 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlined Dense Video Captioning
Apr 08, 2019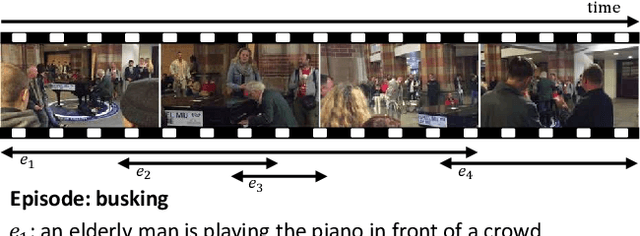

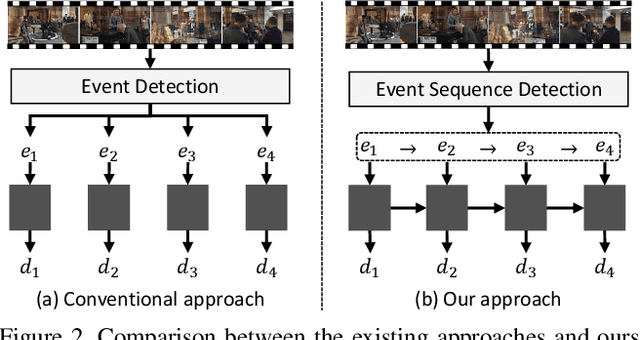
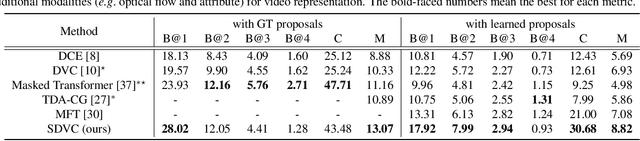
Dense video captioning is an extremely challenging task since accurate and coherent description of events in a video requires holistic understanding of video contents as well as contextual reasoning of individual events. Most existing approaches handle this problem by first detecting event proposals from a video and then captioning on a subset of the proposals. As a result, the generated sentences are prone to be redundant or inconsistent since they fail to consider temporal dependency between events. To tackle this challenge, we propose a novel dense video captioning framework, which models temporal dependency across events in a video explicitly and leverages visual and linguistic context from prior events for coherent storytelling. This objective is achieved by 1) integrating an event sequence generation network to select a sequence of event proposals adaptively, and 2) feeding the sequence of event proposals to our sequential video captioning network, which is trained by reinforcement learning with two-level rewards at both event and episode levels for better context modeling. The proposed technique achieves outstanding performances on ActivityNet Captions dataset in most metrics.
M2KD: Multi-model and Multi-level Knowledge Distillation for Incremental Learning
Apr 03, 2019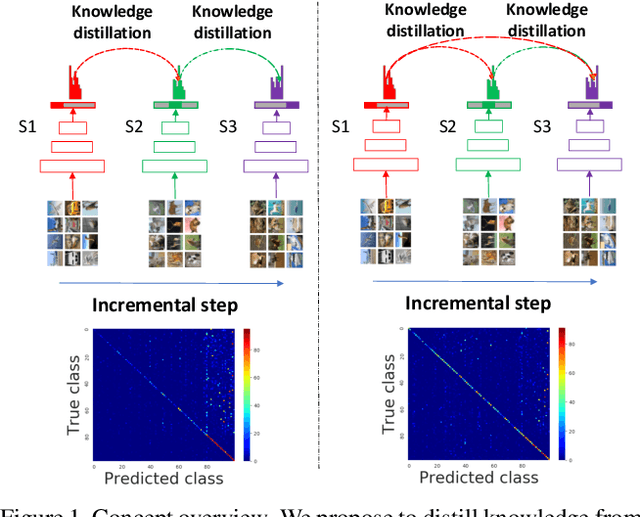
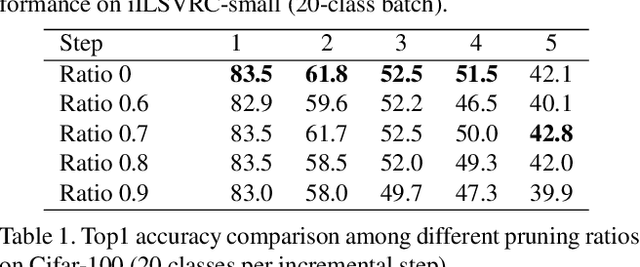
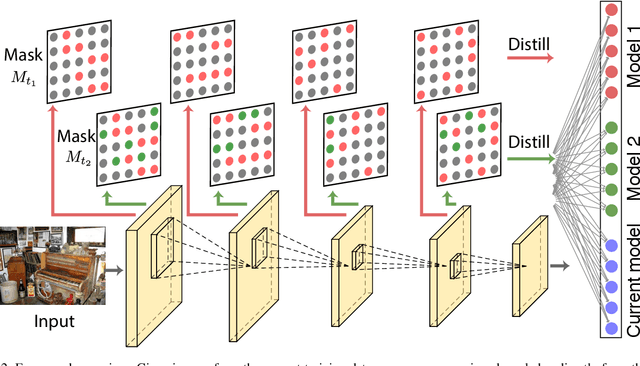

Incremental learning targets at achieving good performance on new categories without forgetting old ones. Knowledge distillation has been shown critical in preserving the performance on old classes. Conventional methods, however, sequentially distill knowledge only from the last model, leading to performance degradation on the old classes in later incremental learning steps. In this paper, we propose a multi-model and multi-level knowledge distillation strategy. Instead of sequentially distilling knowledge only from the last model, we directly leverage all previous model snapshots. In addition, we incorporate an auxiliary distillation to further preserve knowledge encoded at the intermediate feature levels. To make the model more memory efficient, we adapt mask based pruning to reconstruct all previous models with a small memory footprint. Experiments on standard incremental learning benchmarks show that our method preserves the knowledge on old classes better and improves the overall performance over standard distillation techniques.
End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image
Apr 01, 2019

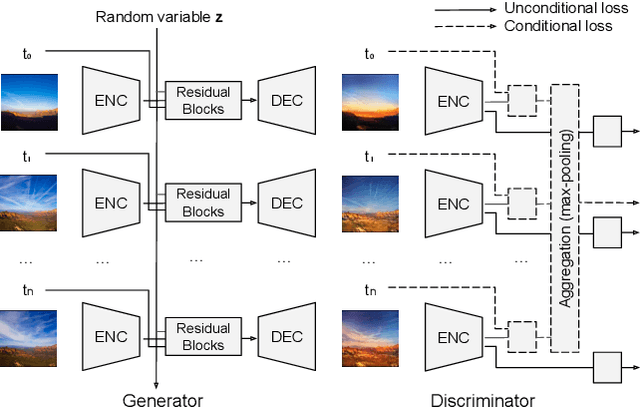
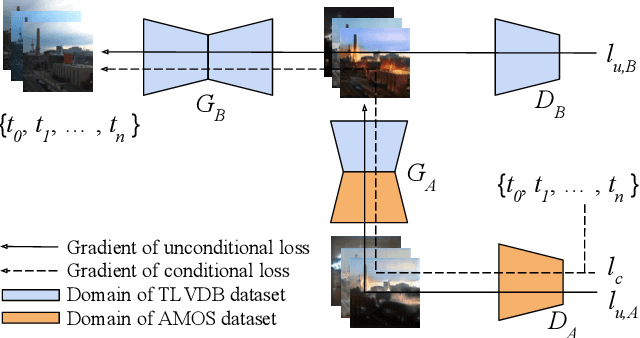
Time-lapse videos usually contain visually appealing content but are often difficult and costly to create. In this paper, we present an end-to-end solution to synthesize a time-lapse video from a single outdoor image using deep neural networks. Our key idea is to train a conditional generative adversarial network based on existing datasets of time-lapse videos and image sequences. We propose a multi-frame joint conditional generation framework to effectively learn the correlation between the illumination change of an outdoor scene and the time of the day. We further present a multi-domain training scheme for robust training of our generative models from two datasets with different distributions and missing timestamp labels. Compared to alternative time-lapse video synthesis algorithms, our method uses the timestamp as the control variable and does not require a reference video to guide the synthesis of the final output. We conduct ablation studies to validate our algorithm and compare with state-of-the-art techniques both qualitatively and quantitatively.
Video Object Segmentation using Space-Time Memory Networks
Apr 01, 2019
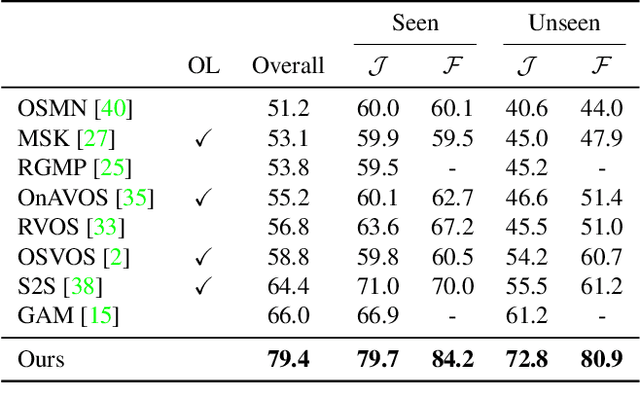
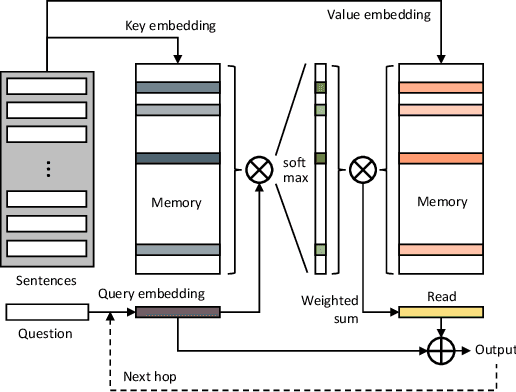
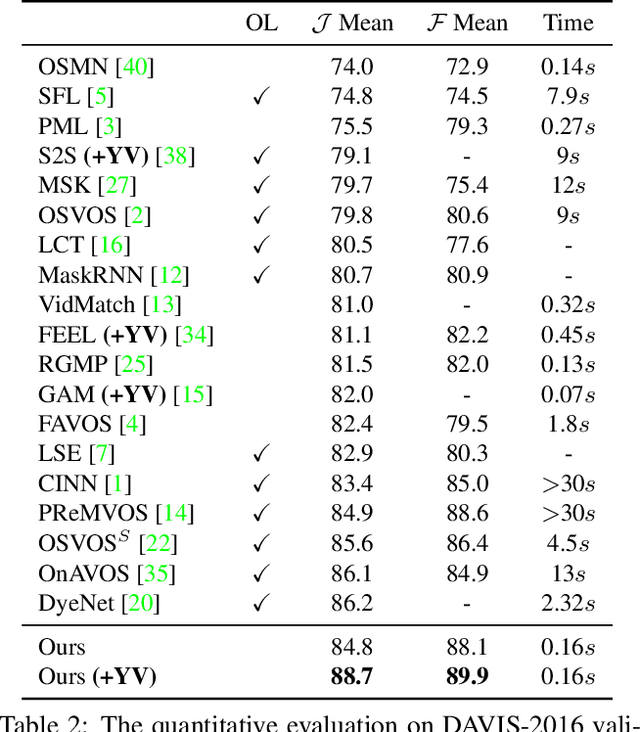
We propose a novel solution for semi-supervised video object segmentation. By the nature of the problem, available cues (e.g. video frame(s) with object masks) become richer with the intermediate predictions. However, the existing methods are unable to fully exploit this rich source of information. We resolve the issue by leveraging memory networks and learn to read relevant information from all available sources. In our framework, the past frames with object masks form an external memory, and the current frame as the query is segmented using the mask information in the memory. Specifically, the query and the memory are densely matched in the feature space, covering all the space-time pixel locations in a feed-forward fashion. Contrast to the previous approaches, the abundant use of the guidance information allows us to better handle the challenges such as appearance changes and occlussions. We validate our method on the latest benchmark sets and achieved the state-of-the-art performance (overall score of 79.4 on Youtube-VOS val set, J of 88.7 and 79.2 on DAVIS 2016/2017 val set respectively) while having a fast runtime (0.16 second/frame on DAVIS 2016 val set).
Singing voice conversion with non-parallel data
Mar 11, 2019

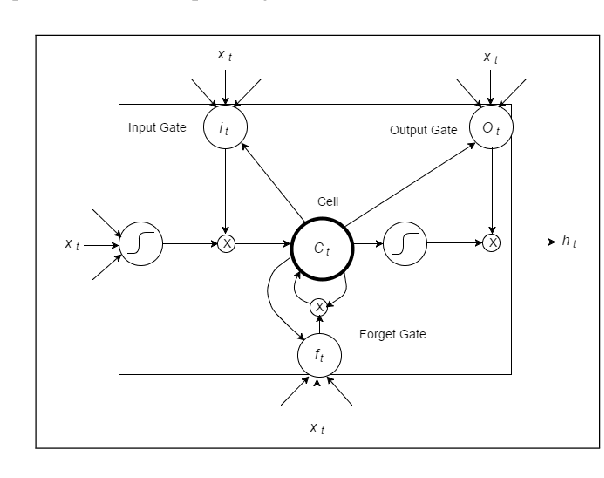
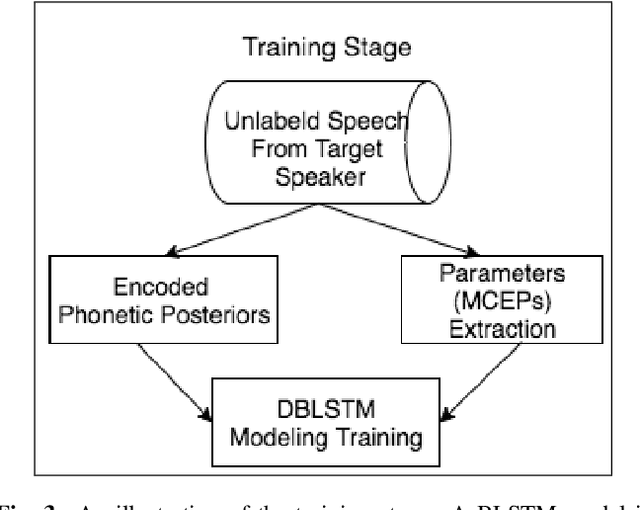
Singing voice conversion is a task to convert a song sang by a source singer to the voice of a target singer. In this paper, we propose using a parallel data free, many-to-one voice conversion technique on singing voices. A phonetic posterior feature is first generated by decoding singing voices through a robust Automatic Speech Recognition Engine (ASR). Then, a trained Recurrent Neural Network (RNN) with a Deep Bidirectional Long Short Term Memory (DBLSTM) structure is used to model the mapping from person-independent content to the acoustic features of the target person. F0 and aperiodic are obtained through the original singing voice, and used with acoustic features to reconstruct the target singing voice through a vocoder. In the obtained singing voice, the targeted and sourced singers sound similar. To our knowledge, this is the first study that uses non parallel data to train a singing voice conversion system. Subjective evaluations demonstrate that the proposed method effectively converts singing voices.
Slimmable Neural Networks
Dec 21, 2018
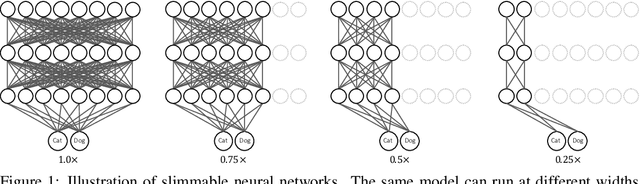

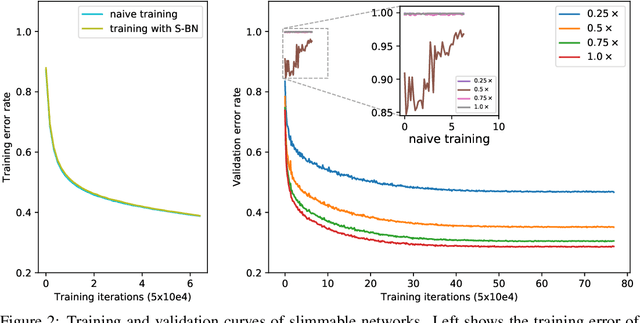
We present a simple and general method to train a single neural network executable at different widths (number of channels in a layer), permitting instant and adaptive accuracy-efficiency trade-offs at runtime. Instead of training individual networks with different width configurations, we train a shared network with switchable batch normalization. At runtime, the network can adjust its width on the fly according to on-device benchmarks and resource constraints, rather than downloading and offloading different models. Our trained networks, named slimmable neural networks, achieve similar (and in many cases better) ImageNet classification accuracy than individually trained models of MobileNet v1, MobileNet v2, ShuffleNet and ResNet-50 at different widths respectively. We also demonstrate better performance of slimmable models compared with individual ones across a wide range of applications including COCO bounding-box object detection, instance segmentation and person keypoint detection without tuning hyper-parameters. Lastly we visualize and discuss the learned features of slimmable networks. Code and models are available at: https://github.com/JiahuiYu/slimmable_networks
Deep neural network based i-vector mapping for speaker verification using short utterances
Oct 16, 2018
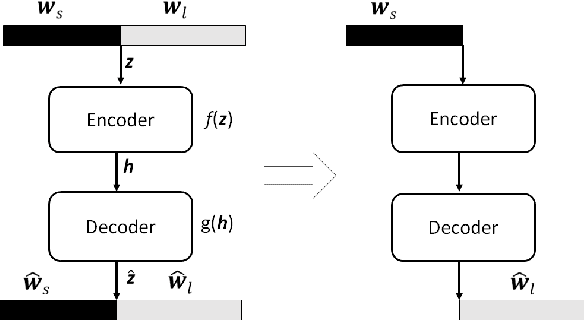

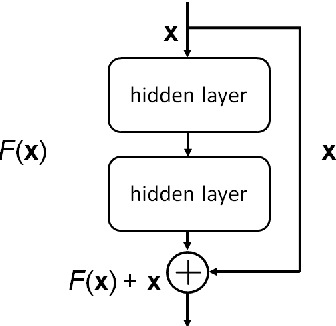
Text-independent speaker recognition using short utterances is a highly challenging task due to the large variation and content mismatch between short utterances. I-vector based systems have become the standard in speaker verification applications, but they are less effective with short utterances. In this paper, we first compare two state-of-the-art universal background model training methods for i-vector modeling using full-length and short utterance evaluation tasks. The two methods are Gaussian mixture model (GMM) based and deep neural network (DNN) based methods. The results indicate that the I-vector_DNN system outperforms the I-vector_GMM system under various durations. However, the performances of both systems degrade significantly as the duration of the utterances decreases. To address this issue, we propose two novel nonlinear mapping methods which train DNN models to map the i-vectors extracted from short utterances to their corresponding long-utterance i-vectors. The mapped i-vector can restore missing information and reduce the variance of the original short-utterance i-vectors. The proposed methods both model the joint representation of short and long utterance i-vectors by using autoencoder. Experimental results using the NIST SRE 2010 dataset show that both methods provide significant improvement and result in a max of 28.43% relative improvement in Equal Error Rates from a baseline system, when using deep encoder with residual blocks and adding an additional phoneme vector. When further testing the best-validated models of SRE10 on the Speaker In The Wild dataset, the methods result in a 23.12% improvement on arbitrary-duration (1-5 s) short-utterance conditions.
YouTube-VOS: A Large-Scale Video Object Segmentation Benchmark
Sep 06, 2018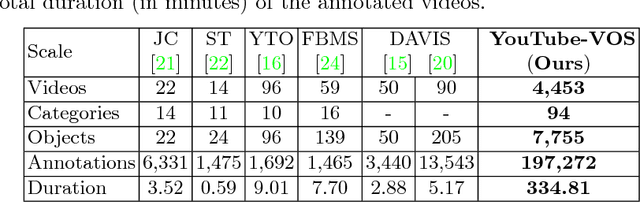

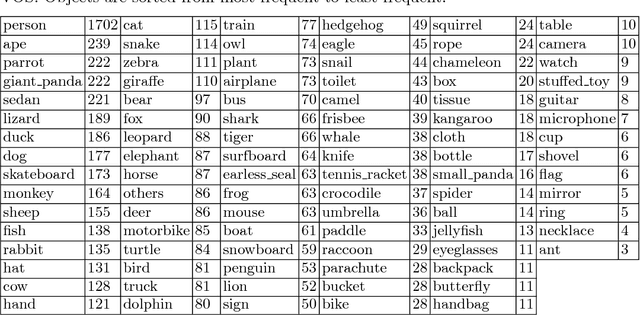
Learning long-term spatial-temporal features are critical for many video analysis tasks. However, existing video segmentation methods predominantly rely on static image segmentation techniques, and methods capturing temporal dependency for segmentation have to depend on pretrained optical flow models, leading to suboptimal solutions for the problem. End-to-end sequential learning to explore spatialtemporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i.e., even the largest video segmentation dataset only contains 90 short video clips. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 4,453 YouTube video clips and 94 object categories. This is by far the largest video object segmentation dataset to our knowledge and has been released at http://youtube-vos.org. We further evaluate several existing state-of-the-art video object segmentation algorithms on this dataset which aims to establish baselines for the development of new algorithms in the future.
YouTube-VOS: Sequence-to-Sequence Video Object Segmentation
Sep 03, 2018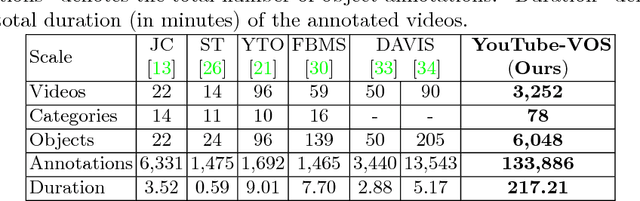

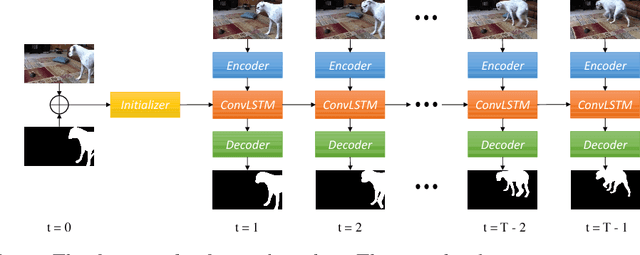
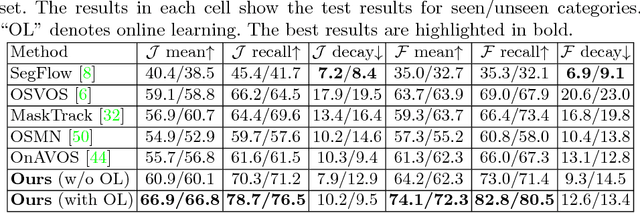
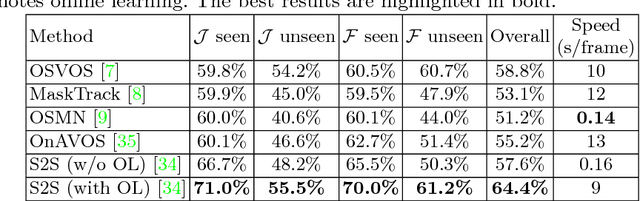
Learning long-term spatial-temporal features are critical for many video analysis tasks. However, existing video segmentation methods predominantly rely on static image segmentation techniques, and methods capturing temporal dependency for segmentation have to depend on pretrained optical flow models, leading to suboptimal solutions for the problem. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i.e., even the largest video segmentation dataset only contains 90 short video clips. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 3,252 YouTube video clips and 78 categories including common objects and human activities. This is by far the largest video object segmentation dataset to our knowledge and we have released it at https://youtube-vos.org. Based on this dataset, we propose a novel sequence-to-sequence network to fully exploit long-term spatial-temporal information in videos for segmentation. We demonstrate that our method is able to achieve the best results on our YouTube-VOS test set and comparable results on DAVIS 2016 compared to the current state-of-the-art methods. Experiments show that the large scale dataset is indeed a key factor to the success of our model.
Wide Activation for Efficient and Accurate Image Super-Resolution
Aug 27, 2018
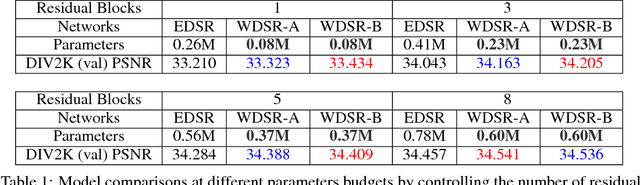

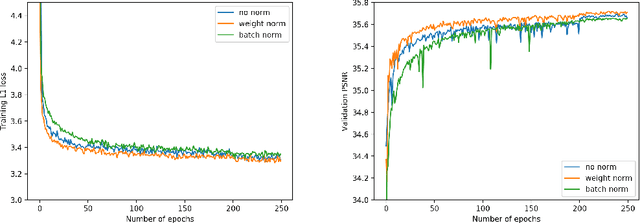
In this report we demonstrate that with same parameters and computational budgets, models with wider features before ReLU activation have significantly better performance for single image super-resolution (SISR). The resulted SR residual network has a slim identity mapping pathway with wider (\(2\times\) to \(4\times\)) channels before activation in each residual block. To further widen activation (\(6\times\) to \(9\times\)) without computational overhead, we introduce linear low-rank convolution into SR networks and achieve even better accuracy-efficiency tradeoffs. In addition, compared with batch normalization or no normalization, we find training with weight normalization leads to better accuracy for deep super-resolution networks. Our proposed SR network \textit{WDSR} achieves better results on large-scale DIV2K image super-resolution benchmark in terms of PSNR with same or lower computational complexity. Based on WDSR, our method also won 1st places in NTIRE 2018 Challenge on Single Image Super-Resolution in all three realistic tracks. Experiments and ablation studies support the importance of wide activation for image super-resolution. Code is released at: https://github.com/JiahuiYu/wdsr_ntire2018