 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Spatial-Temporal and Appearance Modeling with Transformer for Multiple Object Tracking
May 31, 2022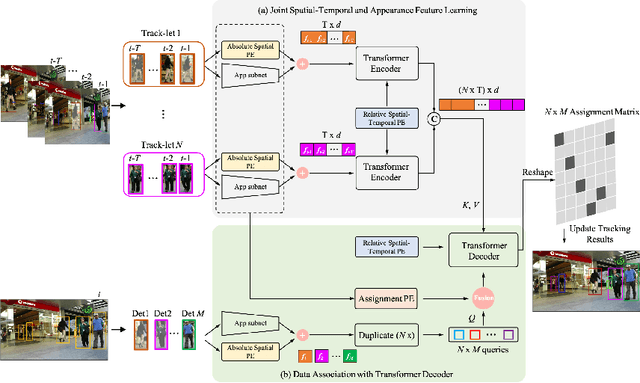

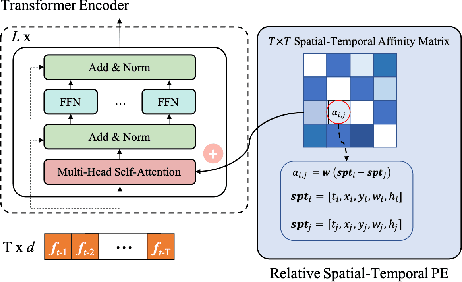
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. In this paper, we propose a novel solution named TransSTAM, which leverages Transformer to effectively model both the appearance features of each object and the spatial-temporal relationships among objects. TransSTAM consists of two major parts: (1) The encoder utilizes the powerful self-attention mechanism of Transformer to learn discriminative features for each tracklet; (2) The decoder adopts the standard cross-attention mechanism to model the affinities between the tracklets and the detections by taking both spatial-temporal and appearance features into account. TransSTAM has two major advantages: (1) It is solely based on the encoder-decoder architecture and enjoys a compact network design, hence being computationally efficient; (2) It can effectively learn spatial-temporal and appearance features within one model, hence achieving better tracking accuracy. The proposed method is evaluated on multiple public benchmarks including MOT16, MOT17, and MOT20, and it achieves a clear performance improvement in both IDF1 and HOTA with respect to previous state-of-the-art approaches on all the benchmarks. Our code is available at \url{https://github.com/icicle4/TranSTAM}.
Video Demoireing with Relation-Based Temporal Consistency
Apr 06, 2022
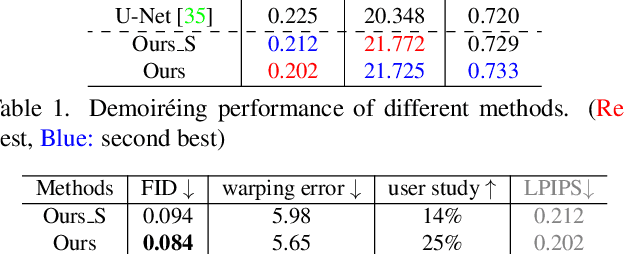

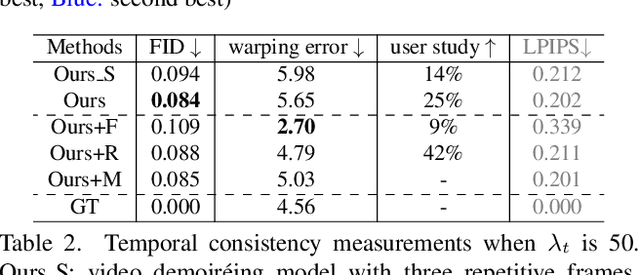
Moire patterns, appearing as color distortions, severely degrade image and video qualities when filming a screen with digital cameras. Considering the increasing demands for capturing videos, we study how to remove such undesirable moire patterns in videos, namely video demoireing. To this end, we introduce the first hand-held video demoireing dataset with a dedicated data collection pipeline to ensure spatial and temporal alignments of captured data. Further, a baseline video demoireing model with implicit feature space alignment and selective feature aggregation is developed to leverage complementary information from nearby frames to improve frame-level video demoireing. More importantly, we propose a relation-based temporal consistency loss to encourage the model to learn temporal consistency priors directly from ground-truth reference videos, which facilitates producing temporally consistent predictions and effectively maintains frame-level qualities. Extensive experiments manifest the superiority of our model. Code is available at \url{https://daipengwa.github.io/VDmoire_ProjectPage/}.
An Efficient and Robust System for Vertically Federated Random Forest
Jan 26, 2022As there is a growing interest in utilizing data across multiple resources to build better machine learning models, many vertically federated learning algorithms have been proposed to preserve the data privacy of the participating organizations. However, the efficiency of existing vertically federated learning algorithms remains to be a big problem, especially when applied to large-scale real-world datasets. In this paper, we present a fast, accurate, scalable and yet robust system for vertically federated random forest. With extensive optimization, we achieved $5\times$ and $83\times$ speed up over the SOTA SecureBoost model \cite{cheng2019secureboost} for training and serving tasks. Moreover, the proposed system can achieve similar accuracy but with favorable scalability and partition tolerance. Our code has been made public to facilitate the development of the community and the protection of user data privacy.
Self-supervised Spatiotemporal Representation Learning by Exploiting Video Continuity
Jan 10, 2022
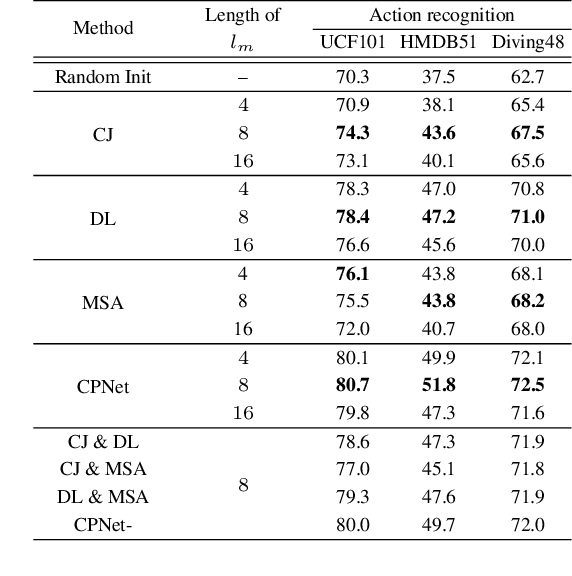
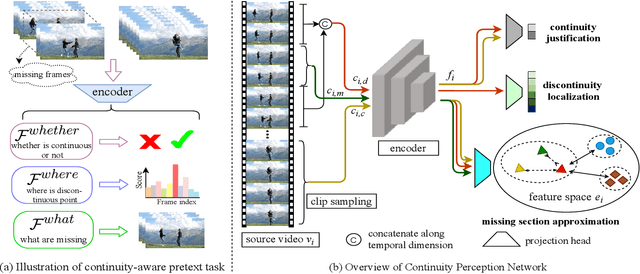
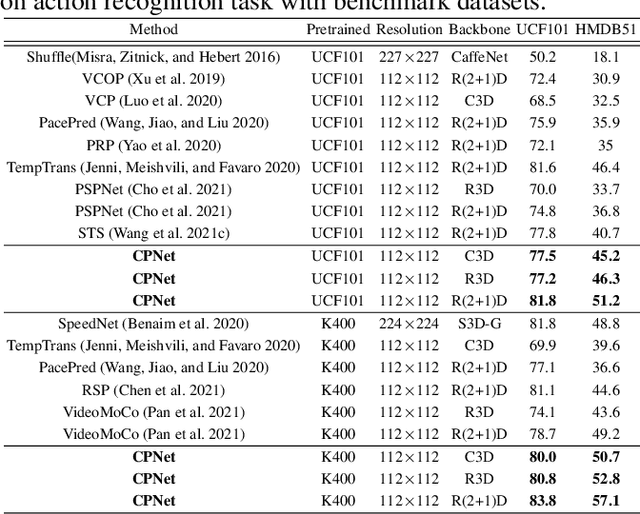
Recent self-supervised video representation learning methods have found significant success by exploring essential properties of videos, e.g. speed, temporal order, etc. This work exploits an essential yet under-explored property of videos, the video continuity, to obtain supervision signals for self-supervised representation learning. Specifically, we formulate three novel continuity-related pretext tasks, i.e. continuity justification, discontinuity localization, and missing section approximation, that jointly supervise a shared backbone for video representation learning. This self-supervision approach, termed as Continuity Perception Network (CPNet), solves the three tasks altogether and encourages the backbone network to learn local and long-ranged motion and context representations. It outperforms prior arts on multiple downstream tasks, such as action recognition, video retrieval, and action localization. Additionally, the video continuity can be complementary to other coarse-grained video properties for representation learning, and integrating the proposed pretext task to prior arts can yield much performance gains.
Spatial-Temporal Sequential Hypergraph Network for Crime Prediction
Jan 07, 2022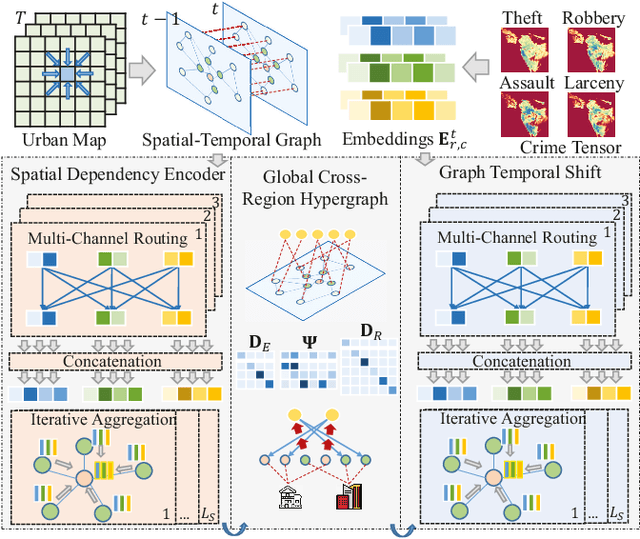
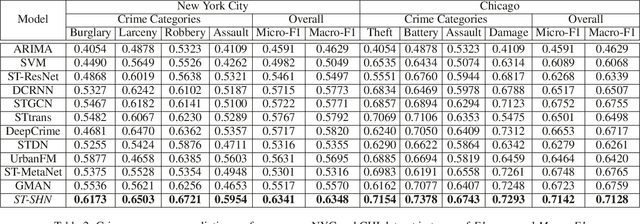
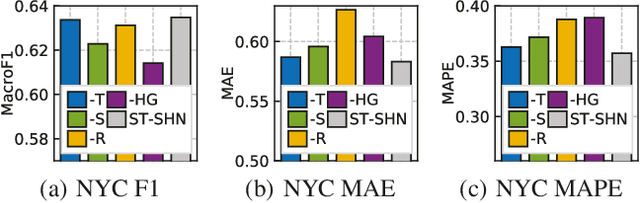
Crime prediction is crucial for public safety and resource optimization, yet is very challenging due to two aspects: i) the dynamics of criminal patterns across time and space, crime events are distributed unevenly on both spatial and temporal domains; ii) time-evolving dependencies between different types of crimes (e.g., Theft, Robbery, Assault, Damage) which reveal fine-grained semantics of crimes. To tackle these challenges, we propose Spatial-Temporal Sequential Hypergraph Network (ST-SHN) to collectively encode complex crime spatial-temporal patterns as well as the underlying category-wise crime semantic relationships. In specific, to handle spatial-temporal dynamics under the long-range and global context, we design a graph-structured message passing architecture with the integration of the hypergraph learning paradigm. To capture category-wise crime heterogeneous relations in a dynamic environment, we introduce a multi-channel routing mechanism to learn the time-evolving structural dependency across crime types. We conduct extensive experiments on two real-world datasets, showing that our proposed ST-SHN framework can significantly improve the prediction performance as compared to various state-of-the-art baselines. The source code is available at: https://github.com/akaxlh/ST-SHN.
Multi-Behavior Enhanced Recommendation with Cross-Interaction Collaborative Relation Modeling
Jan 07, 2022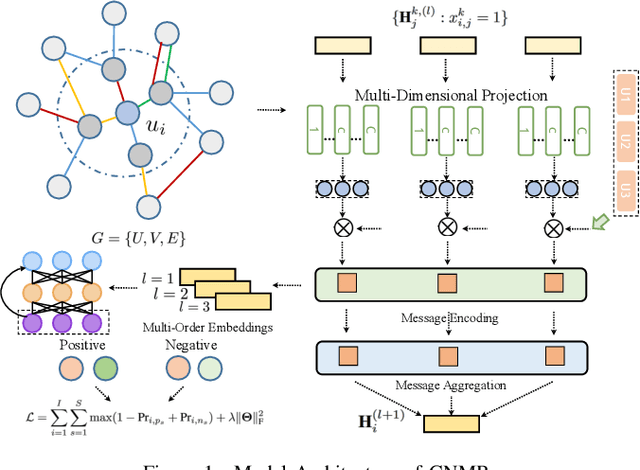
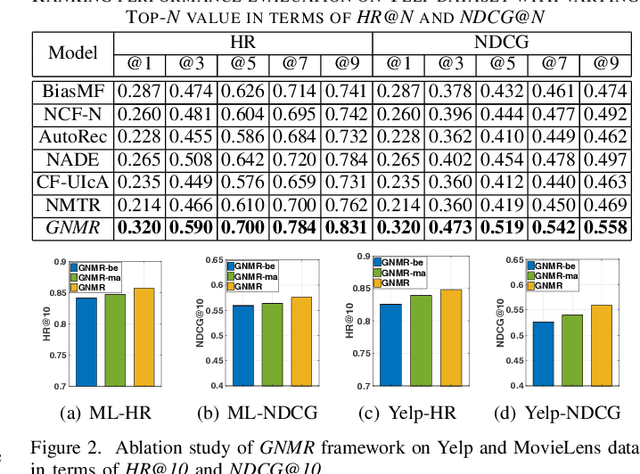
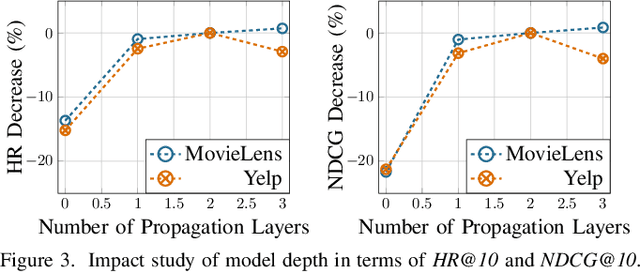

Many previous studies aim to augment collaborative filtering with deep neural network techniques, so as to achieve better recommendation performance. However, most existing deep learning-based recommender systems are designed for modeling singular type of user-item interaction behavior, which can hardly distill the heterogeneous relations between user and item. In practical recommendation scenarios, there exist multityped user behaviors, such as browse and purchase. Due to the overlook of user's multi-behavioral patterns over different items, existing recommendation methods are insufficient to capture heterogeneous collaborative signals from user multi-behavior data. Inspired by the strength of graph neural networks for structured data modeling, this work proposes a Graph Neural Multi-Behavior Enhanced Recommendation (GNMR) framework which explicitly models the dependencies between different types of user-item interactions under a graph-based message passing architecture. GNMR devises a relation aggregation network to model interaction heterogeneity, and recursively performs embedding propagation between neighboring nodes over the user-item interaction graph. Experiments on real-world recommendation datasets show that our GNMR consistently outperforms state-of-the-art methods. The source code is available at https://github.com/akaxlh/GNMR.
Decompose the Sounds and Pixels, Recompose the Events
Dec 21, 2021

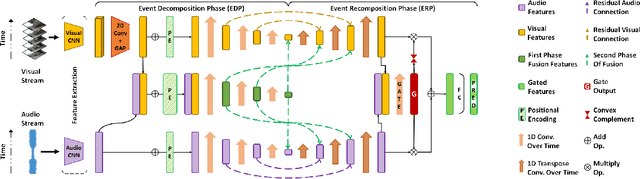
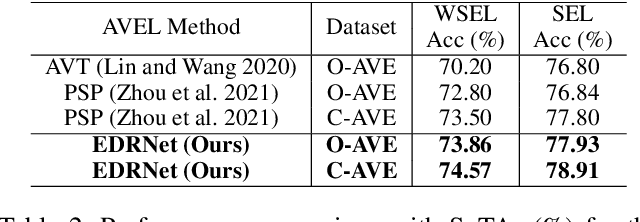
In this paper, we propose a framework centering around a novel architecture called the Event Decomposition Recomposition Network (EDRNet) to tackle the Audio-Visual Event (AVE) localization problem in the supervised and weakly supervised settings. AVEs in the real world exhibit common unravelling patterns (termed as Event Progress Checkpoints (EPC)), which humans can perceive through the cooperation of their auditory and visual senses. Unlike earlier methods which attempt to recognize entire event sequences, the EDRNet models EPCs and inter-EPC relationships using stacked temporal convolutions. Based on the postulation that EPC representations are theoretically consistent for an event category, we introduce the State Machine Based Video Fusion, a novel augmentation technique that blends source videos using different EPC template sequences. Additionally, we design a new loss function called the Land-Shore-Sea loss to compactify continuous foreground and background representations. Lastly, to alleviate the issue of confusing events during weak supervision, we propose a prediction stabilization method called Bag to Instance Label Correction. Experiments on the AVE dataset show that our collective framework outperforms the state-of-the-art by a sizable margin.
Traffic Flow Forecasting with Spatial-Temporal Graph Diffusion Network
Oct 08, 2021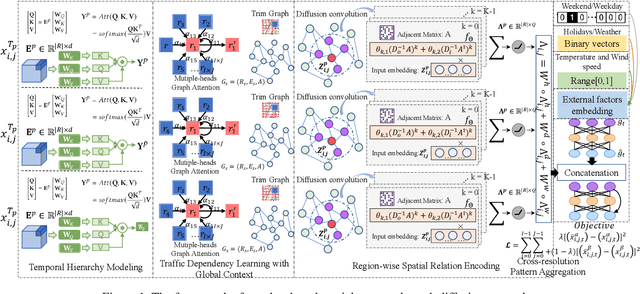
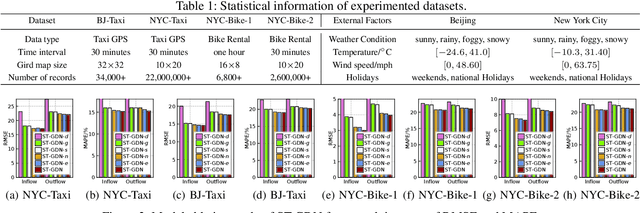
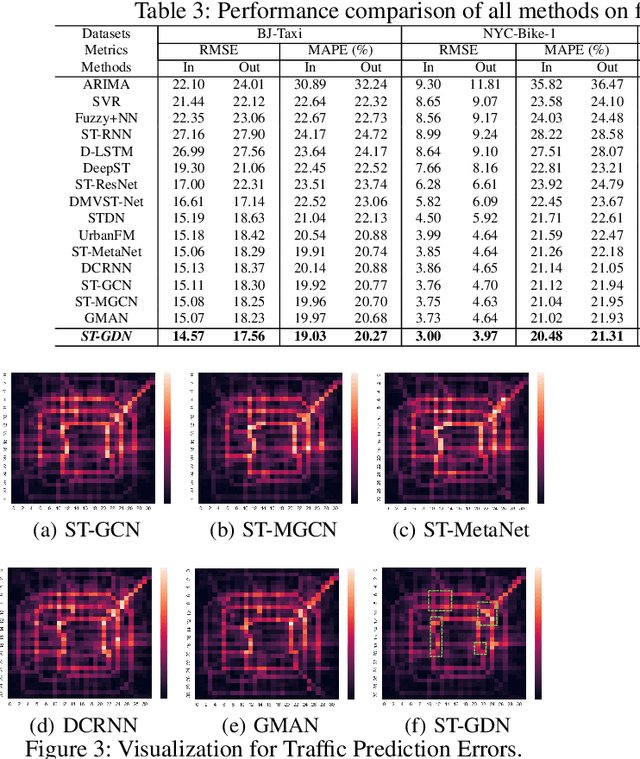
Accurate forecasting of citywide traffic flow has been playing critical role in a variety of spatial-temporal mining applications, such as intelligent traffic control and public risk assessment. While previous work has made significant efforts to learn traffic temporal dynamics and spatial dependencies, two key limitations exist in current models. First, only the neighboring spatial correlations among adjacent regions are considered in most existing methods, and the global inter-region dependency is ignored. Additionally, these methods fail to encode the complex traffic transition regularities exhibited with time-dependent and multi-resolution in nature. To tackle these challenges, we develop a new traffic prediction framework-Spatial-Temporal Graph Diffusion Network (ST-GDN). In particular, ST-GDN is a hierarchically structured graph neural architecture which learns not only the local region-wise geographical dependencies, but also the spatial semantics from a global perspective. Furthermore, a multi-scale attention network is developed to empower ST-GDN with the capability of capturing multi-level temporal dynamics. Experiments on several real-life traffic datasets demonstrate that ST-GDN outperforms different types of state-of-the-art baselines. Source codes of implementations are available at https://github.com/jill001/ST-GDN.
Multiplex Behavioral Relation Learning for Recommendation via Memory Augmented Transformer Network
Oct 08, 2021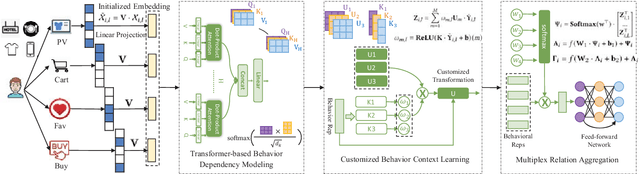

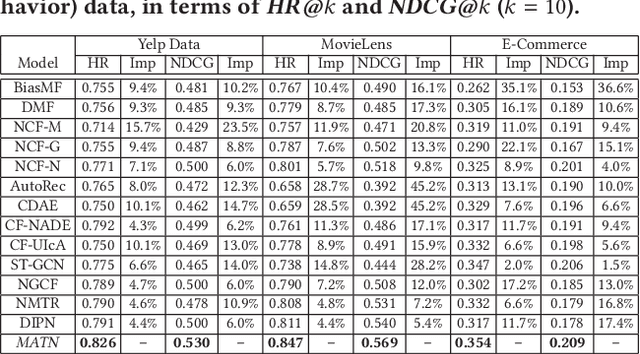
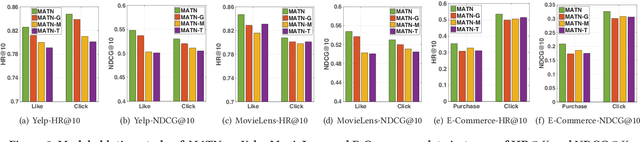
Capturing users' precise preferences is of great importance in various recommender systems (eg., e-commerce platforms), which is the basis of how to present personalized interesting product lists to individual users. In spite of significant progress has been made to consider relations between users and items, most of the existing recommendation techniques solely focus on singular type of user-item interactions. However, user-item interactive behavior is often exhibited with multi-type (e.g., page view, add-to-favorite and purchase) and inter-dependent in nature. The overlook of multiplex behavior relations can hardly recognize the multi-modal contextual signals across different types of interactions, which limit the feasibility of current recommendation methods. To tackle the above challenge, this work proposes a Memory-Augmented Transformer Networks (MATN), to enable the recommendation with multiplex behavioral relational information, and joint modeling of type-specific behavioral context and type-wise behavior inter-dependencies, in a fully automatic manner. In our MATN framework, we first develop a transformer-based multi-behavior relation encoder, to make the learned interaction representations be reflective of the cross-type behavior relations. Furthermore, a memory attention network is proposed to supercharge MATN capturing the contextual signals of different types of behavior into the category-specific latent embedding space. Finally, a cross-behavior aggregation component is introduced to promote the comprehensive collaboration across type-aware interaction behavior representations, and discriminate their inherent contributions in assisting recommendations. Extensive experiments on two benchmark datasets and a real-world e-commence user behavior data demonstrate significant improvements obtained by MATN over baselines. Codes are available at: https://github.com/akaxlh/MATN.
Knowledge-Enhanced Hierarchical Graph Transformer Network for Multi-Behavior Recommendation
Oct 08, 2021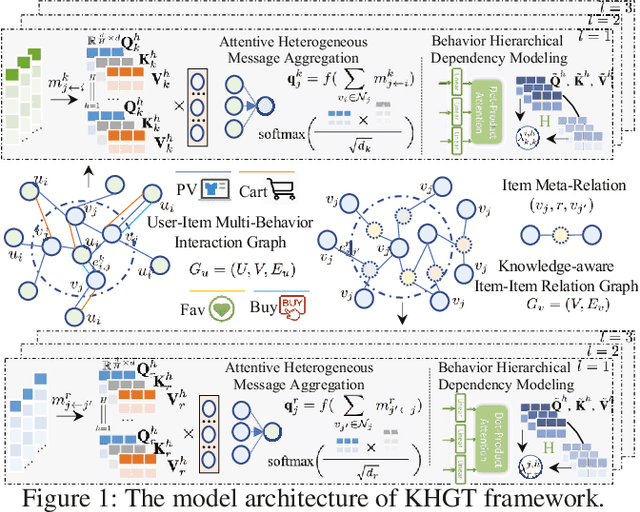

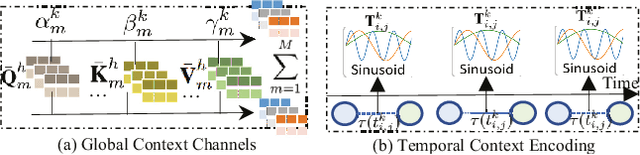
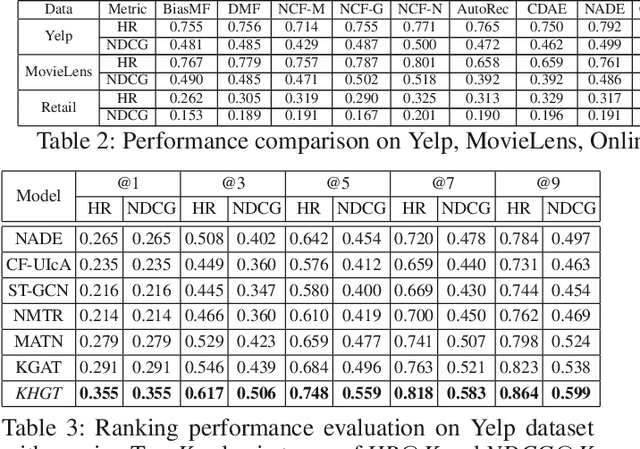
Accurate user and item embedding learning is crucial for modern recommender systems. However, most existing recommendation techniques have thus far focused on modeling users' preferences over singular type of user-item interactions. Many practical recommendation scenarios involve multi-typed user interactive behaviors (e.g., page view, add-to-favorite and purchase), which presents unique challenges that cannot be handled by current recommendation solutions. In particular: i) complex inter-dependencies across different types of user behaviors; ii) the incorporation of knowledge-aware item relations into the multi-behavior recommendation framework; iii) dynamic characteristics of multi-typed user-item interactions. To tackle these challenges, this work proposes a Knowledge-Enhanced Hierarchical Graph Transformer Network (KHGT), to investigate multi-typed interactive patterns between users and items in recommender systems. Specifically, KHGT is built upon a graph-structured neural architecture to i) capture type-specific behavior characteristics; ii) explicitly discriminate which types of user-item interactions are more important in assisting the forecasting task on the target behavior. Additionally, we further integrate the graph attention layer with the temporal encoding strategy, to empower the learned embeddings be reflective of both dedicated multiplex user-item and item-item relations, as well as the underlying interaction dynamics. Extensive experiments conducted on three real-world datasets show that KHGT consistently outperforms many state-of-the-art recommendation methods across various evaluation settings. Our implementation code is available at https://github.com/akaxlh/KHGT.