 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Batch Normalization Boosts Adversarial Training
Jul 04, 2022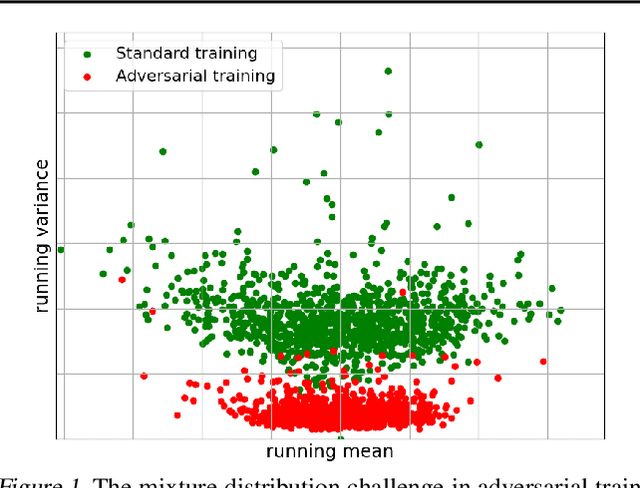
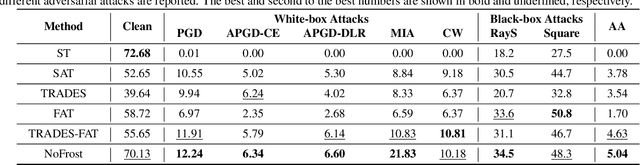
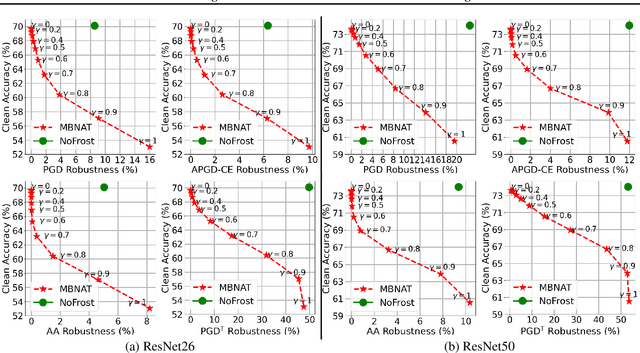
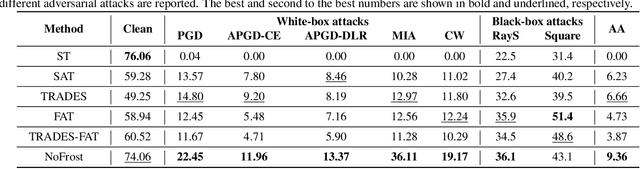
Adversarial training (AT) defends deep neural networks against adversarial attacks. One challenge that limits its practical application is the performance degradation on clean samples. A major bottleneck identified by previous works is the widely used batch normalization (BN), which struggles to model the different statistics of clean and adversarial training samples in AT. Although the dominant approach is to extend BN to capture this mixture of distribution, we propose to completely eliminate this bottleneck by removing all BN layers in AT. Our normalizer-free robust training (NoFrost) method extends recent advances in normalizer-free networks to AT for its unexplored advantage on handling the mixture distribution challenge. We show that NoFrost achieves adversarial robustness with only a minor sacrifice on clean sample accuracy. On ImageNet with ResNet50, NoFrost achieves $74.06\%$ clean accuracy, which drops merely $2.00\%$ from standard training. In contrast, BN-based AT obtains $59.28\%$ clean accuracy, suffering a significant $16.78\%$ drop from standard training. In addition, NoFrost achieves a $23.56\%$ adversarial robustness against PGD attack, which improves the $13.57\%$ robustness in BN-based AT. We observe better model smoothness and larger decision margins from NoFrost, which make the models less sensitive to input perturbations and thus more robust. Moreover, when incorporating more data augmentations into NoFrost, it achieves comprehensive robustness against multiple distribution shifts. Code and pre-trained models are public at https://github.com/amazon-research/normalizer-free-robust-training.
MixGen: A New Multi-Modal Data Augmentation
Jun 16, 2022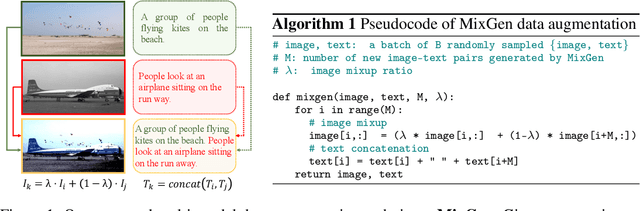

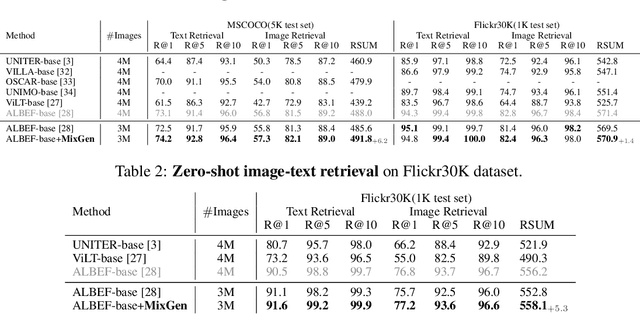
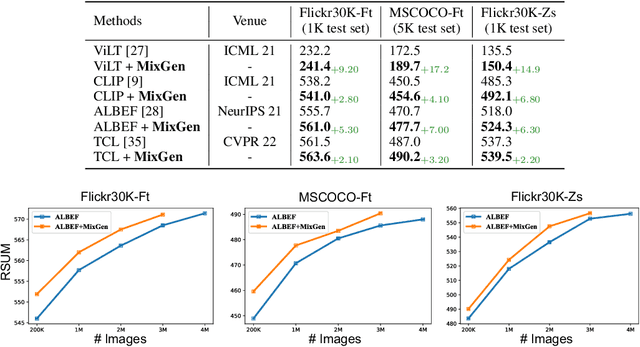
Data augmentation is a necessity to enhance data efficiency in deep learning. For vision-language pre-training, data is only augmented either for images or for text in previous works. In this paper, we present MixGen: a joint data augmentation for vision-language representation learning to further improve data efficiency. It generates new image-text pairs with semantic relationships preserved by interpolating images and concatenating text. It's simple, and can be plug-and-played into existing pipelines. We evaluate MixGen on four architectures, including CLIP, ViLT, ALBEF and TCL, across five downstream vision-language tasks to show its versatility and effectiveness. For example, adding MixGen in ALBEF pre-training leads to absolute performance improvements on downstream tasks: image-text retrieval (+6.2% on COCO fine-tuned and +5.3% on Flicker30K zero-shot), visual grounding (+0.9% on RefCOCO+), visual reasoning (+0.9% on NLVR$^{2}$), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
Modeling Multi-Granularity Hierarchical Features for Relation Extraction
Apr 09, 2022
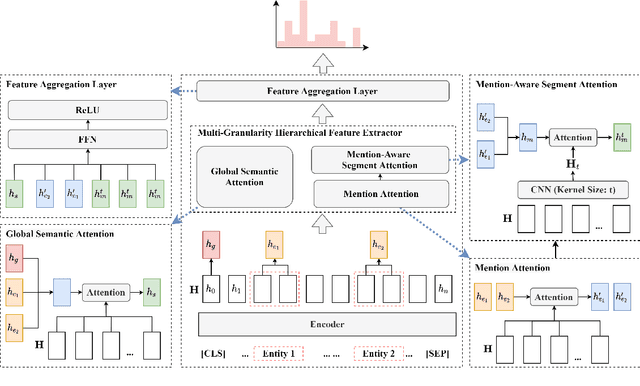
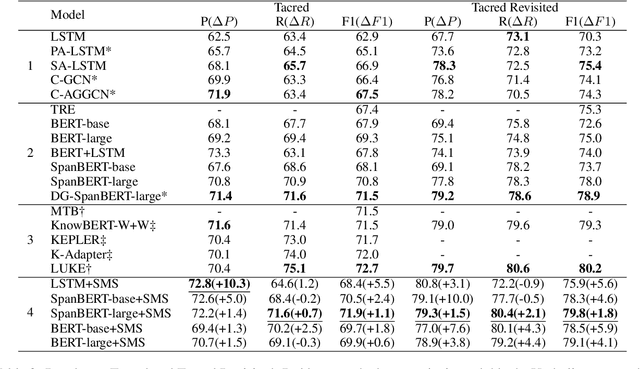
Relation extraction is a key task in Natural Language Processing (NLP), which aims to extract relations between entity pairs from given texts. Recently, relation extraction (RE) has achieved remarkable progress with the development of deep neural networks. Most existing research focuses on constructing explicit structured features using external knowledge such as knowledge graph and dependency tree. In this paper, we propose a novel method to extract multi-granularity features based solely on the original input sentences. We show that effective structured features can be attained even without external knowledge. Three kinds of features based on the input sentences are fully exploited, which are in entity mention level, segment level, and sentence level. All the three are jointly and hierarchically modeled. We evaluate our method on three public benchmarks: SemEval 2010 Task 8, Tacred, and Tacred Revisited. To verify the effectiveness, we apply our method to different encoders such as LSTM and BERT. Experimental results show that our method significantly outperforms existing state-of-the-art models that even use external knowledge. Extensive analyses demonstrate that the performance of our model is contributed by the capture of multi-granularity features and the model of their hierarchical structure. Code and data are available at \url{https://github.com/xnliang98/sms}.
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
Mar 24, 2022
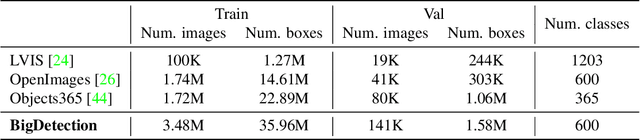
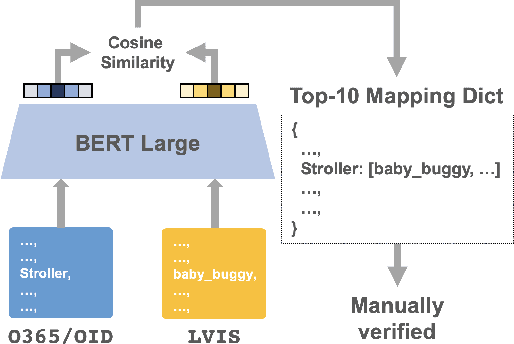
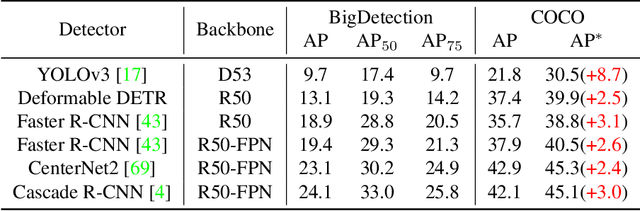
Multiple datasets and open challenges for object detection have been introduced in recent years. To build more general and powerful object detection systems, in this paper, we construct a new large-scale benchmark termed BigDetection. Our goal is to simply leverage the training data from existing datasets (LVIS, OpenImages and Object365) with carefully designed principles, and curate a larger dataset for improved detector pre-training. Specifically, we generate a new taxonomy which unifies the heterogeneous label spaces from different sources. Our BigDetection dataset has 600 object categories and contains over 3.4M training images with 36M bounding boxes. It is much larger in multiple dimensions than previous benchmarks, which offers both opportunities and challenges. Extensive experiments demonstrate its validity as a new benchmark for evaluating different object detection methods, and its effectiveness as a pre-training dataset.
Task-guided Disentangled Tuning for Pretrained Language Models
Mar 22, 2022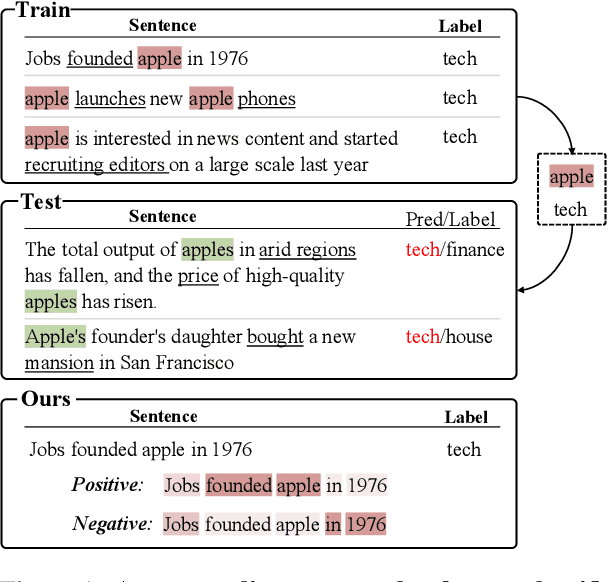
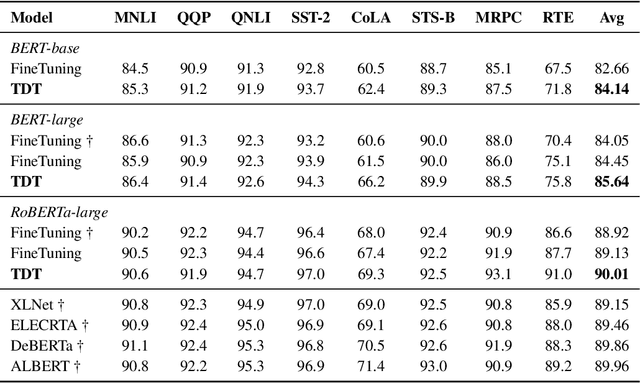

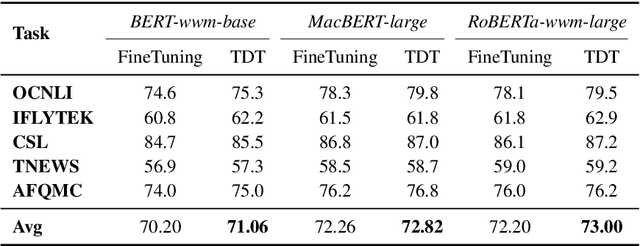
Pretrained language models (PLMs) trained on large-scale unlabeled corpus are typically fine-tuned on task-specific downstream datasets, which have produced state-of-the-art results on various NLP tasks. However, the data discrepancy issue in domain and scale makes fine-tuning fail to efficiently capture task-specific patterns, especially in the low data regime. To address this issue, we propose Task-guided Disentangled Tuning (TDT) for PLMs, which enhances the generalization of representations by disentangling task-relevant signals from the entangled representations. For a given task, we introduce a learnable confidence model to detect indicative guidance from context, and further propose a disentangled regularization to mitigate the over-reliance problem. Experimental results on GLUE and CLUE benchmarks show that TDT gives consistently better results than fine-tuning with different PLMs, and extensive analysis demonstrates the effectiveness and robustness of our method. Code is available at https://github.com/lemon0830/TDT.
Learning Confidence for Transformer-based Neural Machine Translation
Mar 22, 2022
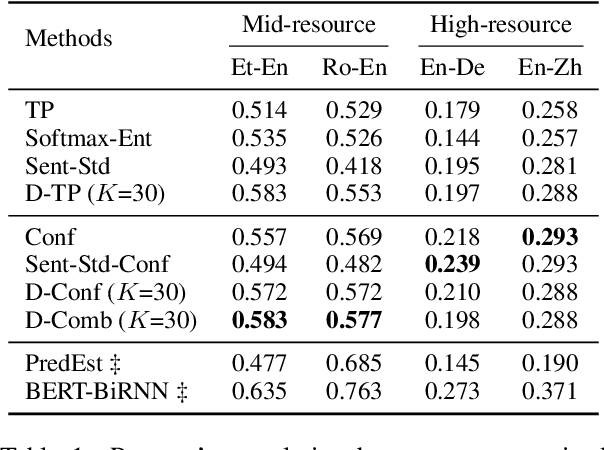
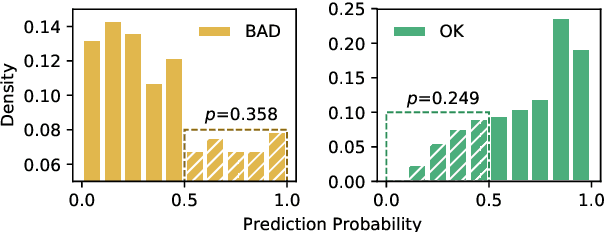

Confidence estimation aims to quantify the confidence of the model prediction, providing an expectation of success. A well-calibrated confidence estimate enables accurate failure prediction and proper risk measurement when given noisy samples and out-of-distribution data in real-world settings. However, this task remains a severe challenge for neural machine translation (NMT), where probabilities from softmax distribution fail to describe when the model is probably mistaken. To address this problem, we propose an unsupervised confidence estimate learning jointly with the training of the NMT model. We explain confidence as how many hints the NMT model needs to make a correct prediction, and more hints indicate low confidence. Specifically, the NMT model is given the option to ask for hints to improve translation accuracy at the cost of some slight penalty. Then, we approximate their level of confidence by counting the number of hints the model uses. We demonstrate that our learned confidence estimate achieves high accuracy on extensive sentence/word-level quality estimation tasks. Analytical results verify that our confidence estimate can correctly assess underlying risk in two real-world scenarios: (1) discovering noisy samples and (2) detecting out-of-domain data. We further propose a novel confidence-based instance-specific label smoothing approach based on our learned confidence estimate, which outperforms standard label smoothing.
Pseudocylindrical Convolutions for Learned Omnidirectional Image Compression
Dec 25, 2021
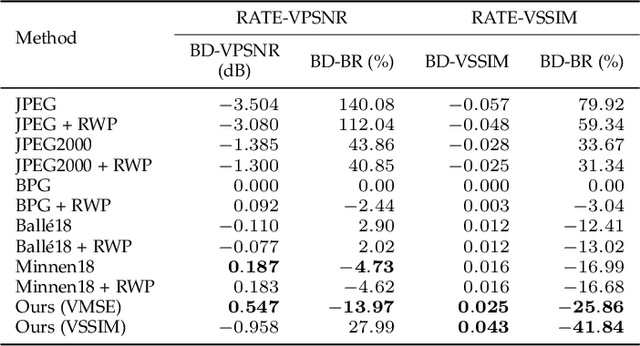
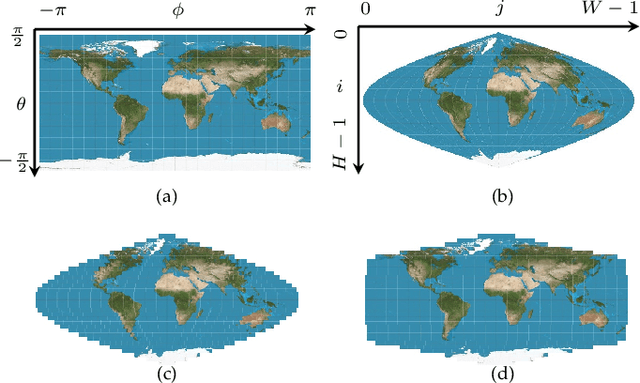

Although equirectangular projection (ERP) is a convenient form to store omnidirectional images (also known as 360-degree images), it is neither equal-area nor conformal, thus not friendly to subsequent visual communication. In the context of image compression, ERP will over-sample and deform things and stuff near the poles, making it difficult for perceptually optimal bit allocation. In conventional 360-degree image compression, techniques such as region-wise packing and tiled representation are introduced to alleviate the over-sampling problem, achieving limited success. In this paper, we make one of the first attempts to learn deep neural networks for omnidirectional image compression. We first describe parametric pseudocylindrical representation as a generalization of common pseudocylindrical map projections. A computationally tractable greedy method is presented to determine the (sub)-optimal configuration of the pseudocylindrical representation in terms of a novel proxy objective for rate-distortion performance. We then propose pseudocylindrical convolutions for 360-degree image compression. Under reasonable constraints on the parametric representation, the pseudocylindrical convolution can be efficiently implemented by standard convolution with the so-called pseudocylindrical padding. To demonstrate the feasibility of our idea, we implement an end-to-end 360-degree image compression system, consisting of the learned pseudocylindrical representation, an analysis transform, a non-uniform quantizer, a synthesis transform, and an entropy model. Experimental results on $19,790$ omnidirectional images show that our method achieves consistently better rate-distortion performance than the competing methods. Moreover, the visual quality by our method is significantly improved for all images at all bitrates.
Benchmarking Multimodal AutoML for Tabular Data with Text Fields
Nov 04, 2021
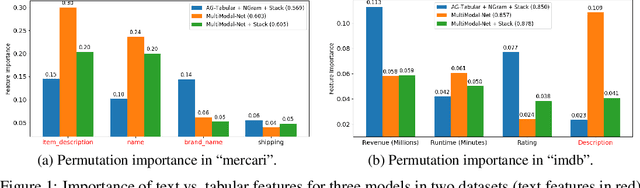
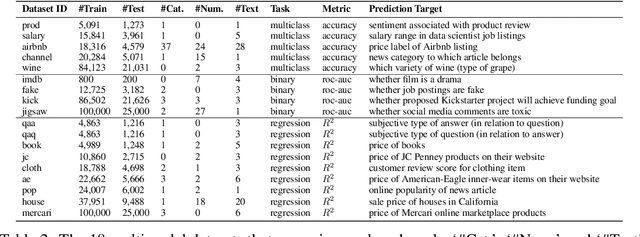
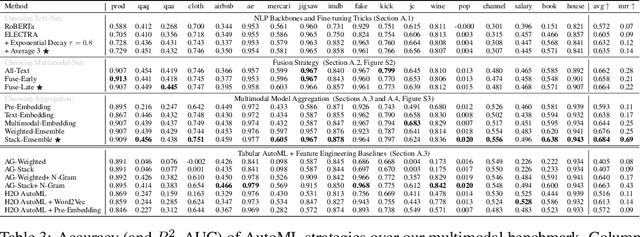
We consider the use of automated supervised learning systems for data tables that not only contain numeric/categorical columns, but one or more text fields as well. Here we assemble 18 multimodal data tables that each contain some text fields and stem from a real business application. Our publicly-available benchmark enables researchers to comprehensively evaluate their own methods for supervised learning with numeric, categorical, and text features. To ensure that any single modeling strategy which performs well over all 18 datasets will serve as a practical foundation for multimodal text/tabular AutoML, the diverse datasets in our benchmark vary greatly in: sample size, problem types (a mix of classification and regression tasks), number of features (with the number of text columns ranging from 1 to 28 between datasets), as well as how the predictive signal is decomposed between text vs. numeric/categorical features (and predictive interactions thereof). Over this benchmark, we evaluate various straightforward pipelines to model such data, including standard two-stage approaches where NLP is used to featurize the text such that AutoML for tabular data can then be applied. Compared with human data science teams, the fully automated methodology that performed best on our benchmark (stack ensembling a multimodal Transformer with various tree models) also manages to rank 1st place when fit to the raw text/tabular data in two MachineHack prediction competitions and 2nd place (out of 2380 teams) in Kaggle's Mercari Price Suggestion Challenge.
Blending Anti-Aliasing into Vision Transformer
Oct 28, 2021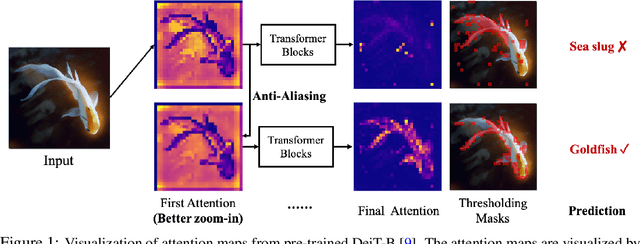
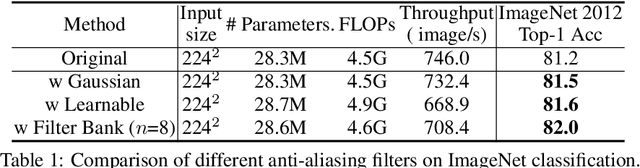

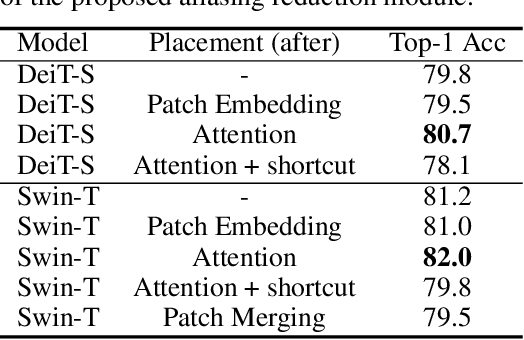
The transformer architectures, based on self-attention mechanism and convolution-free design, recently found superior performance and booming applications in computer vision. However, the discontinuous patch-wise tokenization process implicitly introduces jagged artifacts into attention maps, arising the traditional problem of aliasing for vision transformers. Aliasing effect occurs when discrete patterns are used to produce high frequency or continuous information, resulting in the indistinguishable distortions. Recent researches have found that modern convolution networks still suffer from this phenomenon. In this work, we analyze the uncharted problem of aliasing in vision transformer and explore to incorporate anti-aliasing properties. Specifically, we propose a plug-and-play Aliasing-Reduction Module(ARM) to alleviate the aforementioned issue. We investigate the effectiveness and generalization of the proposed method across multiple tasks and various vision transformer families. This lightweight design consistently attains a clear boost over several famous structures. Furthermore, our module also improves data efficiency and robustness of vision transformers.
Distiller: A Systematic Study of Model Distillation Methods in Natural Language Processing
Sep 23, 2021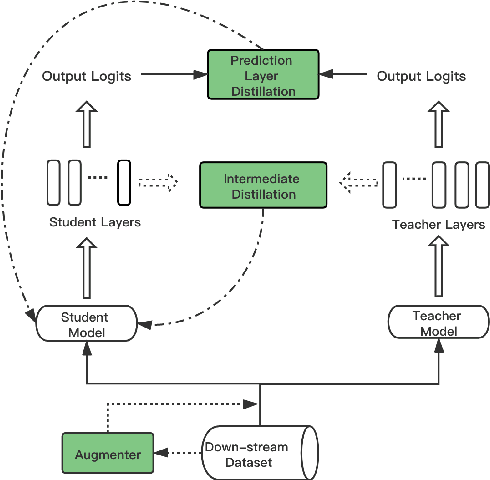
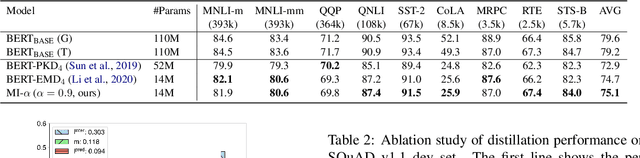
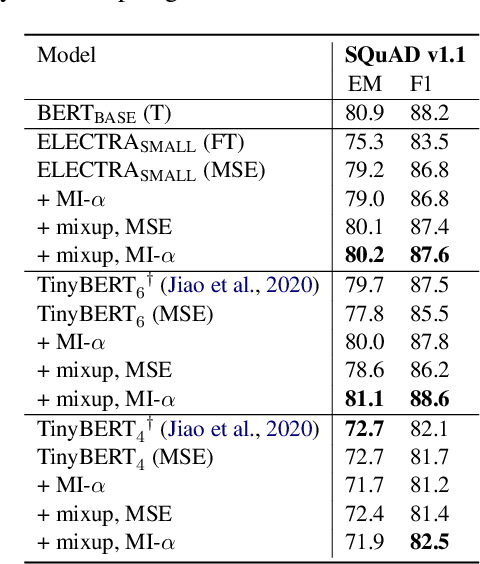
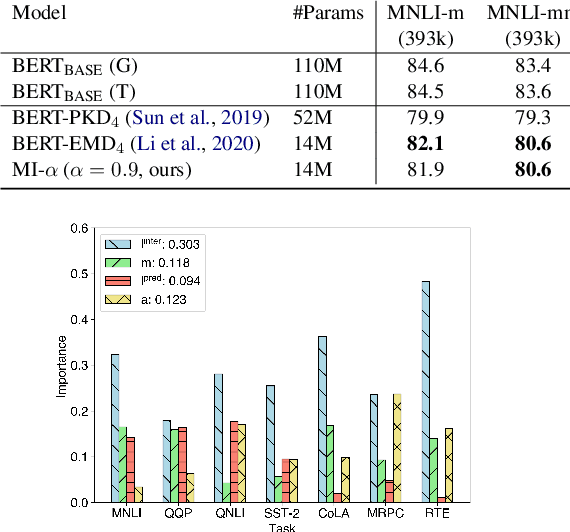
We aim to identify how different components in the KD pipeline affect the resulting performance and how much the optimal KD pipeline varies across different datasets/tasks, such as the data augmentation policy, the loss function, and the intermediate representation for transferring the knowledge between teacher and student. To tease apart their effects, we propose Distiller, a meta KD framework that systematically combines a broad range of techniques across different stages of the KD pipeline, which enables us to quantify each component's contribution. Within Distiller, we unify commonly used objectives for distillation of intermediate representations under a universal mutual information (MI) objective and propose a class of MI-$\alpha$ objective functions with better bias/variance trade-off for estimating the MI between the teacher and the student. On a diverse set of NLP datasets, the best Distiller configurations are identified via large-scale hyperparameter optimization. Our experiments reveal the following: 1) the approach used to distill the intermediate representations is the most important factor in KD performance, 2) among different objectives for intermediate distillation, MI-$\alpha$ performs the best, and 3) data augmentation provides a large boost for small training datasets or small student networks. Moreover, we find that different datasets/tasks prefer different KD algorithms, and thus propose a simple AutoDistiller algorithm that can recommend a good KD pipeline for a new dataset.