 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask3D for 3D Semantic Instance Segmentation
Oct 06, 2022
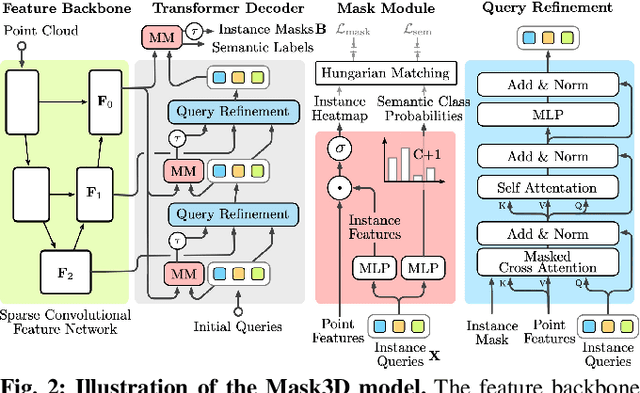
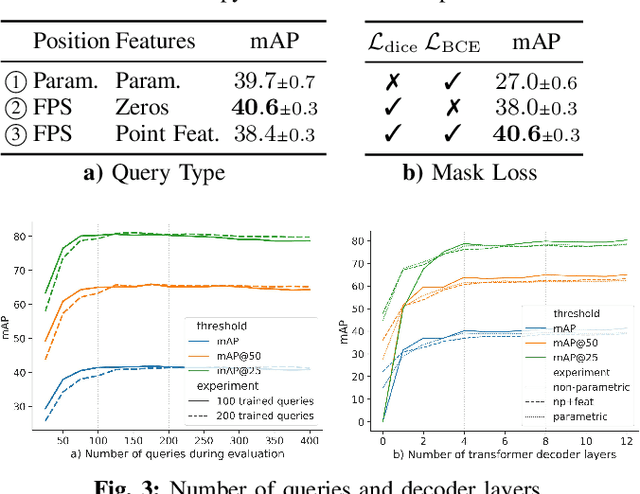
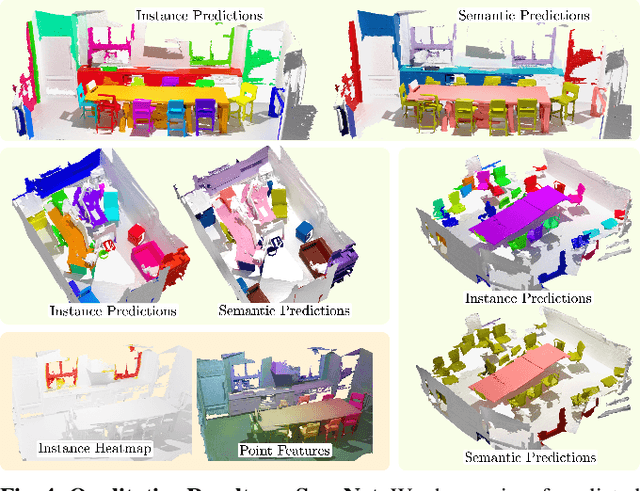
Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Sep 22, 2022



As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident. In our work, we aim to train performant 3D generative models that synthesize textured meshes which can be directly consumed by 3D rendering engines, thus immediately usable in downstream applications. Prior works on 3D generative modeling either lack geometric details, are limited in the mesh topology they can produce, typically do not support textures, or utilize neural renderers in the synthesis process, which makes their use in common 3D software non-trivial. In this work, we introduce GET3D, a Generative model that directly generates Explicit Textured 3D meshes with complex topology, rich geometric details, and high-fidelity textures. We bridge recent success in the differentiable surface modeling, differentiable rendering as well as 2D Generative Adversarial Networks to train our model from 2D image collections. GET3D is able to generate high-quality 3D textured meshes, ranging from cars, chairs, animals, motorbikes and human characters to buildings, achieving significant improvements over previous methods.
MvDeCor: Multi-view Dense Correspondence Learning for Fine-grained 3D Segmentation
Aug 18, 2022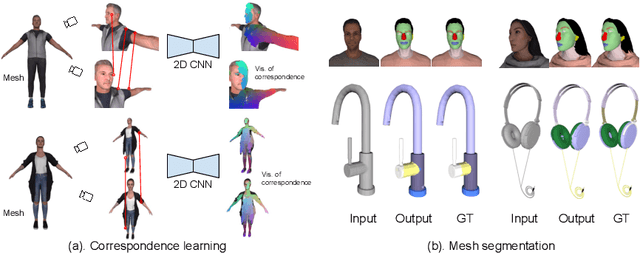
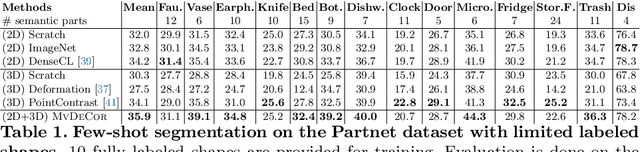
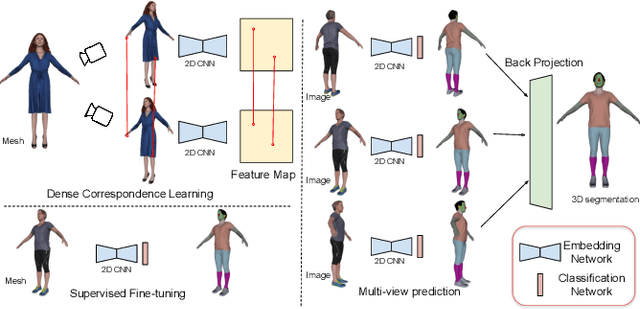
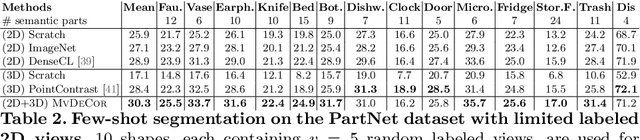
We propose to utilize self-supervised techniques in the 2D domain for fine-grained 3D shape segmentation tasks. This is inspired by the observation that view-based surface representations are more effective at modeling high-resolution surface details and texture than their 3D counterparts based on point clouds or voxel occupancy. Specifically, given a 3D shape, we render it from multiple views, and set up a dense correspondence learning task within the contrastive learning framework. As a result, the learned 2D representations are view-invariant and geometrically consistent, leading to better generalization when trained on a limited number of labeled shapes compared to alternatives that utilize self-supervision in 2D or 3D alone. Experiments on textured (RenderPeople) and untextured (PartNet) 3D datasets show that our method outperforms state-of-the-art alternatives in fine-grained part segmentation. The improvements over baselines are greater when only a sparse set of views is available for training or when shapes are textured, indicating that MvDeCor benefits from both 2D processing and 3D geometric reasoning.
Language-Grounded Indoor 3D Semantic Segmentation in the Wild
Apr 16, 2022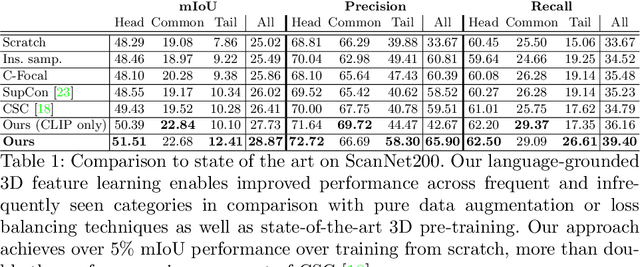
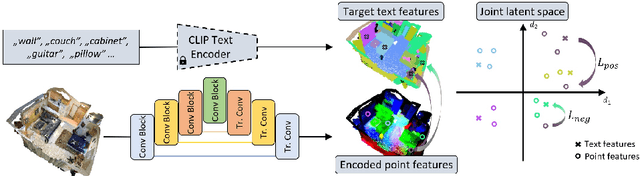
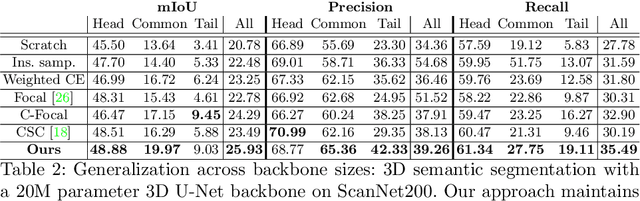
Recent advances in 3D semantic segmentation with deep neural networks have shown remarkable success, with rapid performance increase on available datasets. However, current 3D semantic segmentation benchmarks contain only a small number of categories -- less than 30 for ScanNet and SemanticKITTI, for instance, which are not enough to reflect the diversity of real environments (e.g., semantic image understanding covers hundreds to thousands of classes). Thus, we propose to study a larger vocabulary for 3D semantic segmentation with a new extended benchmark on ScanNet data with 200 class categories, an order of magnitude more than previously studied. This large number of class categories also induces a large natural class imbalance, both of which are challenging for existing 3D semantic segmentation methods. To learn more robust 3D features in this context, we propose a language-driven pre-training method to encourage learned 3D features that might have limited training examples to lie close to their pre-trained text embeddings. Extensive experiments show that our approach consistently outperforms state-of-the-art 3D pre-training for 3D semantic segmentation on our proposed benchmark (+9% relative mIoU), including limited-data scenarios with +25% relative mIoU using only 5% annotations.
Learning Smooth Neural Functions via Lipschitz Regularization
Feb 16, 2022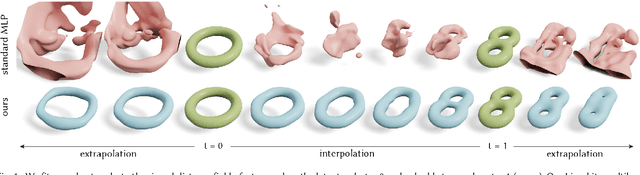

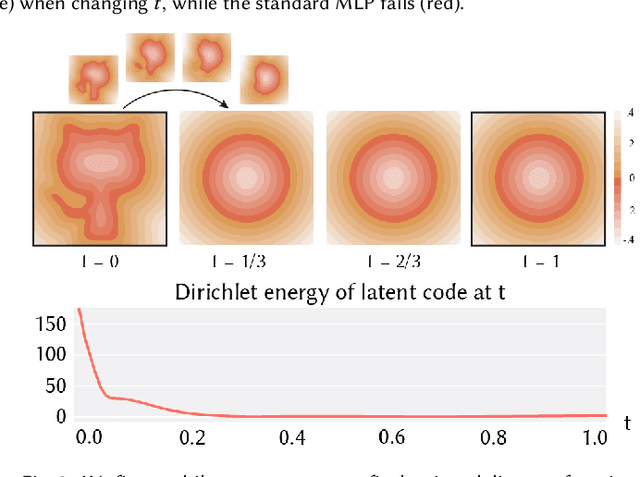

Neural implicit fields have recently emerged as a useful representation for 3D shapes. These fields are commonly represented as neural networks which map latent descriptors and 3D coordinates to implicit function values. The latent descriptor of a neural field acts as a deformation handle for the 3D shape it represents. Thus, smoothness with respect to this descriptor is paramount for performing shape-editing operations. In this work, we introduce a novel regularization designed to encourage smooth latent spaces in neural fields by penalizing the upper bound on the field's Lipschitz constant. Compared with prior Lipschitz regularized networks, ours is computationally fast, can be implemented in four lines of code, and requires minimal hyperparameter tuning for geometric applications. We demonstrate the effectiveness of our approach on shape interpolation and extrapolation as well as partial shape reconstruction from 3D point clouds, showing both qualitative and quantitative improvements over existing state-of-the-art and non-regularized baselines.
Causal Scene BERT: Improving object detection by searching for challenging groups of data
Feb 08, 2022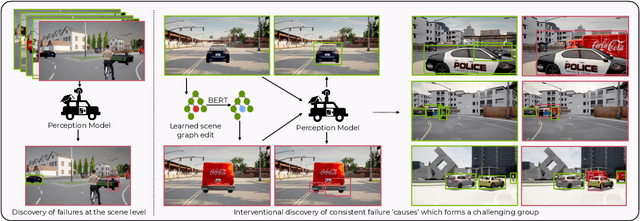
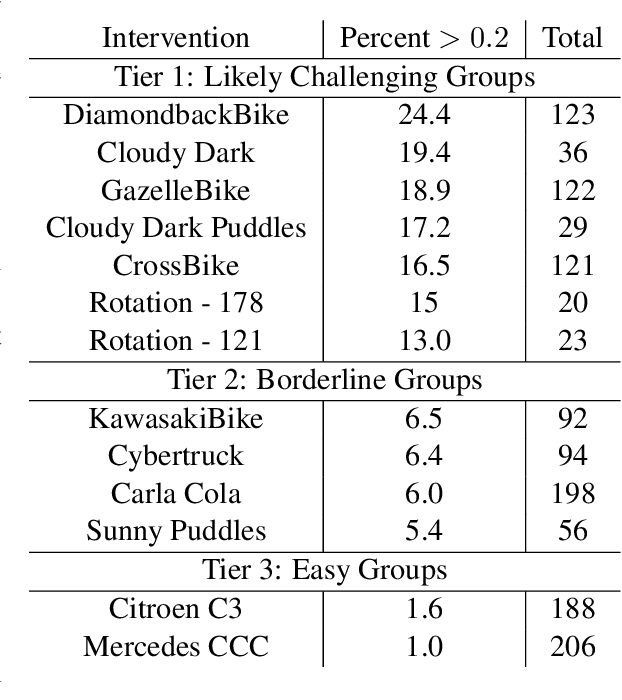
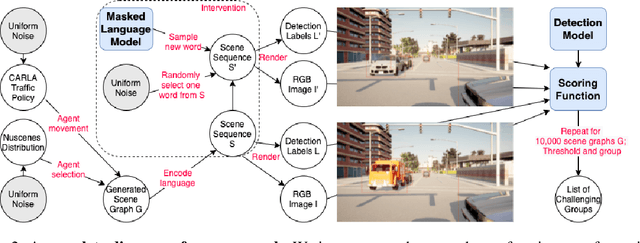
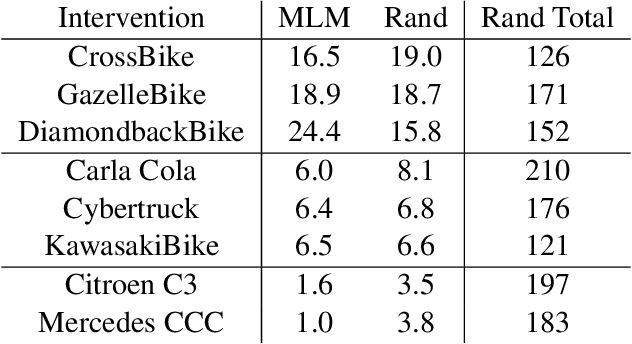
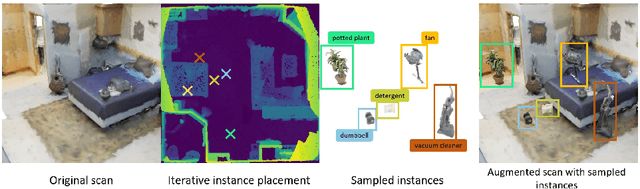
Modern computer vision applications rely on learning-based perception modules parameterized with neural networks for tasks like object detection. These modules frequently have low expected error overall but high error on atypical groups of data due to biases inherent in the training process. In building autonomous vehicles (AV), this problem is an especially important challenge because their perception modules are crucial to the overall system performance. After identifying failures in AV, a human team will comb through the associated data to group perception failures that share common causes. More data from these groups is then collected and annotated before retraining the model to fix the issue. In other words, error groups are found and addressed in hindsight. Our main contribution is a pseudo-automatic method to discover such groups in foresight by performing causal interventions on simulated scenes. To keep our interventions on the data manifold, we utilize masked language models. We verify that the prioritized groups found via intervention are challenging for the object detector and show that retraining with data collected from these groups helps inordinately compared to adding more IID data. We also plan to release software to run interventions in simulated scenes, which we hope will benefit the causality community.
Federated Learning with Heterogeneous Architectures using Graph HyperNetworks
Jan 20, 2022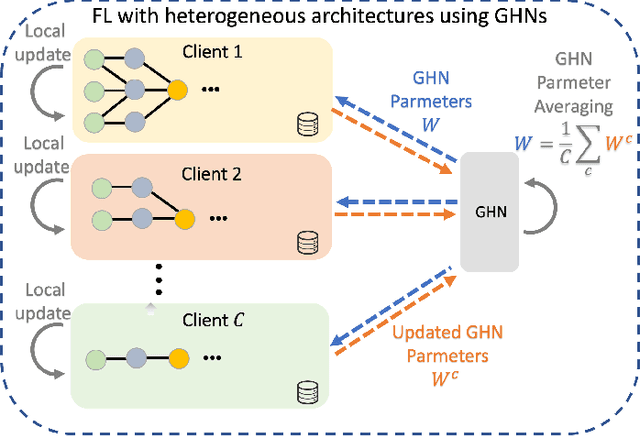
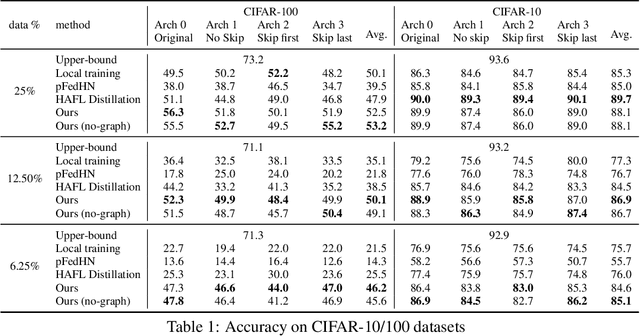
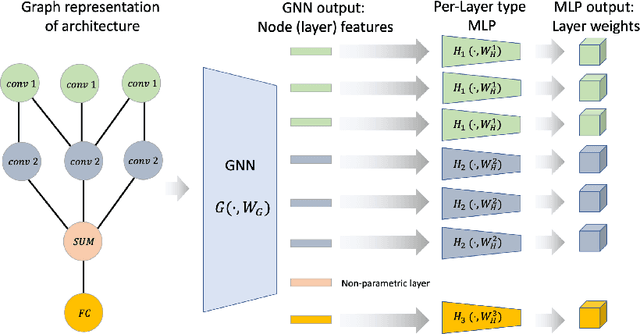
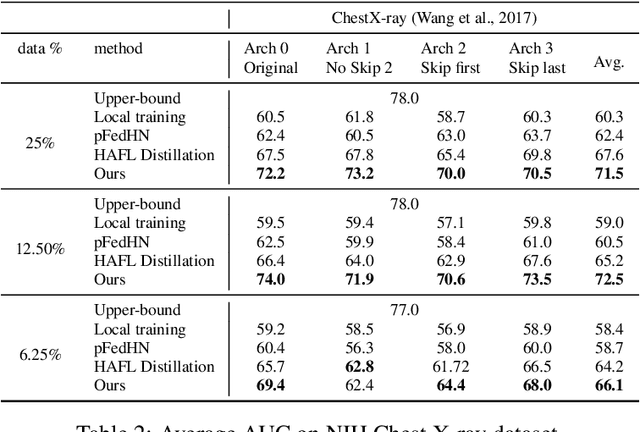
Standard Federated Learning (FL) techniques are limited to clients with identical network architectures. This restricts potential use-cases like cross-platform training or inter-organizational collaboration when both data privacy and architectural proprietary are required. We propose a new FL framework that accommodates heterogeneous client architecture by adopting a graph hypernetwork for parameter sharing. A property of the graph hyper network is that it can adapt to various computational graphs, thereby allowing meaningful parameter sharing across models. Unlike existing solutions, our framework does not limit the clients to share the same architecture type, makes no use of external data and does not require clients to disclose their model architecture. Compared with distillation-based and non-graph hypernetwork baselines, our method performs notably better on standard benchmarks. We additionally show encouraging generalization performance to unseen architectures.
Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior
Dec 09, 2021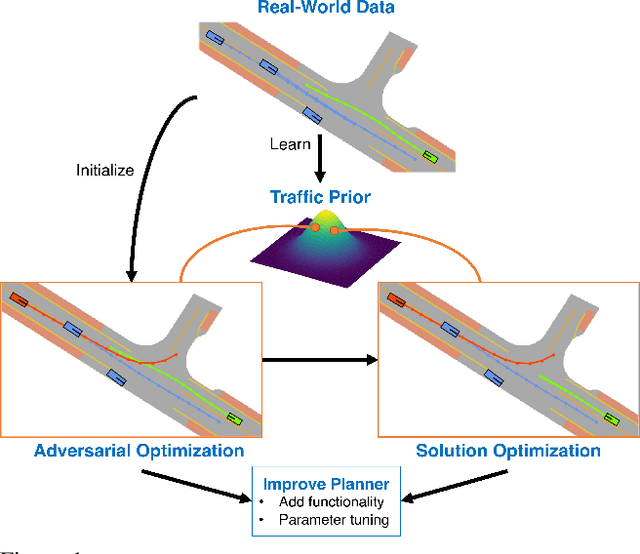

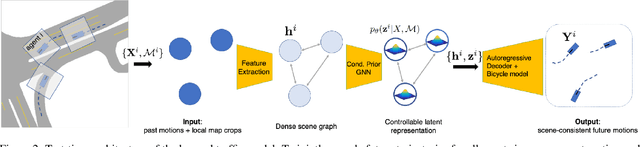

Evaluating and improving planning for autonomous vehicles requires scalable generation of long-tail traffic scenarios. To be useful, these scenarios must be realistic and challenging, but not impossible to drive through safely. In this work, we introduce STRIVE, a method to automatically generate challenging scenarios that cause a given planner to produce undesirable behavior, like collisions. To maintain scenario plausibility, the key idea is to leverage a learned model of traffic motion in the form of a graph-based conditional VAE. Scenario generation is formulated as an optimization in the latent space of this traffic model, effected by perturbing an initial real-world scene to produce trajectories that collide with a given planner. A subsequent optimization is used to find a "solution" to the scenario, ensuring it is useful to improve the given planner. Further analysis clusters generated scenarios based on collision type. We attack two planners and show that STRIVE successfully generates realistic, challenging scenarios in both cases. We additionally "close the loop" and use these scenarios to optimize hyperparameters of a rule-based planner.
Neural Fields in Visual Computing and Beyond
Nov 29, 2021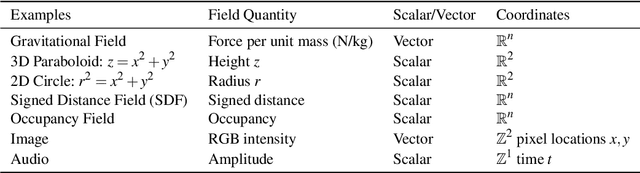
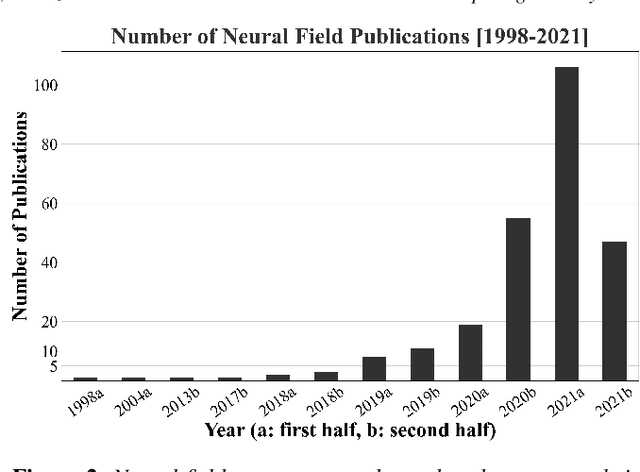

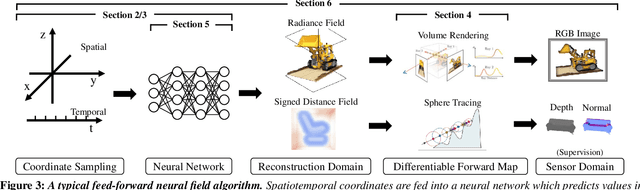
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.
Neural Fields as Learnable Kernels for 3D Reconstruction
Nov 26, 2021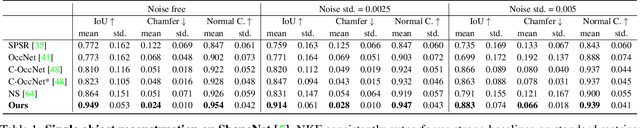

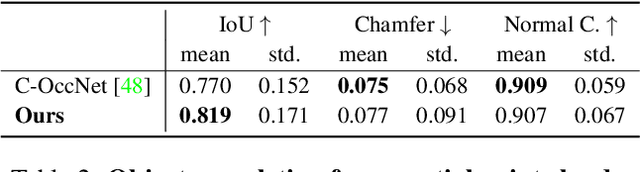
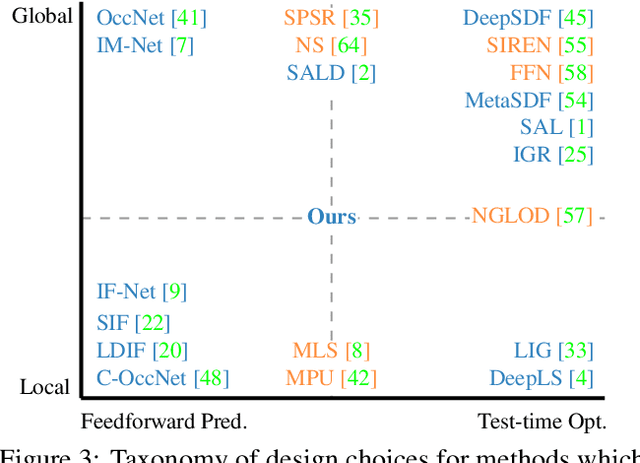
We present Neural Kernel Fields: a novel method for reconstructing implicit 3D shapes based on a learned kernel ridge regression. Our technique achieves state-of-the-art results when reconstructing 3D objects and large scenes from sparse oriented points, and can reconstruct shape categories outside the training set with almost no drop in accuracy. The core insight of our approach is that kernel methods are extremely effective for reconstructing shapes when the chosen kernel has an appropriate inductive bias. We thus factor the problem of shape reconstruction into two parts: (1) a backbone neural network which learns kernel parameters from data, and (2) a kernel ridge regression that fits the input points on-the-fly by solving a simple positive definite linear system using the learned kernel. As a result of this factorization, our reconstruction gains the benefits of data-driven methods under sparse point density while maintaining interpolatory behavior, which converges to the ground truth shape as input sampling density increases. Our experiments demonstrate a strong generalization capability to objects outside the train-set category and scanned scenes. Source code and pretrained models are available at https://nv-tlabs.github.io/nkf.