 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistants, Not Architects: The Role of LLMs in Networked Systems Design
Apr 28, 2026Designing the architecture of modern networked systems requires navigating a large, combinatorial space of hardware, systems, and configuration choices with complex cross-layer interactions. Architects must balance competing objectives such as performance, cost, and deployability while satisfying compatibility and resource constraints, often relying on scattered rules-of-thumb drawn from benchmarks, papers, documentation, and expert experience. This raises a natural question: can large language models (LLMs) reliably perform this kind of architectural reasoning? We find that they cannot. While LLMs produce plausible configurations, they frequently miss critical constraints, encode incorrect assumptions, and exhibit ``stickiness'' to familiar patterns. A natural workaround--iterative validation via simulation or experimentation--is often prohibitively expensive at scale and, in many cases, infeasible, particularly when comparing hardware-dependent alternatives. Motivated by this gap, we present Kepler, a lightweight reasoning framework for architecture design that combines structured, expert-driven specifications with SMT-based optimization. Kepler encodes architecturally significant properties--requirements, incompatibilities, and qualitative trade-offs--about systems, hardware, and workloads as constraints, and synthesizes feasible designs that optimize user-defined objectives. It operates at an abstract level, capturing ``rules-of-thumb'' rather than detailed system behavior, enabling tractable reasoning while preserving key interactions, and provides explanations for its decisions. Through experiments and case studies, we show that Kepler uncovers interactions missed by LLMs and supports systematic, explainable design exploration.
Towards Regulatable AI Systems: Technical Gaps and Policy Opportunities
Jun 22, 2023There is increasing attention being given to how to regulate AI systems. As governing bodies grapple with what values to encapsulate into regulation, we consider the technical half of the question: To what extent can AI experts vet an AI system for adherence to regulatory requirements? We investigate this question through two public sector procurement checklists, identifying what we can do now, what we should be able to do with technical innovation in AI, and what requirements necessitate a more interdisciplinary approach.
Hierarchial Reinforcement Learning in StarCraft II with Human Expertise in Subgoals Selection
Aug 08, 2020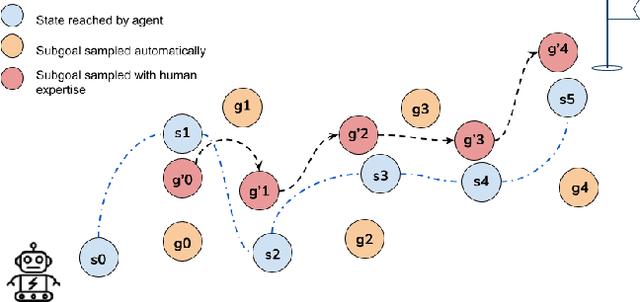
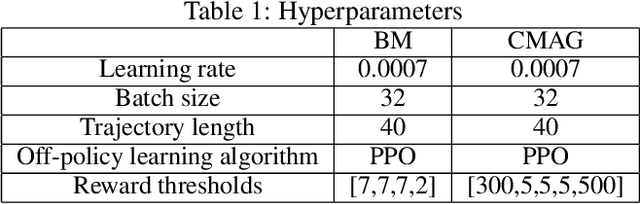
This work is inspired by recent advances in hierarchical reinforcement learning (HRL) (Barto and Mahadevan 2003;Hengst 2010), and improvements in learning efficiency with heuristic-based subgoal selection and hindsight experience replay (HER)(Andrychowicz et al. 2017; Levy et al. 2019). We propose a new method to integrate HRL, HER and effective subgoal selection based on human expertise to support sample-efficient learning and enhance interpretability of the agent's behavior. Human expertise remains indispensable in many areas such as medicine (Buch, Ahmed, and Maruthappu 2018) and law (Cath 2018), where interpretability, explainability and transparency are crucial in the decision making process, for ethical and legal reasons. Our method simplifies the complex task sets for achieving the overall objectives by decomposing into subgoals at different levels of abstraction. Incorporating relevant subjective knowledge also significantly reduces the computational resources spent in exploration for RL, especially in high speed, changing, and complex environments where the transition dynamics cannot be effectively learned and modelled in a short time. Experimental results in two StarCraft II (SC2) minigames demonstrate that our method can achieve better sample efficiency than flat and end-to-end RL methods, and provide an effective method for explaining the agent's performance.