 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation
Jun 28, 2020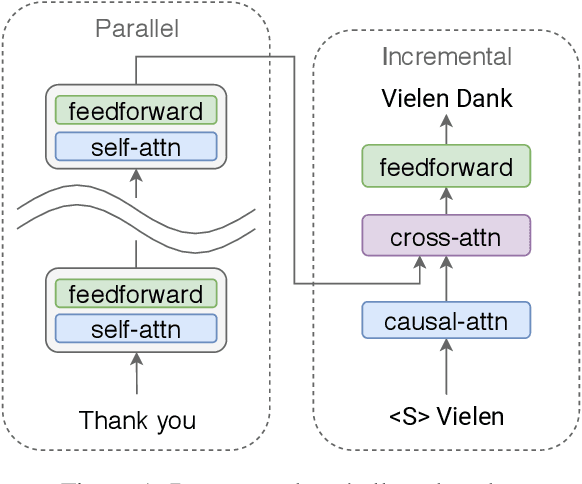

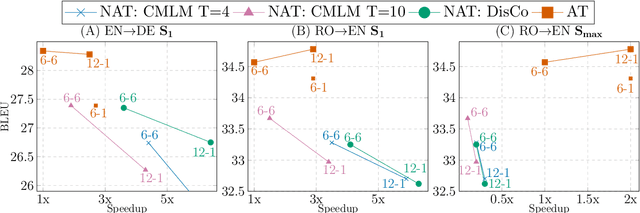
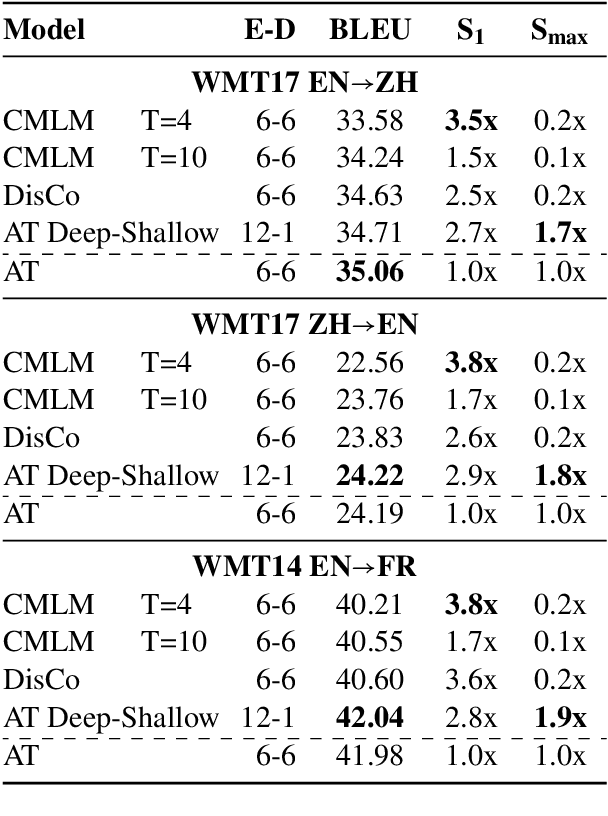
State-of-the-art neural machine translation models generate outputs autoregressively, where every step conditions on the previously generated tokens. This sequential nature causes inherent decoding latency. Non-autoregressive translation techniques, on the other hand, parallelize generation across positions and speed up inference at the expense of translation quality. Much recent effort has been devoted to non-autoregressive methods, aiming for a better balance between speed and quality. In this work, we re-examine the trade-off and argue that transformer-based autoregressive models can be substantially sped up without loss in accuracy. Specifically, we study autoregressive models with encoders and decoders of varied depths. Our extensive experiments show that given a sufficiently deep encoder, a one-layer autoregressive decoder yields state-of-the-art accuracy with comparable latency to strong non-autoregressive models. Our findings suggest that the latency disadvantage for autoregressive translation has been overestimated due to a suboptimal choice of layer allocation, and we provide a new speed-quality baseline for future research toward fast, accurate translation.
A Mixture of $h-1$ Heads is Better than $h$ Heads
May 13, 2020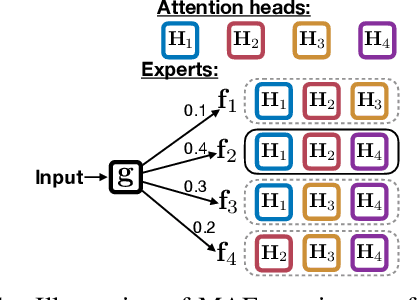

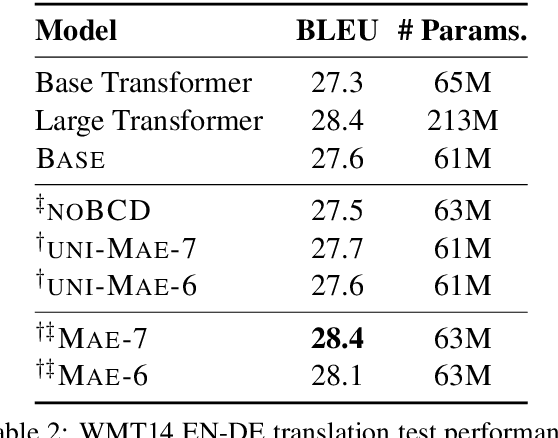
Multi-head attentive neural architectures have achieved state-of-the-art results on a variety of natural language processing tasks. Evidence has shown that they are overparameterized; attention heads can be pruned without significant performance loss. In this work, we instead "reallocate" them -- the model learns to activate different heads on different inputs. Drawing connections between multi-head attention and mixture of experts, we propose the mixture of attentive experts model (MAE). MAE is trained using a block coordinate descent algorithm that alternates between updating (1) the responsibilities of the experts and (2) their parameters. Experiments on machine translation and language modeling show that MAE outperforms strong baselines on both tasks. Particularly, on the WMT14 English to German translation dataset, MAE improves over "transformer-base" by 0.8 BLEU, with a comparable number of parameters. Our analysis shows that our model learns to specialize different experts to different inputs.
The Right Tool for the Job: Matching Model and Instance Complexities
May 09, 2020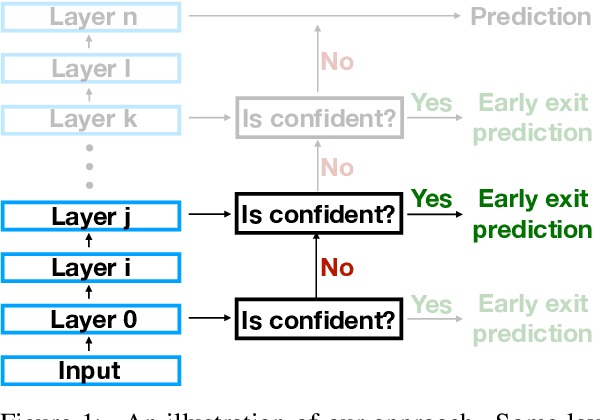
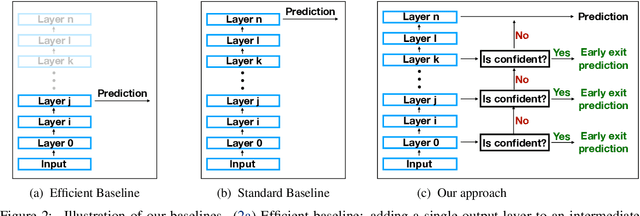
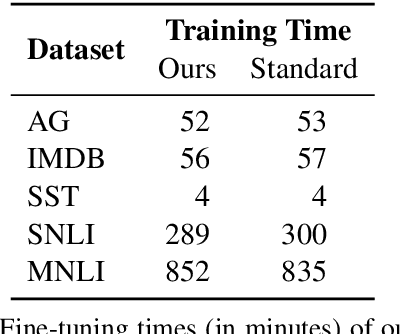
As NLP models become larger, executing a trained model requires significant computational resources incurring monetary and environmental costs. To better respect a given inference budget, we propose a modification to contextual representation fine-tuning which, during inference, allows for an early (and fast) "exit" from neural network calculations for simple instances, and late (and accurate) exit for hard instances. To achieve this, we add classifiers to different layers of BERT and use their calibrated confidence scores to make early exit decisions. We test our proposed modification on five different datasets in two tasks: three text classification datasets and two natural language inference benchmarks. Our method presents a favorable speed/accuracy tradeoff in almost all cases, producing models which are up to five times faster than the state of the art, while preserving their accuracy. Our method also requires almost no additional training resources (in either time or parameters) compared to the baseline BERT model. Finally, our method alleviates the need for costly retraining of multiple models at different levels of efficiency; we allow users to control the inference speed/accuracy tradeoff using a single trained model, by setting a single variable at inference time. We publicly release our code.
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
May 05, 2020

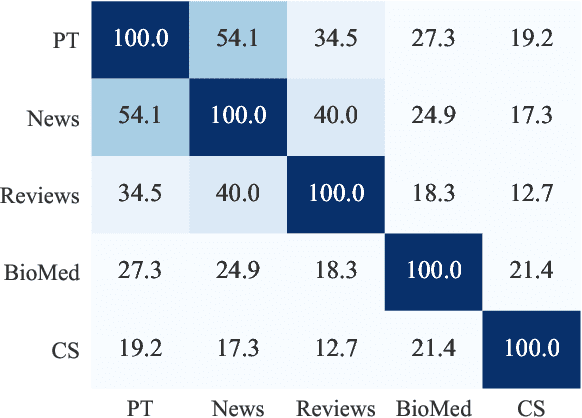
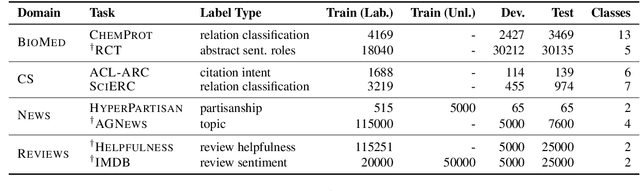
Language models pretrained on text from a wide variety of sources form the foundation of today's NLP. In light of the success of these broad-coverage models, we investigate whether it is still helpful to tailor a pretrained model to the domain of a target task. We present a study across four domains (biomedical and computer science publications, news, and reviews) and eight classification tasks, showing that a second phase of pretraining in-domain (domain-adaptive pretraining) leads to performance gains, under both high- and low-resource settings. Moreover, adapting to the task's unlabeled data (task-adaptive pretraining) improves performance even after domain-adaptive pretraining. Finally, we show that adapting to a task corpus augmented using simple data selection strategies is an effective alternative, especially when resources for domain-adaptive pretraining might be unavailable. Overall, we consistently find that multi-phase adaptive pretraining offers large gains in task performance.
A Formal Hierarchy of RNN Architectures
Apr 24, 2020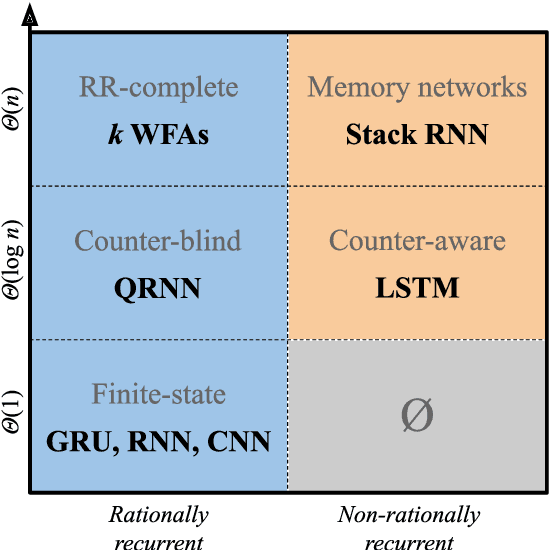
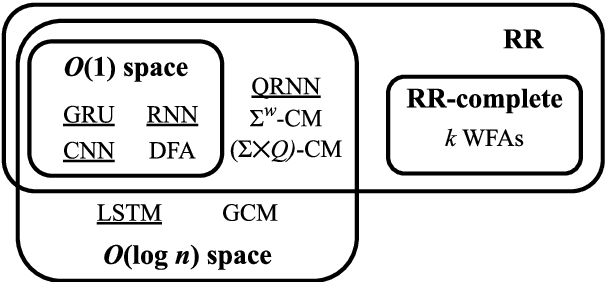
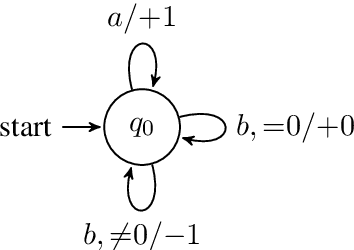
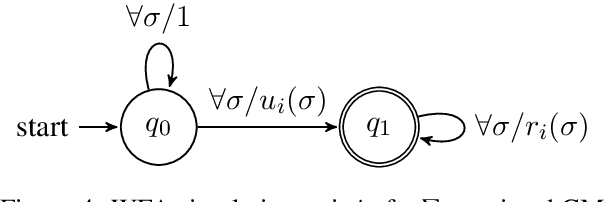
We develop a formal hierarchy of the expressive capacity of RNN architectures. The hierarchy is based on two formal properties: space complexity, which measures the RNN's memory, and rational recurrence, defined as whether the recurrent update can be described by a weighted finite-state machine. We place several RNN variants within this hierarchy. For example, we prove the LSTM is not rational, which formally separates it from the related QRNN (Bradbury et al., 2016). We also show how these models' expressive capacity is expanded by stacking multiple layers or composing them with different pooling functions. Our results build on the theory of "saturated" RNNs (Merrill, 2019). While formally extending these findings to unsaturated RNNs is left to future work, we hypothesize that the practical learnable capacity of unsaturated RNNs obeys a similar hierarchy. Experimental findings from training unsaturated networks on formal languages support this conjecture.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
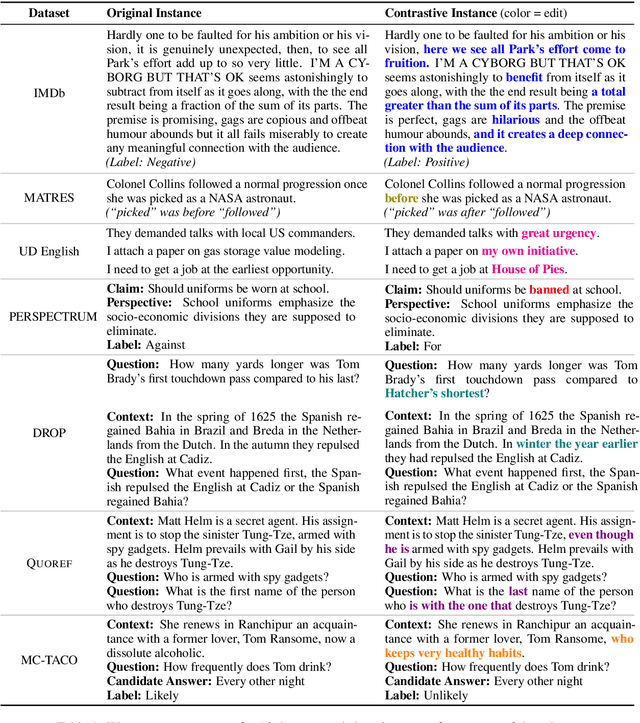
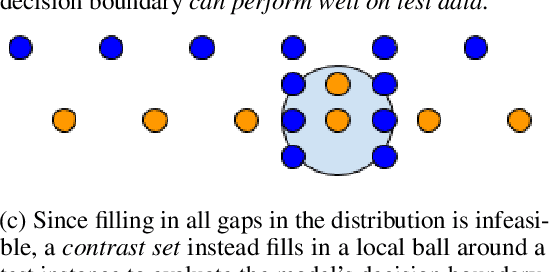
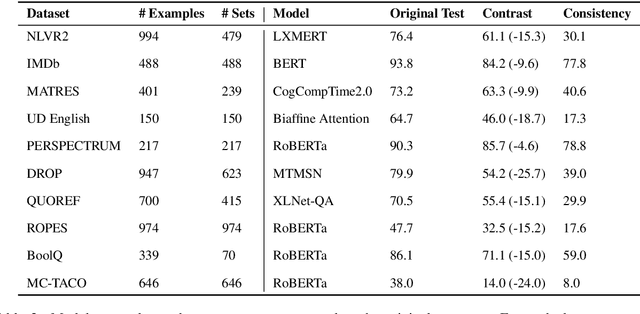
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Multi-View Learning for Vision-and-Language Navigation
Mar 09, 2020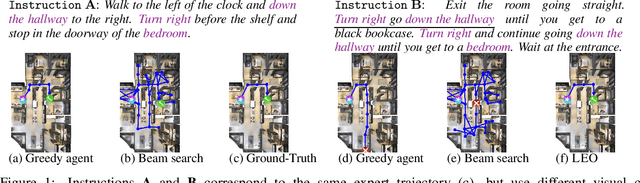
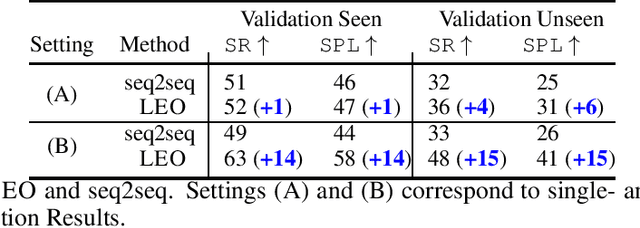
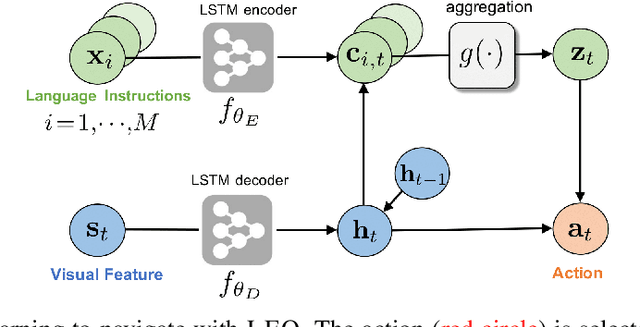
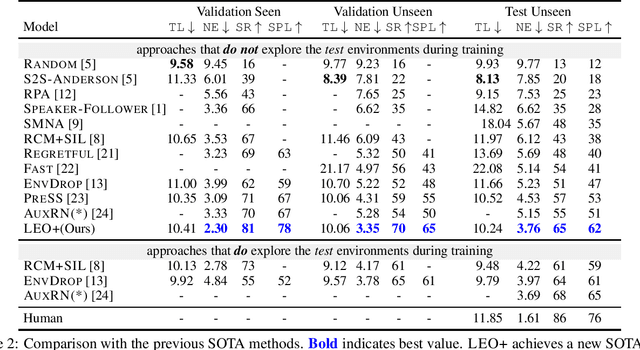
Learning to navigate in a visual environment following natural language instructions is a challenging task because natural language instructions are highly variable, ambiguous, and under-specified. In this paper, we present a novel training paradigm, Learn from EveryOne (LEO), which leverages multiple instructions (as different views) for the same trajectory to resolve language ambiguity and improve generalization. By sharing parameters across instructions, our approach learns more effectively from limited training data and generalizes better in unseen environments. On the recent Room-to-Room (R2R) benchmark dataset, LEO achieves 16% improvement (absolute) over a greedy agent as the base agent (25.3% $\rightarrow$ 41.4%) in Success Rate weighted by Path Length (SPL). Further, LEO is complementary to most existing models for vision-and-language navigation, allowing for easy integration with the existing techniques, leading to LEO+, which creates the new state of the art, pushing the R2R benchmark to 62% (9% absolute improvement).
Citation Text Generation
Feb 02, 2020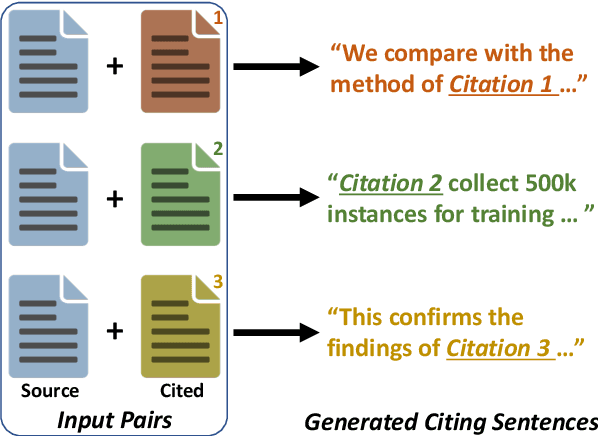
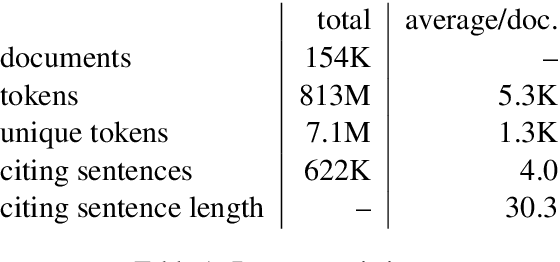
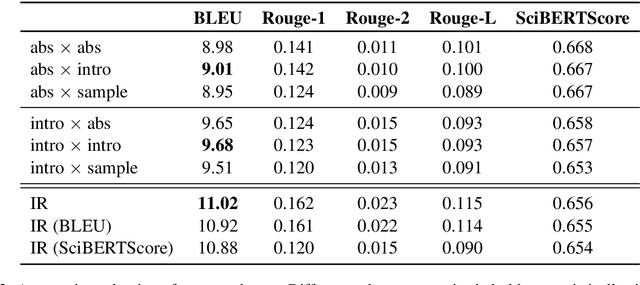
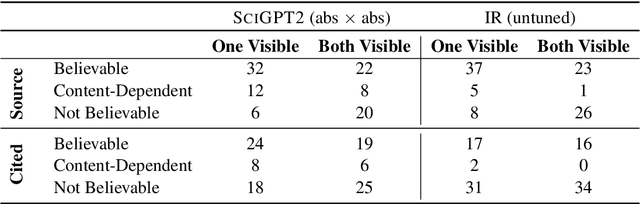
We introduce the task of citation text generation: given a pair of scientific documents, explain their relationship in natural language text in the manner of a citation from one text to the other. This task encourages systems to learn rich relationships between scientific texts and to express them concretely in natural language. Models for citation text generation will require robust document understanding including the capacity to quickly adapt to new vocabulary and to reason about document content. We believe this challenging direction of research will benefit high-impact applications such as automatic literature review or scientific writing assistance systems. In this paper we establish the task of citation text generation with a standard evaluation corpus and explore several baseline models.
On Consequentialism and Fairness
Jan 02, 2020Recent work on fairness in machine learning has primarily emphasized how to define, quantify, and encourage "fair" outcomes. Less attention has been paid, however, to the ethical foundations which underlie such efforts. Among the ethical perspectives that should be taken into consideration is consequentialism, the position that, roughly speaking, outcomes are all that matter. Although consequentialism is not free from difficulties, and although it does not necessarily provide a tractable way of choosing actions (because of the combined problems of uncertainty, subjectivity, and aggregation), it nevertheless provides a powerful foundation from which to critique the existing literature on machine learning fairness. Moreover, it brings to the fore some of the tradeoffs involved, including the problem of who counts, the pros and cons of using a policy, and the relative value of the distant future. In this paper we provide a consequentialist critique of common definitions of fairness within machine learning, as well as a machine learning perspective on consequentialism. We conclude with a broader discussion of the issues of learning and randomization, which have important implications for the ethics of automated decision making systems.
Social Bias Frames: Reasoning about Social and Power Implications of Language
Nov 10, 2019
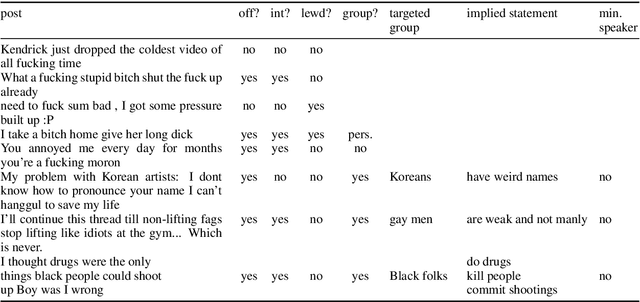
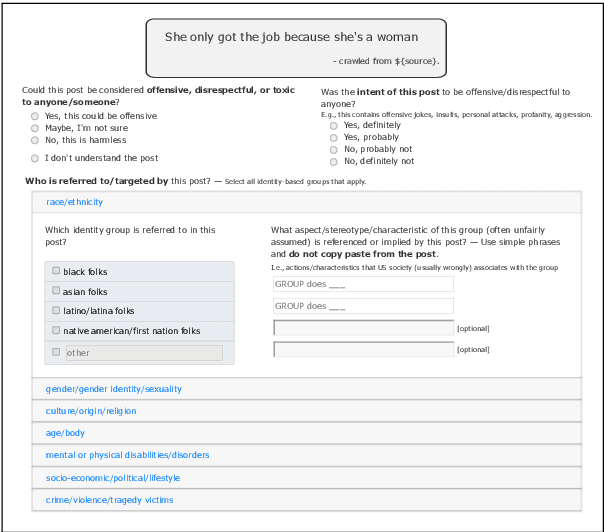
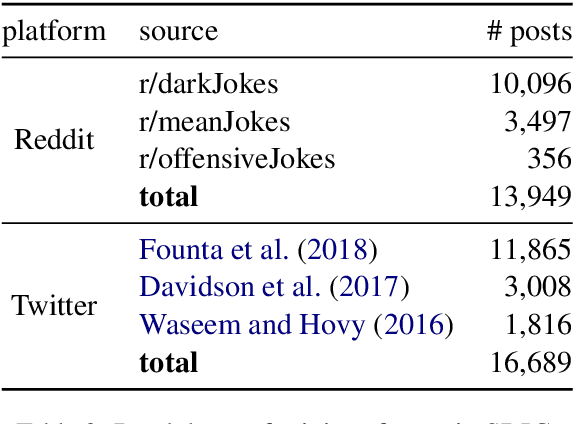
Language has the power to reinforce stereotypes and project social biases onto others. At the core of the challenge is that it is rarely what is stated explicitly, but all the implied meanings that frame people's judgements about others. For example, given a seemingly innocuous statement "we shouldn't lower our standards to hire more women," most listeners will infer the implicature intended by the speaker - that "women (candidates) are less qualified." Most frame semantic formalisms, to date, do not capture such pragmatic frames in which people express social biases and power differentials in language. We introduce Social Bias Frames, a new conceptual formalism that aims to model the pragmatic frames in which people project social biases and stereotypes on others. In addition, we introduce the Social Bias Inference Corpus, to support large-scale modelling and evaluation with 100k structured annotations of social media posts, covering over 26k implications about a thousand demographic groups. We then establish baseline approaches that learn to recover Social Bias Frames from unstructured text. We find that while state-of-the-art neural models are effective at high-level categorization of whether a given statement projects unwanted social bias (86% F1), they are not effective at spelling out more detailed explanations by accurately decoding out Social Bias Frames. Our study motivates future research that combines structured pragmatic inference with commonsense reasoning on social implications.