 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Imitation Learning: Layered Control Architecture for Certifiable Autonomy
Dec 19, 2025Imitation learning (IL) enables autonomous behavior by learning from expert demonstrations. While more sample-efficient than comparative alternatives like reinforcement learning, IL is sensitive to compounding errors induced by distribution shifts. There are two significant sources of distribution shifts when using IL-based feedback laws on systems: distribution shifts caused by policy error and distribution shifts due to exogenous disturbances and endogenous model errors due to lack of learning. Our previously developed approaches, Taylor Series Imitation Learning (TaSIL) and $\mathcal{L}_1$ -Distributionally Robust Adaptive Control (\ellonedrac), address the challenge of distribution shifts in complementary ways. While TaSIL offers robustness against policy error-induced distribution shifts, \ellonedrac offers robustness against distribution shifts due to aleatoric and epistemic uncertainties. To enable certifiable IL for learned and/or uncertain dynamical systems, we formulate \textit{Distributionally Robust Imitation Policy (DRIP)} architecture, a Layered Control Architecture (LCA) that integrates TaSIL and~\ellonedrac. By judiciously designing individual layer-centric input and output requirements, we show how we can guarantee certificates for the entire control pipeline. Our solution paves the path for designing fully certifiable autonomy pipelines, by integrating learning-based components, such as perception, with certifiable model-based decision-making through the proposed LCA approach.
A Robust Task-Level Control Architecture for Learned Dynamical Systems
Nov 12, 2025Dynamical system (DS)-based learning from demonstration (LfD) is a powerful tool for generating motion plans in the operation (`task') space of robotic systems. However, the realization of the generated motion plans is often compromised by a ''task-execution mismatch'', where unmodeled dynamics, persistent disturbances, and system latency cause the robot's actual task-space state to diverge from the desired motion trajectory. We propose a novel task-level robust control architecture, L1-augmented Dynamical Systems (L1-DS), that explicitly handles the task-execution mismatch in tracking a nominal motion plan generated by any DS-based LfD scheme. Our framework augments any DS-based LfD model with a nominal stabilizing controller and an L1 adaptive controller. Furthermore, we introduce a windowed Dynamic Time Warping (DTW)-based target selector, which enables the nominal stabilizing controller to handle temporal misalignment for improved phase-consistent tracking. We demonstrate the efficacy of our architecture on the LASA and IROS handwriting datasets.
DiffCoTune: Differentiable Co-Tuning for Cross-domain Robot Control
May 29, 2025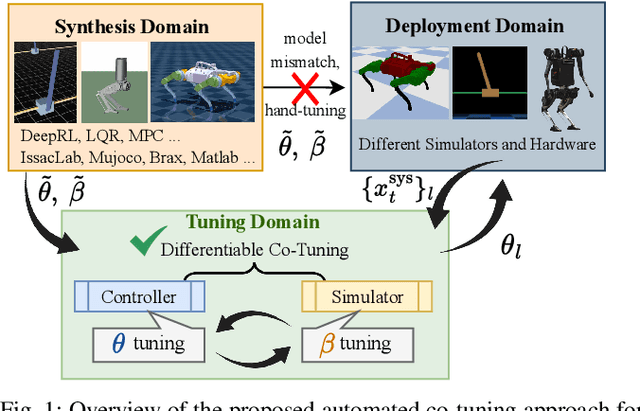
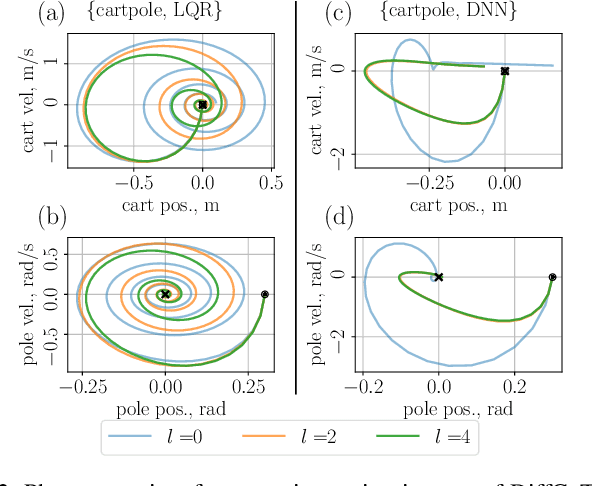
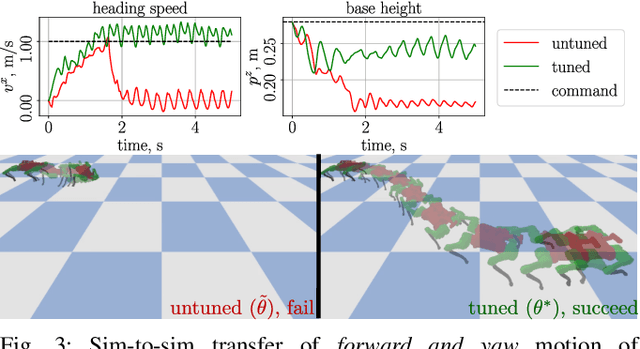
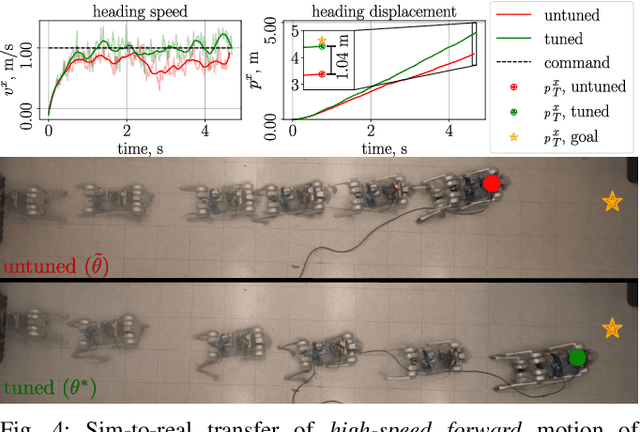
The deployment of robot controllers is hindered by modeling discrepancies due to necessary simplifications for computational tractability or inaccuracies in data-generating simulators. Such discrepancies typically require ad-hoc tuning to meet the desired performance, thereby ensuring successful transfer to a target domain. We propose a framework for automated, gradient-based tuning to enhance performance in the deployment domain by leveraging differentiable simulators. Our method collects rollouts in an iterative manner to co-tune the simulator and controller parameters, enabling systematic transfer within a few trials in the deployment domain. Specifically, we formulate multi-step objectives for tuning and employ alternating optimization to effectively adapt the controller to the deployment domain. The scalability of our framework is demonstrated by co-tuning model-based and learning-based controllers of arbitrary complexity for tasks ranging from low-dimensional cart-pole stabilization to high-dimensional quadruped and biped tracking, showing performance improvements across different deployment domains.
Task-Parameter Nexus: Task-Specific Parameter Learning for Model-Based Control
Dec 17, 2024



This paper presents the Task-Parameter Nexus (TPN), a learning-based approach for online determination of the (near-)optimal control parameters of model-based controllers (MBCs) for tracking tasks. In TPN, a deep neural network is introduced to predict the control parameters for any given tracking task at runtime, especially when optimal parameters for new tasks are not immediately available. To train this network, we constructed a trajectory bank with various speeds and curvatures that represent different motion characteristics. Then, for each trajectory in the bank, we auto-tune the optimal control parameters offline and use them as the corresponding ground truth. With this dataset, the TPN is trained by supervised learning. We evaluated the TPN on the quadrotor platform. In simulation experiments, it is shown that the TPN can predict near-optimal control parameters for a spectrum of tracking tasks, demonstrating its robust generalization capabilities to unseen tasks.
Integrating Vision Systems and STPA for Robust Landing and Take-Off in VTOL Aircraft
Dec 12, 2024Vertical take-off and landing (VTOL) unmanned aerial vehicles (UAVs) are versatile platforms widely used in applications such as surveillance, search and rescue, and urban air mobility. Despite their potential, the critical phases of take-off and landing in uncertain and dynamic environments pose significant safety challenges due to environmental uncertainties, sensor noise, and system-level interactions. This paper presents an integrated approach combining vision-based sensor fusion with System-Theoretic Process Analysis (STPA) to enhance the safety and robustness of VTOL UAV operations during take-off and landing. By incorporating fiducial markers, such as AprilTags, into the control architecture, and performing comprehensive hazard analysis, we identify unsafe control actions and propose mitigation strategies. Key contributions include developing the control structure with vision system capable of identifying a fiducial marker, multirotor controller and corresponding unsafe control actions and mitigation strategies. The proposed solution is expected to improve the reliability and safety of VTOL UAV operations, paving the way for resilient autonomous systems.
Verification and Validation of a Vision-Based Landing System for Autonomous VTOL Air Taxis
Dec 11, 2024



Autonomous air taxis are poised to revolutionize urban mass transportation, however, ensuring their safety and reliability remains an open challenge. Validating autonomy solutions on air taxis in the real world presents complexities, risks, and costs that further convolute this challenge. Verification and Validation (V&V) frameworks play a crucial role in the design and development of highly reliable systems by formally verifying safety properties and validating algorithm behavior across diverse operational scenarios. Advancements in high-fidelity simulators have significantly enhanced their capability to emulate real-world conditions, encouraging their use for validating autonomous air taxi solutions, especially during early development stages. This evolution underscores the growing importance of simulation environments, not only as complementary tools to real-world testing but as essential platforms for evaluating algorithms in a controlled, reproducible, and scalable manner. This work presents a V&V framework for a vision-based landing system for air taxis with vertical take-off and landing (VTOL) capabilities. Specifically, we use Verse, a tool for formal verification, to model and verify the safety of the system by obtaining and analyzing the reachable sets. To conduct this analysis, we utilize a photorealistic simulation environment. The simulation environment, built on Unreal Engine, provides realistic terrain, weather, and sensor characteristics to emulate real-world conditions with high fidelity. To validate the safety analysis results, we conduct extensive scenario-based testing to assess the reachability set and robustness of the landing algorithm in various conditions. This approach showcases the representativeness of high-fidelity simulators, offering an effective means to analyze and refine algorithms before real-world deployment.
Bayesian Data Augmentation and Training for Perception DNN in Autonomous Aerial Vehicles
Dec 10, 2024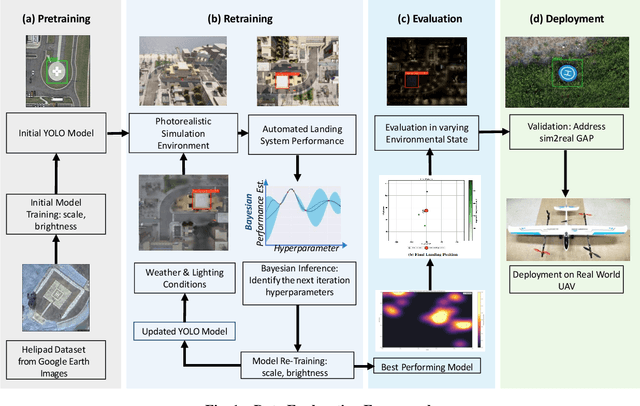
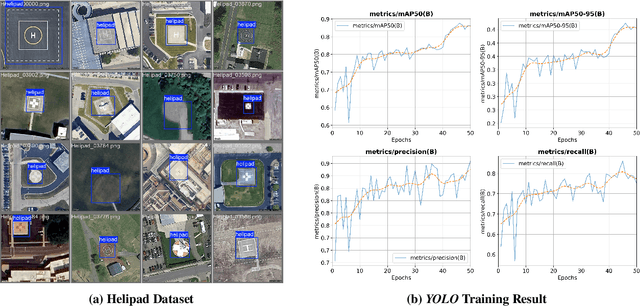
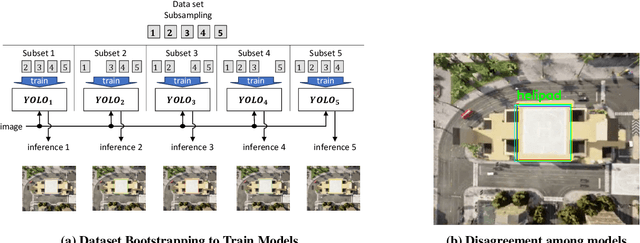
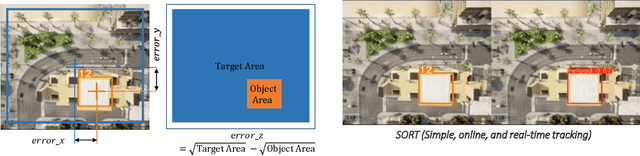
Learning-based solutions have enabled incredible capabilities for autonomous systems. Autonomous vehicles, both aerial and ground, rely on DNN for various integral tasks, including perception. The efficacy of supervised learning solutions hinges on the quality of the training data. Discrepancies between training data and operating conditions result in faults that can lead to catastrophic incidents. However, collecting vast amounts of context-sensitive data, with broad coverage of possible operating environments, is prohibitively difficult. Synthetic data generation techniques for DNN allow for the easy exploration of diverse scenarios. However, synthetic data generation solutions for aerial vehicles are still lacking. This work presents a data augmentation framework for aerial vehicle's perception training, leveraging photorealistic simulation integrated with high-fidelity vehicle dynamics. Safe landing is a crucial challenge in the development of autonomous air taxis, therefore, landing maneuver is chosen as the focus of this work. With repeated simulations of landing in varying scenarios we assess the landing performance of the VTOL type UAV and gather valuable data. The landing performance is used as the objective function to optimize the DNN through retraining. Given the high computational cost of DNN retraining, we incorporated Bayesian Optimization in our framework that systematically explores the data augmentation parameter space to retrain the best-performing models. The framework allowed us to identify high-performing data augmentation parameters that are consistently effective across different landing scenarios. Utilizing the capabilities of this data augmentation framework, we obtained a robust perception model. The model consistently improved the perception-based landing success rate by at least 20% under different lighting and weather conditions.
CROPS: A Deployable Crop Management System Over All Possible State Availabilities
Nov 09, 2024



Exploring the optimal management strategy for nitrogen and irrigation has a significant impact on crop yield, economic profit, and the environment. To tackle this optimization challenge, this paper introduces a deployable \textbf{CR}op Management system \textbf{O}ver all \textbf{P}ossible \textbf{S}tate availabilities (CROPS). CROPS employs a language model (LM) as a reinforcement learning (RL) agent to explore optimal management strategies within the Decision Support System for Agrotechnology Transfer (DSSAT) crop simulations. A distinguishing feature of this system is that the states used for decision-making are partially observed through random masking. Consequently, the RL agent is tasked with two primary objectives: optimizing management policies and inferring masked states. This approach significantly enhances the RL agent's robustness and adaptability across various real-world agricultural scenarios. Extensive experiments on maize crops in Florida, USA, and Zaragoza, Spain, validate the effectiveness of CROPS. Not only did CROPS achieve State-of-the-Art (SOTA) results across various evaluation metrics such as production, profit, and sustainability, but the trained management policies are also immediately deployable in over of ten millions of real-world contexts. Furthermore, the pre-trained policies possess a noise resilience property, which enables them to minimize potential sensor biases, ensuring robustness and generalizability. Finally, unlike previous methods, the strength of CROPS lies in its unified and elegant structure, which eliminates the need for pre-defined states or multi-stage training. These advancements highlight the potential of CROPS in revolutionizing agricultural practices.
Addressing Behavior Model Inaccuracies for Safe Motion Control in Uncertain Dynamic Environments
Jul 26, 2024



Uncertainties in the environment and behavior model inaccuracies compromise the state estimation of a dynamic obstacle and its trajectory predictions, introducing biases in estimation and shifts in predictive distributions. Addressing these challenges is crucial to safely control an autonomous system. In this paper, we propose a novel algorithm SIED-MPC, which synergistically integrates Simultaneous State and Input Estimation (SSIE) and Distributionally Robust Model Predictive Control (DR-MPC) using model confidence evaluation. The SSIE process produces unbiased state estimates and optimal input gap estimates to assess the confidence of the behavior model, defining the ambiguity radius for DR-MPC to handle predictive distribution shifts. This systematic confidence evaluation leads to producing safe inputs with an adequate level of conservatism. Our algorithm demonstrated a reduced collision rate in autonomous driving simulations through improved state estimation, with a 54% shorter average computation time.
Resilient Estimator-based Control Barrier Functions for Dynamical Systems with Disturbances and Noise
Jun 28, 2024



Control Barrier Function (CBF) is an emerging method that guarantees safety in path planning problems by generating a control command to ensure the forward invariance of a safety set. Most of the developments up to date assume availability of correct state measurements and absence of disturbances on the system. However, if the system incurs disturbances and is subject to noise, the CBF cannot guarantee safety due to the distorted state estimate. To improve the resilience and adaptability of the CBF, we propose a resilient estimator-based control barrier function (RE-CBF), which is based on a novel stochastic CBF optimization and resilient estimator, to guarantee the safety of systems with disturbances and noise in the path planning problems. The proposed algorithm uses the resilient estimation algorithm to estimate disturbances and counteract their effect using novel stochastic CBF optimization, providing safe control inputs for dynamical systems with disturbances and noise. To demonstrate the effectiveness of our algorithm in handling both noise and disturbances in dynamics and measurement, we design a quadrotor testing pipeline to simulate the proposed algorithm and then implement the algorithm on a real drone in our flying arena. Both simulations and real-world experiments show that the proposed method can guarantee safety for systems with disturbances and noise.