 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Multi-Perception Features for Real-Word Image Super-resolution
May 26, 2023Currently, there are two popular approaches for addressing real-world image super-resolution problems: degradation-estimation-based and blind-based methods. However, degradation-estimation-based methods may be inaccurate in estimating the degradation, making them less applicable to real-world LR images. On the other hand, blind-based methods are often limited by their fixed single perception information, which hinders their ability to handle diverse perceptual characteristics. To overcome this limitation, we propose a novel SR method called MPF-Net that leverages multiple perceptual features of input images. Our method incorporates a Multi-Perception Feature Extraction (MPFE) module to extract diverse perceptual information and a series of newly-designed Cross-Perception Blocks (CPB) to combine this information for effective super-resolution reconstruction. Additionally, we introduce a contrastive regularization term (CR) that improves the model's learning capability by using newly generated HR and LR images as positive and negative samples for ground truth HR. Experimental results on challenging real-world SR datasets demonstrate that our approach significantly outperforms existing state-of-the-art methods in both qualitative and quantitative measures.
GRAN: Ghost Residual Attention Network for Single Image Super Resolution
Mar 02, 2023Recently, many works have designed wider and deeper networks to achieve higher image super-resolution performance. Despite their outstanding performance, they still suffer from high computational resources, preventing them from directly applying to embedded devices. To reduce the computation resources and maintain performance, we propose a novel Ghost Residual Attention Network (GRAN) for efficient super-resolution. This paper introduces Ghost Residual Attention Block (GRAB) groups to overcome the drawbacks of the standard convolutional operation, i.e., redundancy of the intermediate feature. GRAB consists of the Ghost Module and Channel and Spatial Attention Module (CSAM) to alleviate the generation of redundant features. Specifically, Ghost Module can reveal information underlying intrinsic features by employing linear operations to replace the standard convolutions. Reducing redundant features by the Ghost Module, our model decreases memory and computing resource requirements in the network. The CSAM pays more comprehensive attention to where and what the feature extraction is, which is critical to recovering the image details. Experiments conducted on the benchmark datasets demonstrate the superior performance of our method in both qualitative and quantitative. Compared to the baseline models, we achieve higher performance with lower computational resources, whose parameters and FLOPs have decreased by more than ten times.
Take a Prior from Other Tasks for Severe Blur Removal
Feb 14, 2023



Recovering clear structures from severely blurry inputs is a challenging problem due to the large movements between the camera and the scene. Although some works apply segmentation maps on human face images for deblurring, they cannot handle natural scenes because objects and degradation are more complex, and inaccurate segmentation maps lead to a loss of details. For general scene deblurring, the feature space of the blurry image and corresponding sharp image under the high-level vision task is closer, which inspires us to rely on other tasks (e.g. classification) to learn a comprehensive prior in severe blur removal cases. We propose a cross-level feature learning strategy based on knowledge distillation to learn the priors, which include global contexts and sharp local structures for recovering potential details. In addition, we propose a semantic prior embedding layer with multi-level aggregation and semantic attention transformation to integrate the priors effectively. We introduce the proposed priors to various models, including the UNet and other mainstream deblurring baselines, leading to better performance on severe blur removal. Extensive experiments on natural image deblurring benchmarks and real-world images, such as GoPro and RealBlur datasets, demonstrate our method's effectiveness and generalization ability.
UniNL: Aligning Representation Learning with Scoring Function for OOD Detection via Unified Neighborhood Learning
Oct 19, 2022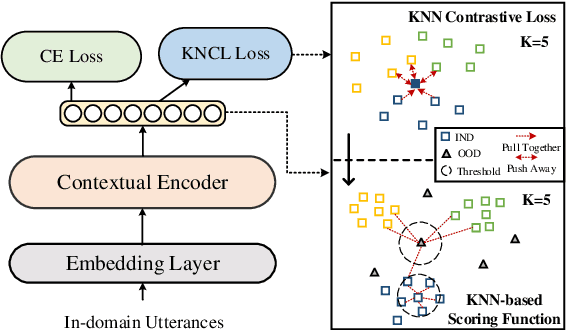
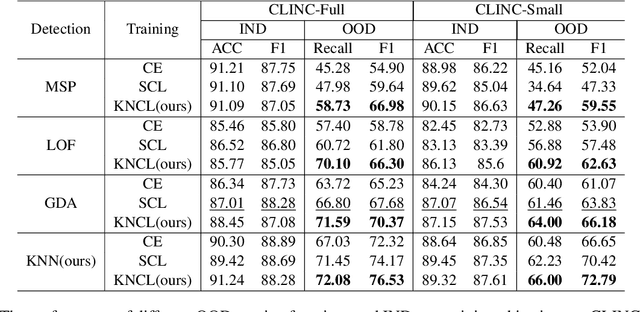

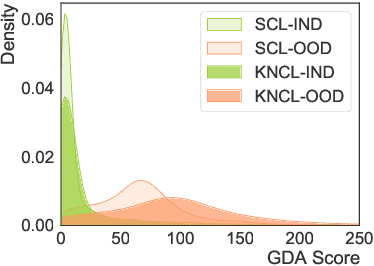
Detecting out-of-domain (OOD) intents from user queries is essential for avoiding wrong operations in task-oriented dialogue systems. The key challenge is how to distinguish in-domain (IND) and OOD intents. Previous methods ignore the alignment between representation learning and scoring function, limiting the OOD detection performance. In this paper, we propose a unified neighborhood learning framework (UniNL) to detect OOD intents. Specifically, we design a K-nearest neighbor contrastive learning (KNCL) objective for representation learning and introduce a KNN-based scoring function for OOD detection. We aim to align representation learning with scoring function. Experiments and analysis on two benchmark datasets show the effectiveness of our method.
Watch the Neighbors: A Unified K-Nearest Neighbor Contrastive Learning Framework for OOD Intent Discovery
Oct 17, 2022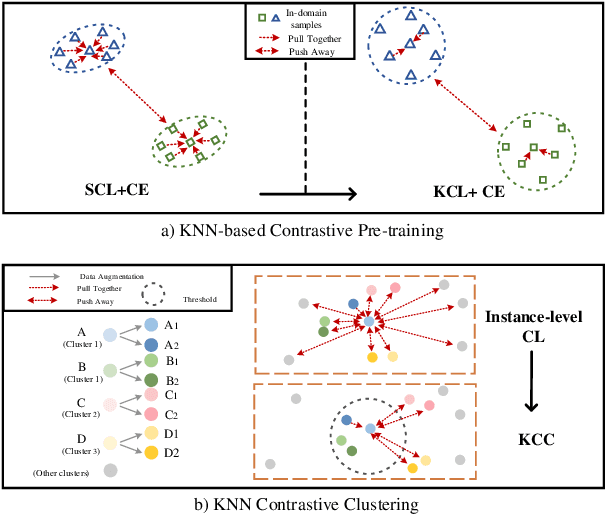
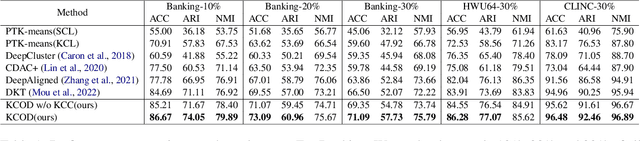
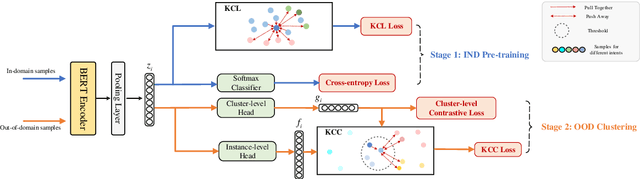
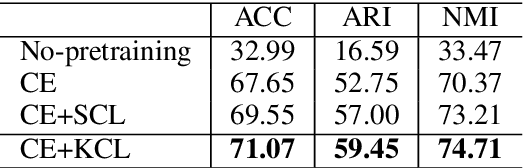
Discovering out-of-domain (OOD) intent is important for developing new skills in task-oriented dialogue systems. The key challenges lie in how to transfer prior in-domain (IND) knowledge to OOD clustering, as well as jointly learn OOD representations and cluster assignments. Previous methods suffer from in-domain overfitting problem, and there is a natural gap between representation learning and clustering objectives. In this paper, we propose a unified K-nearest neighbor contrastive learning framework to discover OOD intents. Specifically, for IND pre-training stage, we propose a KCL objective to learn inter-class discriminative features, while maintaining intra-class diversity, which alleviates the in-domain overfitting problem. For OOD clustering stage, we propose a KCC method to form compact clusters by mining true hard negative samples, which bridges the gap between clustering and representation learning. Extensive experiments on three benchmark datasets show that our method achieves substantial improvements over the state-of-the-art methods.
Semi-Supervised Knowledge-Grounded Pre-training for Task-Oriented Dialog Systems
Oct 17, 2022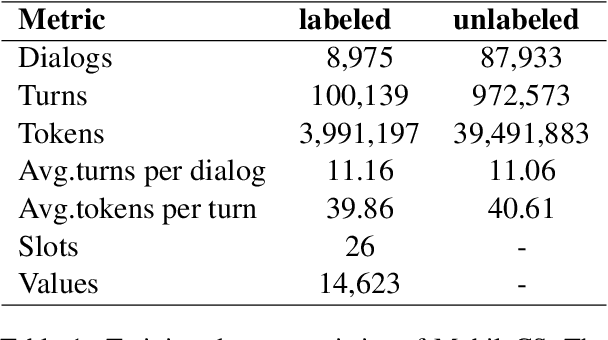
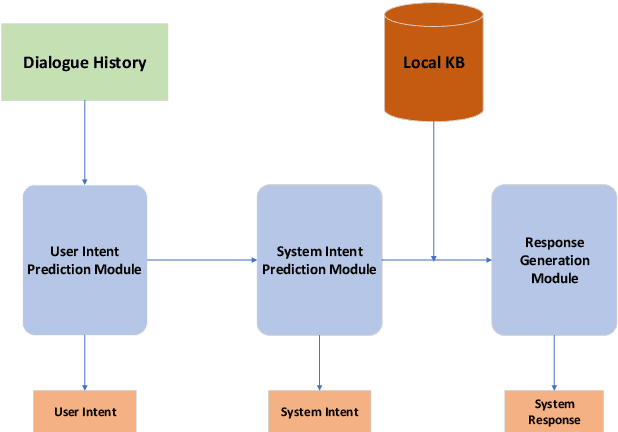
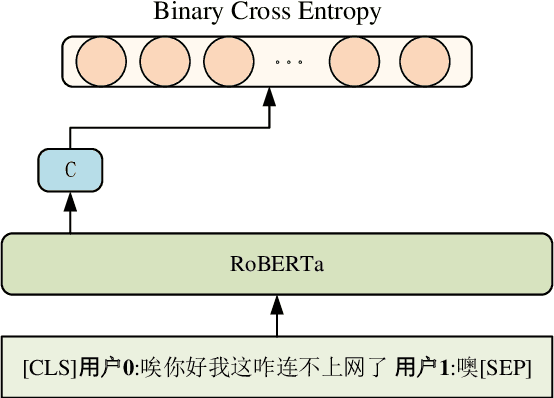
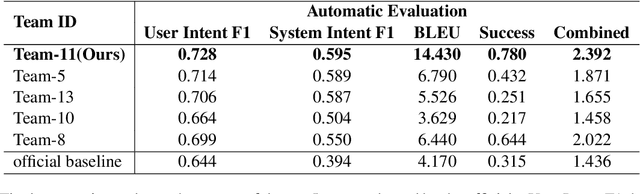
Recent advances in neural approaches greatly improve task-oriented dialogue (TOD) systems which assist users to accomplish their goals. However, such systems rely on costly manually labeled dialogs which are not available in practical scenarios. In this paper, we present our models for Track 2 of the SereTOD 2022 challenge, which is the first challenge of building semi-supervised and reinforced TOD systems on a large-scale real-world Chinese TOD dataset MobileCS. We build a knowledge-grounded dialog model to formulate dialog history and local KB as input and predict the system response. And we perform semi-supervised pre-training both on the labeled and unlabeled data. Our system achieves the first place both in the automatic evaluation and human interaction, especially with higher BLEU (+7.64) and Success (+13.6\%) than the second place.
Disentangling Confidence Score Distribution for Out-of-Domain Intent Detection with Energy-Based Learning
Oct 17, 2022
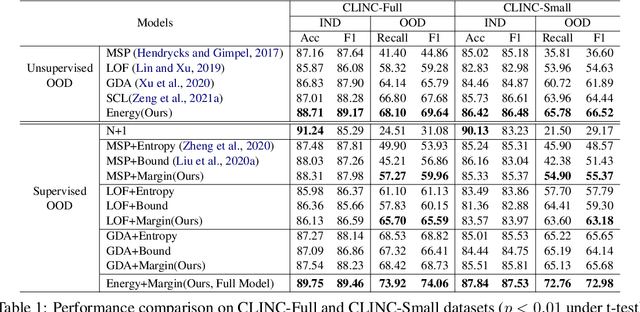
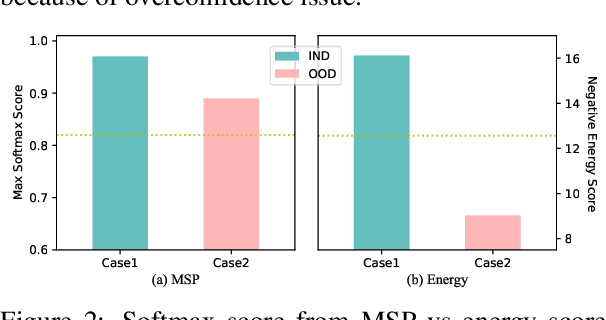
Detecting Out-of-Domain (OOD) or unknown intents from user queries is essential in a task-oriented dialog system. Traditional softmax-based confidence scores are susceptible to the overconfidence issue. In this paper, we propose a simple but strong energy-based score function to detect OOD where the energy scores of OOD samples are higher than IND samples. Further, given a small set of labeled OOD samples, we introduce an energy-based margin objective for supervised OOD detection to explicitly distinguish OOD samples from INDs. Comprehensive experiments and analysis prove our method helps disentangle confidence score distributions of IND and OOD data.\footnote{Our code is available at \url{https://github.com/pris-nlp/EMNLP2022-energy_for_OOD/}.}
Distribution Calibration for Out-of-Domain Detection with Bayesian Approximation
Sep 14, 2022
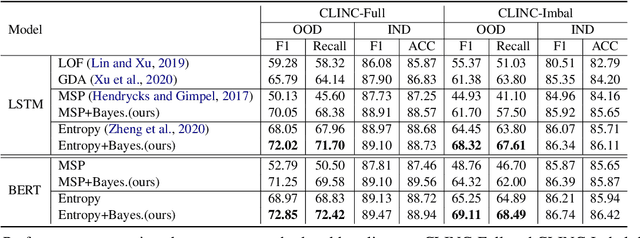
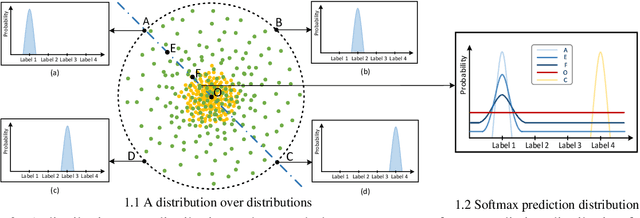
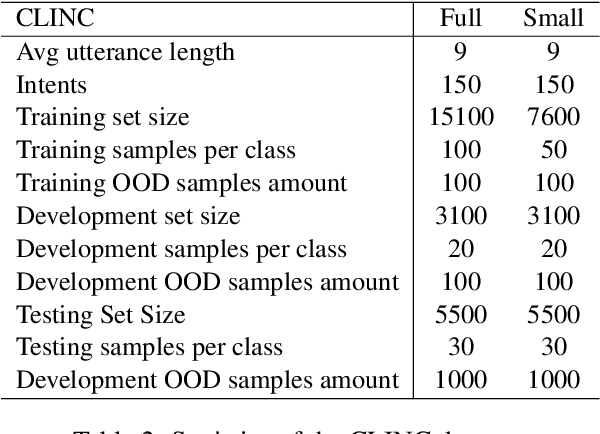
Out-of-Domain (OOD) detection is a key component in a task-oriented dialog system, which aims to identify whether a query falls outside the predefined supported intent set. Previous softmax-based detection algorithms are proved to be overconfident for OOD samples. In this paper, we analyze overconfident OOD comes from distribution uncertainty due to the mismatch between the training and test distributions, which makes the model can't confidently make predictions thus probably causing abnormal softmax scores. We propose a Bayesian OOD detection framework to calibrate distribution uncertainty using Monte-Carlo Dropout. Our method is flexible and easily pluggable into existing softmax-based baselines and gains 33.33\% OOD F1 improvements with increasing only 0.41\% inference time compared to MSP. Further analyses show the effectiveness of Bayesian learning for OOD detection.
Generalized Intent Discovery: Learning from Open World Dialogue System
Sep 13, 2022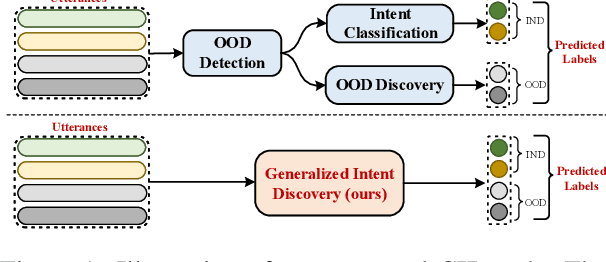

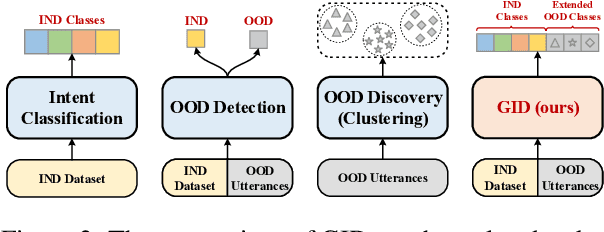

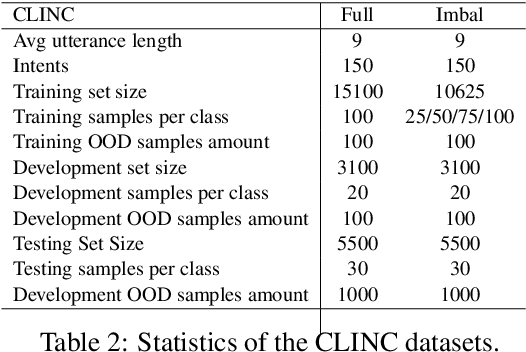
Traditional intent classification models are based on a pre-defined intent set and only recognize limited in-domain (IND) intent classes. But users may input out-of-domain (OOD) queries in a practical dialogue system. Such OOD queries can provide directions for future improvement. In this paper, we define a new task, Generalized Intent Discovery (GID), which aims to extend an IND intent classifier to an open-world intent set including IND and OOD intents. We hope to simultaneously classify a set of labeled IND intent classes while discovering and recognizing new unlabeled OOD types incrementally. We construct three public datasets for different application scenarios and propose two kinds of frameworks, pipeline-based and end-to-end for future work. Further, we conduct exhaustive experiments and qualitative analysis to comprehend key challenges and provide new guidance for future GID research.
SlimSeg: Slimmable Semantic Segmentation with Boundary Supervision
Jul 13, 2022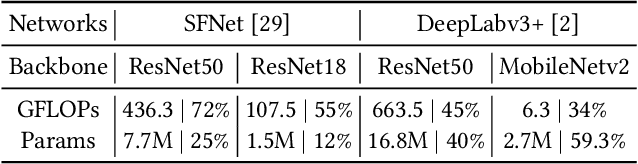
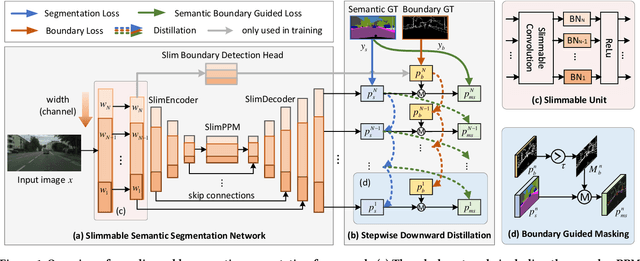

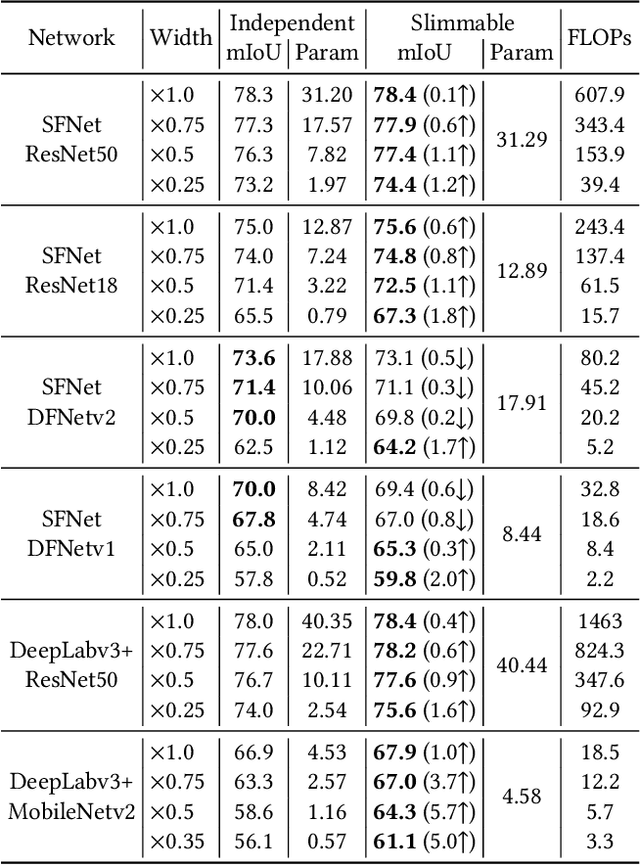
Accurate semantic segmentation models typically require significant computational resources, inhibiting their use in practical applications. Recent works rely on well-crafted lightweight models to achieve fast inference. However, these models cannot flexibly adapt to varying accuracy and efficiency requirements. In this paper, we propose a simple but effective slimmable semantic segmentation (SlimSeg) method, which can be executed at different capacities during inference depending on the desired accuracy-efficiency tradeoff. More specifically, we employ parametrized channel slimming by stepwise downward knowledge distillation during training. Motivated by the observation that the differences between segmentation results of each submodel are mainly near the semantic borders, we introduce an additional boundary guided semantic segmentation loss to further improve the performance of each submodel. We show that our proposed SlimSeg with various mainstream networks can produce flexible models that provide dynamic adjustment of computational cost and better performance than independent models. Extensive experiments on semantic segmentation benchmarks, Cityscapes and CamVid, demonstrate the generalization ability of our framework.