 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Transfer Learning under Federated Learning for Automatic Speech Recognition
Aug 19, 2024



This work explores the challenge of enhancing Automatic Speech Recognition (ASR) model performance across various user-specific domains while preserving user data privacy. We employ federated learning and parameter-efficient domain adaptation methods to solve the (1) massive data requirement of ASR models from user-specific scenarios and (2) the substantial communication cost between servers and clients during federated learning. We demonstrate that when equipped with proper adapters, ASR models under federated tuning can achieve similar performance compared with centralized tuning ones, thus providing a potential direction for future privacy-preserved ASR services. Besides, we investigate the efficiency of different adapters and adapter incorporation strategies under the federated learning setting.
Text Injection for Neural Contextual Biasing
Jun 05, 2024



Neural contextual biasing effectively improves automatic speech recognition (ASR) for crucial phrases within a speaker's context, particularly those that are infrequent in the training data. This work proposes contextual text injection (CTI) to enhance contextual ASR. CTI leverages not only the paired speech-text data, but also a much larger corpus of unpaired text to optimize the ASR model and its biasing component. Unpaired text is converted into speech-like representations and used to guide the model's attention towards relevant bias phrases. Moreover, we introduce a contextual text-injected (CTI) minimum word error rate (MWER) training, which minimizes the expected WER caused by contextual biasing when unpaired text is injected into the model. Experiments show that CTI with 100 billion text sentences can achieve up to 43.3% relative WER reduction from a strong neural biasing model. CTI-MWER provides a further relative improvement of 23.5%.
* 5 pages, 1 figure
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
E3 TTS: Easy End-to-End Diffusion-based Text to Speech
Nov 02, 2023We propose Easy End-to-End Diffusion-based Text to Speech, a simple and efficient end-to-end text-to-speech model based on diffusion. E3 TTS directly takes plain text as input and generates an audio waveform through an iterative refinement process. Unlike many prior work, E3 TTS does not rely on any intermediate representations like spectrogram features or alignment information. Instead, E3 TTS models the temporal structure of the waveform through the diffusion process. Without relying on additional conditioning information, E3 TTS could support flexible latent structure within the given audio. This enables E3 TTS to be easily adapted for zero-shot tasks such as editing without any additional training. Experiments show that E3 TTS can generate high-fidelity audio, approaching the performance of a state-of-the-art neural TTS system. Audio samples are available at https://e3tts.github.io.
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023



We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.
Efficient Adapters for Giant Speech Models
Jun 13, 2023



Large pre-trained speech models are widely used as the de-facto paradigm, especially in scenarios when there is a limited amount of labeled data available. However, finetuning all parameters from the self-supervised learned model can be computationally expensive, and becomes infeasiable as the size of the model and the number of downstream tasks scales. In this paper, we propose a novel approach called Two Parallel Adapter (TPA) that is inserted into the conformer-based model pre-trained model instead. TPA is based on systematic studies of the residual adapter, a popular approach for finetuning a subset of parameters. We evaluate TPA on various public benchmarks and experiment results demonstrates its superior performance, which is close to the full finetuning on different datasets and speech tasks. These results show that TPA is an effective and efficient approach for serving large pre-trained speech models. Ablation studies show that TPA can also be pruned, especially for lower blocks.
How to Estimate Model Transferability of Pre-Trained Speech Models?
Jun 01, 2023In this work, we introduce a ``score-based assessment'' framework for estimating the transferability of pre-trained speech models (PSMs) for fine-tuning target tasks. We leverage upon two representation theories, Bayesian likelihood estimation and optimal transport, to generate rank scores for the PSM candidates using the extracted representations. Our framework efficiently computes transferability scores without actual fine-tuning of candidate models or layers by making a temporal independent hypothesis. We evaluate some popular supervised speech models (e.g., Conformer RNN-Transducer) and self-supervised speech models (e.g., HuBERT) in cross-layer and cross-model settings using public data. Experimental results show a high Spearman's rank correlation and low $p$-value between our estimation framework and fine-tuning ground truth. Our proposed transferability framework requires less computational time and resources, making it a resource-saving and time-efficient approach for tuning speech foundation models.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
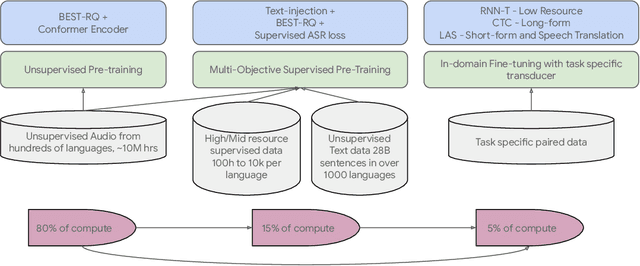
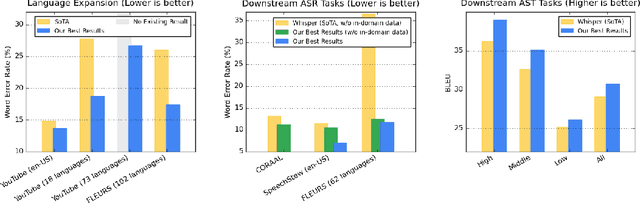

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023



We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music