 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-lingual Functional Evaluation for Large Language Models
Jun 25, 2025Multi-lingual competence in large language models is often evaluated via static data benchmarks such as Belebele, M-MMLU and M-GSM. However, these evaluations often fail to provide an adequate understanding of the practical performance and robustness of models across multi-lingual settings. In response, we create multi-lingual functional benchmarks -- Cross-Lingual Grade School Math Symbolic (CL-GSM Symbolic) and Cross-Lingual Instruction-Following Eval (CL-IFEval)-- by translating existing functional benchmark templates from English to five additional languages that span the range of resources available for NLP: French, Spanish, Hindi, Arabic and Yoruba. Our results reveal that some static multi-lingual benchmarks capture functional performance much more closely than others (i.e. across models, there is a 24%, 17% and 18% decrease in performance between M-GSM and CL-GSM Symbolic in English, French and Spanish respectively; similarly there's a 15 - 24% performance drop across languages between Belebele and CL-IFEval, and only a 0.5% to 3% performance drop between M-MMLU and CL-IFEval). Similarly, we find that model robustness across languages varies significantly, with certain languages (eg. Arabic, English) being the most consistently well performing across evaluation iterations.
From Individual Experience to Collective Evidence: A Reporting-Based Framework for Identifying Systemic Harms
Feb 12, 2025When an individual reports a negative interaction with some system, how can their personal experience be contextualized within broader patterns of system behavior? We study the incident database problem, where individual reports of adverse events arrive sequentially, and are aggregated over time. In this work, our goal is to identify whether there are subgroups--defined by any combination of relevant features--that are disproportionately likely to experience harmful interactions with the system. We formalize this problem as a sequential hypothesis test, and identify conditions on reporting behavior that are sufficient for making inferences about disparities in true rates of harm across subgroups. We show that algorithms for sequential hypothesis tests can be applied to this problem with a standard multiple testing correction. We then demonstrate our method on real-world datasets, including mortgage decisions and vaccine side effects; on each, our method (re-)identifies subgroups known to experience disproportionate harm using only a fraction of the data that was initially used to discover them.
The Data Addition Dilemma
Aug 08, 2024



In many machine learning for healthcare tasks, standard datasets are constructed by amassing data across many, often fundamentally dissimilar, sources. But when does adding more data help, and when does it hinder progress on desired model outcomes in real-world settings? We identify this situation as the \textit{Data Addition Dilemma}, demonstrating that adding training data in this multi-source scaling context can at times result in reduced overall accuracy, uncertain fairness outcomes, and reduced worst-subgroup performance. We find that this possibly arises from an empirically observed trade-off between model performance improvements due to data scaling and model deterioration from distribution shift. We thus establish baseline strategies for navigating this dilemma, introducing distribution shift heuristics to guide decision-making on which data sources to add in data scaling, in order to yield the expected model performance improvements. We conclude with a discussion of the required considerations for data collection and suggestions for studying data composition and scale in the age of increasingly larger models.
REFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023

Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
Organizational Governance of Emerging Technologies: AI Adoption in Healthcare
May 10, 2023



Private and public sector structures and norms refine how emerging technology is used in practice. In healthcare, despite a proliferation of AI adoption, the organizational governance surrounding its use and integration is often poorly understood. What the Health AI Partnership (HAIP) aims to do in this research is to better define the requirements for adequate organizational governance of AI systems in healthcare settings and support health system leaders to make more informed decisions around AI adoption. To work towards this understanding, we first identify how the standards for the AI adoption in healthcare may be designed to be used easily and efficiently. Then, we map out the precise decision points involved in the practical institutional adoption of AI technology within specific health systems. Practically, we achieve this through a multi-organizational collaboration with leaders from major health systems across the United States and key informants from related fields. Working with the consultancy IDEO [dot] org, we were able to conduct usability-testing sessions with healthcare and AI ethics professionals. Usability analysis revealed a prototype structured around mock key decision points that align with how organizational leaders approach technology adoption. Concurrently, we conducted semi-structured interviews with 89 professionals in healthcare and other relevant fields. Using a modified grounded theory approach, we were able to identify 8 key decision points and comprehensive procedures throughout the AI adoption lifecycle. This is one of the most detailed qualitative analyses to date of the current governance structures and processes involved in AI adoption by health systems in the United States. We hope these findings can inform future efforts to build capabilities to promote the safe, effective, and responsible adoption of emerging technologies in healthcare.
The Fallacy of AI Functionality
Jun 20, 2022
Deployed AI systems often do not work. They can be constructed haphazardly, deployed indiscriminately, and promoted deceptively. However, despite this reality, scholars, the press, and policymakers pay too little attention to functionality. This leads to technical and policy solutions focused on "ethical" or value-aligned deployments, often skipping over the prior question of whether a given system functions, or provides any benefits at all.To describe the harms of various types of functionality failures, we analyze a set of case studies to create a taxonomy of known AI functionality issues. We then point to policy and organizational responses that are often overlooked and become more readily available once functionality is drawn into focus. We argue that functionality is a meaningful AI policy challenge, operating as a necessary first step towards protecting affected communities from algorithmic harm.
AI and the Everything in the Whole Wide World Benchmark
Nov 26, 2021
There is a tendency across different subfields in AI to valorize a small collection of influential benchmarks. These benchmarks operate as stand-ins for a range of anointed common problems that are frequently framed as foundational milestones on the path towards flexible and generalizable AI systems. State-of-the-art performance on these benchmarks is widely understood as indicative of progress towards these long-term goals. In this position paper, we explore the limits of such benchmarks in order to reveal the construct validity issues in their framing as the functionally "general" broad measures of progress they are set up to be.
About Face: A Survey of Facial Recognition Evaluation
Feb 01, 2021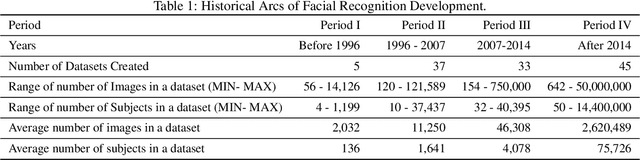
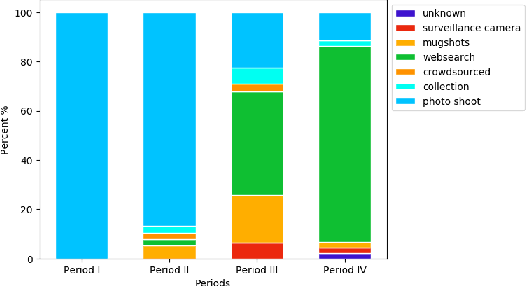
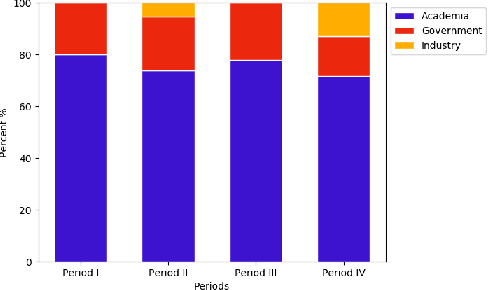
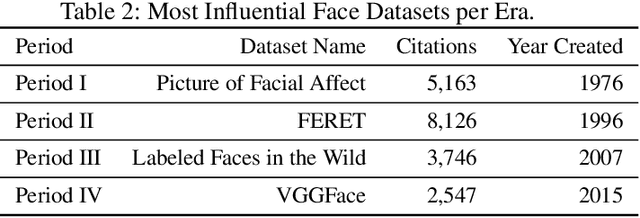
We survey over 100 face datasets constructed between 1976 to 2019 of 145 million images of over 17 million subjects from a range of sources, demographics and conditions. Our historical survey reveals that these datasets are contextually informed, shaped by changes in political motivations, technological capability and current norms. We discuss how such influences mask specific practices (some of which may actually be harmful or otherwise problematic) and make a case for the explicit communication of such details in order to establish a more grounded understanding of the technology's function in the real world.
Data and its contents: A survey of dataset development and use in machine learning research
Dec 09, 2020Datasets have played a foundational role in the advancement of machine learning research. They form the basis for the models we design and deploy, as well as our primary medium for benchmarking and evaluation. Furthermore, the ways in which we collect, construct and share these datasets inform the kinds of problems the field pursues and the methods explored in algorithm development. However, recent work from a breadth of perspectives has revealed the limitations of predominant practices in dataset collection and use. In this paper, we survey the many concerns raised about the way we collect and use data in machine learning and advocate that a more cautious and thorough understanding of data is necessary to address several of the practical and ethical issues of the field.
ABOUT ML: Annotation and Benchmarking on Understanding and Transparency of Machine Learning Lifecycles
Jan 08, 2020
We present the "Annotation and Benchmarking on Understanding and Transparency of Machine Learning Lifecycles" (ABOUT ML) project as an initiative to operationalize ML transparency and work towards a standard ML documentation practice. We make the case for the project's relevance and effectiveness in consolidating disparate efforts across a variety of stakeholders, as well as bringing in the perspectives of currently missing voices that will be valuable in shaping future conversations. We describe the details of the initiative and the gaps we hope this project will help address.