 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
Nov 10, 2024



Language agents have demonstrated promising capabilities in automating web-based tasks, though their current reactive approaches still underperform largely compared to humans. While incorporating advanced planning algorithms, particularly tree search methods, could enhance these agents' performance, implementing tree search directly on live websites poses significant safety risks and practical constraints due to irreversible actions such as confirming a purchase. In this paper, we introduce a novel paradigm that augments language agents with model-based planning, pioneering the innovative use of large language models (LLMs) as world models in complex web environments. Our method, WebDreamer, builds on the key insight that LLMs inherently encode comprehensive knowledge about website structures and functionalities. Specifically, WebDreamer uses LLMs to simulate outcomes for each candidate action (e.g., "what would happen if I click this button?") using natural language descriptions, and then evaluates these imagined outcomes to determine the optimal action at each step. Empirical results on two representative web agent benchmarks with online interaction -- VisualWebArena and Mind2Web-live -- demonstrate that WebDreamer achieves substantial improvements over reactive baselines. By establishing the viability of LLMs as world models in web environments, this work lays the groundwork for a paradigm shift in automated web interaction. More broadly, our findings open exciting new avenues for future research into 1) optimizing LLMs specifically for world modeling in complex, dynamic environments, and 2) model-based speculative planning for language agents.
Dancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
FakingRecipe: Detecting Fake News on Short Video Platforms from the Perspective of Creative Process
Jul 23, 2024



As short-form video-sharing platforms become a significant channel for news consumption, fake news in short videos has emerged as a serious threat in the online information ecosystem, making developing detection methods for this new scenario an urgent need. Compared with that in text and image formats, fake news on short video platforms contains rich but heterogeneous information in various modalities, posing a challenge to effective feature utilization. Unlike existing works mostly focusing on analyzing what is presented, we introduce a novel perspective that considers how it might be created. Through the lens of the creative process behind news video production, our empirical analysis uncovers the unique characteristics of fake news videos in material selection and editing. Based on the obtained insights, we design FakingRecipe, a creative process-aware model for detecting fake news short videos. It captures the fake news preferences in material selection from sentimental and semantic aspects and considers the traits of material editing from spatial and temporal aspects. To improve evaluation comprehensiveness, we first construct FakeTT, an English dataset for this task, and conduct experiments on both FakeTT and the existing Chinese FakeSV dataset. The results show FakingRecipe's superiority in detecting fake news on short video platforms.
RAG-QA Arena: Evaluating Domain Robustness for Long-form Retrieval Augmented Question Answering
Jul 19, 2024Question answering based on retrieval augmented generation (RAG-QA) is an important research topic in NLP and has a wide range of real-world applications. However, most existing datasets for this task are either constructed using a single source corpus or consist of short extractive answers, which fall short of evaluating large language model (LLM) based RAG-QA systems on cross-domain generalization. To address these limitations, we create Long-form RobustQA (LFRQA), a new dataset comprising human-written long-form answers that integrate short extractive answers from multiple documents into a single, coherent narrative, covering 26K queries and large corpora across seven different domains. We further propose RAG-QA Arena by directly comparing model-generated answers against LFRQA's answers using LLMs as evaluators. We show via extensive experiments that RAG-QA Arena and human judgments on answer quality are highly correlated. Moreover, only 41.3% of the most competitive LLM's answers are preferred to LFRQA's answers, demonstrating RAG-QA Arena as a challenging evaluation platform for future research.
SNIFFER: Multimodal Large Language Model for Explainable Out-of-Context Misinformation Detection
Mar 05, 2024Misinformation is a prevalent societal issue due to its potential high risks. Out-of-context (OOC) misinformation, where authentic images are repurposed with false text, is one of the easiest and most effective ways to mislead audiences. Current methods focus on assessing image-text consistency but lack convincing explanations for their judgments, which is essential for debunking misinformation. While Multimodal Large Language Models (MLLMs) have rich knowledge and innate capability for visual reasoning and explanation generation, they still lack sophistication in understanding and discovering the subtle crossmodal differences. In this paper, we introduce SNIFFER, a novel multimodal large language model specifically engineered for OOC misinformation detection and explanation. SNIFFER employs two-stage instruction tuning on InstructBLIP. The first stage refines the model's concept alignment of generic objects with news-domain entities and the second stage leverages language-only GPT-4 generated OOC-specific instruction data to fine-tune the model's discriminatory powers. Enhanced by external tools and retrieval, SNIFFER not only detects inconsistencies between text and image but also utilizes external knowledge for contextual verification. Our experiments show that SNIFFER surpasses the original MLLM by over 40% and outperforms state-of-the-art methods in detection accuracy. SNIFFER also provides accurate and persuasive explanations as validated by quantitative and human evaluations.
Bad Actor, Good Advisor: Exploring the Role of Large Language Models in Fake News Detection
Sep 21, 2023Detecting fake news requires both a delicate sense of diverse clues and a profound understanding of the real-world background, which remains challenging for detectors based on small language models (SLMs) due to their knowledge and capability limitations. Recent advances in large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with fake news detection remains underexplored. In this paper, we investigate the potential of LLMs in fake news detection. First, we conduct an empirical study and find that a sophisticated LLM such as GPT 3.5 could generally expose fake news and provide desirable multi-perspective rationales but still underperforms the basic SLM, fine-tuned BERT. Our subsequent analysis attributes such a gap to the LLM's inability to select and integrate rationales properly to conclude. Based on these findings, we propose that current LLMs may not substitute fine-tuned SLMs in fake news detection but can be a good advisor for SLMs by providing multi-perspective instructive rationales. To instantiate this proposal, we design an adaptive rationale guidance network for fake news detection (ARG), in which SLMs selectively acquire insights on news analysis from the LLMs' rationales. We further derive a rationale-free version of ARG by distillation, namely ARG-D, which services cost-sensitive scenarios without inquiring LLMs. Experiments on two real-world datasets demonstrate that ARG and ARG-D outperform three types of baseline methods, including SLM-based, LLM-based, and combinations of small and large language models.
A Miniaturised Camera-based Multi-Modal Tactile Sensor
Mar 06, 2023



In conjunction with huge recent progress in camera and computer vision technology, camera-based sensors have increasingly shown considerable promise in relation to tactile sensing. In comparison to competing technologies (be they resistive, capacitive or magnetic based), they offer super-high-resolution, while suffering from fewer wiring problems. The human tactile system is composed of various types of mechanoreceptors, each able to perceive and process distinct information such as force, pressure, texture, etc. Camera-based tactile sensors such as GelSight mainly focus on high-resolution geometric sensing on a flat surface, and their force measurement capabilities are limited by the hysteresis and non-linearity of the silicone material. In this paper, we present a miniaturised dome-shaped camera-based tactile sensor that allows accurate force and tactile sensing in a single coherent system. The key novelty of the sensor design is as follows. First, we demonstrate how to build a smooth silicone hemispheric sensing medium with uniform markers on its curved surface. Second, we enhance the illumination of the rounded silicone with diffused LEDs. Third, we construct a force-sensitive mechanical structure in a compact form factor with usage of springs to accurately perceive forces. Our multi-modal sensor is able to acquire tactile information from multi-axis forces, local force distribution, and contact geometry, all in real-time. We apply an end-to-end deep learning method to process all the information.
Online Misinformation Video Detection: A Survey
Feb 07, 2023



With information consumption via online video streaming becoming increasingly popular, misinformation video poses a new threat to the health of the online information ecosystem. Though previous studies have made much progress in detecting misinformation in text and image formats, video-based misinformation brings new and unique challenges to automatic detection systems: 1) high information heterogeneity brought by various modalities, 2) blurred distinction between misleading video manipulation and ubiquitous artistic video editing, and 3) new patterns of misinformation propagation due to the dominant role of recommendation systems on online video platforms. To facilitate research on this challenging task, we conduct this survey to present advances in misinformation video detection research. We first analyze and characterize the misinformation video from three levels including signals, semantics, and intents. Based on the characterization, we systematically review existing works for detection from features of various modalities to techniques for clue integration. We also introduce existing resources including representative datasets and widely used tools. Besides summarizing existing studies, we discuss related areas and outline open issues and future directions to encourage and guide more research on misinformation video detection. Our corresponding public repository is available at https://github.com/ICTMCG/Awesome-Misinfo-Video-Detection.
Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
Dec 19, 2022



Generative models have been widely applied to solve extractive tasks, where parts of the input is extracted to form the desired output, and achieved significant success. For example, in extractive question answering (QA), generative models have constantly yielded state-of-the-art results. In this work, we identify the issue of tokenization inconsistency that is commonly neglected in training these models. This issue damages the extractive nature of these tasks after the input and output are tokenized inconsistently by the tokenizer, and thus leads to performance drop as well as hallucination. We propose a simple yet effective fix to this issue and conduct a case study on extractive QA. We show that, with consistent tokenization, the model performs better in both in-domain and out-of-domain datasets, with a notable average of +1.7 F2 gain when a BART model is trained on SQuAD and evaluated on 8 QA datasets. Further, the model converges faster, and becomes less likely to generate out-of-context answers. With these findings, we would like to call for more attention on how tokenization should be done when solving extractive tasks and recommend applying consistent tokenization during training.
How (Not) To Evaluate Explanation Quality
Oct 13, 2022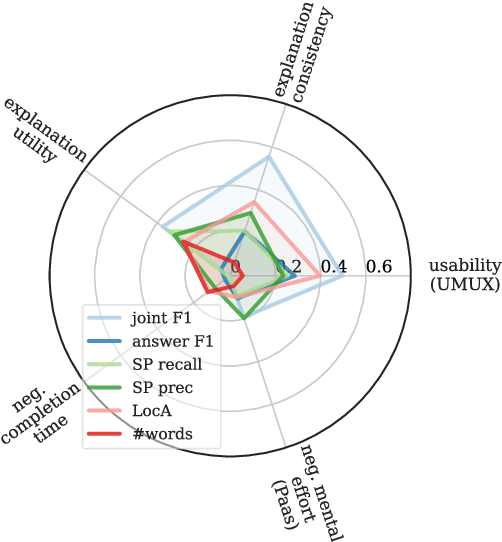

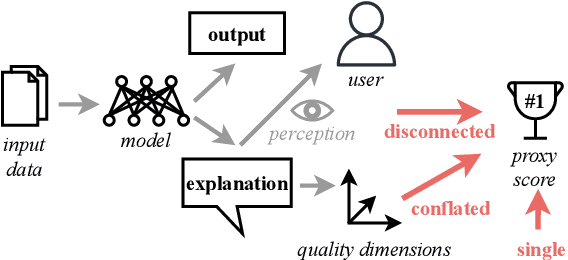

The importance of explainability is increasingly acknowledged in natural language processing. However, it is still unclear how the quality of explanations can be assessed effectively. The predominant approach is to compare proxy scores (such as BLEU or explanation F1) evaluated against gold explanations in the dataset. The assumption is that an increase of the proxy score implies a higher utility of explanations to users. In this paper, we question this assumption. In particular, we (i) formulate desired characteristics of explanation quality that apply across tasks and domains, (ii) point out how current evaluation practices violate those characteristics, and (iii) propose actionable guidelines to overcome obstacles that limit today's evaluation of explanation quality and to enable the development of explainable systems that provide tangible benefits for human users. We substantiate our theoretical claims (i.e., the lack of validity and temporal decline of currently-used proxy scores) with empirical evidence from a crowdsourcing case study in which we investigate the explanation quality of state-of-the-art explainable question answering systems.