 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBTMTrack: Robust RGB-T Tracking via Dual-template Bridging and Temporal-Modal Candidate Elimination
Jan 07, 2025



RGB-T tracking leverages the complementary strengths of RGB and thermal infrared (TIR) modalities to address challenging scenarios such as low illumination and adverse weather. However, existing methods often fail to effectively integrate temporal information and perform efficient cross-modal interactions, which constrain their adaptability to dynamic targets. In this paper, we propose BTMTrack, a novel framework for RGB-T tracking. The core of our approach lies in the dual-template backbone network and the Temporal-Modal Candidate Elimination (TMCE) strategy. The dual-template backbone effectively integrates temporal information, while the TMCE strategy focuses the model on target-relevant tokens by evaluating temporal and modal correlations, reducing computational overhead and avoiding irrelevant background noise. Building upon this foundation, we propose the Temporal Dual Template Bridging (TDTB) module, which facilitates precise cross-modal fusion through dynamically filtered tokens. This approach further strengthens the interaction between templates and the search region. Extensive experiments conducted on three benchmark datasets demonstrate the effectiveness of BTMTrack. Our method achieves state-of-the-art performance, with a 72.3% precision rate on the LasHeR test set and competitive results on RGBT210 and RGBT234 datasets.
DGSNA: prompt-based Dynamic Generative Scene-based Noise Addition method
Nov 19, 2024



This paper addresses the challenges of accurately enumerating and describing scenes and the labor-intensive process required to replicate acoustic environments using non-generative methods. We introduce the prompt-based Dynamic Generative Sce-ne-based Noise Addition method (DGSNA), which innovatively combines the Dynamic Generation of Scene Information (DGSI) with Scene-based Noise Addition for Audio (SNAA). Employing generative chat models structured within the Back-ground-Examples-Task (BET) prompt framework, DGSI com-ponent facilitates the dynamic synthesis of tailored Scene Infor-mation (SI) for specific acoustic environments. Additionally, the SNAA component leverages Room Impulse Response (RIR) fil-ters and Text-To-Audio (TTA) systems to generate realistic, scene-based noise that can be adapted for both indoor and out-door environments. Through comprehensive experiments, the adaptability of DGSNA across different generative chat models was demonstrated. The results, assessed through both objective and subjective evaluations, show that DGSNA provides robust performance in dynamically generating precise SI and effectively enhancing scene-based noise addition capabilities, thus offering significant improvements over traditional methods in acoustic scene simulation. Our implementation and demos are available at https://dgsna.github.io.
A Refined 3D Gaussian Representation for High-Quality Dynamic Scene Reconstruction
May 28, 2024In recent years, Neural Radiance Fields (NeRF) has revolutionized three-dimensional (3D) reconstruction with its implicit representation. Building upon NeRF, 3D Gaussian Splatting (3D-GS) has departed from the implicit representation of neural networks and instead directly represents scenes as point clouds with Gaussian-shaped distributions. While this shift has notably elevated the rendering quality and speed of radiance fields but inevitably led to a significant increase in memory usage. Additionally, effectively rendering dynamic scenes in 3D-GS has emerged as a pressing challenge. To address these concerns, this paper purposes a refined 3D Gaussian representation for high-quality dynamic scene reconstruction. Firstly, we use a deformable multi-layer perceptron (MLP) network to capture the dynamic offset of Gaussian points and express the color features of points through hash encoding and a tiny MLP to reduce storage requirements. Subsequently, we introduce a learnable denoising mask coupled with denoising loss to eliminate noise points from the scene, thereby further compressing 3D Gaussian model. Finally, motion noise of points is mitigated through static constraints and motion consistency constraints. Experimental results demonstrate that our method surpasses existing approaches in rendering quality and speed, while significantly reducing the memory usage associated with 3D-GS, making it highly suitable for various tasks such as novel view synthesis, and dynamic mapping.
2DLIW-SLAM:2D LiDAR-Inertial-Wheel Odometry with Real-Time Loop Closure
Apr 15, 2024Due to budgetary constraints, indoor navigation typically employs 2D LiDAR rather than 3D LiDAR. However, the utilization of 2D LiDAR in Simultaneous Localization And Mapping (SLAM) frequently encounters challenges related to motion degeneracy, particularly in geometrically similar environments. To address this problem, this paper proposes a robust, accurate, and multi-sensor-fused 2D LiDAR SLAM system specifically designed for indoor mobile robots. To commence, the original LiDAR data undergoes meticulous processing through point and line extraction. Leveraging the distinctive characteristics of indoor environments, line-line constraints are established to complement other sensor data effectively, thereby augmenting the overall robustness and precision of the system. Concurrently, a tightly-coupled front-end is created, integrating data from the 2D LiDAR, IMU, and wheel odometry, thus enabling real-time state estimation. Building upon this solid foundation, a novel global feature point matching-based loop closure detection algorithm is proposed. This algorithm proves highly effective in mitigating front-end accumulated errors and ultimately constructs a globally consistent map. The experimental results indicate that our system fully meets real-time requirements. When compared to Cartographer, our system not only exhibits lower trajectory errors but also demonstrates stronger robustness, particularly in degeneracy problem.
RTrack: Accelerating Convergence for Visual Object Tracking via Pseudo-Boxes Exploration
Sep 23, 2023Single object tracking (SOT) heavily relies on the representation of the target object as a bounding box. However, due to the potential deformation and rotation experienced by the tracked targets, the genuine bounding box fails to capture the appearance information explicitly and introduces cluttered background. This paper proposes RTrack, a novel object representation baseline tracker that utilizes a set of sample points to get a pseudo bounding box. RTrack automatically arranges these points to define the spatial extents and highlight local areas. Building upon the baseline, we conducted an in-depth exploration of the training potential and introduced a one-to-many leading assignment strategy. It is worth noting that our approach achieves competitive performance to the state-of-the-art trackers on the GOT-10k dataset while reducing training time to just 10% of the previous state-of-the-art (SOTA) trackers' training costs. The substantial reduction in training costs brings single-object tracking (SOT) closer to the object detection (OD) task. Extensive experiments demonstrate that our proposed RTrack achieves SOTA results with faster convergence.
LiteTrack: Layer Pruning with Asynchronous Feature Extraction for Lightweight and Efficient Visual Tracking
Sep 17, 2023The recent advancements in transformer-based visual trackers have led to significant progress, attributed to their strong modeling capabilities. However, as performance improves, running latency correspondingly increases, presenting a challenge for real-time robotics applications, especially on edge devices with computational constraints. In response to this, we introduce LiteTrack, an efficient transformer-based tracking model optimized for high-speed operations across various devices. It achieves a more favorable trade-off between accuracy and efficiency than the other lightweight trackers. The main innovations of LiteTrack encompass: 1) asynchronous feature extraction and interaction between the template and search region for better feature fushion and cutting redundant computation, and 2) pruning encoder layers from a heavy tracker to refine the balnace between performance and speed. As an example, our fastest variant, LiteTrack-B4, achieves 65.2% AO on the GOT-10k benchmark, surpassing all preceding efficient trackers, while running over 100 fps with ONNX on the Jetson Orin NX edge device. Moreover, our LiteTrack-B9 reaches competitive 72.2% AO on GOT-10k and 82.4% AUC on TrackingNet, and operates at 171 fps on an NVIDIA 2080Ti GPU. The code and demo materials will be available at https://github.com/TsingWei/LiteTrack.
Efficient Training for Visual Tracking with Deformable Transformer
Sep 06, 2023Recent Transformer-based visual tracking models have showcased superior performance. Nevertheless, prior works have been resource-intensive, requiring prolonged GPU training hours and incurring high GFLOPs during inference due to inefficient training methods and convolution-based target heads. This intensive resource use renders them unsuitable for real-world applications. In this paper, we present DETRack, a streamlined end-to-end visual object tracking framework. Our framework utilizes an efficient encoder-decoder structure where the deformable transformer decoder acting as a target head, achieves higher sparsity than traditional convolution heads, resulting in decreased GFLOPs. For training, we introduce a novel one-to-many label assignment and an auxiliary denoising technique, significantly accelerating model's convergence. Comprehensive experiments affirm the effectiveness and efficiency of our proposed method. For instance, DETRack achieves 72.9% AO on challenging GOT-10k benchmarks using only 20% of the training epochs required by the baseline, and runs with lower GFLOPs than all the transformer-based trackers.
Towards Efficient Training with Negative Samples in Visual Tracking
Sep 06, 2023Current state-of-the-art (SOTA) methods in visual object tracking often require extensive computational resources and vast amounts of training data, leading to a risk of overfitting. This study introduces a more efficient training strategy to mitigate overfitting and reduce computational requirements. We balance the training process with a mix of negative and positive samples from the outset, named as Joint learning with Negative samples (JN). Negative samples refer to scenarios where the object from the template is not present in the search region, which helps to prevent the model from simply memorizing the target, and instead encourages it to use the template for object location. To handle the negative samples effectively, we adopt a distribution-based head, which modeling the bounding box as distribution of distances to express uncertainty about the target's location in the presence of negative samples, offering an efficient way to manage the mixed sample training. Furthermore, our approach introduces a target-indicating token. It encapsulates the target's precise location within the template image. This method provides exact boundary details with negligible computational cost but improving performance. Our model, JN-256, exhibits superior performance on challenging benchmarks, achieving 75.8% AO on GOT-10k and 84.1% AUC on TrackingNet. Notably, JN-256 outperforms previous SOTA trackers that utilize larger models and higher input resolutions, even though it is trained with only half the number of data sampled used in those works.
TMSTC*: A Turn-minimizing Algorithm For Multi-robot Coverage Path Planning
Dec 05, 2022



Coverage path planning is a major application for mobile robots, which requires robots to move along a planned path to cover the entire map. For large-scale tasks, coverage path planning benefits greatly from multiple robots. In this paper, we describe Turn-minimizing Multirobot Spanning Tree Coverage Star(TMSTC*), an improved multirobot coverage path planning (mCPP) algorithm based on the MSTC*. Our algorithm partitions the map into minimum bricks as tree's branches and thereby transforms the problem into finding the maximum independent set of bipartite graph. We then connect bricks with greedy strategy to form a tree, aiming to reduce the number of turns of corresponding circumnavigating coverage path. Our experimental results show that our approach enables multiple robots to make fewer turns and thus complete terrain coverage tasks faster than other popular algorithms.
Joint Intent Detection and Slot Filling with Wheel-Graph Attention Networks
Feb 09, 2021
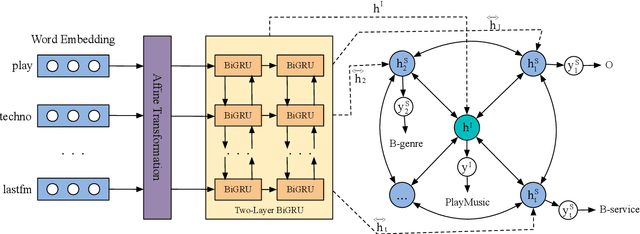
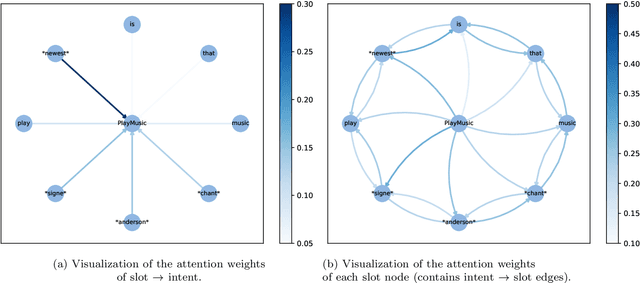
Intent detection and slot filling are two fundamental tasks for building a spoken language understanding (SLU) system. Multiple deep learning-based joint models have demonstrated excellent results on the two tasks. In this paper, we propose a new joint model with a wheel-graph attention network (Wheel-GAT) which is able to model interrelated connections directly for intent detection and slot filling. To construct a graph structure for utterances, we create intent nodes, slot nodes, and directed edges. Intent nodes can provide utterance-level semantic information for slot filling, while slot nodes can also provide local keyword information for intent. Experiments show that our model outperforms multiple baselines on two public datasets. Besides, we also demonstrate that using Bidirectional Encoder Representation from Transformer (BERT) model further boosts the performance in the SLU task.