 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Transforms Salient Object Detection and Camouflaged Object Detection
Paper and Code
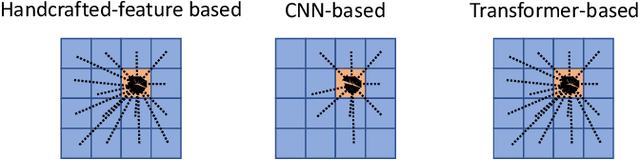
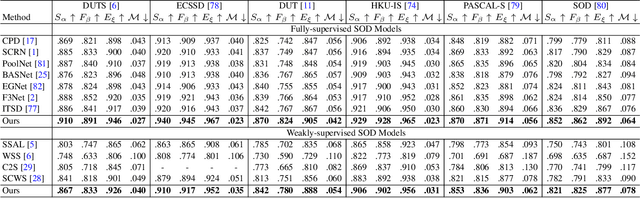
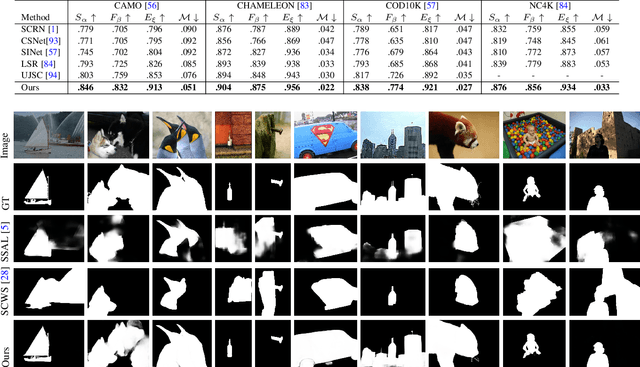
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.