 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generative Vision Transformer with Energy-Based Latent Space for Saliency Prediction
Dec 27, 2021
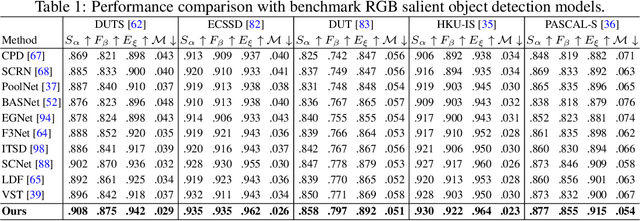

Vision transformer networks have shown superiority in many computer vision tasks. In this paper, we take a step further by proposing a novel generative vision transformer with latent variables following an informative energy-based prior for salient object detection. Both the vision transformer network and the energy-based prior model are jointly trained via Markov chain Monte Carlo-based maximum likelihood estimation, in which the sampling from the intractable posterior and prior distributions of the latent variables are performed by Langevin dynamics. Further, with the generative vision transformer, we can easily obtain a pixel-wise uncertainty map from an image, which indicates the model confidence in predicting saliency from the image. Different from the existing generative models which define the prior distribution of the latent variables as a simple isotropic Gaussian distribution, our model uses an energy-based informative prior which can be more expressive to capture the latent space of the data. We apply the proposed framework to both RGB and RGB-D salient object detection tasks. Extensive experimental results show that our framework can achieve not only accurate saliency predictions but also meaningful uncertainty maps that are consistent with the human perception.
GETAM: Gradient-weighted Element-wise Transformer Attention Map for Weakly-supervised Semantic segmentation
Dec 06, 2021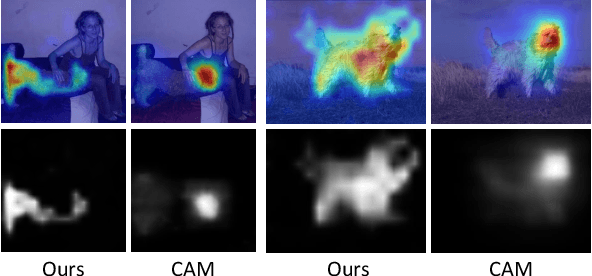
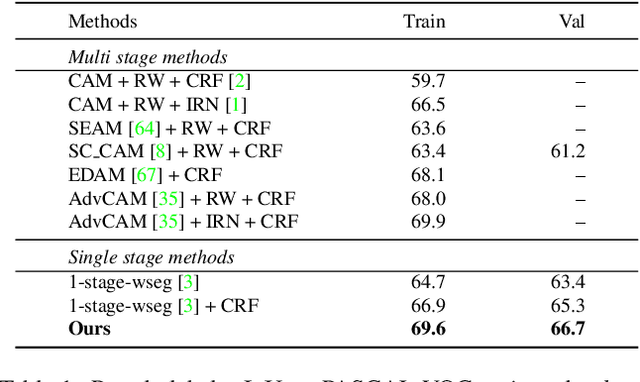

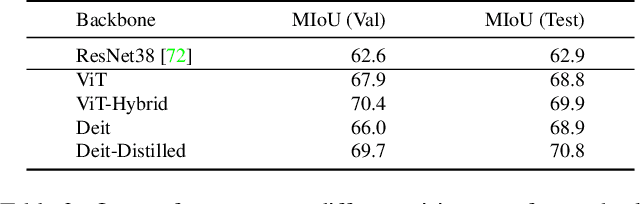
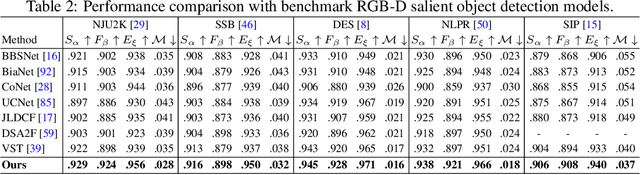
Weakly Supervised Semantic Segmentation (WSSS) is challenging, particularly when image-level labels are used to supervise pixel level prediction. To bridge their gap, a Class Activation Map (CAM) is usually generated to provide pixel level pseudo labels. CAMs in Convolutional Neural Networks suffer from partial activation ie, only the most discriminative regions are activated. Transformer based methods, on the other hand, are highly effective at exploring global context with long range dependency modeling, potentially alleviating the "partial activation" issue. In this paper, we propose the first transformer based WSSS approach, and introduce the Gradient weighted Element wise Transformer Attention Map (GETAM). GETAM shows fine scale activation for all feature map elements, revealing different parts of the object across transformer layers. Further, we propose an activation aware label completion module to generate high quality pseudo labels. Finally, we incorporate our methods into an end to end framework for WSSS using double backward propagation. Extensive experiments on PASCAL VOC and COCO demonstrate that our results beat the state-of-the-art end-to-end approaches by a significant margin, and outperform most multi-stage methods.m most multi-stage methods.
Learning To Segment Dominant Object Motion From Watching Videos
Nov 28, 2021
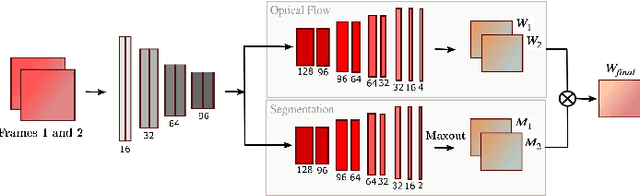

Existing deep learning based unsupervised video object segmentation methods still rely on ground-truth segmentation masks to train. Unsupervised in this context only means that no annotated frames are used during inference. As obtaining ground-truth segmentation masks for real image scenes is a laborious task, we envision a simple framework for dominant moving object segmentation that neither requires annotated data to train nor relies on saliency priors or pre-trained optical flow maps. Inspired by a layered image representation, we introduce a technique to group pixel regions according to their affine parametric motion. This enables our network to learn segmentation of the dominant foreground object using only RGB image pairs as input for both training and inference. We establish a baseline for this novel task using a new MovingCars dataset and show competitive performance against recent methods that require annotated masks to train.
PU-Transformer: Point Cloud Upsampling Transformer
Nov 24, 2021


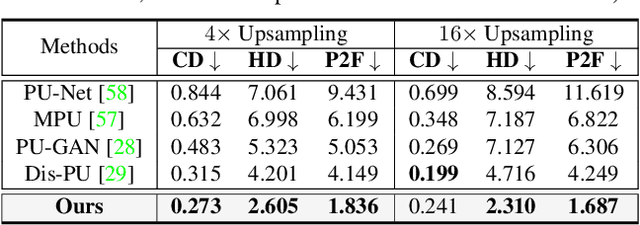
Given the rapid development of 3D scanners, point clouds are becoming popular in AI-driven machines. However, point cloud data is inherently sparse and irregular, causing major difficulties for machine perception. In this work, we focus on the point cloud upsampling task that intends to generate dense high-fidelity point clouds from sparse input data. Specifically, to activate the transformer's strong capability in representing features, we develop a new variant of a multi-head self-attention structure to enhance both point-wise and channel-wise relations of the feature map. In addition, we leverage a positional fusion block to comprehensively capture the local context of point cloud data, providing more position-related information about the scattered points. As the first transformer model introduced for point cloud upsampling, we demonstrate the outstanding performance of our approach by comparing with the state-of-the-art CNN-based methods on different benchmarks quantitatively and qualitatively.
Dense Uncertainty Estimation via an Ensemble-based Conditional Latent Variable Model
Nov 22, 2021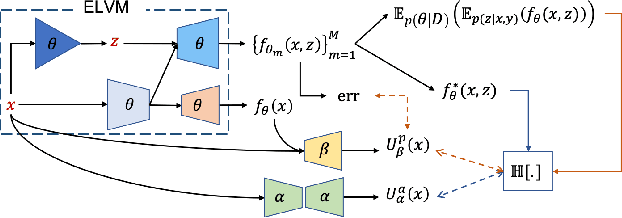



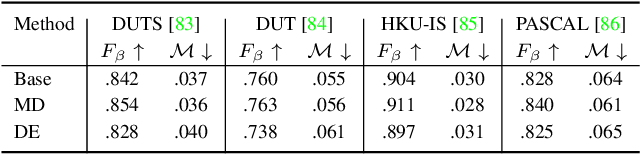
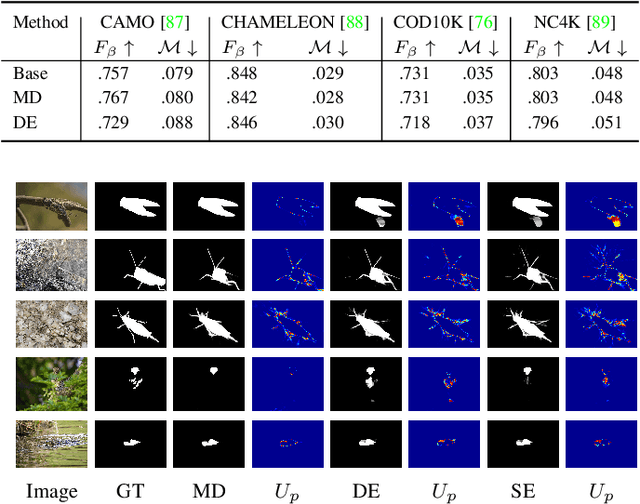
Uncertainty estimation has been extensively studied in recent literature, which can usually be classified as aleatoric uncertainty and epistemic uncertainty. In current aleatoric uncertainty estimation frameworks, it is often neglected that the aleatoric uncertainty is an inherent attribute of the data and can only be correctly estimated with an unbiased oracle model. Since the oracle model is inaccessible in most cases, we propose a new sampling and selection strategy at train time to approximate the oracle model for aleatoric uncertainty estimation. Further, we show a trivial solution in the dual-head based heteroscedastic aleatoric uncertainty estimation framework and introduce a new uncertainty consistency loss to avoid it. For epistemic uncertainty estimation, we argue that the internal variable in a conditional latent variable model is another source of epistemic uncertainty to model the predictive distribution and explore the limited knowledge about the hidden true model. We validate our observation on a dense prediction task, i.e., camouflaged object detection. Our results show that our solution achieves both accurate deterministic results and reliable uncertainty estimation.
Inferring the Class Conditional Response Map for Weakly Supervised Semantic Segmentation
Oct 27, 2021
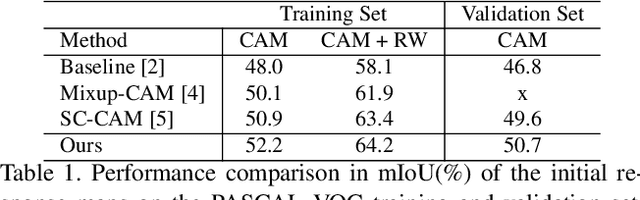

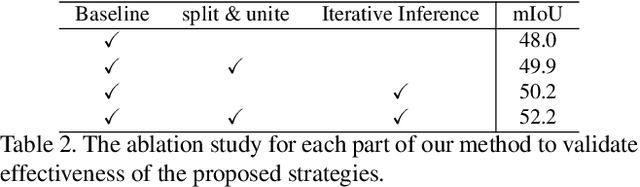
Image-level weakly supervised semantic segmentation (WSSS) relies on class activation maps (CAMs) for pseudo labels generation. As CAMs only highlight the most discriminative regions of objects, the generated pseudo labels are usually unsatisfactory to serve directly as supervision. To solve this, most existing approaches follow a multi-training pipeline to refine CAMs for better pseudo-labels, which includes: 1) re-training the classification model to generate CAMs; 2) post-processing CAMs to obtain pseudo labels; and 3) training a semantic segmentation model with the obtained pseudo labels. However, this multi-training pipeline requires complicated adjustment and additional time. To address this, we propose a class-conditional inference strategy and an activation aware mask refinement loss function to generate better pseudo labels without re-training the classifier. The class conditional inference-time approach is presented to separately and iteratively reveal the classification network's hidden object activation to generate more complete response maps. Further, our activation aware mask refinement loss function introduces a novel way to exploit saliency maps during segmentation training and refine the foreground object masks without suppressing background objects. Our method achieves superior WSSS results without requiring re-training of the classifier.
Dense Uncertainty Estimation
Oct 13, 2021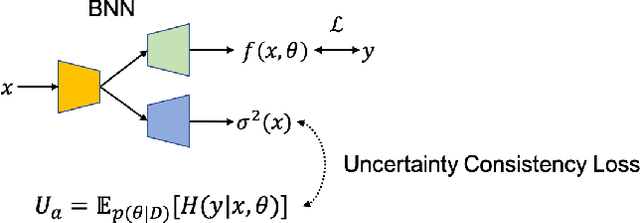
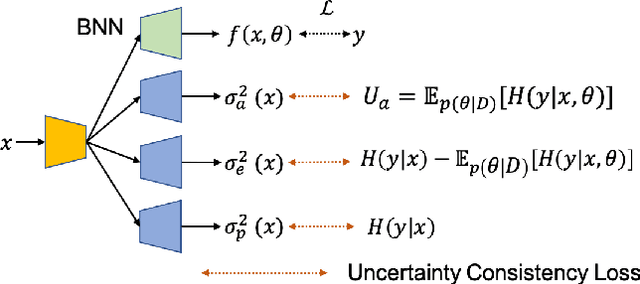
Deep neural networks can be roughly divided into deterministic neural networks and stochastic neural networks.The former is usually trained to achieve a mapping from input space to output space via maximum likelihood estimation for the weights, which leads to deterministic predictions during testing. In this way, a specific weights set is estimated while ignoring any uncertainty that may occur in the proper weight space. The latter introduces randomness into the framework, either by assuming a prior distribution over model parameters (i.e. Bayesian Neural Networks) or including latent variables (i.e. generative models) to explore the contribution of latent variables for model predictions, leading to stochastic predictions during testing. Different from the former that achieves point estimation, the latter aims to estimate the prediction distribution, making it possible to estimate uncertainty, representing model ignorance about its predictions. We claim that conventional deterministic neural network based dense prediction tasks are prone to overfitting, leading to over-confident predictions, which is undesirable for decision making. In this paper, we investigate stochastic neural networks and uncertainty estimation techniques to achieve both accurate deterministic prediction and reliable uncertainty estimation. Specifically, we work on two types of uncertainty estimations solutions, namely ensemble based methods and generative model based methods, and explain their pros and cons while using them in fully/semi/weakly-supervised framework. Due to the close connection between uncertainty estimation and model calibration, we also introduce how uncertainty estimation can be used for deep model calibration to achieve well-calibrated models, namely dense model calibration. Code and data are available at https://github.com/JingZhang617/UncertaintyEstimation.
RGB-D Saliency Detection via Cascaded Mutual Information Minimization
Sep 15, 2021

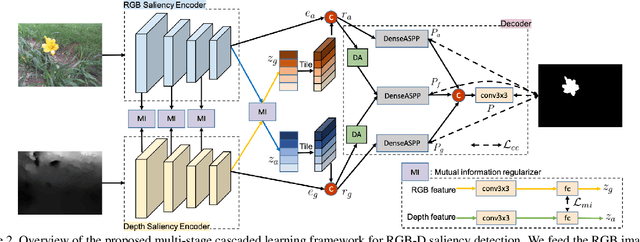
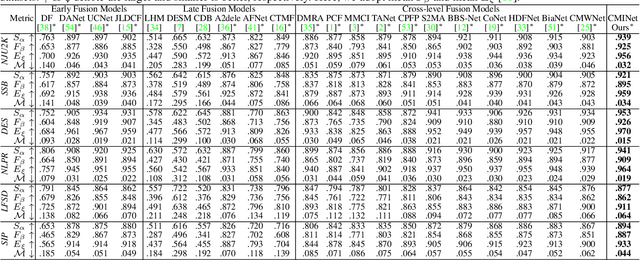
Existing RGB-D saliency detection models do not explicitly encourage RGB and depth to achieve effective multi-modal learning. In this paper, we introduce a novel multi-stage cascaded learning framework via mutual information minimization to "explicitly" model the multi-modal information between RGB image and depth data. Specifically, we first map the feature of each mode to a lower dimensional feature vector, and adopt mutual information minimization as a regularizer to reduce the redundancy between appearance features from RGB and geometric features from depth. We then perform multi-stage cascaded learning to impose the mutual information minimization constraint at every stage of the network. Extensive experiments on benchmark RGB-D saliency datasets illustrate the effectiveness of our framework. Further, to prosper the development of this field, we contribute the largest (7x larger than NJU2K) dataset, which contains 15,625 image pairs with high quality polygon-/scribble-/object-/instance-/rank-level annotations. Based on these rich labels, we additionally construct four new benchmarks with strong baselines and observe some interesting phenomena, which can motivate future model design. Source code and dataset are available at "https://github.com/JingZhang617/cascaded_rgbd_sod".
PnP-3D: A Plug-and-Play for 3D Point Clouds
Aug 16, 2021
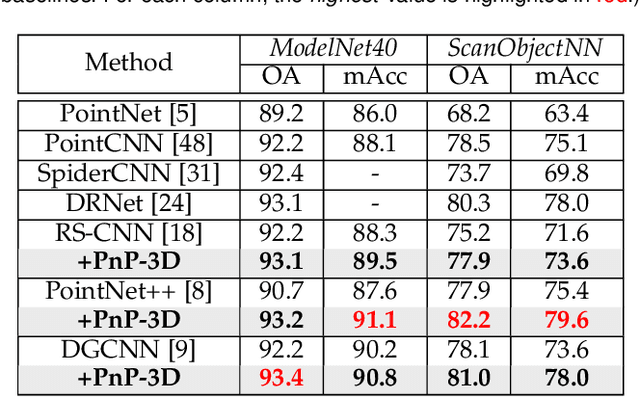
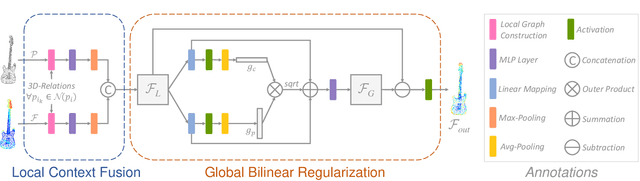

With the help of the deep learning paradigm, many point cloud networks have been invented for visual analysis. However, there is great potential for development of these networks since the given information of point cloud data has not been fully exploited. To improve the effectiveness of existing networks in analyzing point cloud data, we propose a plug-and-play module, PnP-3D, aiming to refine the fundamental point cloud feature representations by involving more local context and global bilinear response from explicit 3D space and implicit feature space. To thoroughly evaluate our approach, we conduct experiments on three standard point cloud analysis tasks, including classification, semantic segmentation, and object detection, where we select three state-of-the-art networks from each task for evaluation. Serving as a plug-and-play module, PnP-3D can significantly boost the performances of established networks. In addition to achieving state-of-the-art results on four widely used point cloud benchmarks, we present comprehensive ablation studies and visualizations to demonstrate our approach's advantages. The code will be available at https://github.com/ShiQiu0419/pnp-3d.
Energy-Based Generative Cooperative Saliency Prediction
Jun 25, 2021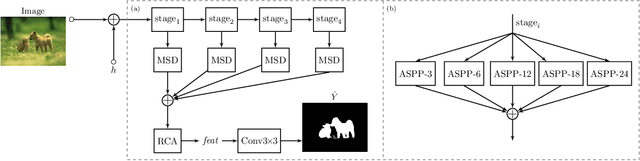
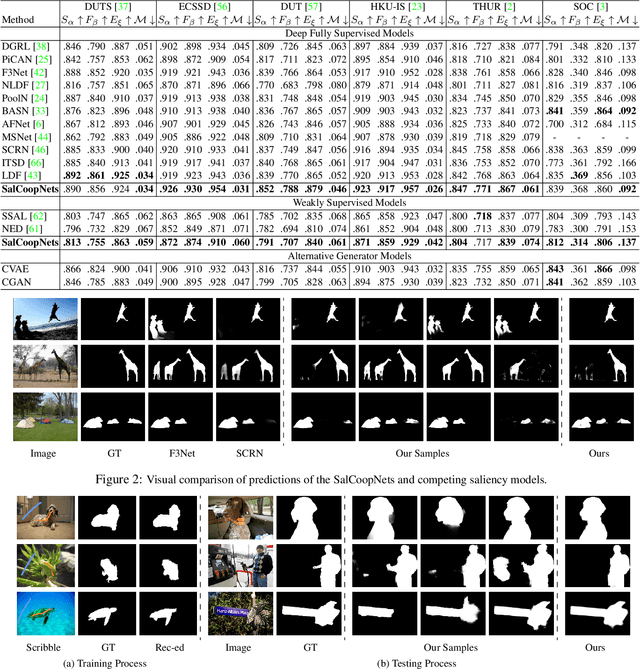
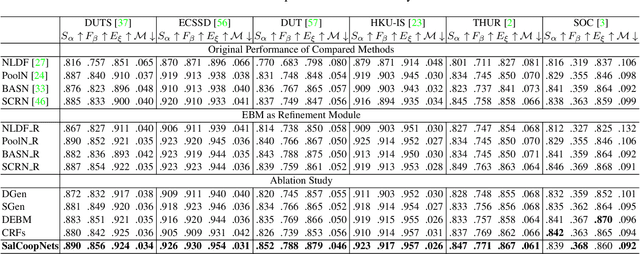
Conventional saliency prediction models typically learn a deterministic mapping from images to the corresponding ground truth saliency maps. In this paper, we study the saliency prediction problem from the perspective of generative models by learning a conditional probability distribution over saliency maps given an image, and treating the prediction as a sampling process. Specifically, we propose a generative cooperative saliency prediction framework based on the generative cooperative networks, where a conditional latent variable model and a conditional energy-based model are jointly trained to predict saliency in a cooperative manner. We call our model the SalCoopNets. The latent variable model serves as a fast but coarse predictor to efficiently produce an initial prediction, which is then refined by the iterative Langevin revision of the energy-based model that serves as a fine predictor. Such a coarse-to-fine cooperative saliency prediction strategy offers the best of both worlds. Moreover, we generalize our framework to the scenario of weakly supervised saliency prediction, where saliency annotation of training images is partially observed, by proposing a cooperative learning while recovering strategy. Lastly, we show that the learned energy function can serve as a refinement module that can refine the results of other pre-trained saliency prediction models. Experimental results show that our generative model can achieve state-of-the-art performance. Our code is publicly available at: \url{https://github.com/JingZhang617/SalCoopNets}.