 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
LLMCO2: Advancing Accurate Carbon Footprint Prediction for LLM Inferences
Oct 03, 2024Throughout its lifecycle, a large language model (LLM) generates a substantially larger carbon footprint during inference than training. LLM inference requests vary in batch size, prompt length, and token generation number, while cloud providers employ different GPU types and quantities to meet diverse service-level objectives for accuracy and latency. It is crucial for both users and cloud providers to have a tool that quickly and accurately estimates the carbon impact of LLM inferences based on a combination of inference request and hardware configurations before execution. Estimating the carbon footprint of LLM inferences is more complex than training due to lower and highly variable model FLOPS utilization, rendering previous equation-based models inaccurate. Additionally, existing machine learning (ML) prediction methods either lack accuracy or demand extensive training data, as they inadequately handle the distinct prefill and decode phases, overlook hardware-specific features, and inefficiently sample uncommon inference configurations. We introduce \coo, a graph neural network (GNN)-based model that greatly improves the accuracy of LLM inference carbon footprint predictions compared to previous methods.
TIMELY: Pushing Data Movements and Interfaces in PIM Accelerators Towards Local and in Time Domain
May 03, 2020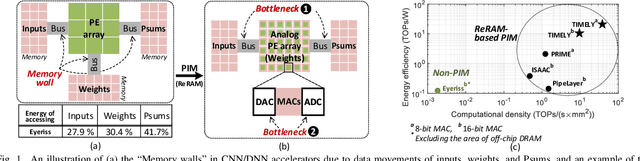
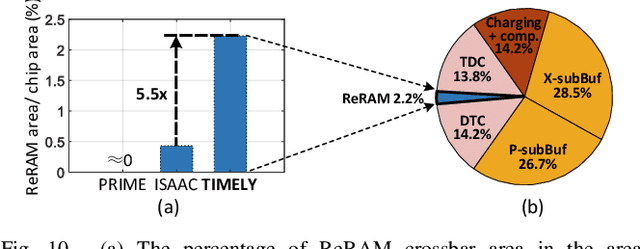
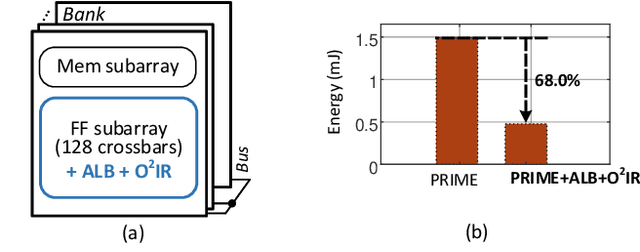
Resistive-random-access-memory (ReRAM) based processing-in-memory (R$^2$PIM) accelerators show promise in bridging the gap between Internet of Thing devices' constrained resources and Convolutional/Deep Neural Networks' (CNNs/DNNs') prohibitive energy cost. Specifically, R$^2$PIM accelerators enhance energy efficiency by eliminating the cost of weight movements and improving the computational density through ReRAM's high density. However, the energy efficiency is still limited by the dominant energy cost of input and partial sum (Psum) movements and the cost of digital-to-analog (D/A) and analog-to-digital (A/D) interfaces. In this work, we identify three energy-saving opportunities in R$^2$PIM accelerators: analog data locality, time-domain interfacing, and input access reduction, and propose an innovative R$^2$PIM accelerator called TIMELY, with three key contributions: (1) TIMELY adopts analog local buffers (ALBs) within ReRAM crossbars to greatly enhance the data locality, minimizing the energy overheads of both input and Psum movements; (2) TIMELY largely reduces the energy of each single D/A (and A/D) conversion and the total number of conversions by using time-domain interfaces (TDIs) and the employed ALBs, respectively; (3) we develop an only-once input read (O$^2$IR) mapping method to further decrease the energy of input accesses and the number of D/A conversions. The evaluation with more than 10 CNN/DNN models and various chip configurations shows that, TIMELY outperforms the baseline R$^2$PIM accelerator, PRIME, by one order of magnitude in energy efficiency while maintaining better computational density (up to 31.2$\times$) and throughput (up to 736.6$\times$). Furthermore, comprehensive studies are performed to evaluate the effectiveness of the proposed ALB, TDI, and O$^2$IR innovations in terms of energy savings and area reduction.
Hyperdimensional Computing Nanosystem
Nov 23, 2018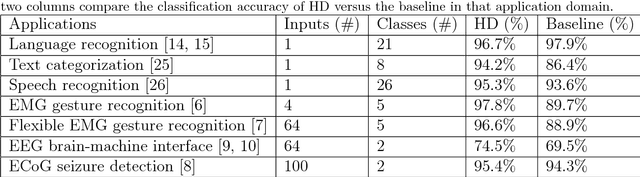
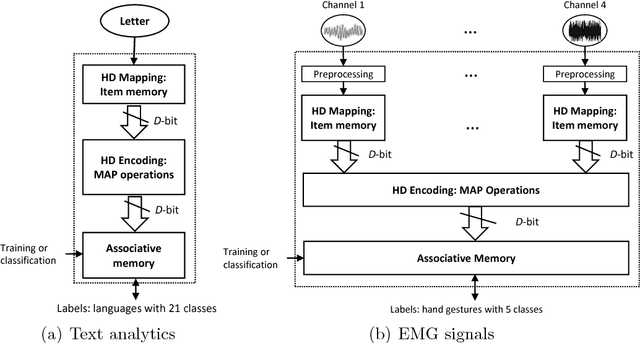
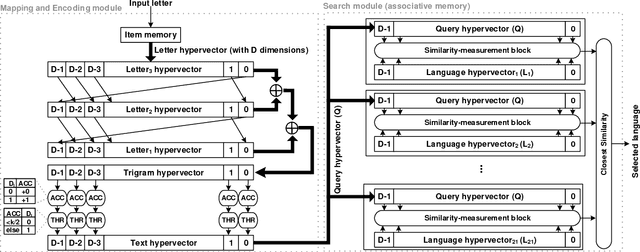
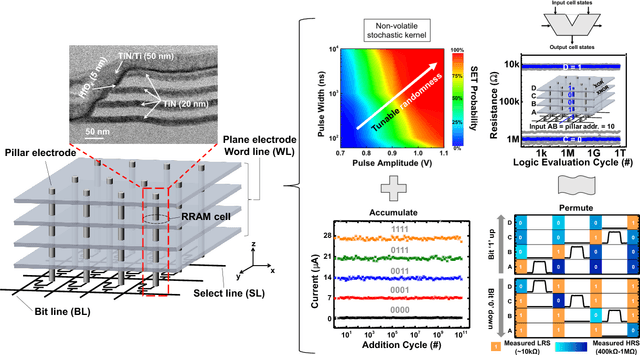
One viable solution for continuous reduction in energy-per-operation is to rethink functionality to cope with uncertainty by adopting computational approaches that are inherently robust to uncertainty. It requires a novel look at data representations, associated operations, and circuits, and at materials and substrates that enable them. 3D integrated nanotechnologies combined with novel brain-inspired computational paradigms that support fast learning and fault tolerance could lead the way. Recognizing the very size of the brain's circuits, hyperdimensional (HD) computing can model neural activity patterns with points in a HD space, that is, with hypervectors as large randomly generated patterns. At its very core, HD computing is about manipulating and comparing these patterns inside memory. Emerging nanotechnologies such as carbon nanotube field effect transistors (CNFETs) and resistive RAM (RRAM), and their monolithic 3D integration offer opportunities for hardware implementations of HD computing through tight integration of logic and memory, energy-efficient computation, and unique device characteristics. We experimentally demonstrate and characterize an end-to-end HD computing nanosystem built using monolithic 3D integration of CNFETs and RRAM. With our nanosystem, we experimentally demonstrate classification of 21 languages with measured accuracy of up to 98% on >20,000 sentences (6.4 million characters), training using one text sample (~100,000 characters) per language, and resilient operation (98% accuracy) despite 78% hardware errors in HD representation (outputs stuck at 0 or 1). By exploiting the unique properties of the underlying nanotechnologies, we show that HD computing, when implemented with monolithic 3D integration, can be up to 420X more energy-efficient while using 25X less area compared to traditional silicon CMOS implementations.