 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning
Jul 08, 2025Long-context reasoning requires accurately identifying relevant information in extensive, noisy input contexts. Previous research shows that using test-time learning to encode context directly into model parameters can effectively enable reasoning over noisy information. However, meta-learning methods for enabling test-time learning are prohibitively memory-intensive, preventing their application to long context settings. In this work, we propose PERK (Parameter Efficient Reasoning over Knowledge), a scalable approach for learning to encode long input contexts using gradient updates to a lightweight model adapter at test time. Specifically, PERK employs two nested optimization loops in a meta-training phase. The inner loop rapidly encodes contexts into a low-rank adapter (LoRA) that serves as a parameter-efficient memory module for the base model. Concurrently, the outer loop learns to use the updated adapter to accurately recall and reason over relevant information from the encoded long context. Our evaluations on several long-context reasoning tasks show that PERK significantly outperforms the standard prompt-based long-context baseline, achieving average absolute performance gains of up to 90% for smaller models (GPT-2) and up to 27% for our largest evaluated model, Qwen-2.5-0.5B. In general, PERK is more robust to reasoning complexity, length extrapolation, and the locations of relevant information in contexts. Finally, we show that while PERK is memory-intensive during training, it scales more efficiently at inference time than prompt-based long-context inference.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Improving Autoformalization using Type Checking
Jun 11, 2024



Large language models show promise for autoformalization, the task of automatically translating natural language into formal languages. However, current autoformalization methods remain limited. The last reported state-of-the-art performance on the ProofNet formalization benchmark for the Lean proof assistant, achieved using Codex for Lean 3, only showed successful formalization of 16.1% of informal statements. Similarly, our evaluation of GPT-4o for Lean 4 only produces successful translations 34.9% of the time. Our analysis shows that the performance of these models is largely limited by their inability to generate formal statements that successfully type-check (i.e., are syntactically correct and consistent with types) - with a whopping 86.6% of GPT-4o errors starting from a type-check failure. In this work, we propose a method to fix this issue through decoding with type-check filtering, where we initially sample a diverse set of candidate formalizations for an informal statement, then use the Lean proof assistant to filter out candidates that do not type-check. Using GPT-4o as a base model, and combining our method with self-consistency, we obtain a +18.3% absolute increase in formalization accuracy, and achieve a new state-of-the-art of 53.2% on ProofNet with Lean 4.
Transformers as Recognizers of Formal Languages: A Survey on Expressivity
Nov 01, 2023As transformers have gained prominence in natural language processing, some researchers have investigated theoretically what problems they can and cannot solve, by treating problems as formal languages. Exploring questions such as this will help to compare transformers with other models, and transformer variants with one another, for various tasks. Work in this subarea has made considerable progress in recent years. Here, we undertake a comprehensive survey of this work, documenting the diverse assumptions that underlie different results and providing a unified framework for harmonizing seemingly contradictory findings.
Discovering Knowledge-Critical Subnetworks in Pretrained Language Models
Oct 04, 2023



Pretrained language models (LMs) encode implicit representations of knowledge in their parameters. However, localizing these representations and disentangling them from each other remains an open problem. In this work, we investigate whether pretrained language models contain various knowledge-critical subnetworks: particular sparse computational subgraphs responsible for encoding specific knowledge the model has memorized. We propose a multi-objective differentiable weight masking scheme to discover these subnetworks and show that we can use them to precisely remove specific knowledge from models while minimizing adverse effects on the behavior of the original language model. We demonstrate our method on multiple GPT2 variants, uncovering highly sparse subnetworks (98%+) that are solely responsible for specific collections of relational knowledge. When these subnetworks are removed, the remaining network maintains most of its initial capacity (modeling language and other memorized relational knowledge) but struggles to express the removed knowledge, and suffers performance drops on examples needing this removed knowledge on downstream tasks after finetuning.
RECKONING: Reasoning through Dynamic Knowledge Encoding
May 23, 2023



Recent studies on transformer-based language models show that they can answer questions by reasoning over knowledge provided as part of the context (i.e., in-context reasoning). However, since the available knowledge is often not filtered for a particular question, in-context reasoning can be sensitive to distractor facts, additional content that is irrelevant to a question but that may be relevant for a different question (i.e., not necessarily random noise). In these situations, the model fails to distinguish the knowledge that is necessary to answer the question, leading to spurious reasoning and degraded performance. This reasoning failure contrasts with the model's apparent ability to distinguish its contextual knowledge from all the knowledge it has memorized during pre-training. Following this observation, we propose teaching the model to reason more robustly by folding the provided contextual knowledge into the model's parameters before presenting it with a question. Our method, RECKONING, is a bi-level learning algorithm that teaches language models to reason by updating their parametric knowledge through back-propagation, allowing them to then answer questions using the updated parameters. During training, the inner loop rapidly adapts a copy of the model weights to encode contextual knowledge into its parameters. In the outer loop, the model learns to use the updated weights to reproduce and answer reasoning questions about the memorized knowledge. Our experiments on two multi-hop reasoning datasets show that RECKONING's performance improves over the in-context reasoning baseline (by up to 4.5%). We also find that compared to in-context reasoning, RECKONING generalizes better to longer reasoning chains unseen during training, is more robust to distractors in the context, and is more computationally efficient when multiple questions are asked about the same knowledge.
Thinking Like Transformers
Jun 13, 2021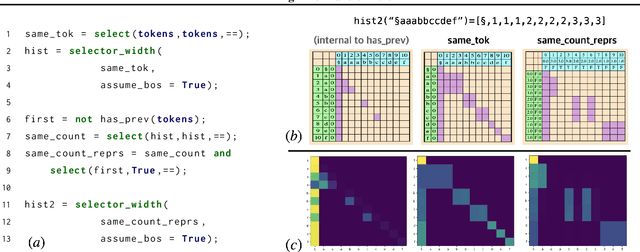
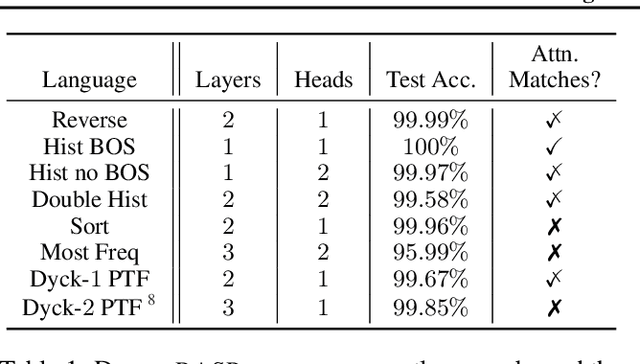
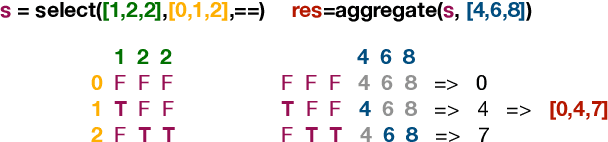
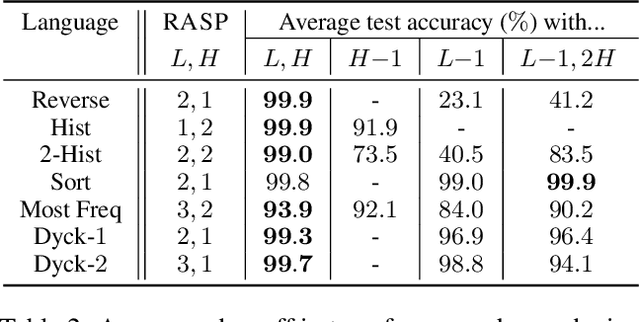
What is the computational model behind a Transformer? Where recurrent neural networks have direct parallels in finite state machines, allowing clear discussion and thought around architecture variants or trained models, Transformers have no such familiar parallel. In this paper we aim to change that, proposing a computational model for the transformer-encoder in the form of a programming language. We map the basic components of a transformer-encoder -- attention and feed-forward computation -- into simple primitives, around which we form a programming language: the Restricted Access Sequence Processing Language (RASP). We show how RASP can be used to program solutions to tasks that could conceivably be learned by a Transformer, and how a Transformer can be trained to mimic a RASP solution. In particular, we provide RASP programs for histograms, sorting, and Dyck-languages. We further use our model to relate their difficulty in terms of the number of required layers and attention heads: analyzing a RASP program implies a maximum number of heads and layers necessary to encode a task in a transformer. Finally, we see how insights gained from our abstraction might be used to explain phenomena seen in recent works.
Synthesizing Context-free Grammars from Recurrent Neural Networks (Extended Version)
Feb 09, 2021
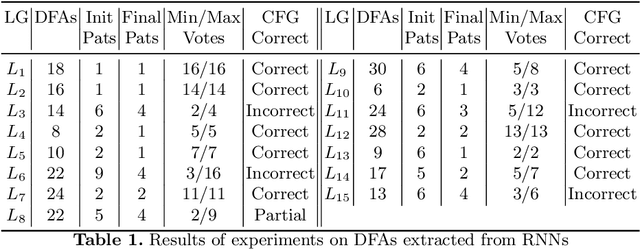
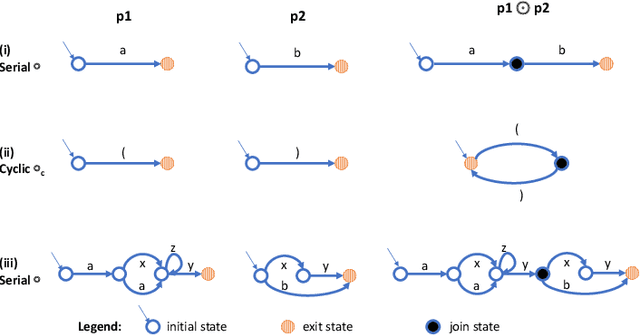
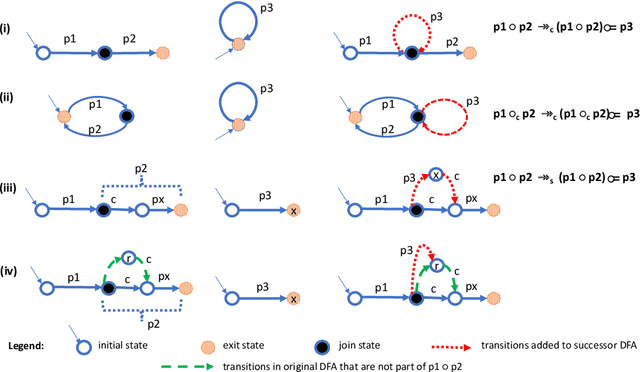
We present an algorithm for extracting a subclass of the context free grammars (CFGs) from a trained recurrent neural network (RNN). We develop a new framework, pattern rule sets (PRSs), which describe sequences of deterministic finite automata (DFAs) that approximate a non-regular language. We present an algorithm for recovering the PRS behind a sequence of such automata, and apply it to the sequences of automata extracted from trained RNNs using the L* algorithm. We then show how the PRS may converted into a CFG, enabling a familiar and useful presentation of the learned language. Extracting the learned language of an RNN is important to facilitate understanding of the RNN and to verify its correctness. Furthermore, the extracted CFG can augment the RNN in classifying correct sentences, as the RNN's predictive accuracy decreases when the recursion depth and distance between matching delimiters of its input sequences increases.
A Formal Hierarchy of RNN Architectures
Apr 24, 2020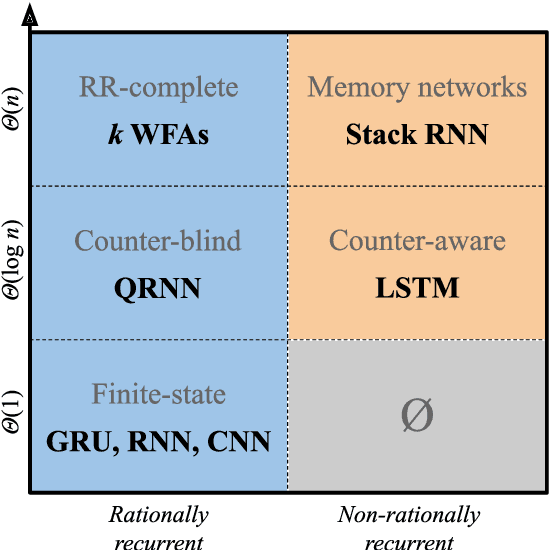
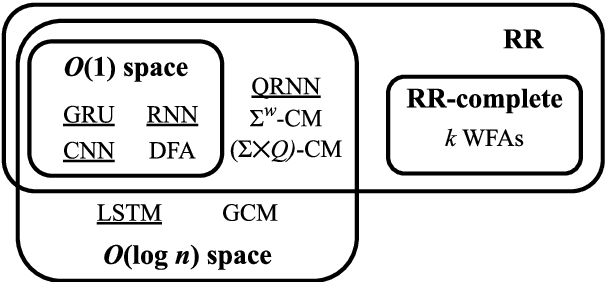
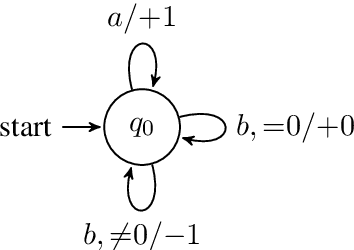
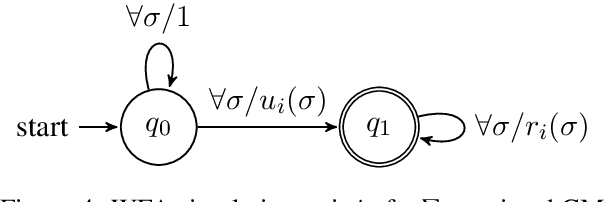
We develop a formal hierarchy of the expressive capacity of RNN architectures. The hierarchy is based on two formal properties: space complexity, which measures the RNN's memory, and rational recurrence, defined as whether the recurrent update can be described by a weighted finite-state machine. We place several RNN variants within this hierarchy. For example, we prove the LSTM is not rational, which formally separates it from the related QRNN (Bradbury et al., 2016). We also show how these models' expressive capacity is expanded by stacking multiple layers or composing them with different pooling functions. Our results build on the theory of "saturated" RNNs (Merrill, 2019). While formally extending these findings to unsaturated RNNs is left to future work, we hypothesize that the practical learnable capacity of unsaturated RNNs obeys a similar hierarchy. Experimental findings from training unsaturated networks on formal languages support this conjecture.
Learning Deterministic Weighted Automata with Queries and Counterexamples
Oct 30, 2019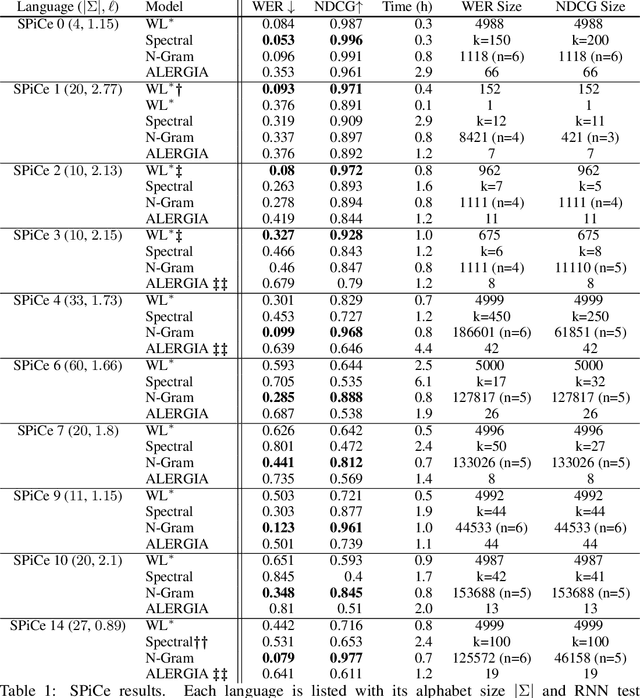
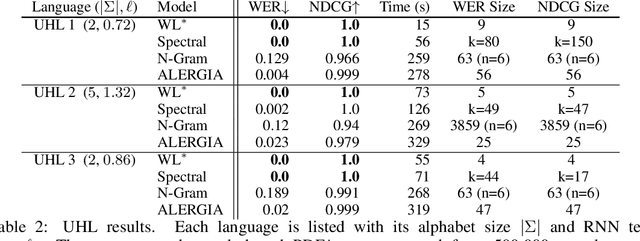
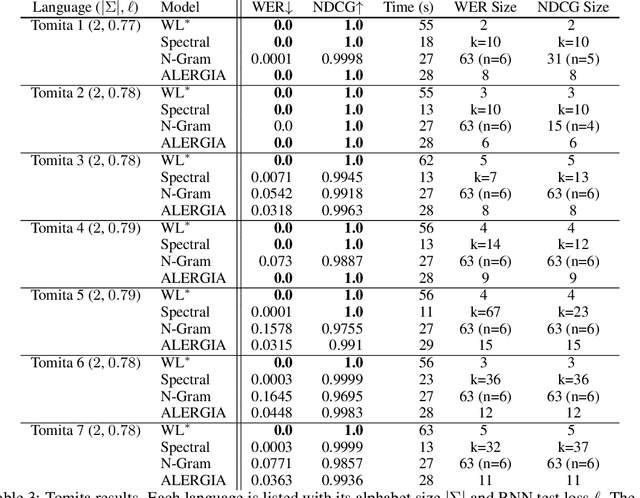
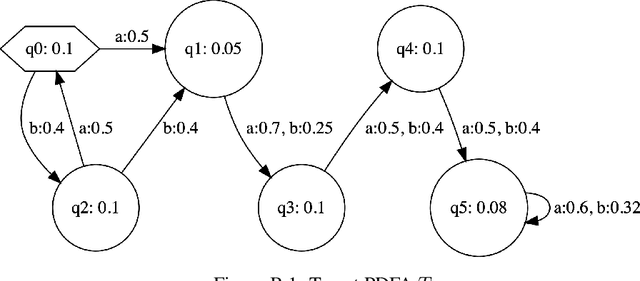
We present an algorithm for extraction of a probabilistic deterministic finite automaton (PDFA) from a given black-box language model, such as a recurrent neural network (RNN). The algorithm is a variant of the exact-learning algorithm L*, adapted to a probabilistic setting with noise. The key insight is the use of conditional probabilities for observations, and the introduction of a local tolerance when comparing them. When applied to RNNs, our algorithm often achieves better word error rate (WER) and normalised distributed cumulative gain (NDCG) than that achieved by spectral extraction of weighted finite automata (WFA) from the same networks. PDFAs are substantially more expressive than n-grams, and are guaranteed to be stochastic and deterministic - unlike spectrally extracted WFAs.