 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Molecular Representation Learning via Fragment-Based Self-Supervised Embedding Prediction
Feb 23, 2026Graph self-supervised learning (GSSL) has demonstrated strong potential for generating expressive graph embeddings without the need for human annotations, making it particularly valuable in domains with high labeling costs such as molecular graph analysis. However, existing GSSL methods mostly focus on node- or edge-level information, often ignoring chemically relevant substructures which strongly influence molecular properties. In this work, we propose Graph Semantic Predictive Network (GraSPNet), a hierarchical self-supervised framework that explicitly models both atomic-level and fragment-level semantics. GraSPNet decomposes molecular graphs into chemically meaningful fragments without predefined vocabularies and learns node- and fragment-level representations through multi-level message passing with masked semantic prediction at both levels. This hierarchical semantic supervision enables GraSPNet to learn multi-resolution structural information that is both expressive and transferable. Extensive experiments on multiple molecular property prediction benchmarks demonstrate that GraSPNet learns chemically meaningful representations and consistently outperforms state-of-the-art GSSL methods in transfer learning settings.
Randomized Transferable Machine
Nov 27, 2020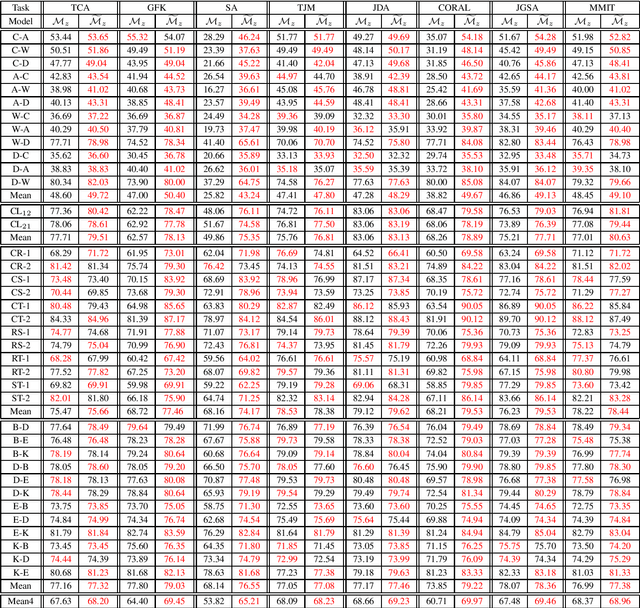
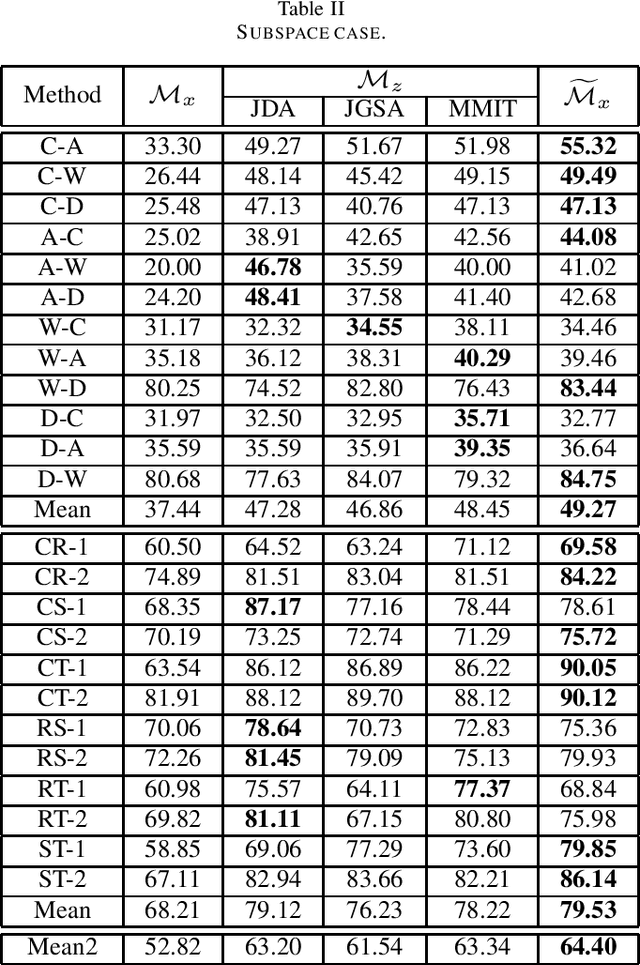
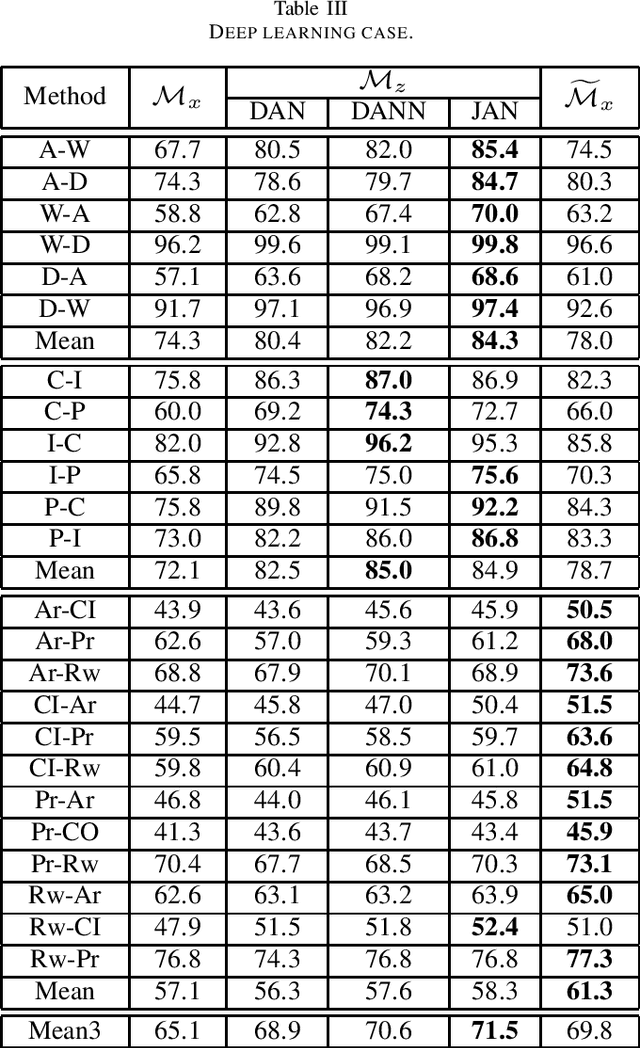
Feature-based transfer is one of the most effective methodologies for transfer learning. Existing studies usually assume that the learned new feature representation is truly \emph{domain-invariant}, and thus directly train a transfer model $\mathcal{M}$ on source domain. In this paper, we consider a more realistic scenario where the new feature representation is suboptimal and small divergence still exists across domains. We propose a new learning strategy with a transfer model called Randomized Transferable Machine (RTM). More specifically, we work on source data with the new feature representation learned from existing feature-based transfer methods. The key idea is to enlarge source training data populations by randomly corrupting source data using some noises, and then train a transfer model $\widetilde{\mathcal{M}}$ that performs well on all the corrupted source data populations. In principle, the more corruptions are made, the higher the probability of the target data can be covered by the constructed source populations, and thus better transfer performance can be achieved by $\widetilde{\mathcal{M}}$. An ideal case is with infinite corruptions, which however is infeasible in reality. We develop a marginalized solution with linear regression model and dropout noise. With a marginalization trick, we can train an RTM that is equivalently to training using infinite source noisy populations without truly conducting any corruption. More importantly, such an RTM has a closed-form solution, which enables very fast and efficient training. Extensive experiments on various real-world transfer tasks show that RTM is a promising transfer model.