 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum CycleGAN for Textual Sentiment Domain Adaptation with Multiple Sources
Nov 17, 2020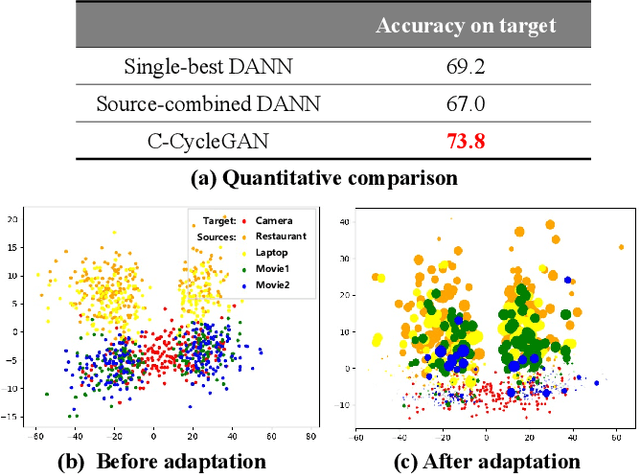
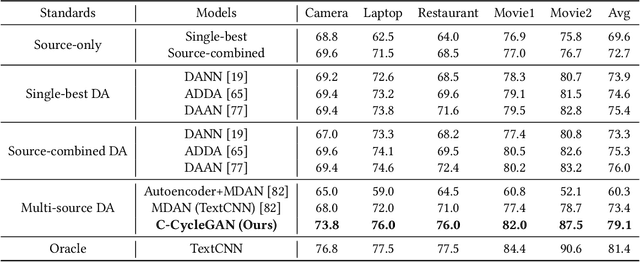
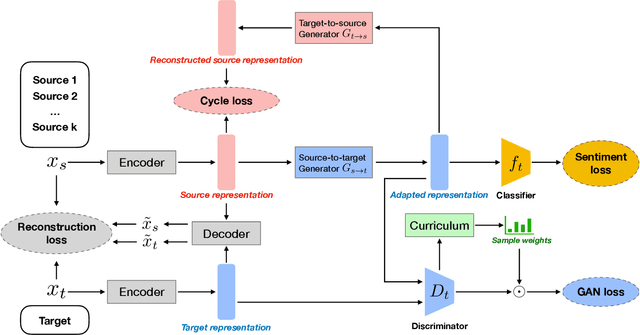
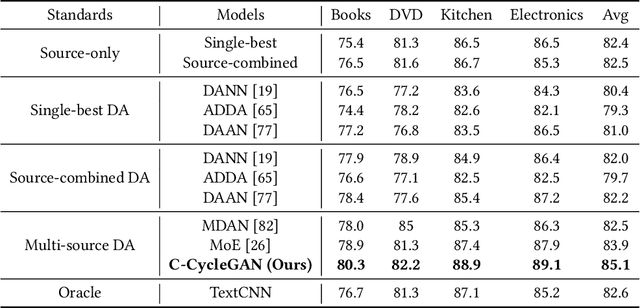
Sentiment analysis of user-generated reviews or comments on products and services on social media can help enterprises to analyze the feedback from customers and take corresponding actions for improvement. To mitigate large-scale annotations, domain adaptation (DA) provides an alternate solution by learning a transferable model from another labeled source domain. Since the labeled data may be from multiple sources, multi-source domain adaptation (MDA) would be more practical to exploit the complementary information from different domains. Existing MDA methods might fail to extract some discriminative features in the target domain that are related to sentiment, neglect the correlations of different sources as well as the distribution difference among different sub-domains even in the same source, and cannot reflect the varying optimal weighting during different training stages. In this paper, we propose an instance-level multi-source domain adaptation framework, named curriculum cycle-consistent generative adversarial network (C-CycleGAN). Specifically, C-CycleGAN consists of three components: (1) pre-trained text encoder which encodes textual input from different domains into a continuous representation space, (2) intermediate domain generator with curriculum instance-level adaptation which bridges the gap across source and target domains, and (3) task classifier trained on the intermediate domain for final sentiment classification. C-CycleGAN transfers source samples at an instance-level to an intermediate domain that is closer to target domain with sentiment semantics preserved and without losing discriminative features. Further, our dynamic instance-level weighting mechanisms can assign the optimal weights to different source samples in each training stage. We conduct extensive experiments on three benchmark datasets and achieve substantial gains over state-of-the-art approaches.
ePointDA: An End-to-End Simulation-to-Real Domain Adaptation Framework for LiDAR Point Cloud Segmentation
Sep 07, 2020
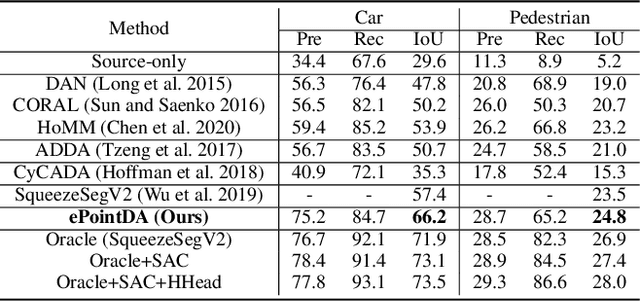
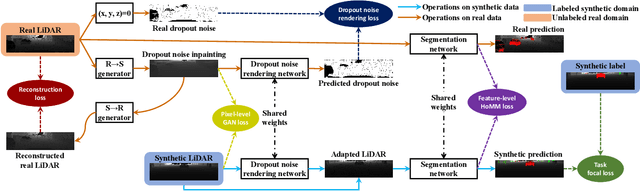
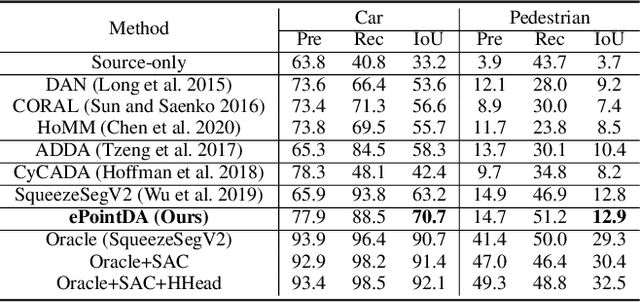
Due to its robust and precise distance measurements, LiDAR plays an important role in scene understanding for autonomous driving. Training deep neural networks (DNNs) on LiDAR data requires large-scale point-wise annotations, which are time-consuming and expensive to obtain. Instead, simulation-to-real domain adaptation (SRDA) trains a DNN using unlimited synthetic data with automatically generated labels and transfers the learned model to real scenarios. Existing SRDA methods for LiDAR point cloud segmentation mainly employ a multi-stage pipeline and focus on feature-level alignment. They require prior knowledge of real-world statistics and ignore the pixel-level dropout noise gap and the spatial feature gap between different domains. In this paper, we propose a novel end-to-end framework, named ePointDA, to address the above issues. Specifically, ePointDA consists of three components: self-supervised dropout noise rendering, statistics-invariant and spatially-adaptive feature alignment, and transferable segmentation learning. The joint optimization enables ePointDA to bridge the domain shift at the pixel-level by explicitly rendering dropout noise for synthetic LiDAR and at the feature-level by spatially aligning the features between different domains, without requiring the real-world statistics. Extensive experiments adapting from synthetic GTA-LiDAR to real KITTI and SemanticKITTI demonstrate the superiority of ePointDA for LiDAR point cloud segmentation.
Emotion-Based End-to-End Matching Between Image and Music in Valence-Arousal Space
Aug 22, 2020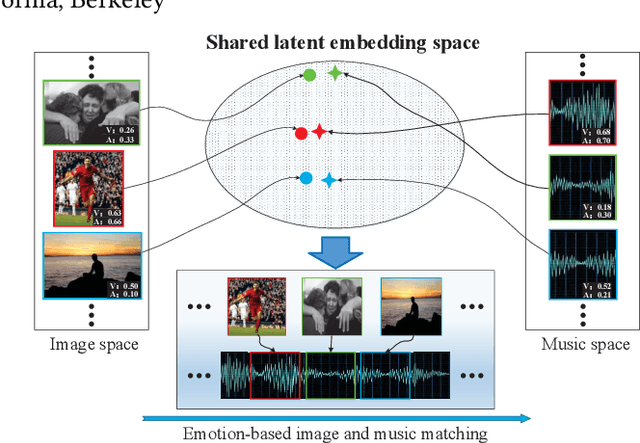
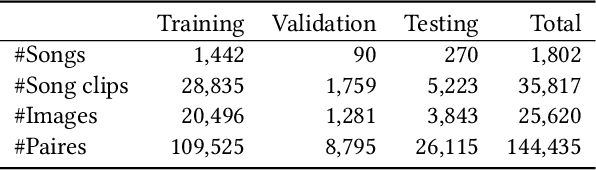
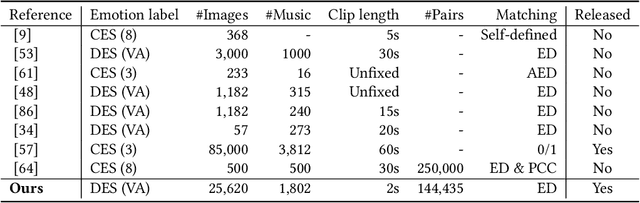
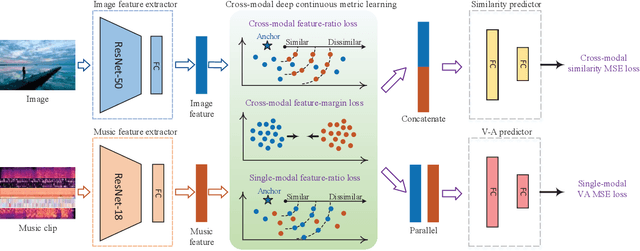
Both images and music can convey rich semantics and are widely used to induce specific emotions. Matching images and music with similar emotions might help to make emotion perceptions more vivid and stronger. Existing emotion-based image and music matching methods either employ limited categorical emotion states which cannot well reflect the complexity and subtlety of emotions, or train the matching model using an impractical multi-stage pipeline. In this paper, we study end-to-end matching between image and music based on emotions in the continuous valence-arousal (VA) space. First, we construct a large-scale dataset, termed Image-Music-Emotion-Matching-Net (IMEMNet), with over 140K image-music pairs. Second, we propose cross-modal deep continuous metric learning (CDCML) to learn a shared latent embedding space which preserves the cross-modal similarity relationship in the continuous matching space. Finally, we refine the embedding space by further preserving the single-modal emotion relationship in the VA spaces of both images and music. The metric learning in the embedding space and task regression in the label space are jointly optimized for both cross-modal matching and single-modal VA prediction. The extensive experiments conducted on IMEMNet demonstrate the superiority of CDCML for emotion-based image and music matching as compared to the state-of-the-art approaches.
Rethinking Distributional Matching Based Domain Adaptation
Jul 03, 2020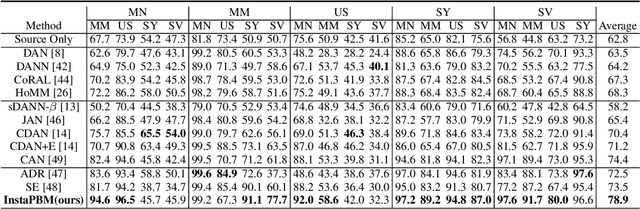
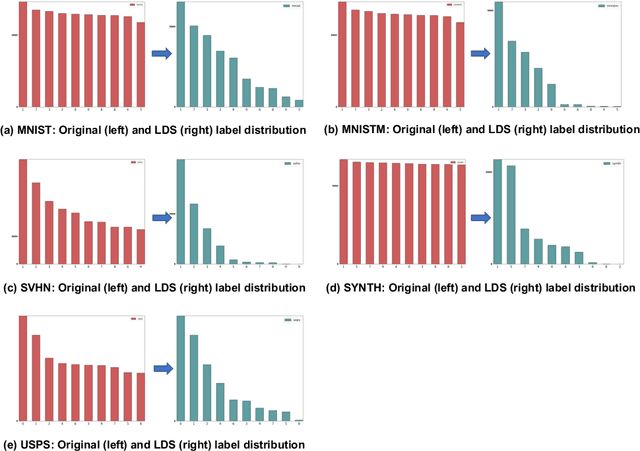
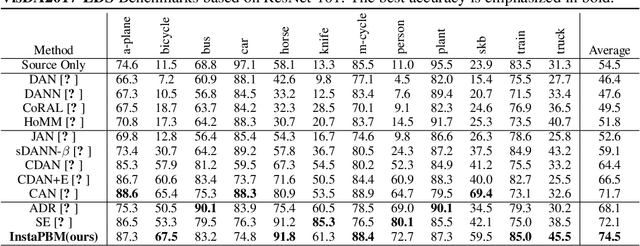
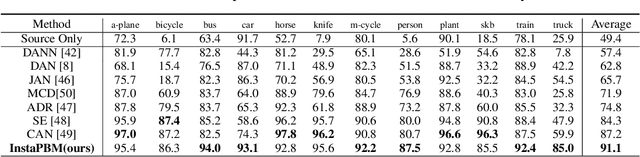
Domain adaptation (DA) is a technique that transfers predictive models trained on a labeled source domain to an unlabeled target domain, with the core difficulty of resolving distributional shift between domains. Currently, most popular DA algorithms are based on distributional matching (DM). However in practice, realistic domain shifts (RDS) may violate their basic assumptions and as a result these methods will fail. In this paper, in order to devise robust DA algorithms, we first systematically analyze the limitations of DM based methods, and then build new benchmarks with more realistic domain shifts to evaluate the well-accepted DM methods. We further propose InstaPBM, a novel Instance-based Predictive Behavior Matching method for robust DA. Extensive experiments on both conventional and RDS benchmarks demonstrate both the limitations of DM methods and the efficacy of InstaPBM: Compared with the best baselines, InstaPBM improves the classification accuracy respectively by $4.5\%$, $3.9\%$ on Digits5, VisDA2017, and $2.2\%$, $2.9\%$, $3.6\%$ on DomainNet-LDS, DomainNet-ILDS, ID-TwO. We hope our intuitive yet effective method will serve as a useful new direction and increase the robustness of DA in real scenarios. Code will be available at anonymous link: https://github.com/pikachusocute/InstaPBM-RobustDA.
TIMELY: Pushing Data Movements and Interfaces in PIM Accelerators Towards Local and in Time Domain
May 03, 2020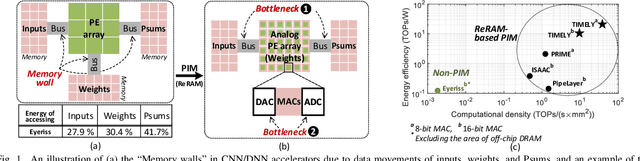
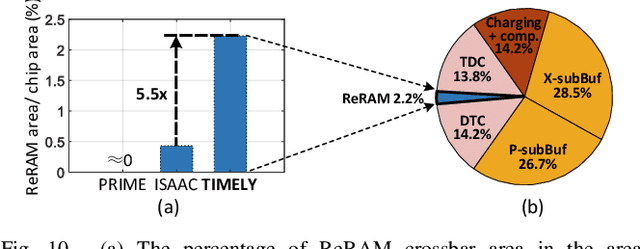
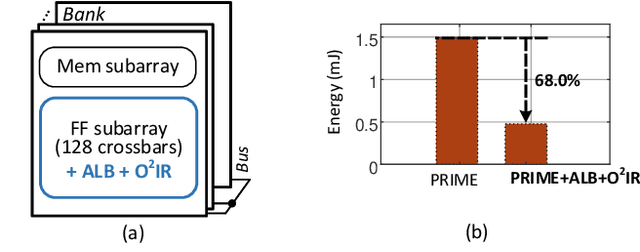
Resistive-random-access-memory (ReRAM) based processing-in-memory (R$^2$PIM) accelerators show promise in bridging the gap between Internet of Thing devices' constrained resources and Convolutional/Deep Neural Networks' (CNNs/DNNs') prohibitive energy cost. Specifically, R$^2$PIM accelerators enhance energy efficiency by eliminating the cost of weight movements and improving the computational density through ReRAM's high density. However, the energy efficiency is still limited by the dominant energy cost of input and partial sum (Psum) movements and the cost of digital-to-analog (D/A) and analog-to-digital (A/D) interfaces. In this work, we identify three energy-saving opportunities in R$^2$PIM accelerators: analog data locality, time-domain interfacing, and input access reduction, and propose an innovative R$^2$PIM accelerator called TIMELY, with three key contributions: (1) TIMELY adopts analog local buffers (ALBs) within ReRAM crossbars to greatly enhance the data locality, minimizing the energy overheads of both input and Psum movements; (2) TIMELY largely reduces the energy of each single D/A (and A/D) conversion and the total number of conversions by using time-domain interfaces (TDIs) and the employed ALBs, respectively; (3) we develop an only-once input read (O$^2$IR) mapping method to further decrease the energy of input accesses and the number of D/A conversions. The evaluation with more than 10 CNN/DNN models and various chip configurations shows that, TIMELY outperforms the baseline R$^2$PIM accelerator, PRIME, by one order of magnitude in energy efficiency while maintaining better computational density (up to 31.2$\times$) and throughput (up to 736.6$\times$). Furthermore, comprehensive studies are performed to evaluate the effectiveness of the proposed ALB, TDI, and O$^2$IR innovations in terms of energy savings and area reduction.
Multi-source Domain Adaptation in the Deep Learning Era: A Systematic Survey
Feb 26, 2020
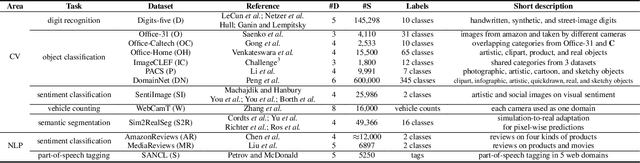
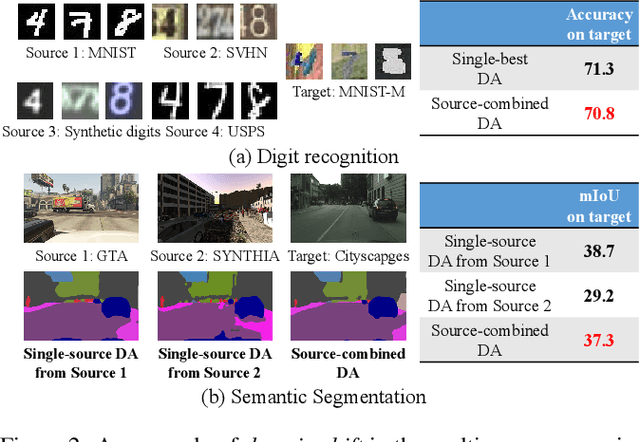
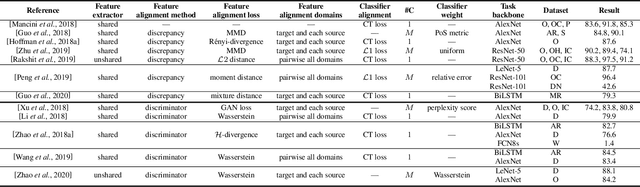
In many practical applications, it is often difficult and expensive to obtain enough large-scale labeled data to train deep neural networks to their full capability. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) addresses this problem by minimizing the impact of domain shift between the source and target domains. Multi-source domain adaptation (MDA) is a powerful extension in which the labeled data may be collected from multiple sources with different distributions. Due to the success of DA methods and the prevalence of multi-source data, MDA has attracted increasing attention in both academia and industry. In this survey, we define various MDA strategies and summarize available datasets for evaluation. We also compare modern MDA methods in the deep learning era, including latent space transformation and intermediate domain generation. Finally, we discuss future research directions for MDA.
DNN-Chip Predictor: An Analytical Performance Predictor for DNN Accelerators with Various Dataflows and Hardware Architectures
Feb 26, 2020
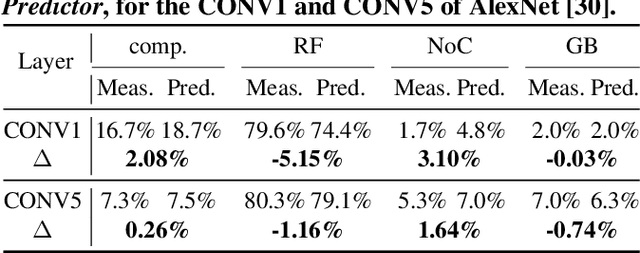
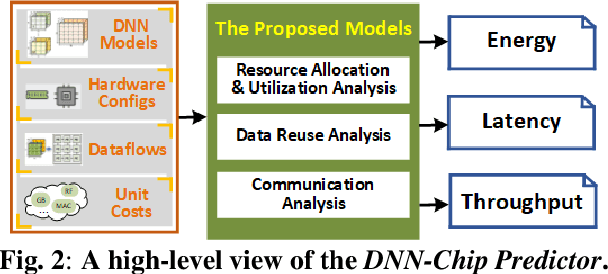
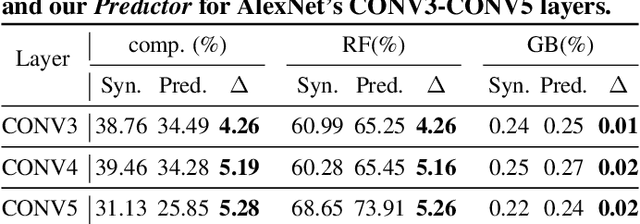
The recent breakthroughs in deep neural networks (DNNs) have spurred a tremendously increased demand for DNN accelerators. However, designing DNN accelerators is non-trivial as it often takes months/years and requires cross-disciplinary knowledge. To enable fast and effective DNN accelerator development, we propose DNN-Chip Predictor, an analytical performance predictor which can accurately predict DNN accelerators' energy, throughput, and latency prior to their actual implementation. Our Predictor features two highlights: (1) its analytical performance formulation of DNN ASIC/FPGA accelerators facilitates fast design space exploration and optimization; and (2) it supports DNN accelerators with different algorithm-to-hardware mapping methods (i.e., dataflows) and hardware architectures. Experiment results based on 2 DNN models and 3 different ASIC/FPGA implementations show that our DNN-Chip Predictor's predicted performance differs from those of chip measurements of FPGA/ASIC implementation by no more than 17.66% when using different DNN models, hardware architectures, and dataflows. We will release code upon acceptance.
MADAN: Multi-source Adversarial Domain Aggregation Network for Domain Adaptation
Feb 19, 2020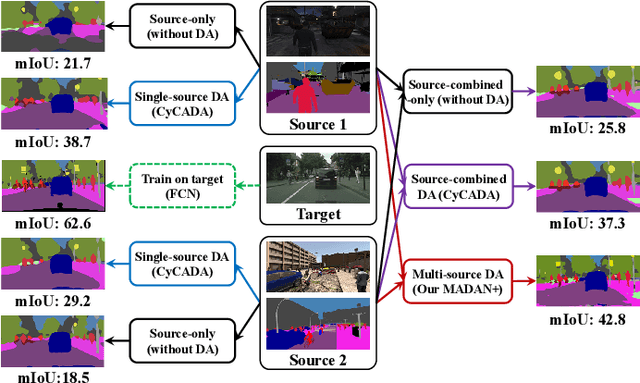

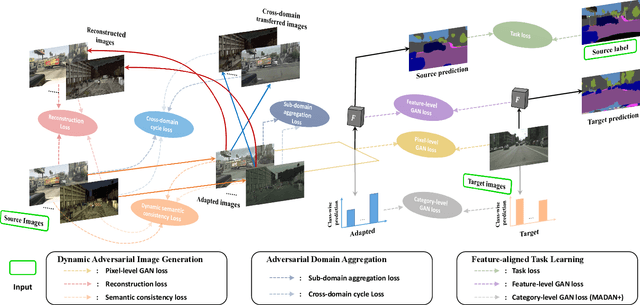
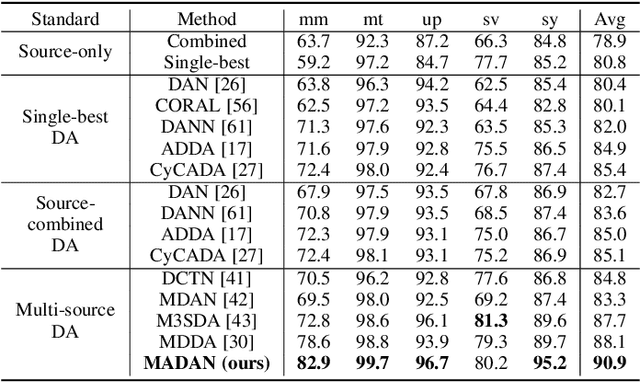
Domain adaptation aims to learn a transferable model to bridge the domain shift between one labeled source domain and another sparsely labeled or unlabeled target domain. Since the labeled data may be collected from multiple sources, multi-source domain adaptation (MDA) has attracted increasing attention. Recent MDA methods do not consider the pixel-level alignment between sources and target or the misalignment across different sources. In this paper, we propose a novel MDA framework to address these challenges. Specifically, we design an end-to-end Multi-source Adversarial Domain Aggregation Network (MADAN). First, an adapted domain is generated for each source with dynamic semantic consistency while aligning towards the target at the pixel-level cycle-consistently. Second, sub-domain aggregation discriminator and cross-domain cycle discriminator are proposed to make different adapted domains more closely aggregated. Finally, feature-level alignment is performed between the aggregated domain and the target domain while training the task network. For the segmentation adaptation, we further enforce category-level alignment and incorporate context-aware generation, which constitutes MADAN+. We conduct extensive MDA experiments on digit recognition, object classification, and simulation-to-real semantic segmentation. The results demonstrate that the proposed MADAN and MANDA+ models outperform state-of-the-art approaches by a large margin.
An End-to-End Visual-Audio Attention Network for Emotion Recognition in User-Generated Videos
Feb 12, 2020

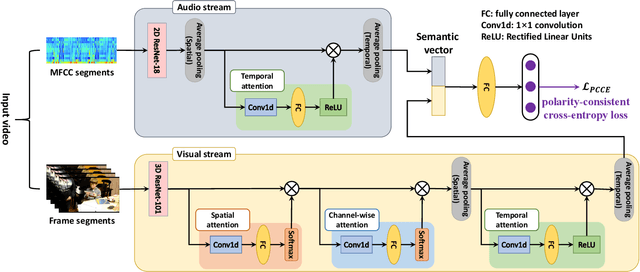

Emotion recognition in user-generated videos plays an important role in human-centered computing. Existing methods mainly employ traditional two-stage shallow pipeline, i.e. extracting visual and/or audio features and training classifiers. In this paper, we propose to recognize video emotions in an end-to-end manner based on convolutional neural networks (CNNs). Specifically, we develop a deep Visual-Audio Attention Network (VAANet), a novel architecture that integrates spatial, channel-wise, and temporal attentions into a visual 3D CNN and temporal attentions into an audio 2D CNN. Further, we design a special classification loss, i.e. polarity-consistent cross-entropy loss, based on the polarity-emotion hierarchy constraint to guide the attention generation. Extensive experiments conducted on the challenging VideoEmotion-8 and Ekman-6 datasets demonstrate that the proposed VAANet outperforms the state-of-the-art approaches for video emotion recognition. Our source code is released at: https://github.com/maysonma/VAANet.
AutoDNNchip: An Automated DNN Chip Predictor and Builder for Both FPGAs and ASICs
Jan 06, 2020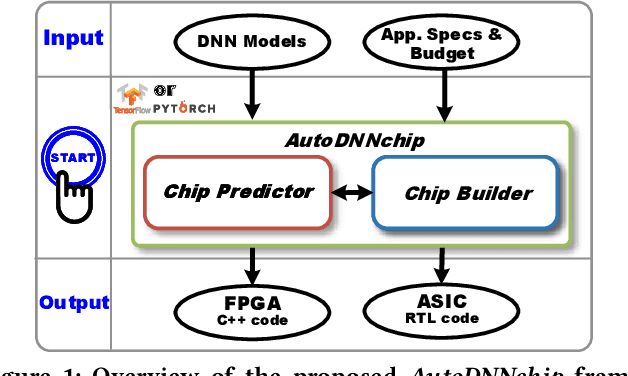
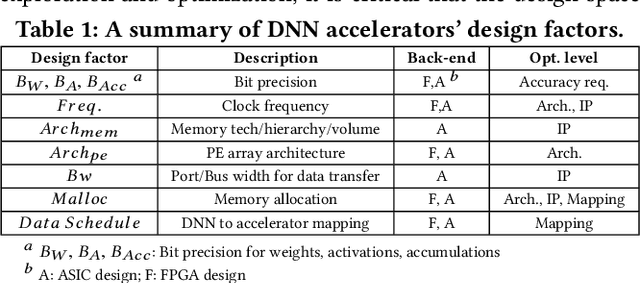
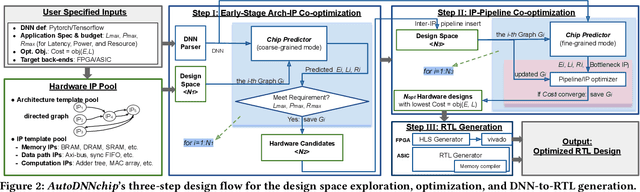

Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a growing demand for DNN chips. However, designing DNN chips is non-trivial because: (1) mainstream DNNs have millions of parameters and operations; (2) the large design space due to the numerous design choices of dataflows, processing elements, memory hierarchy, etc.; and (3) an algorithm/hardware co-design is needed to allow the same DNN functionality to have a different decomposition, which would require different hardware IPs to meet the application specifications. Therefore, DNN chips take a long time to design and require cross-disciplinary experts. To enable fast and effective DNN chip design, we propose AutoDNNchip - a DNN chip generator that can automatically generate both FPGA- and ASIC-based DNN chip implementation given DNNs from machine learning frameworks (e.g., PyTorch) for a designated application and dataset. Specifically, AutoDNNchip consists of two integrated enablers: (1) a Chip Predictor, built on top of a graph-based accelerator representation, which can accurately and efficiently predict a DNN accelerator's energy, throughput, and area based on the DNN model parameters, hardware configuration, technology-based IPs, and platform constraints; and (2) a Chip Builder, which can automatically explore the design space of DNN chips (including IP selection, block configuration, resource balancing, etc.), optimize chip design via the Chip Predictor, and then generate optimized synthesizable RTL to achieve the target design metrics. Experimental results show that our Chip Predictor's predicted performance differs from real-measured ones by < 10% when validated using 15 DNN models and 4 platforms (edge-FPGA/TPU/GPU and ASIC). Furthermore, accelerators generated by our AutoDNNchip can achieve better (up to 3.86X improvement) performance than that of expert-crafted state-of-the-art accelerators.