 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Deep Learning for Video Captioning
Apr 22, 2023



Video captioning (VC) is a fast-moving, cross-disciplinary area of research that bridges work in the fields of computer vision, natural language processing (NLP), linguistics, and human-computer interaction. In essence, VC involves understanding a video and describing it with language. Captioning is used in a host of applications from creating more accessible interfaces (e.g., low-vision navigation) to video question answering (V-QA), video retrieval and content generation. This survey covers deep learning-based VC, including but, not limited to, attention-based architectures, graph networks, reinforcement learning, adversarial networks, dense video captioning (DVC), and more. We discuss the datasets and evaluation metrics used in the field, and limitations, applications, challenges, and future directions for VC.
Aligning Text-to-Image Models using Human Feedback
Feb 23, 2023



Deep generative models have shown impressive results in text-to-image synthesis. However, current text-to-image models often generate images that are inadequately aligned with text prompts. We propose a fine-tuning method for aligning such models using human feedback, comprising three stages. First, we collect human feedback assessing model output alignment from a set of diverse text prompts. We then use the human-labeled image-text dataset to train a reward function that predicts human feedback. Lastly, the text-to-image model is fine-tuned by maximizing reward-weighted likelihood to improve image-text alignment. Our method generates objects with specified colors, counts and backgrounds more accurately than the pre-trained model. We also analyze several design choices and find that careful investigations on such design choices are important in balancing the alignment-fidelity tradeoffs. Our results demonstrate the potential for learning from human feedback to significantly improve text-to-image models.
Offline Reinforcement Learning for Mixture-of-Expert Dialogue Management
Feb 21, 2023Reinforcement learning (RL) has shown great promise for developing dialogue management (DM) agents that are non-myopic, conduct rich conversations, and maximize overall user satisfaction. Despite recent developments in RL and language models (LMs), using RL to power conversational chatbots remains challenging, in part because RL requires online exploration to learn effectively, whereas collecting novel human-bot interactions can be expensive and unsafe. This issue is exacerbated by the combinatorial action spaces facing these algorithms, as most LM agents generate responses at the word level. We develop a variety of RL algorithms, specialized to dialogue planning, that leverage recent Mixture-of-Expert Language Models (MoE-LMs) -- models that capture diverse semantics, generate utterances reflecting different intents, and are amenable for multi-turn DM. By exploiting MoE-LM structure, our methods significantly reduce the size of the action space and improve the efficacy of RL-based DM. We evaluate our methods in open-domain dialogue to demonstrate their effectiveness w.r.t.\ the diversity of intent in generated utterances and overall DM performance.
Multi-Task Off-Policy Learning from Bandit Feedback
Dec 09, 2022


Many practical applications, such as recommender systems and learning to rank, involve solving multiple similar tasks. One example is learning of recommendation policies for users with similar movie preferences, where the users may still rank the individual movies slightly differently. Such tasks can be organized in a hierarchy, where similar tasks are related through a shared structure. In this work, we formulate this problem as a contextual off-policy optimization in a hierarchical graphical model from logged bandit feedback. To solve the problem, we propose a hierarchical off-policy optimization algorithm (HierOPO), which estimates the parameters of the hierarchical model and then acts pessimistically with respect to them. We instantiate HierOPO in linear Gaussian models, for which we also provide an efficient implementation and analysis. We prove per-task bounds on the suboptimality of the learned policies, which show a clear improvement over not using the hierarchical model. We also evaluate the policies empirically. Our theoretical and empirical results show a clear advantage of using the hierarchy over solving each task independently.
Operator Splitting Value Iteration
Nov 25, 2022We introduce new planning and reinforcement learning algorithms for discounted MDPs that utilize an approximate model of the environment to accelerate the convergence of the value function. Inspired by the splitting approach in numerical linear algebra, we introduce Operator Splitting Value Iteration (OS-VI) for both Policy Evaluation and Control problems. OS-VI achieves a much faster convergence rate when the model is accurate enough. We also introduce a sample-based version of the algorithm called OS-Dyna. Unlike the traditional Dyna architecture, OS-Dyna still converges to the correct value function in presence of model approximation error.
RASR: Risk-Averse Soft-Robust MDPs with EVaR and Entropic Risk
Sep 14, 2022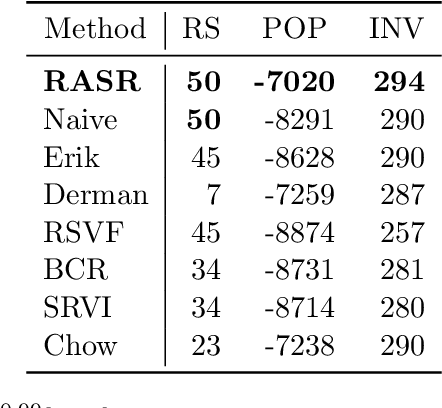

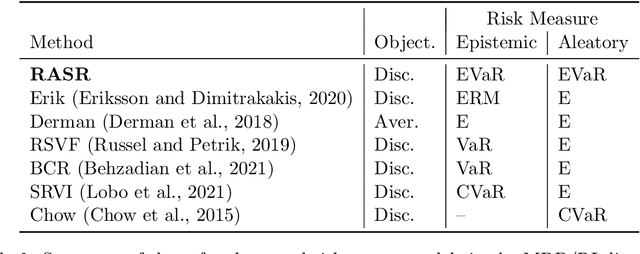
Prior work on safe Reinforcement Learning (RL) has studied risk-aversion to randomness in dynamics (aleatory) and to model uncertainty (epistemic) in isolation. We propose and analyze a new framework to jointly model the risk associated with epistemic and aleatory uncertainties in finite-horizon and discounted infinite-horizon MDPs. We call this framework that combines Risk-Averse and Soft-Robust methods RASR. We show that when the risk-aversion is defined using either EVaR or the entropic risk, the optimal policy in RASR can be computed efficiently using a new dynamic program formulation with a time-dependent risk level. As a result, the optimal risk-averse policies are deterministic but time-dependent, even in the infinite-horizon discounted setting. We also show that particular RASR objectives reduce to risk-averse RL with mean posterior transition probabilities. Our empirical results show that our new algorithms consistently mitigate uncertainty as measured by EVaR and other standard risk measures.
Robust Reinforcement Learning using Offline Data
Aug 10, 2022
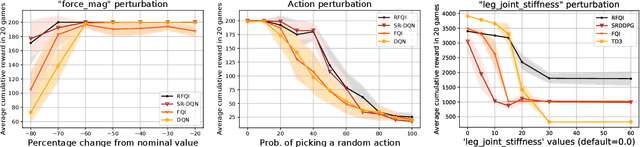
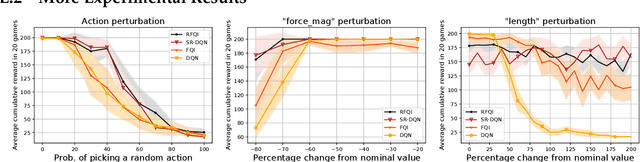
The goal of robust reinforcement learning (RL) is to learn a policy that is robust against the uncertainty in model parameters. Parameter uncertainty commonly occurs in many real-world RL applications due to simulator modeling errors, changes in the real-world system dynamics over time, and adversarial disturbances. Robust RL is typically formulated as a max-min problem, where the objective is to learn the policy that maximizes the value against the worst possible models that lie in an uncertainty set. In this work, we propose a robust RL algorithm called Robust Fitted Q-Iteration (RFQI), which uses only an offline dataset to learn the optimal robust policy. Robust RL with offline data is significantly more challenging than its non-robust counterpart because of the minimization over all models present in the robust Bellman operator. This poses challenges in offline data collection, optimization over the models, and unbiased estimation. In this work, we propose a systematic approach to overcome these challenges, resulting in our RFQI algorithm. We prove that RFQI learns a near-optimal robust policy under standard assumptions and demonstrate its superior performance on standard benchmark problems.
Reinforcement Learning of Multi-Domain Dialog Policies Via Action Embeddings
Jul 01, 2022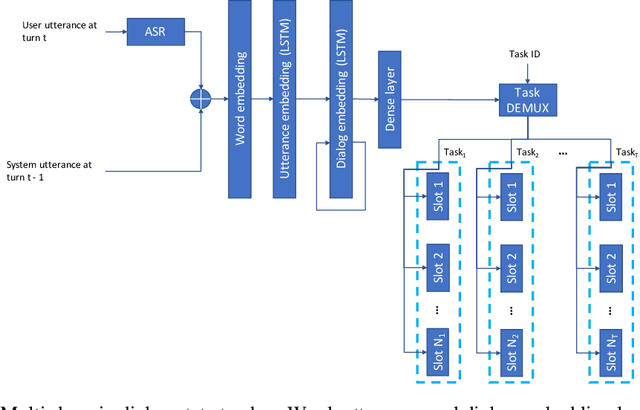
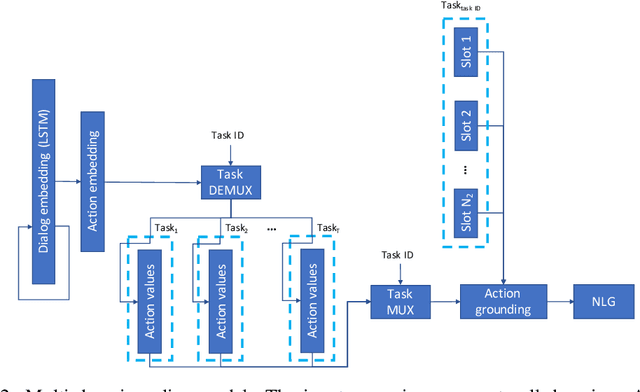
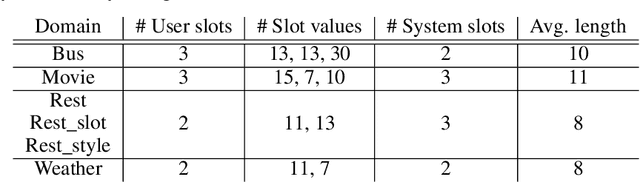
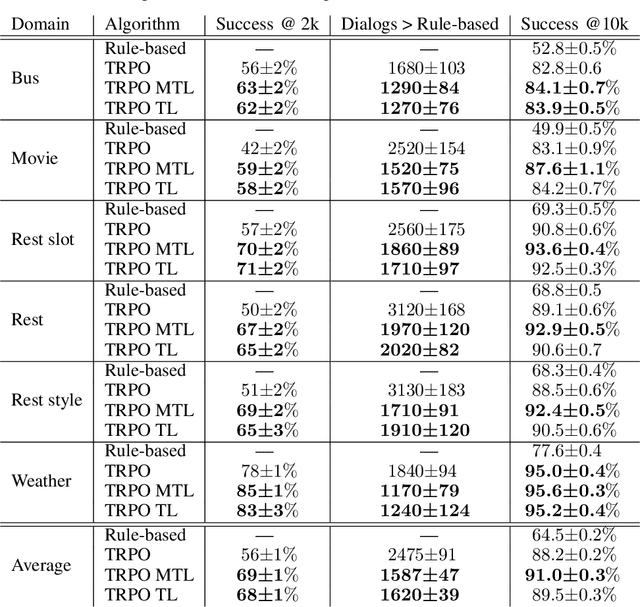
Learning task-oriented dialog policies via reinforcement learning typically requires large amounts of interaction with users, which in practice renders such methods unusable for real-world applications. In order to reduce the data requirements, we propose to leverage data from across different dialog domains, thereby reducing the amount of data required from each given domain. In particular, we propose to learn domain-agnostic action embeddings, which capture general-purpose structure that informs the system how to act given the current dialog context, and are then specialized to a specific domain. We show how this approach is capable of learning with significantly less interaction with users, with a reduction of 35% in the number of dialogs required to learn, and to a higher level of proficiency than training separate policies for each domain on a set of simulated domains.
A Mixture-of-Expert Approach to RL-based Dialogue Management
May 31, 2022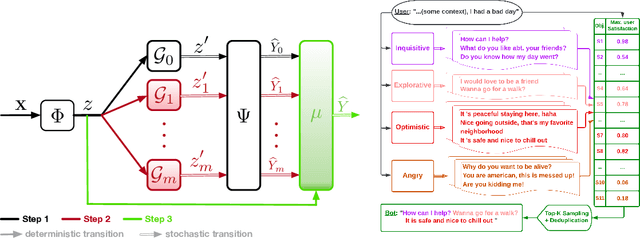

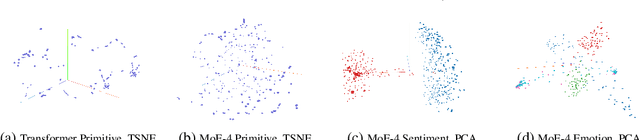

Despite recent advancements in language models (LMs), their application to dialogue management (DM) problems and ability to carry on rich conversations remain a challenge. We use reinforcement learning (RL) to develop a dialogue agent that avoids being short-sighted (outputting generic utterances) and maximizes overall user satisfaction. Most existing RL approaches to DM train the agent at the word-level, and thus, have to deal with a combinatorially complex action space even for a medium-size vocabulary. As a result, they struggle to produce a successful and engaging dialogue even if they are warm-started with a pre-trained LM. To address this issue, we develop a RL-based DM using a novel mixture of expert language model (MoE-LM) that consists of (i) a LM capable of learning diverse semantics for conversation histories, (ii) a number of {\em specialized} LMs (or experts) capable of generating utterances corresponding to a particular attribute or personality, and (iii) a RL-based DM that performs dialogue planning with the utterances generated by the experts. Our MoE approach provides greater flexibility to generate sensible utterances with different intents and allows RL to focus on conversational-level DM. We compare it with SOTA baselines on open-domain dialogues and demonstrate its effectiveness both in terms of the diversity and sensibility of the generated utterances and the overall DM performance.
Collaborative Multi-agent Stochastic Linear Bandits
May 12, 2022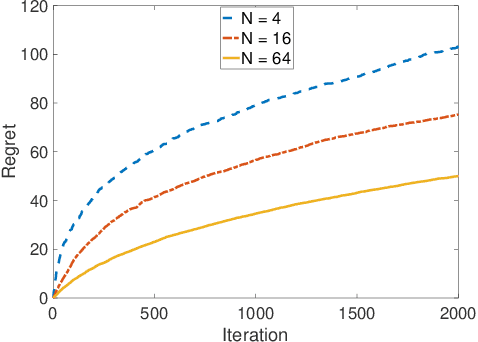
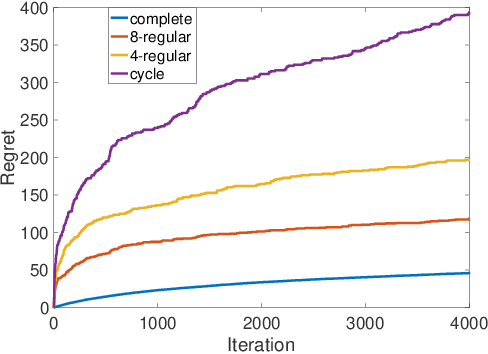
We study a collaborative multi-agent stochastic linear bandit setting, where $N$ agents that form a network communicate locally to minimize their overall regret. In this setting, each agent has its own linear bandit problem (its own reward parameter) and the goal is to select the best global action w.r.t. the average of their reward parameters. At each round, each agent proposes an action, and one action is randomly selected and played as the network action. All the agents observe the corresponding rewards of the played actions and use an accelerated consensus procedure to compute an estimate of the average of the rewards obtained by all the agents. We propose a distributed upper confidence bound (UCB) algorithm and prove a high probability bound on its $T$-round regret in which we include a linear growth of regret associated with each communication round. Our regret bound is of order $\mathcal{O}\Big(\sqrt{\frac{T}{N \log(1/|\lambda_2|)}}\cdot (\log T)^2\Big)$, where $\lambda_2$ is the second largest (in absolute value) eigenvalue of the communication matrix.