 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Unsupervised Realistic Visual Question Answering
Mar 09, 2023



The problem of realistic VQA (RVQA), where a model has to reject unanswerable questions (UQs) and answer answerable ones (AQs), is studied. We first point out 2 drawbacks in current RVQA research, where (1) datasets contain too many unchallenging UQs and (2) a large number of annotated UQs are required for training. To resolve the first drawback, we propose a new testing dataset, RGQA, which combines AQs from an existing VQA dataset with around 29K human-annotated UQs. These UQs consist of both fine-grained and coarse-grained image-question pairs generated with 2 approaches: CLIP-based and Perturbation-based. To address the second drawback, we introduce an unsupervised training approach. This combines pseudo UQs obtained by randomly pairing images and questions, with an RoI Mixup procedure to generate more fine-grained pseudo UQs, and model ensembling to regularize model confidence. Experiments show that using pseudo UQs significantly outperforms RVQA baselines. RoI Mixup and model ensembling further increase the gain. Finally, human evaluation reveals a performance gap between humans and models, showing that more RVQA research is needed.
DISCO: Adversarial Defense with Local Implicit Functions
Dec 11, 2022



The problem of adversarial defenses for image classification, where the goal is to robustify a classifier against adversarial examples, is considered. Inspired by the hypothesis that these examples lie beyond the natural image manifold, a novel aDversarIal defenSe with local impliCit functiOns (DISCO) is proposed to remove adversarial perturbations by localized manifold projections. DISCO consumes an adversarial image and a query pixel location and outputs a clean RGB value at the location. It is implemented with an encoder and a local implicit module, where the former produces per-pixel deep features and the latter uses the features in the neighborhood of query pixel for predicting the clean RGB value. Extensive experiments demonstrate that both DISCO and its cascade version outperform prior defenses, regardless of whether the defense is known to the attacker. DISCO is also shown to be data and parameter efficient and to mount defenses that transfers across datasets, classifiers and attacks.
YORO -- Lightweight End to End Visual Grounding
Nov 15, 2022



We present YORO - a multi-modal transformer encoder-only architecture for the Visual Grounding (VG) task. This task involves localizing, in an image, an object referred via natural language. Unlike the recent trend in the literature of using multi-stage approaches that sacrifice speed for accuracy, YORO seeks a better trade-off between speed an accuracy by embracing a single-stage design, without CNN backbone. YORO consumes natural language queries, image patches, and learnable detection tokens and predicts coordinates of the referred object, using a single transformer encoder. To assist the alignment between text and visual objects, a novel patch-text alignment loss is proposed. Extensive experiments are conducted on 5 different datasets with ablations on architecture design choices. YORO is shown to support real-time inference and outperform all approaches in this class (single-stage methods) by large margins. It is also the fastest VG model and achieves the best speed/accuracy trade-off in the literature.
Should All Proposals be Treated Equally in Object Detection?
Jul 07, 2022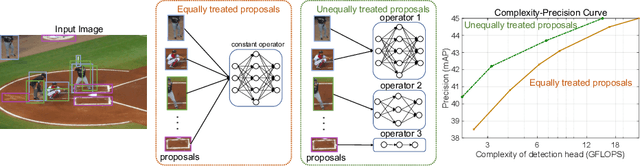
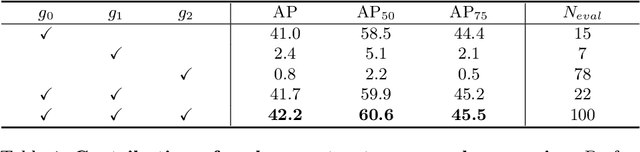
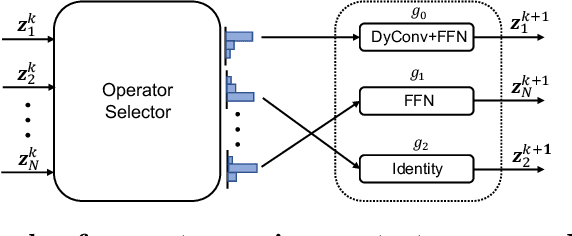
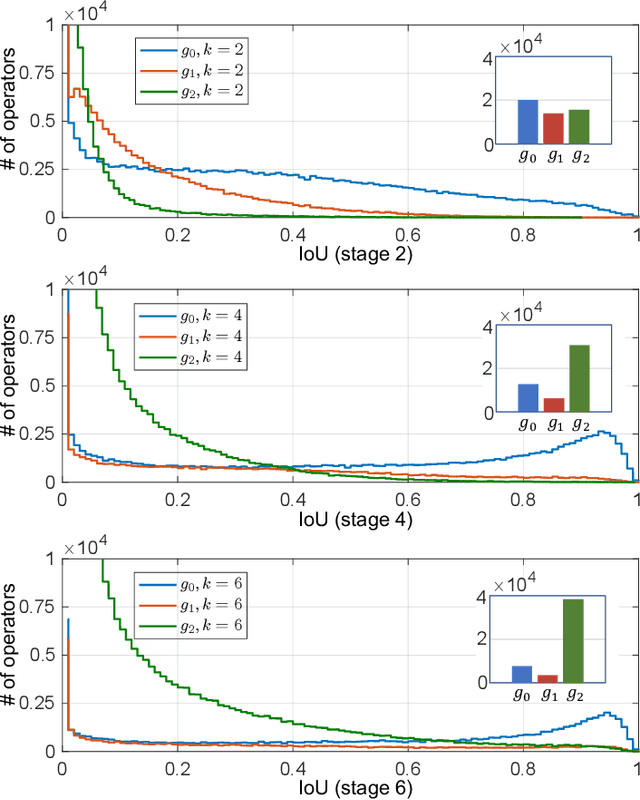
The complexity-precision trade-off of an object detector is a critical problem for resource constrained vision tasks. Previous works have emphasized detectors implemented with efficient backbones. The impact on this trade-off of proposal processing by the detection head is investigated in this work. It is hypothesized that improved detection efficiency requires a paradigm shift, towards the unequal processing of proposals, assigning more computation to good proposals than poor ones. This results in better utilization of available computational budget, enabling higher accuracy for the same FLOPS. We formulate this as a learning problem where the goal is to assign operators to proposals, in the detection head, so that the total computational cost is constrained and the precision is maximized. The key finding is that such matching can be learned as a function that maps each proposal embedding into a one-hot code over operators. While this function induces a complex dynamic network routing mechanism, it can be implemented by a simple MLP and learned end-to-end with off-the-shelf object detectors. This 'dynamic proposal processing' (DPP) is shown to outperform state-of-the-art end-to-end object detectors (DETR, Sparse R-CNN) by a clear margin for a given computational complexity.
Meta-Learning over Time for Destination Prediction Tasks
Jun 29, 2022
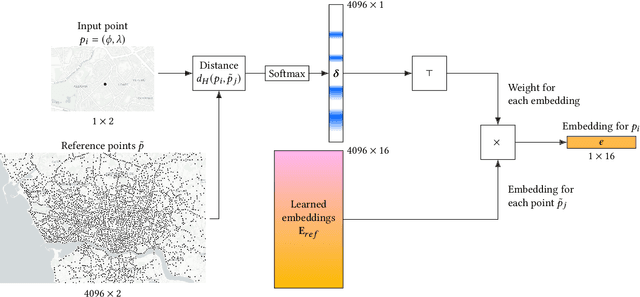

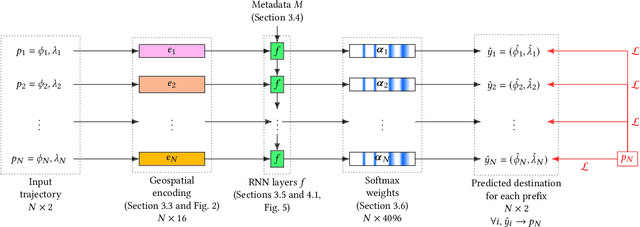
A need to understand and predict vehicles' behavior underlies both public and private goals in the transportation domain, including urban planning and management, ride-sharing services, and intelligent transportation systems. Individuals' preferences and intended destinations vary throughout the day, week, and year: for example, bars are most popular in the evenings, and beaches are most popular in the summer. Despite this principle, we note that recent studies on a popular benchmark dataset from Porto, Portugal have found, at best, only marginal improvements in predictive performance from incorporating temporal information. We propose an approach based on hypernetworks, a variant of meta-learning ("learning to learn") in which a neural network learns to change its own weights in response to an input. In our case, the weights responsible for destination prediction vary with the metadata, in particular the time, of the input trajectory. The time-conditioned weights notably improve the model's error relative to ablation studies and comparable prior work, and we confirm our hypothesis that knowledge of time should improve prediction of a vehicle's intended destination.
VALHALLA: Visual Hallucination for Machine Translation
May 31, 2022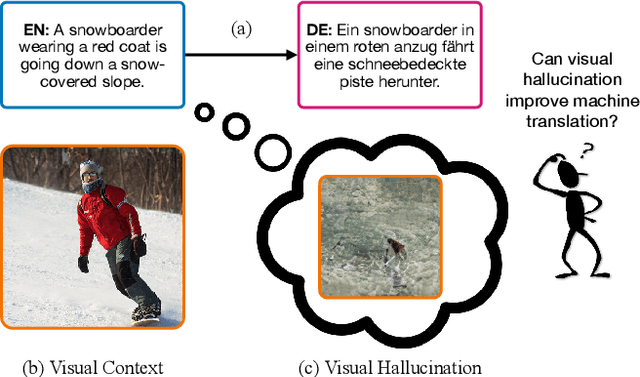
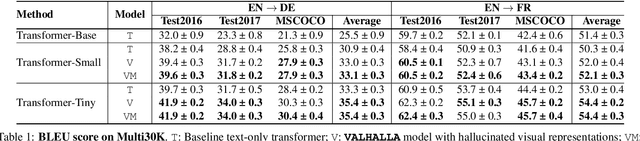
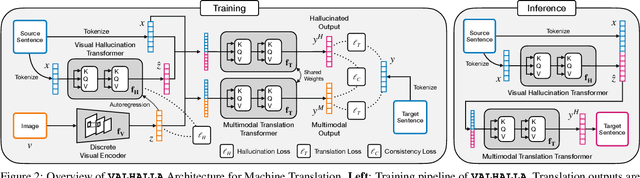
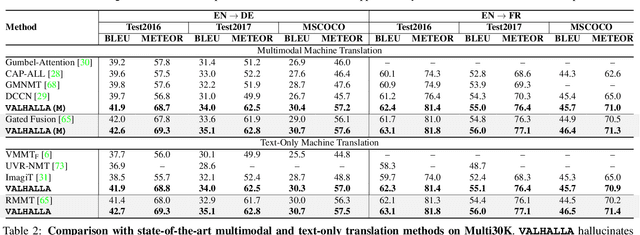
Designing better machine translation systems by considering auxiliary inputs such as images has attracted much attention in recent years. While existing methods show promising performance over the conventional text-only translation systems, they typically require paired text and image as input during inference, which limits their applicability to real-world scenarios. In this paper, we introduce a visual hallucination framework, called VALHALLA, which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. In particular, given a source sentence an autoregressive hallucination transformer is used to predict a discrete visual representation from the input text, and the combined text and hallucinated representations are utilized to obtain the target translation. We train the hallucination transformer jointly with the translation transformer using standard backpropagation with cross-entropy losses while being guided by an additional loss that encourages consistency between predictions using either ground-truth or hallucinated visual representations. Extensive experiments on three standard translation datasets with a diverse set of language pairs demonstrate the effectiveness of our approach over both text-only baselines and state-of-the-art methods. Project page: http://www.svcl.ucsd.edu/projects/valhalla.
Class-Incremental Learning with Strong Pre-trained Models
Apr 07, 2022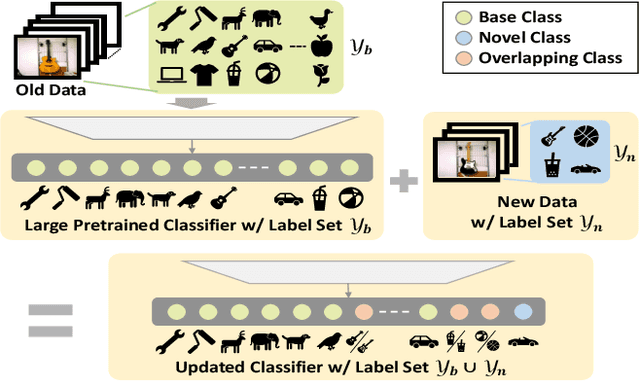
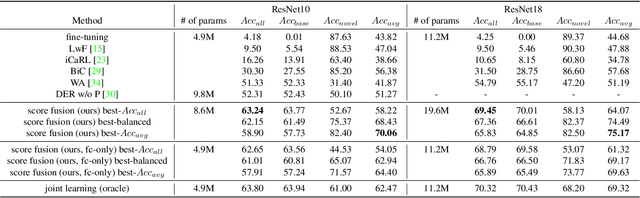
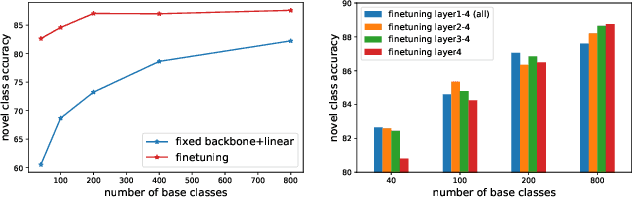
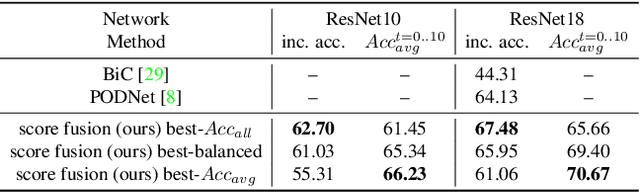
Class-incremental learning (CIL) has been widely studied under the setting of starting from a small number of classes (base classes). Instead, we explore an understudied real-world setting of CIL that starts with a strong model pre-trained on a large number of base classes. We hypothesize that a strong base model can provide a good representation for novel classes and incremental learning can be done with small adaptations. We propose a 2-stage training scheme, i) feature augmentation -- cloning part of the backbone and fine-tuning it on the novel data, and ii) fusion -- combining the base and novel classifiers into a unified classifier. Experiments show that the proposed method significantly outperforms state-of-the-art CIL methods on the large-scale ImageNet dataset (e.g. +10% overall accuracy than the best). We also propose and analyze understudied practical CIL scenarios, such as base-novel overlap with distribution shift. Our proposed method is robust and generalizes to all analyzed CIL settings.
CoordGAN: Self-Supervised Dense Correspondences Emerge from GANs
Mar 30, 2022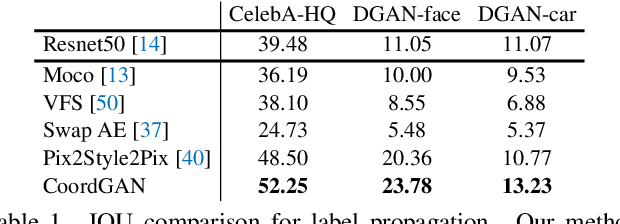
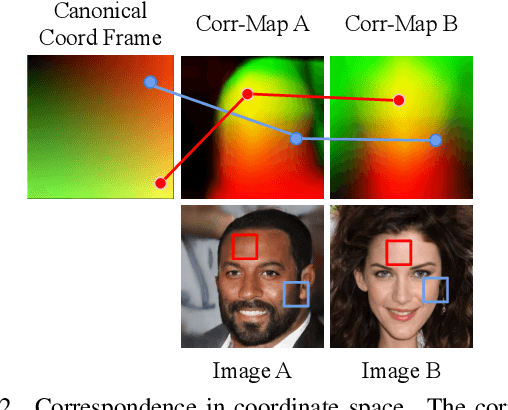
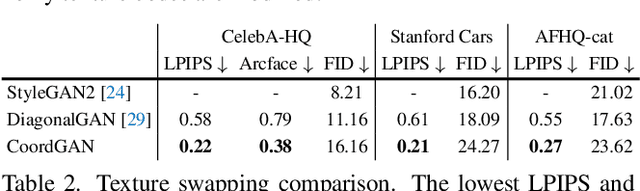
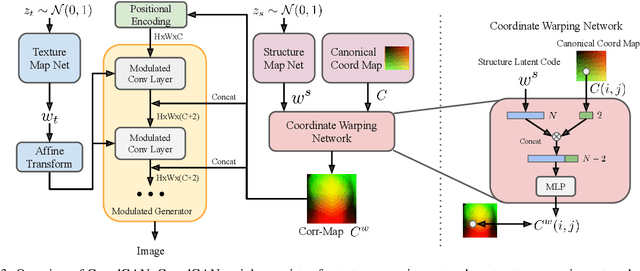
Recent advances show that Generative Adversarial Networks (GANs) can synthesize images with smooth variations along semantically meaningful latent directions, such as pose, expression, layout, etc. While this indicates that GANs implicitly learn pixel-level correspondences across images, few studies explored how to extract them explicitly. In this work, we introduce Coordinate GAN (CoordGAN), a structure-texture disentangled GAN that learns a dense correspondence map for each generated image. We represent the correspondence maps of different images as warped coordinate frames transformed from a canonical coordinate frame, i.e., the correspondence map, which describes the structure (e.g., the shape of a face), is controlled via a transformation. Hence, finding correspondences boils down to locating the same coordinate in different correspondence maps. In CoordGAN, we sample a transformation to represent the structure of a synthesized instance, while an independent texture branch is responsible for rendering appearance details orthogonal to the structure. Our approach can also extract dense correspondence maps for real images by adding an encoder on top of the generator. We quantitatively demonstrate the quality of the learned dense correspondences through segmentation mask transfer on multiple datasets. We also show that the proposed generator achieves better structure and texture disentanglement compared to existing approaches. Project page: https://jitengmu.github.io/CoordGAN/
Omni-DETR: Omni-Supervised Object Detection with Transformers
Mar 30, 2022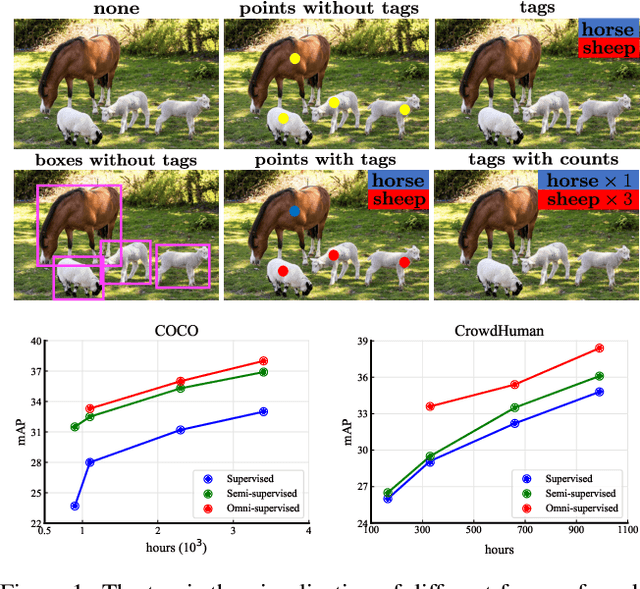


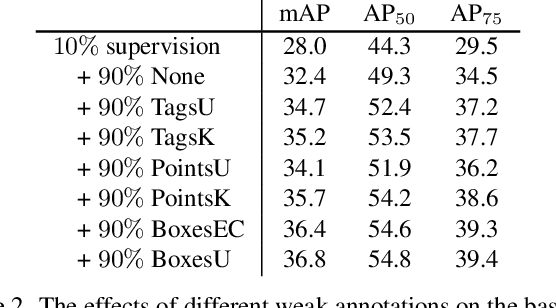
We consider the problem of omni-supervised object detection, which can use unlabeled, fully labeled and weakly labeled annotations, such as image tags, counts, points, etc., for object detection. This is enabled by a unified architecture, Omni-DETR, based on the recent progress on student-teacher framework and end-to-end transformer based object detection. Under this unified architecture, different types of weak labels can be leveraged to generate accurate pseudo labels, by a bipartite matching based filtering mechanism, for the model to learn. In the experiments, Omni-DETR has achieved state-of-the-art results on multiple datasets and settings. And we have found that weak annotations can help to improve detection performance and a mixture of them can achieve a better trade-off between annotation cost and accuracy than the standard complete annotation. These findings could encourage larger object detection datasets with mixture annotations. The code is available at https://github.com/amazon-research/omni-detr.
BEV-Net: Assessing Social Distancing Compliance by Joint People Localization and Geometric Reasoning
Oct 12, 2021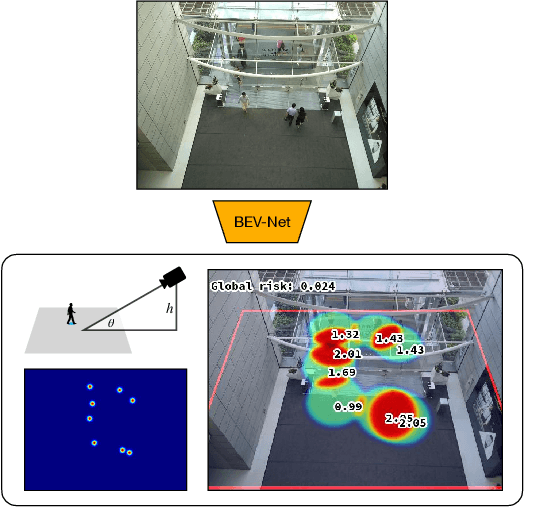
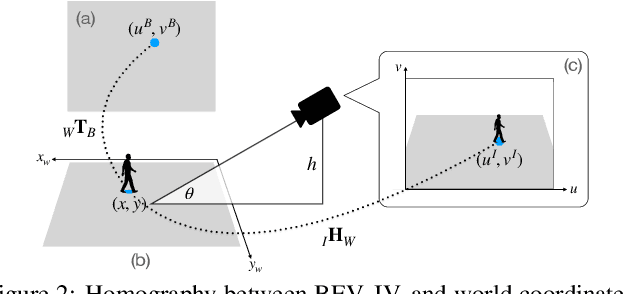

Social distancing, an essential public health measure to limit the spread of contagious diseases, has gained significant attention since the outbreak of the COVID-19 pandemic. In this work, the problem of visual social distancing compliance assessment in busy public areas, with wide field-of-view cameras, is considered. A dataset of crowd scenes with people annotations under a bird's eye view (BEV) and ground truth for metric distances is introduced, and several measures for the evaluation of social distance detection systems are proposed. A multi-branch network, BEV-Net, is proposed to localize individuals in world coordinates and identify high-risk regions where social distancing is violated. BEV-Net combines detection of head and feet locations, camera pose estimation, a differentiable homography module to map image into BEV coordinates, and geometric reasoning to produce a BEV map of the people locations in the scene. Experiments on complex crowded scenes demonstrate the power of the approach and show superior performance over baselines derived from methods in the literature. Applications of interest for public health decision makers are finally discussed. Datasets, code and pretrained models are publicly available at GitHub.