 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021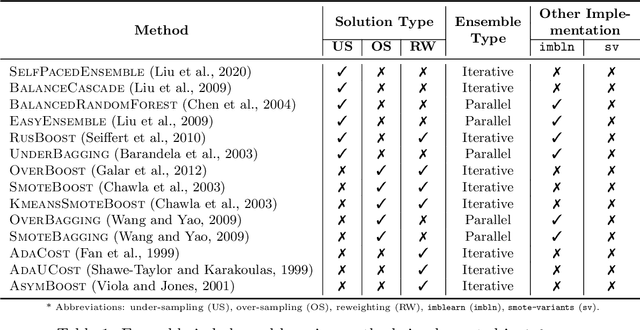
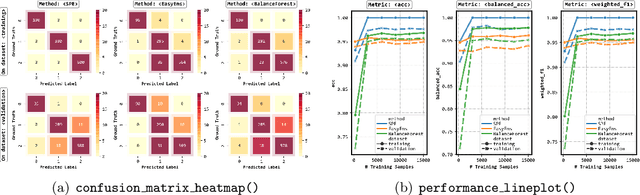
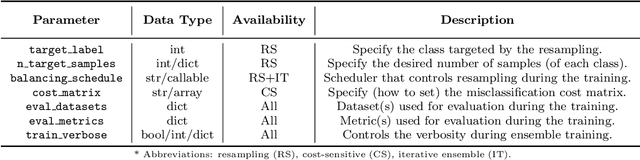
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.
Graph Domain Adaptation: A Generative View
Jun 14, 2021
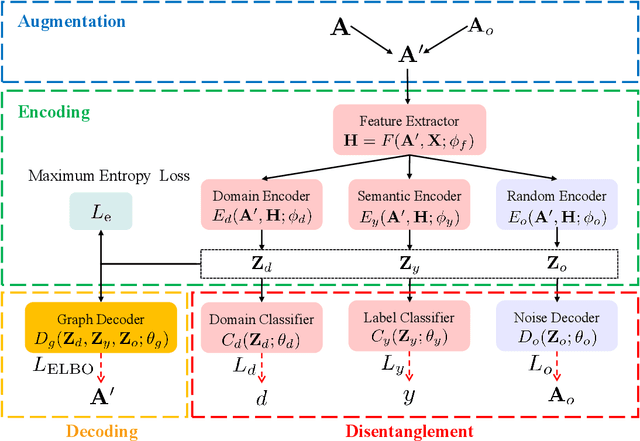
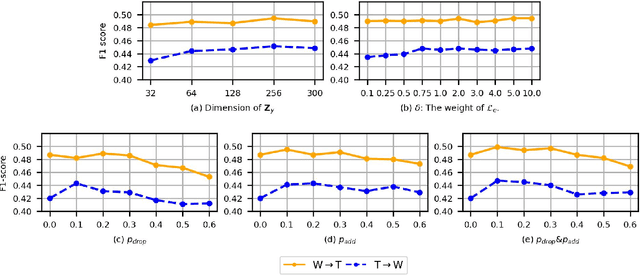
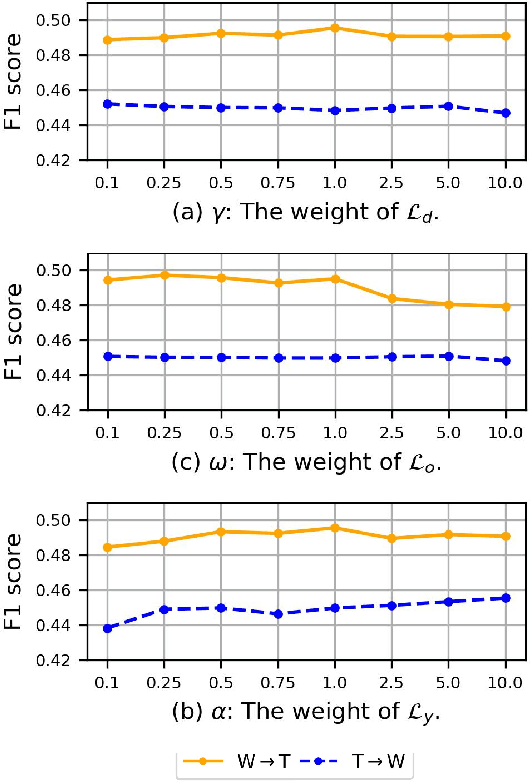
Recent years have witnessed tremendous interest in deep learning on graph-structured data. Due to the high cost of collecting labeled graph-structured data, domain adaptation is important to supervised graph learning tasks with limited samples. However, current graph domain adaptation methods are generally adopted from traditional domain adaptation tasks, and the properties of graph-structured data are not well utilized. For example, the observed social networks on different platforms are controlled not only by the different crowd or communities but also by the domain-specific policies and the background noise. Based on these properties in graph-structured data, we first assume that the graph-structured data generation process is controlled by three independent types of latent variables, i.e., the semantic latent variables, the domain latent variables, and the random latent variables. Based on this assumption, we propose a disentanglement-based unsupervised domain adaptation method for the graph-structured data, which applies variational graph auto-encoders to recover these latent variables and disentangles them via three supervised learning modules. Extensive experimental results on two real-world datasets in the graph classification task reveal that our method not only significantly outperforms the traditional domain adaptation methods and the disentangled-based domain adaptation methods but also outperforms the state-of-the-art graph domain adaptation algorithms.
Adaptive Multi-Source Causal Inference
May 31, 2021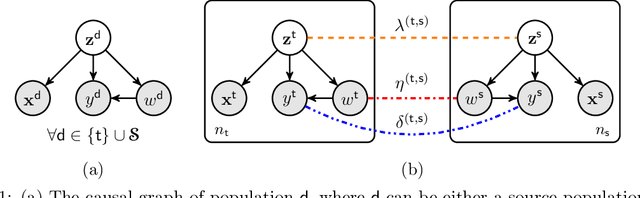
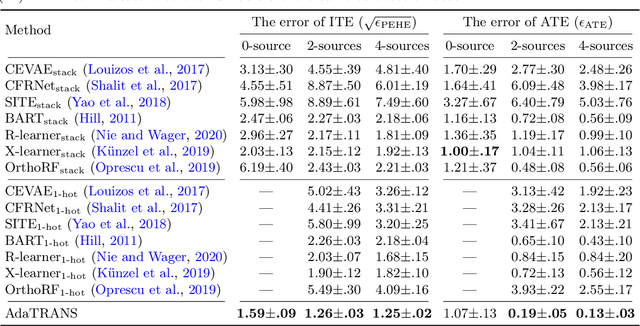
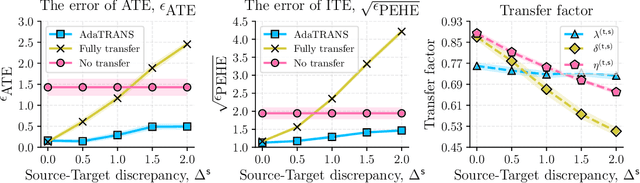
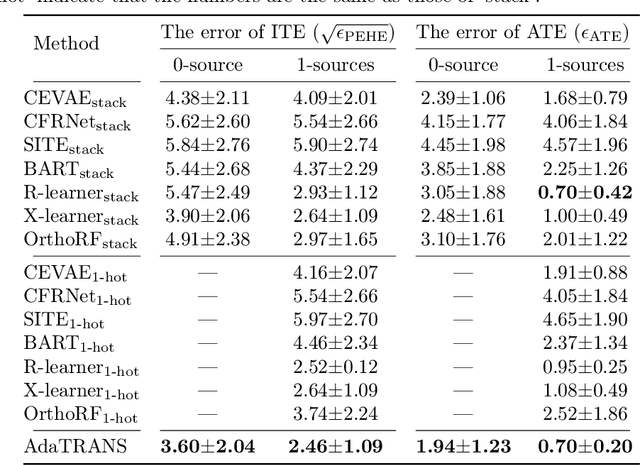
Data scarcity is a tremendous challenge in causal effect estimation. In this paper, we propose to exploit additional data sources to facilitate estimating causal effects in the target population. Specifically, we leverage additional source datasets which share similar causal mechanisms with the target observations to help infer causal effects of the target population. We propose three levels of knowledge transfer, through modelling the outcomes, treatments, and confounders. To achieve consistent positive transfer, we introduce learnable parametric transfer factors to adaptively control the transfer strength, and thus achieving a fair and balanced knowledge transfer between the sources and the target. The proposed method can infer causal effects in the target population without prior knowledge of data discrepancy between the additional data sources and the target. Experiments on both synthetic and real-world datasets show the effectiveness of the proposed method as compared with recent baselines.
Joint Intent Detection and Slot Filling with Wheel-Graph Attention Networks
Feb 09, 2021
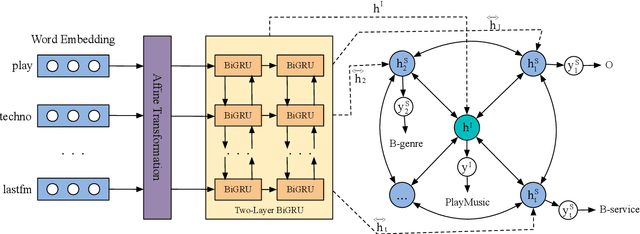
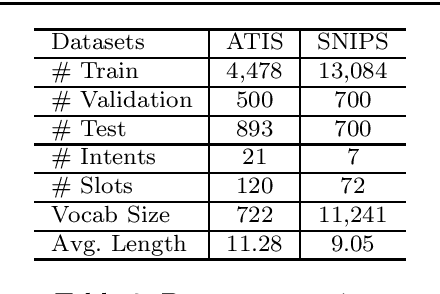
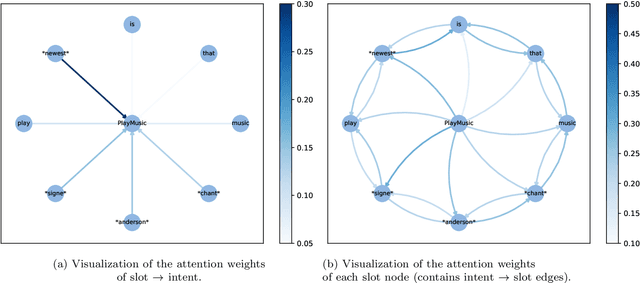
Intent detection and slot filling are two fundamental tasks for building a spoken language understanding (SLU) system. Multiple deep learning-based joint models have demonstrated excellent results on the two tasks. In this paper, we propose a new joint model with a wheel-graph attention network (Wheel-GAT) which is able to model interrelated connections directly for intent detection and slot filling. To construct a graph structure for utterances, we create intent nodes, slot nodes, and directed edges. Intent nodes can provide utterance-level semantic information for slot filling, while slot nodes can also provide local keyword information for intent. Experiments show that our model outperforms multiple baselines on two public datasets. Besides, we also demonstrate that using Bidirectional Encoder Representation from Transformer (BERT) model further boosts the performance in the SLU task.
Learning Disentangled Semantic Representation for Domain Adaptation
Dec 22, 2020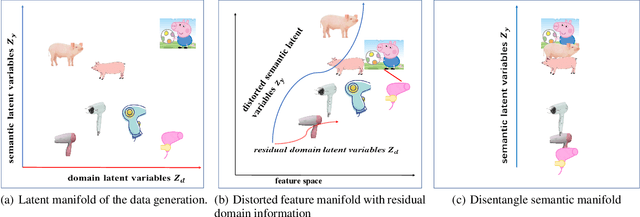
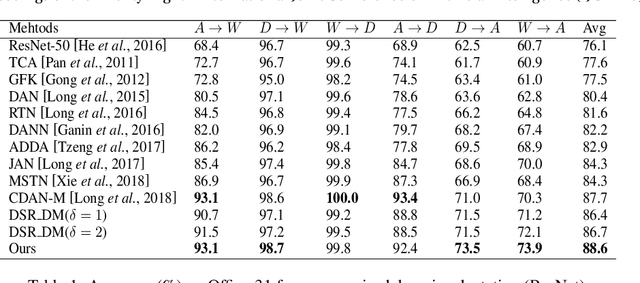
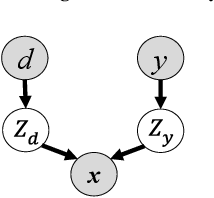
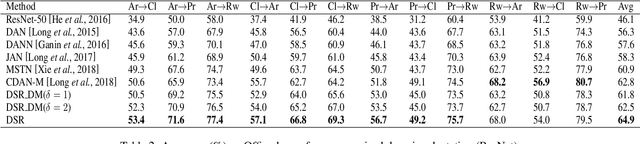
Domain adaptation is an important but challenging task. Most of the existing domain adaptation methods struggle to extract the domain-invariant representation on the feature space with entangling domain information and semantic information. Different from previous efforts on the entangled feature space, we aim to extract the domain invariant semantic information in the latent disentangled semantic representation (DSR) of the data. In DSR, we assume the data generation process is controlled by two independent sets of variables, i.e., the semantic latent variables and the domain latent variables. Under the above assumption, we employ a variational auto-encoder to reconstruct the semantic latent variables and domain latent variables behind the data. We further devise a dual adversarial network to disentangle these two sets of reconstructed latent variables. The disentangled semantic latent variables are finally adapted across the domains. Experimental studies testify that our model yields state-of-the-art performance on several domain adaptation benchmark datasets.
Randomized Transferable Machine
Nov 27, 2020
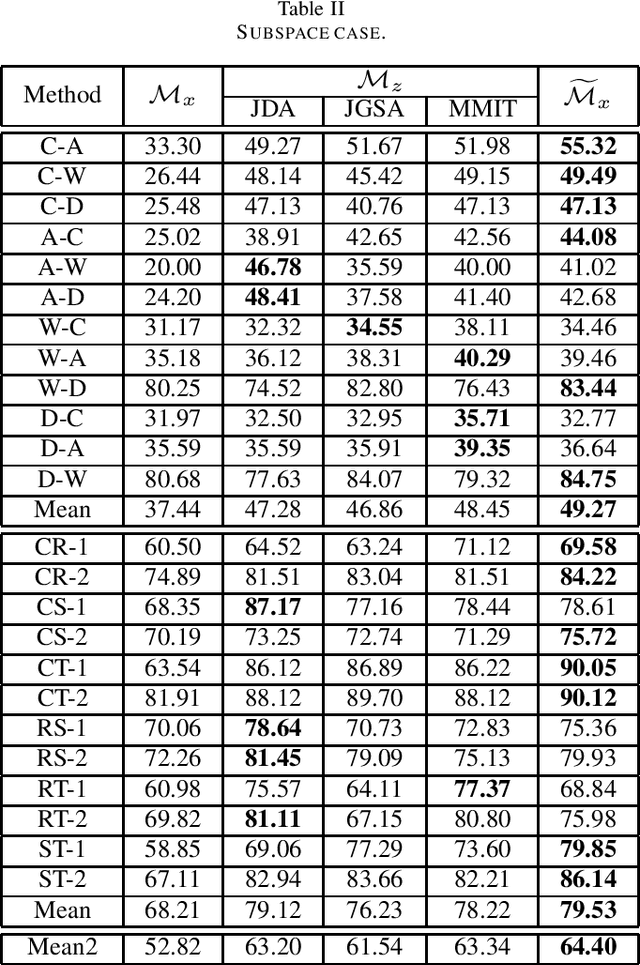
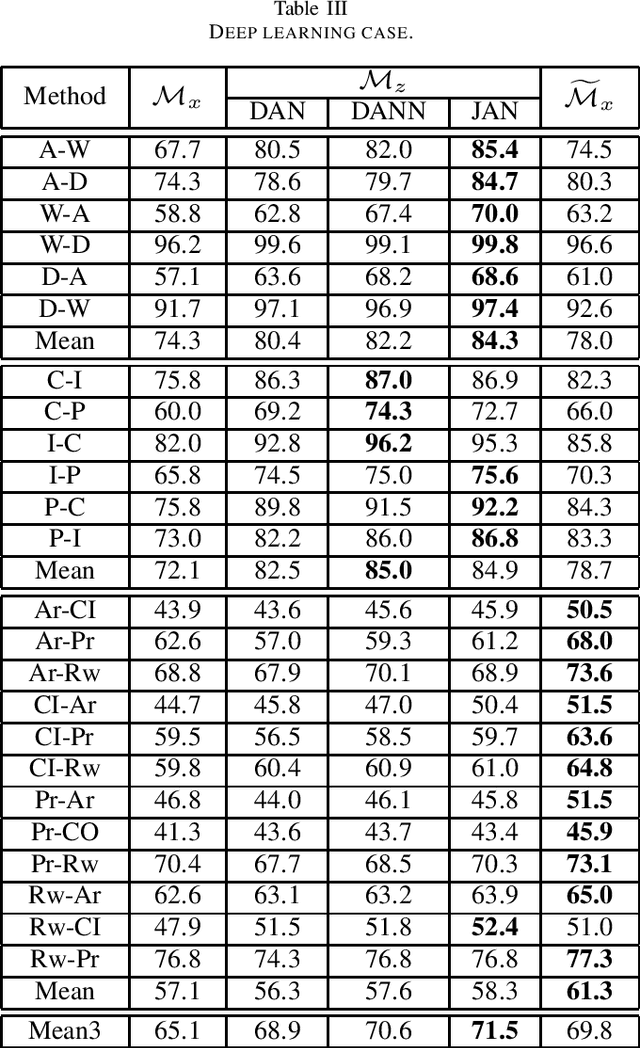
Feature-based transfer is one of the most effective methodologies for transfer learning. Existing studies usually assume that the learned new feature representation is truly \emph{domain-invariant}, and thus directly train a transfer model $\mathcal{M}$ on source domain. In this paper, we consider a more realistic scenario where the new feature representation is suboptimal and small divergence still exists across domains. We propose a new learning strategy with a transfer model called Randomized Transferable Machine (RTM). More specifically, we work on source data with the new feature representation learned from existing feature-based transfer methods. The key idea is to enlarge source training data populations by randomly corrupting source data using some noises, and then train a transfer model $\widetilde{\mathcal{M}}$ that performs well on all the corrupted source data populations. In principle, the more corruptions are made, the higher the probability of the target data can be covered by the constructed source populations, and thus better transfer performance can be achieved by $\widetilde{\mathcal{M}}$. An ideal case is with infinite corruptions, which however is infeasible in reality. We develop a marginalized solution with linear regression model and dropout noise. With a marginalization trick, we can train an RTM that is equivalently to training using infinite source noisy populations without truly conducting any corruption. More importantly, such an RTM has a closed-form solution, which enables very fast and efficient training. Extensive experiments on various real-world transfer tasks show that RTM is a promising transfer model.
Cooperative Heterogeneous Deep Reinforcement Learning
Nov 02, 2020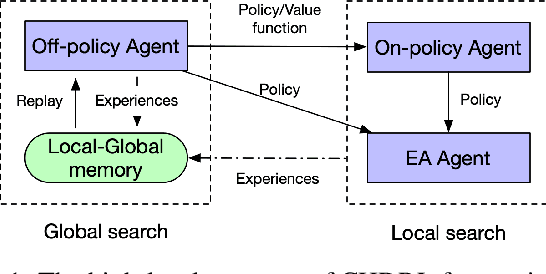
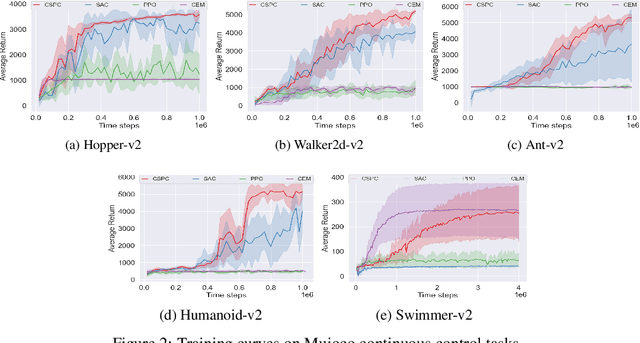

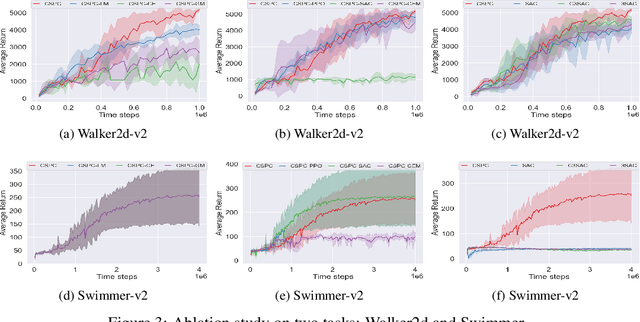
Numerous deep reinforcement learning agents have been proposed, and each of them has its strengths and flaws. In this work, we present a Cooperative Heterogeneous Deep Reinforcement Learning (CHDRL) framework that can learn a policy by integrating the advantages of heterogeneous agents. Specifically, we propose a cooperative learning framework that classifies heterogeneous agents into two classes: global agents and local agents. Global agents are off-policy agents that can utilize experiences from the other agents. Local agents are either on-policy agents or population-based evolutionary algorithms (EAs) agents that can explore the local area effectively. We employ global agents, which are sample-efficient, to guide the learning of local agents so that local agents can benefit from sample-efficient agents and simultaneously maintain their advantages, e.g., stability. Global agents also benefit from effective local searches. Experimental studies on a range of continuous control tasks from the Mujoco benchmark show that CHDRL achieves better performance compared with state-of-the-art baselines.
MESA: Boost Ensemble Imbalanced Learning with MEta-SAmpler
Oct 17, 2020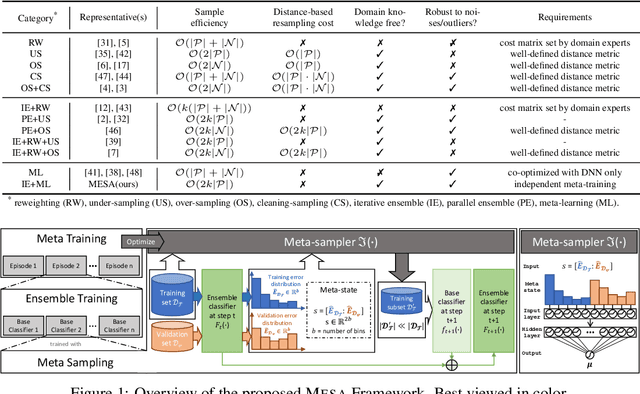
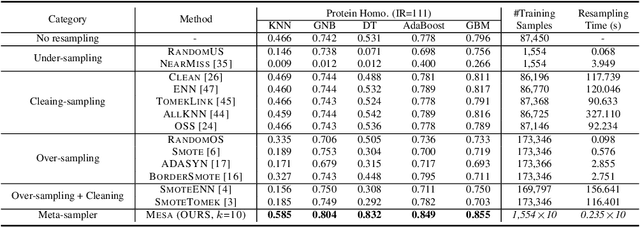
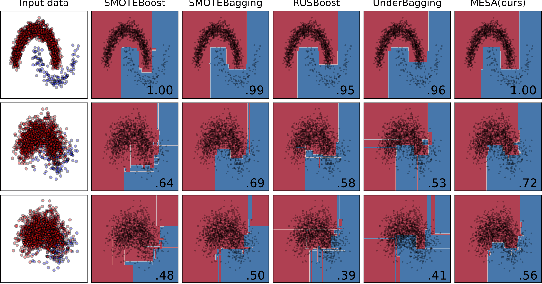
Imbalanced learning (IL), i.e., learning unbiased models from class-imbalanced data, is a challenging problem. Typical IL methods including resampling and reweighting were designed based on some heuristic assumptions. They often suffer from unstable performance, poor applicability, and high computational cost in complex tasks where their assumptions do not hold. In this paper, we introduce a novel ensemble IL framework named MESA. It adaptively resamples the training set in iterations to get multiple classifiers and forms a cascade ensemble model. MESA directly learns the sampling strategy from data to optimize the final metric beyond following random heuristics. Moreover, unlike prevailing meta-learning-based IL solutions, we decouple the model-training and meta-training in MESA by independently train the meta-sampler over task-agnostic meta-data. This makes MESA generally applicable to most of the existing learning models and the meta-sampler can be efficiently applied to new tasks. Extensive experiments on both synthetic and real-world tasks demonstrate the effectiveness, robustness, and transferability of MESA. Our code is available at https://github.com/ZhiningLiu1998/mesa.
Hierarchial Reinforcement Learning in StarCraft II with Human Expertise in Subgoals Selection
Aug 08, 2020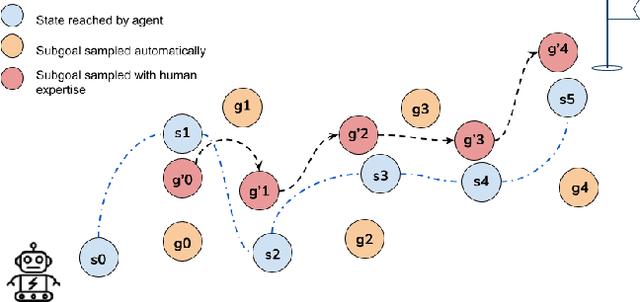
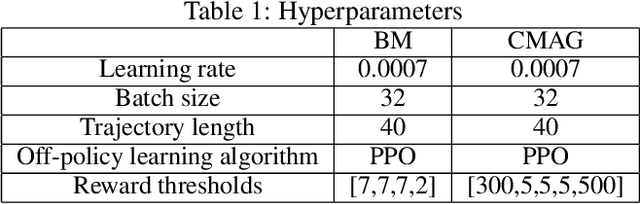
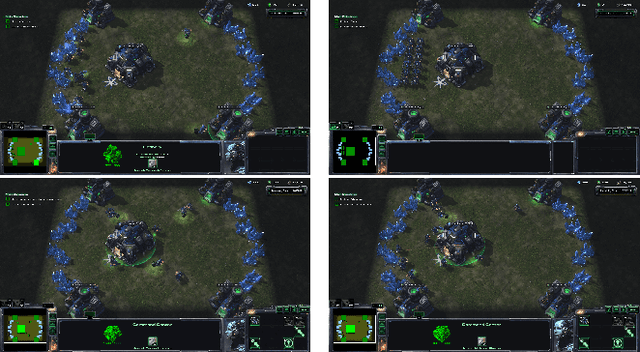
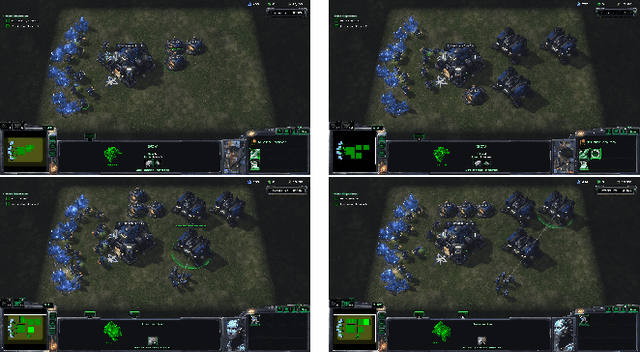
This work is inspired by recent advances in hierarchical reinforcement learning (HRL) (Barto and Mahadevan 2003;Hengst 2010), and improvements in learning efficiency with heuristic-based subgoal selection and hindsight experience replay (HER)(Andrychowicz et al. 2017; Levy et al. 2019). We propose a new method to integrate HRL, HER and effective subgoal selection based on human expertise to support sample-efficient learning and enhance interpretability of the agent's behavior. Human expertise remains indispensable in many areas such as medicine (Buch, Ahmed, and Maruthappu 2018) and law (Cath 2018), where interpretability, explainability and transparency are crucial in the decision making process, for ethical and legal reasons. Our method simplifies the complex task sets for achieving the overall objectives by decomposing into subgoals at different levels of abstraction. Incorporating relevant subjective knowledge also significantly reduces the computational resources spent in exploration for RL, especially in high speed, changing, and complex environments where the transition dynamics cannot be effectively learned and modelled in a short time. Experimental results in two StarCraft II (SC2) minigames demonstrate that our method can achieve better sample efficiency than flat and end-to-end RL methods, and provide an effective method for explaining the agent's performance.
Subdomain Adaptation with Manifolds Discrepancy Alignment
May 06, 2020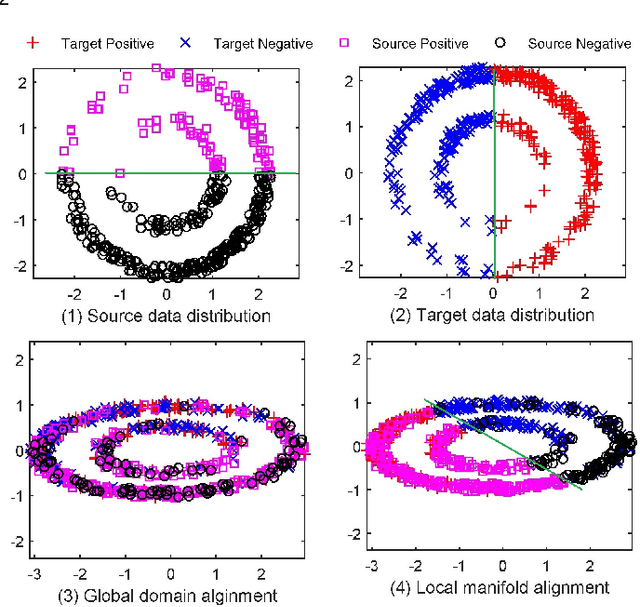
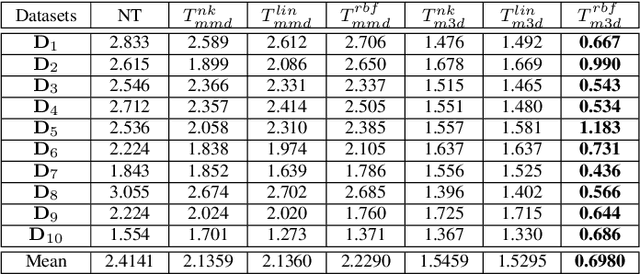
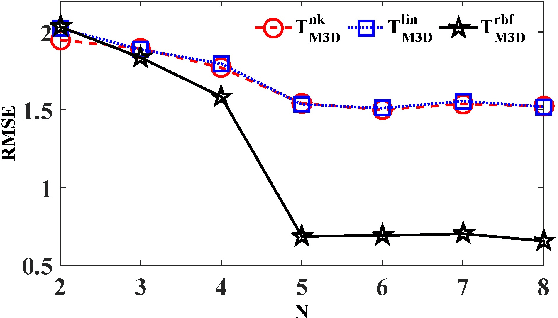
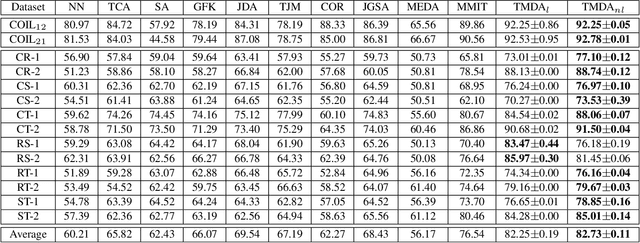
Reducing domain divergence is a key step in transfer learning problems. Existing works focus on the minimization of global domain divergence. However, two domains may consist of several shared subdomains, and differ from each other in each subdomain. In this paper, we take the local divergence of subdomains into account in transfer. Specifically, we propose to use low-dimensional manifold to represent subdomain, and align the local data distribution discrepancy in each manifold across domains. A Manifold Maximum Mean Discrepancy (M3D) is developed to measure the local distribution discrepancy in each manifold. We then propose a general framework, called Transfer with Manifolds Discrepancy Alignment (TMDA), to couple the discovery of data manifolds with the minimization of M3D. We instantiate TMDA in the subspace learning case considering both the linear and nonlinear mappings. We also instantiate TMDA in the deep learning framework. Extensive experimental studies demonstrate that TMDA is a promising method for various transfer learning tasks.