 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Individual Experience to Collective Evidence: A Reporting-Based Framework for Identifying Systemic Harms
Feb 12, 2025When an individual reports a negative interaction with some system, how can their personal experience be contextualized within broader patterns of system behavior? We study the incident database problem, where individual reports of adverse events arrive sequentially, and are aggregated over time. In this work, our goal is to identify whether there are subgroups--defined by any combination of relevant features--that are disproportionately likely to experience harmful interactions with the system. We formalize this problem as a sequential hypothesis test, and identify conditions on reporting behavior that are sufficient for making inferences about disparities in true rates of harm across subgroups. We show that algorithms for sequential hypothesis tests can be applied to this problem with a standard multiple testing correction. We then demonstrate our method on real-world datasets, including mortgage decisions and vaccine side effects; on each, our method (re-)identifies subgroups known to experience disproportionate harm using only a fraction of the data that was initially used to discover them.
Projection-free Adaptive Regret with Membership Oracles
Dec 14, 2022
In the framework of online convex optimization, most iterative algorithms require the computation of projections onto convex sets, which can be computationally expensive. To tackle this problem HK12 proposed the study of projection-free methods that replace projections with less expensive computations. The most common approach is based on the Frank-Wolfe method, that uses linear optimization computation in lieu of projections. Recent work by GK22 gave sublinear adaptive regret guarantees with projection free algorithms based on the Frank Wolfe approach. In this work we give projection-free algorithms that are based on a different technique, inspired by Mhammedi22, that replaces projections by set-membership computations. We propose a simple lazy gradient-based algorithm with a Minkowski regularization that attains near-optimal adaptive regret bounds. For general convex loss functions we improve previous adaptive regret bounds from $O(T^{3/4})$ to $O(\sqrt{T})$, and further to tight interval dependent bound $\tilde{O}(\sqrt{I})$ where $I$ denotes the interval length. For strongly convex functions we obtain the first poly-logarithmic adaptive regret bounds using a projection-free algorithm.
Valid Inference after Causal Discovery
Aug 11, 2022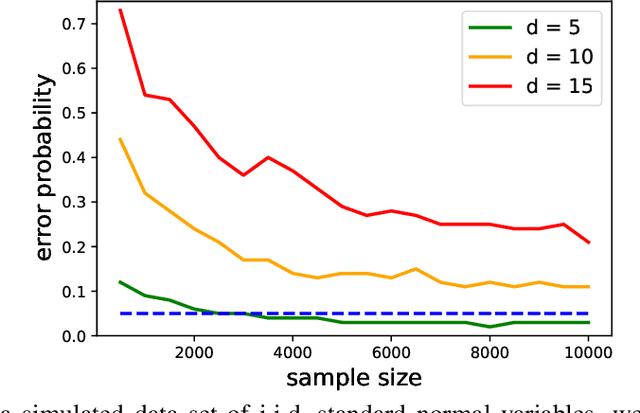

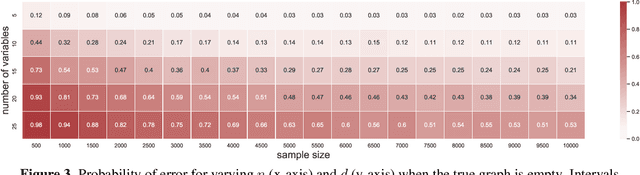
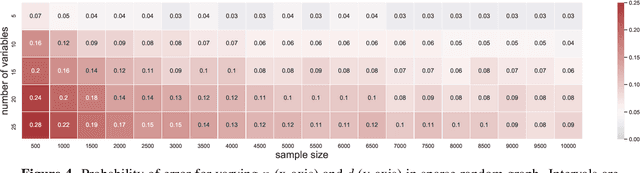
Causal graph discovery and causal effect estimation are two fundamental tasks in causal inference. While many methods have been developed for each task individually, statistical challenges arise when applying these methods jointly: estimating causal effects after running causal discovery algorithms on the same data leads to "double dipping," invalidating coverage guarantees of classical confidence intervals. To this end, we develop tools for valid post-causal-discovery inference. One key contribution is a randomized version of the greedy equivalence search (GES) algorithm, which permits a valid, finite-sample correction of classical confidence intervals. Across empirical studies, we show that a naive combination of causal discovery and subsequent inference algorithms typically leads to highly inflated miscoverage rates; at the same time, our noisy GES method provides reliable coverage control while achieving more accurate causal graph recovery than data splitting.
Lyapunov Density Models: Constraining Distribution Shift in Learning-Based Control
Jun 21, 2022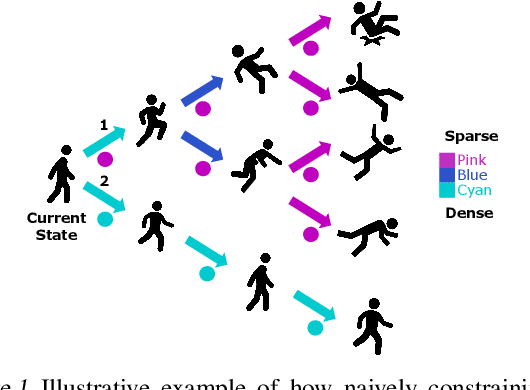
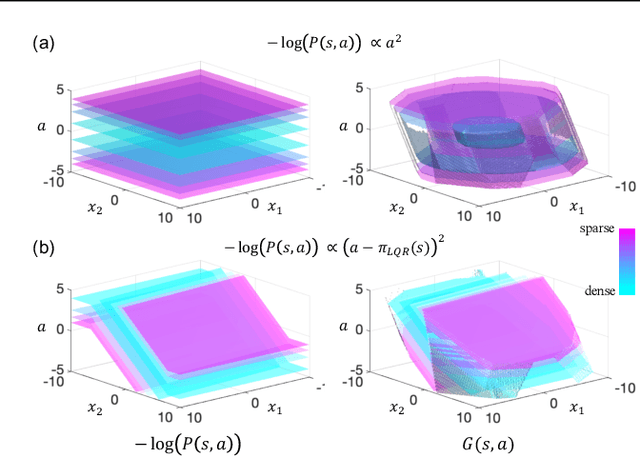
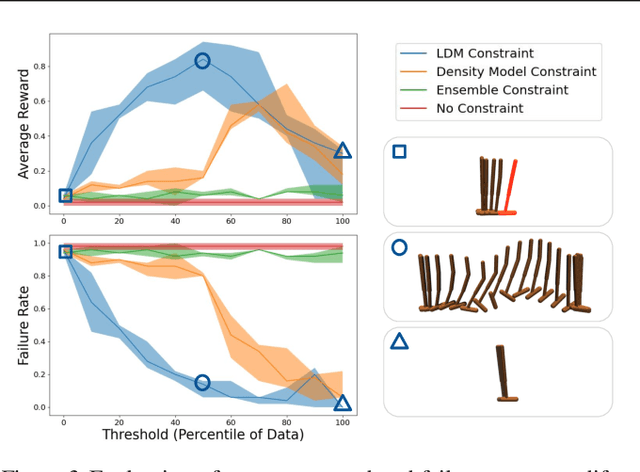
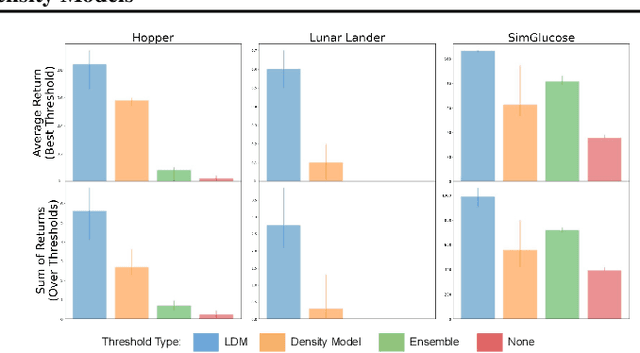
Learned models and policies can generalize effectively when evaluated within the distribution of the training data, but can produce unpredictable and erroneous outputs on out-of-distribution inputs. In order to avoid distribution shift when deploying learning-based control algorithms, we seek a mechanism to constrain the agent to states and actions that resemble those that it was trained on. In control theory, Lyapunov stability and control-invariant sets allow us to make guarantees about controllers that stabilize the system around specific states, while in machine learning, density models allow us to estimate the training data distribution. Can we combine these two concepts, producing learning-based control algorithms that constrain the system to in-distribution states using only in-distribution actions? In this work, we propose to do this by combining concepts from Lyapunov stability and density estimation, introducing Lyapunov density models: a generalization of control Lyapunov functions and density models that provides guarantees on an agent's ability to stay in-distribution over its entire trajectory.
Online Control of Unknown Time-Varying Dynamical Systems
Feb 16, 2022We study online control of time-varying linear systems with unknown dynamics in the nonstochastic control model. At a high level, we demonstrate that this setting is \emph{qualitatively harder} than that of either unknown time-invariant or known time-varying dynamics, and complement our negative results with algorithmic upper bounds in regimes where sublinear regret is possible. More specifically, we study regret bounds with respect to common classes of policies: Disturbance Action (SLS), Disturbance Response (Youla), and linear feedback policies. While these three classes are essentially equivalent for LTI systems, we demonstrate that these equivalences break down for time-varying systems. We prove a lower bound that no algorithm can obtain sublinear regret with respect to the first two classes unless a certain measure of system variability also scales sublinearly in the horizon. Furthermore, we show that offline planning over the state linear feedback policies is NP-hard, suggesting hardness of the online learning problem. On the positive side, we give an efficient algorithm that attains a sublinear regret bound against the class of Disturbance Response policies up to the aforementioned system variability term. In fact, our algorithm enjoys sublinear \emph{adaptive} regret bounds, which is a strictly stronger metric than standard regret and is more appropriate for time-varying systems. We sketch extensions to Disturbance Action policies and partial observation, and propose an inefficient algorithm for regret against linear state feedback policies.
Machine Learning for Mechanical Ventilation Control (Extended Abstract)
Nov 23, 2021Mechanical ventilation is one of the most widely used therapies in the ICU. However, despite broad application from anaesthesia to COVID-related life support, many injurious challenges remain. We frame these as a control problem: ventilators must let air in and out of the patient's lungs according to a prescribed trajectory of airway pressure. Industry-standard controllers, based on the PID method, are neither optimal nor robust. Our data-driven approach learns to control an invasive ventilator by training on a simulator itself trained on data collected from the ventilator. This method outperforms popular reinforcement learning algorithms and even controls the physical ventilator more accurately and robustly than PID. These results underscore how effective data-driven methodologies can be for invasive ventilation and suggest that more general forms of ventilation (e.g., non-invasive, adaptive) may also be amenable.
Machine Learning for Mechanical Ventilation Control
Feb 26, 2021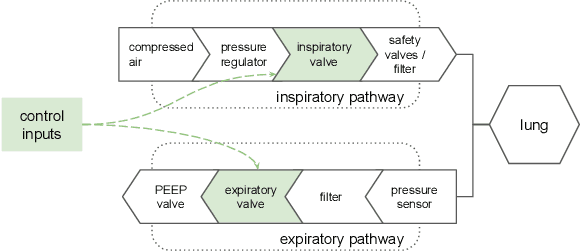
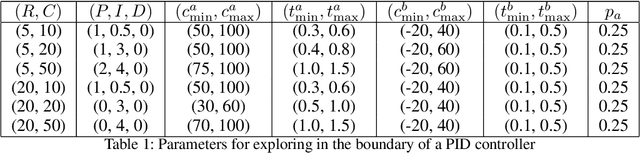
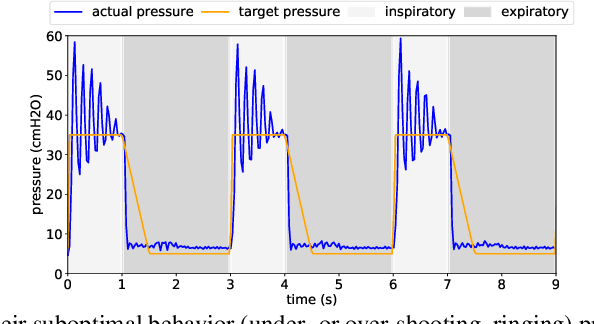
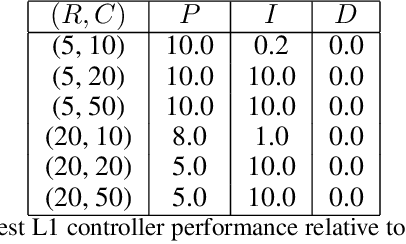
We consider the problem of controlling an invasive mechanical ventilator for pressure-controlled ventilation: a controller must let air in and out of a sedated patient's lungs according to a trajectory of airway pressures specified by a clinician. Hand-tuned PID controllers and similar variants have comprised the industry standard for decades, yet can behave poorly by over- or under-shooting their target or oscillating rapidly. We consider a data-driven machine learning approach: First, we train a simulator based on data we collect from an artificial lung. Then, we train deep neural network controllers on these simulators.We show that our controllers are able to track target pressure waveforms significantly better than PID controllers. We further show that a learned controller generalizes across lungs with varying characteristics much more readily than PID controllers do.
Deluca -- A Differentiable Control Library: Environments, Methods, and Benchmarking
Feb 19, 2021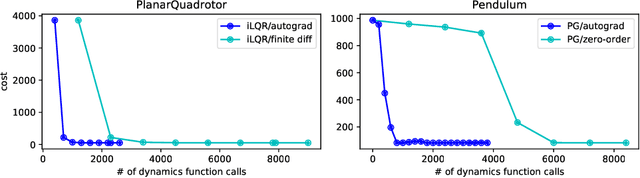
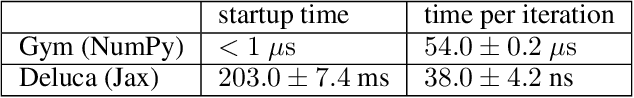
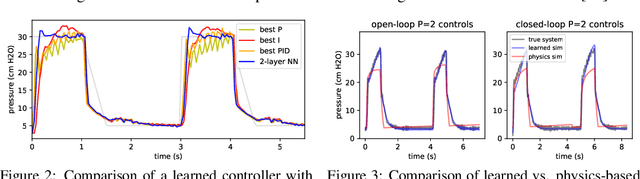
We present an open-source library of natively differentiable physics and robotics environments, accompanied by gradient-based control methods and a benchmark-ing suite. The introduced environments allow auto-differentiation through the simulation dynamics, and thereby permit fast training of controllers. The library features several popular environments, including classical control settings from OpenAI Gym. We also provide a novel differentiable environment, based on deep neural networks, that simulates medical ventilation. We give several use-cases of new scientific results obtained using the library. This includes a medical ventilator simulator and controller, an adaptive control method for time-varying linear dynamical systems, and new gradient-based methods for control of linear dynamical systems with adversarial perturbations.
Non-Stochastic Control with Bandit Feedback
Aug 12, 2020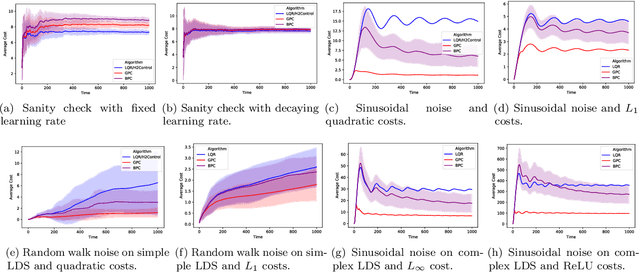
We study the problem of controlling a linear dynamical system with adversarial perturbations where the only feedback available to the controller is the scalar loss, and the loss function itself is unknown. For this problem, with either a known or unknown system, we give an efficient sublinear regret algorithm. The main algorithmic difficulty is the dependence of the loss on past controls. To overcome this issue, we propose an efficient algorithm for the general setting of bandit convex optimization for loss functions with memory, which may be of independent interest.
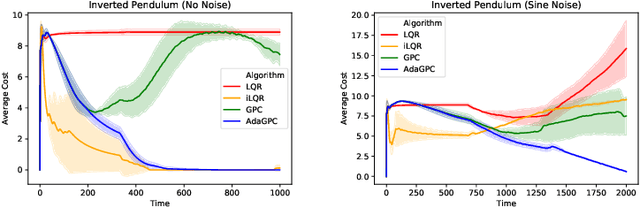
Adaptive Regret for Control of Time-Varying Dynamics
Jul 16, 2020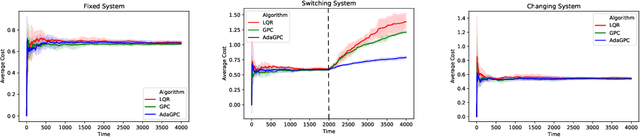
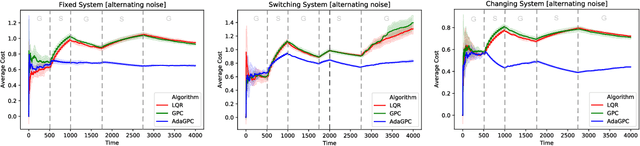
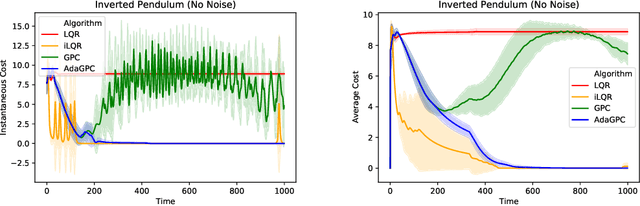
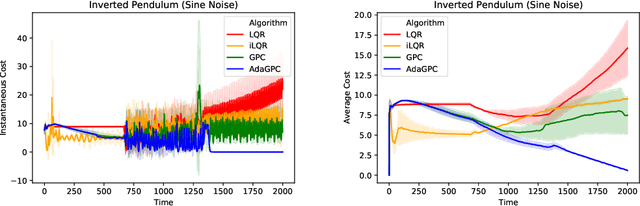
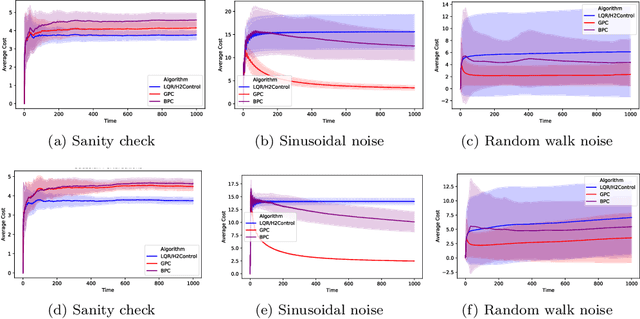
We consider regret minimization for online control with time-varying linear dynamical systems. The metric of performance we study is adaptive policy regret, or regret compared to the best policy on {\it any interval in time}. We give an efficient algorithm that attains first-order adaptive regret guarantees for the setting of online convex optimization with memory. We also show that these first-order bounds are nearly tight. This algorithm is then used to derive a controller with adaptive regret guarantees that provably competes with the best linear dynamical controller on any interval in time. We validate these theoretical findings experimentally on (1) simulations of time-varying linear dynamics and disturbances, and (2) the non-linear inverted pendulum benchmark.