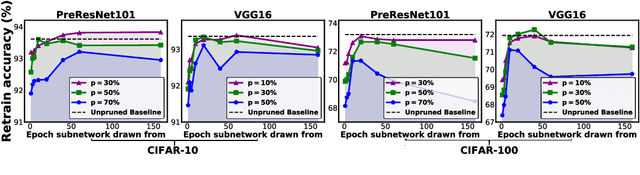
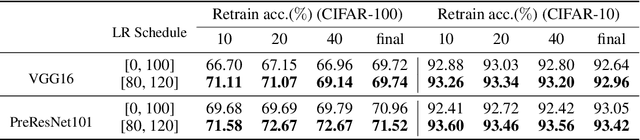
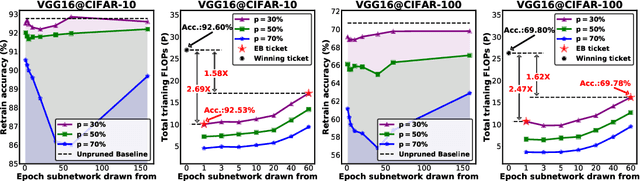
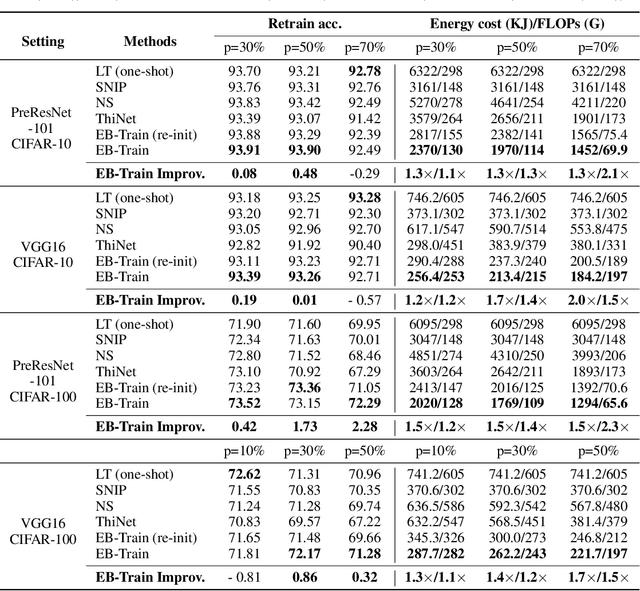
(Frankle & Carbin, 2019) shows that there exist winning tickets (small but critical subnetworks) for dense, randomly initialized networks, that can be trained alone to achieve comparable accuracies to the latter in a similar number of iterations. However, the identification of these winning tickets still requires the costly train-prune-retrain process, limiting their practical benefits. In this paper, we discover for the first time that the winning tickets can be identified at the very early training stage, which we term as early-bird (EB) tickets, via low-cost training schemes (e.g., early stopping and low-precision training) at large learning rates. Our finding of EB tickets is consistent with recently reported observations that the key connectivity patterns of neural networks emerge early. Furthermore, we propose a mask distance metric that can be used to identify EB tickets with low computational overhead, without needing to know the true winning tickets that emerge after the full training. Finally, we leverage the existence of EB tickets and the proposed mask distance to develop efficient training methods, which are achieved by first identifying EB tickets via low-cost schemes, and then continuing to train merely the EB tickets towards the target accuracy. Experiments based on various deep networks and datasets validate: 1) the existence of EB tickets, and the effectiveness of mask distance in efficiently identifying them; and 2) that the proposed efficient training via EB tickets can achieve up to 4.7x energy savings while maintaining comparable or even better accuracy, demonstrating a promising and easily adopted method for tackling cost-prohibitive deep network training.
ROAM: Recurrently Optimizing Tracking Model
Jul 31, 2019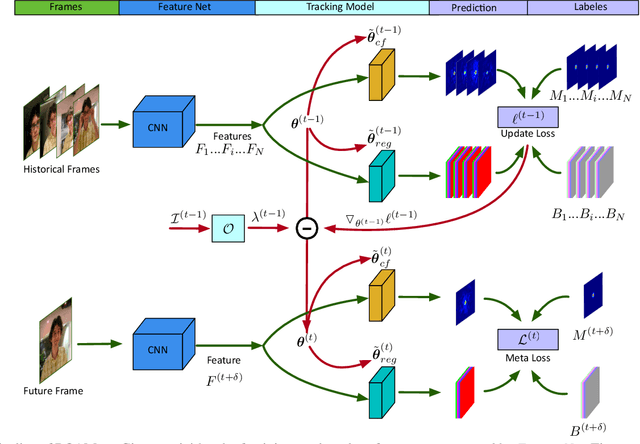
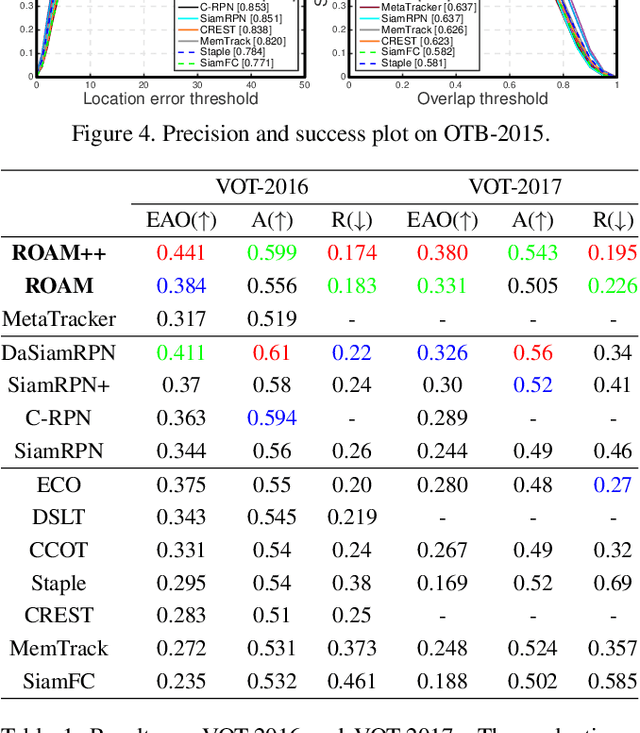
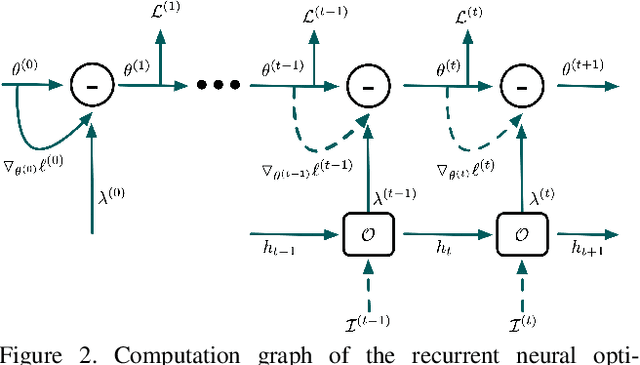
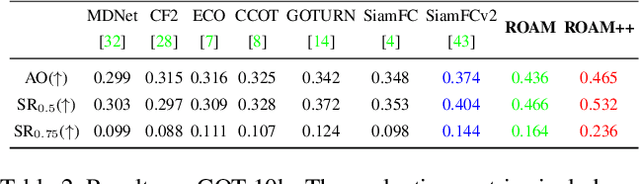
In this paper, we design a tracking model consisting of response generation and bounding box regression, where the first component produces a heat map to indicate the presence of the object at different positions and the second part regresses the relative bounding box shifts to anchors mounted on sliding-window locations. Thanks to the resizable convolutional filters used in both components to adapt to the shape changes of objects, our tracking model does not need to enumerate different sized anchors, thus saving model parameters. To effectively adapt the model to appearance variations, we propose to offline train a recurrent neural optimizer to update tracking model in a meta-learning setting, which can converge the model in a few gradient steps. This improves the convergence speed of updating the tracking model while achieving better performance. Moreover, we also propose a simple yet effective training trick called Random Filter Scaling to prevent overfitting, which boosts the generalization performance greatly. Finally, we extensively evaluate our trackers, ROAM and ROAM++, on the OTB, VOT, LaSOT, GOT-10K and TrackingNet benchmark and our methods perform favorably against state-of-the-art algorithms.
Dual Dynamic Inference: Enabling More Efficient, Adaptive and Controllable Deep Inference
Jul 17, 2019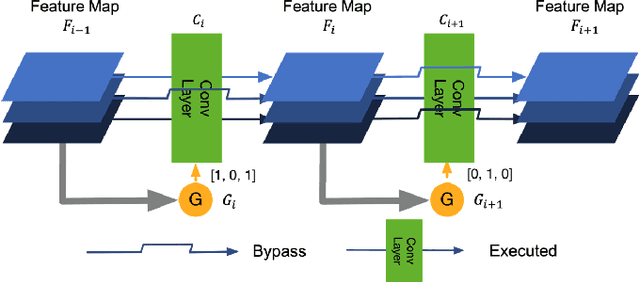
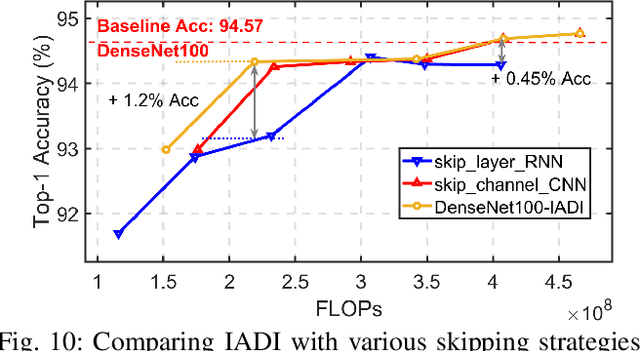
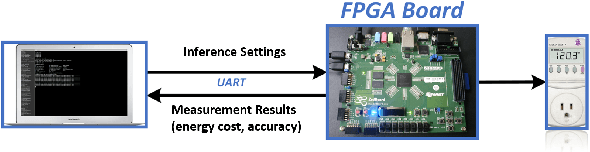
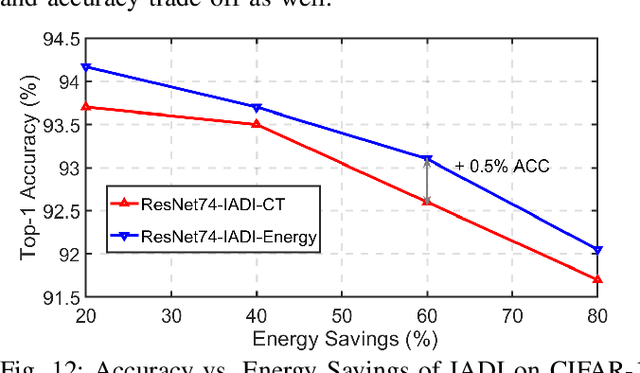
State-of-the-art convolutional neural networks (CNNs) yield record-breaking predictive performance, yet at the cost of high-energy-consumption inference, that prohibits their widely deployments in resource-constrained Internet of Things (IoT) applications. We propose a dual dynamic inference (DDI) framework that highlights the following aspects: 1) we integrate both input-dependent and resource-dependent dynamic inference mechanisms under a unified framework in order to fit the varying IoT resource requirements in practice. DDI is able to both constantly suppress unnecessary costs for easy samples, and to halt inference for all samples to meet hard resource constraints enforced; 2) we propose a flexible multi-grained learning to skip (MGL2S) approach for input-dependent inference which allows simultaneous layer-wise and channel-wise skipping; 3) we extend DDI to complex CNN backbones such as DenseNet and show that DDI can be applied towards optimizing any specific resource goals including inference latency or energy cost. Extensive experiments demonstrate the superior inference accuracy-resource trade-off achieved by DDI, as well as the flexibility to control such trade-offs compared to existing peer methods. Specifically, DDI can achieve up to 4 times computational savings with the same or even higher accuracy as compared to existing competitive baselines.
Performance Evaluation of Deep Learning Tools in Docker Containers
Nov 09, 2017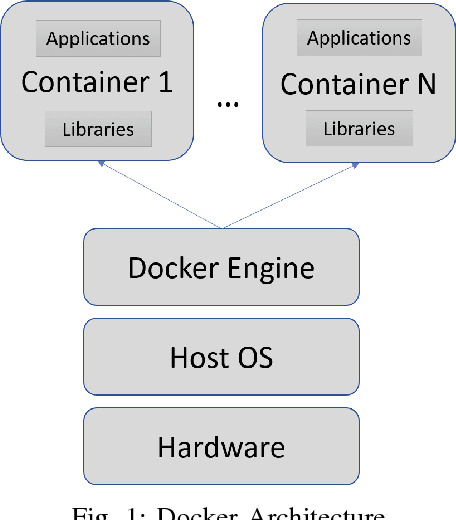
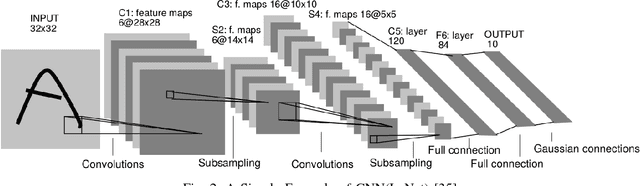
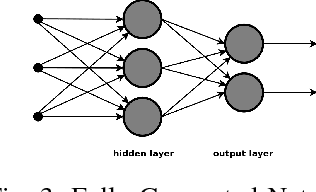
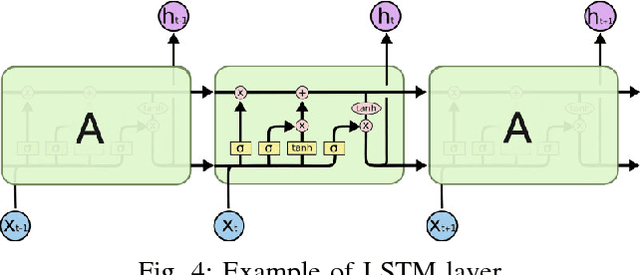
With the success of deep learning techniques in a broad range of application domains, many deep learning software frameworks have been developed and are being updated frequently to adapt to new hardware features and software libraries, which bring a big challenge for end users and system administrators. To address this problem, container techniques are widely used to simplify the deployment and management of deep learning software. However, it remains unknown whether container techniques bring any performance penalty to deep learning applications. The purpose of this work is to systematically evaluate the impact of docker container on the performance of deep learning applications. We first benchmark the performance of system components (IO, CPU and GPU) in a docker container and the host system and compare the results to see if there's any difference. According to our results, we find that computational intensive jobs, either running on CPU or GPU, have small overhead indicating docker containers can be applied to deep learning programs. Then we evaluate the performance of some popular deep learning tools deployed in a docker container and the host system. It turns out that the docker container will not cause noticeable drawbacks while running those deep learning tools. So encapsulating deep learning tool in a container is a feasible solution.
Benchmarking State-of-the-Art Deep Learning Software Tools
Feb 17, 2017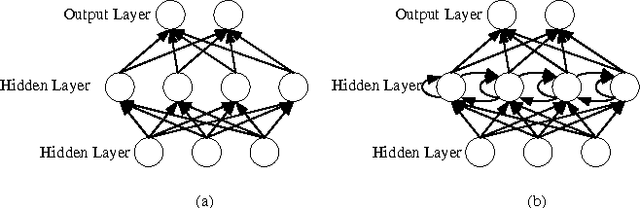

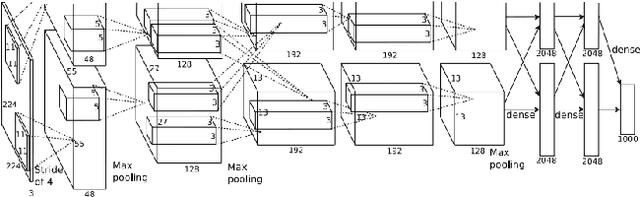
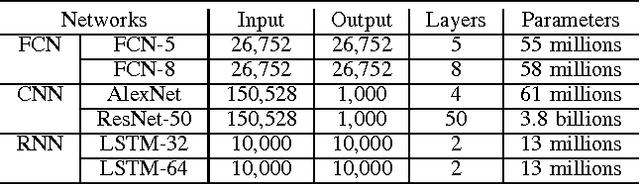
Deep learning has been shown as a successful machine learning method for a variety of tasks, and its popularity results in numerous open-source deep learning software tools. Training a deep network is usually a very time-consuming process. To address the computational challenge in deep learning, many tools exploit hardware features such as multi-core CPUs and many-core GPUs to shorten the training time. However, different tools exhibit different features and running performance when training different types of deep networks on different hardware platforms, which makes it difficult for end users to select an appropriate pair of software and hardware. In this paper, we aim to make a comparative study of the state-of-the-art GPU-accelerated deep learning software tools, including Caffe, CNTK, MXNet, TensorFlow, and Torch. We first benchmark the running performance of these tools with three popular types of neural networks on two CPU platforms and three GPU platforms. We then benchmark some distributed versions on multiple GPUs. Our contribution is two-fold. First, for end users of deep learning tools, our benchmarking results can serve as a guide to selecting appropriate hardware platforms and software tools. Second, for software developers of deep learning tools, our in-depth analysis points out possible future directions to further optimize the running performance.