 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Poisoning Backdoor Attacks from a Statistical Perspective
Oct 18, 2023



The growing dependence on machine learning in real-world applications emphasizes the importance of understanding and ensuring its safety. Backdoor attacks pose a significant security risk due to their stealthy nature and potentially serious consequences. Such attacks involve embedding triggers within a learning model with the intention of causing malicious behavior when an active trigger is present while maintaining regular functionality without it. This paper evaluates the effectiveness of any backdoor attack incorporating a constant trigger, by establishing tight lower and upper boundaries for the performance of the compromised model on both clean and backdoor test data. The developed theory answers a series of fundamental but previously underexplored problems, including (1) what are the determining factors for a backdoor attack's success, (2) what is the direction of the most effective backdoor attack, and (3) when will a human-imperceptible trigger succeed. Our derived understanding applies to both discriminative and generative models. We also demonstrate the theory by conducting experiments using benchmark datasets and state-of-the-art backdoor attack scenarios.
Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning
Oct 16, 2023



Massive data is often considered essential for deep learning applications, but it also incurs significant computational and infrastructural costs. Therefore, dataset pruning (DP) has emerged as an effective way to improve data efficiency by identifying and removing redundant training samples without sacrificing performance. In this work, we aim to address the problem of DP for transfer learning, i.e., how to prune a source dataset for improved pretraining efficiency and lossless finetuning accuracy on downstream target tasks. To our best knowledge, the problem of DP for transfer learning remains open, as previous studies have primarily addressed DP and transfer learning as separate problems. By contrast, we establish a unified viewpoint to integrate DP with transfer learning and find that existing DP methods are not suitable for the transfer learning paradigm. We then propose two new DP methods, label mapping and feature mapping, for supervised and self-supervised pretraining settings respectively, by revisiting the DP problem through the lens of source-target domain mapping. Furthermore, we demonstrate the effectiveness of our approach on numerous transfer learning tasks. We show that source data classes can be pruned by up to 40% ~ 80% without sacrificing downstream performance, resulting in a significant 2 ~ 5 times speed-up during the pretraining stage. Besides, our proposal exhibits broad applicability and can improve other computationally intensive transfer learning techniques, such as adversarial pretraining. Codes are available at https://github.com/OPTML-Group/DP4TL.
A Bayesian Approach to Robust Inverse Reinforcement Learning
Sep 15, 2023We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
An Introduction to Bi-level Optimization: Foundations and Applications in Signal Processing and Machine Learning
Aug 03, 2023



Recently, bi-level optimization (BLO) has taken center stage in some very exciting developments in the area of signal processing (SP) and machine learning (ML). Roughly speaking, BLO is a classical optimization problem that involves two levels of hierarchy (i.e., upper and lower levels), wherein obtaining the solution to the upper-level problem requires solving the lower-level one. BLO has become popular largely because it is powerful in modeling problems in SP and ML, among others, that involve optimizing nested objective functions. Prominent applications of BLO range from resource allocation for wireless systems to adversarial machine learning. In this work, we focus on a class of tractable BLO problems that often appear in SP and ML applications. We provide an overview of some basic concepts of this class of BLO problems, such as their optimality conditions, standard algorithms (including their optimization principles and practical implementations), as well as how they can be leveraged to obtain state-of-the-art results for a number of key SP and ML applications. Further, we discuss some recent advances in BLO theory, its implications for applications, and point out some limitations of the state-of-the-art that require significant future research efforts. Overall, we hope that this article can serve to accelerate the adoption of BLO as a generic tool to model, analyze, and innovate on a wide array of emerging SP and ML applications.
Vcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens
May 07, 2023



Transformer models are foundational to natural language processing (NLP) and computer vision. Despite various recent works devoted to reducing the quadratic cost of such models (as a function of the sequence length $n$), dealing with ultra long sequences efficiently (e.g., with more than 16K tokens) remains challenging. Applications such as answering questions based on an entire book or summarizing a scientific article are inefficient or infeasible. In this paper, we propose to significantly reduce the dependency of a Transformer model's complexity on $n$, by compressing the input into a representation whose size $r$ is independent of $n$ at each layer. Specifically, by exploiting the fact that in many tasks, only a small subset of special tokens (we call VIP-tokens) are most relevant to the final prediction, we propose a VIP-token centric compression (Vcc) scheme which selectively compresses the input sequence based on their impact on approximating the representation of these VIP-tokens. Compared with competitive baselines, the proposed algorithm not only is efficient (achieving more than $3\times$ efficiency improvement compared to baselines on 4K and 16K lengths), but also achieves competitive or better performance on a large number of tasks. Further, we show that our algorithm can be scaled to 128K tokens (or more) while consistently offering accuracy improvement.
GLASU: A Communication-Efficient Algorithm for Federated Learning with Vertically Distributed Graph Data
Mar 16, 2023Vertical federated learning (VFL) is a distributed learning paradigm, where computing clients collectively train a model based on the partial features of the same set of samples they possess. Current research on VFL focuses on the case when samples are independent, but it rarely addresses an emerging scenario when samples are interrelated through a graph. For graph-structured data, graph neural networks (GNNs) are competitive machine learning models, but a naive implementation in the VFL setting causes a significant communication overhead. Moreover, the analysis of the training is faced with a challenge caused by the biased stochastic gradients. In this paper, we propose a model splitting method that splits a backbone GNN across the clients and the server and a communication-efficient algorithm, GLASU, to train such a model. GLASU adopts lazy aggregation and stale updates to skip aggregation when evaluating the model and skip feature exchanges during training, greatly reducing communication. We offer a theoretical analysis and conduct extensive numerical experiments on real-world datasets, showing that the proposed algorithm effectively trains a GNN model, whose performance matches that of the backbone GNN when trained in a centralized manner.
What Is Missing in IRM Training and Evaluation? Challenges and Solutions
Mar 04, 2023



Invariant risk minimization (IRM) has received increasing attention as a way to acquire environment-agnostic data representations and predictions, and as a principled solution for preventing spurious correlations from being learned and for improving models' out-of-distribution generalization. Yet, recent works have found that the optimality of the originally-proposed IRM optimization (IRM) may be compromised in practice or could be impossible to achieve in some scenarios. Therefore, a series of advanced IRM algorithms have been developed that show practical improvement over IRM. In this work, we revisit these recent IRM advancements, and identify and resolve three practical limitations in IRM training and evaluation. First, we find that the effect of batch size during training has been chronically overlooked in previous studies, leaving room for further improvement. We propose small-batch training and highlight the improvements over a set of large-batch optimization techniques. Second, we find that improper selection of evaluation environments could give a false sense of invariance for IRM. To alleviate this effect, we leverage diversified test-time environments to precisely characterize the invariance of IRM when applied in practice. Third, we revisit (Ahuja et al. (2020))'s proposal to convert IRM into an ensemble game and identify a limitation when a single invariant predictor is desired instead of an ensemble of individual predictors. We propose a new IRM variant to address this limitation based on a novel viewpoint of ensemble IRM games as consensus-constrained bi-level optimization. Lastly, we conduct extensive experiments (covering 7 existing IRM variants and 7 datasets) to justify the practical significance of revisiting IRM training and evaluation in a principled manner.
Understanding Expertise through Demonstrations: A Maximum Likelihood Framework for Offline Inverse Reinforcement Learning
Feb 15, 2023



Offline inverse reinforcement learning (Offline IRL) aims to recover the structure of rewards and environment dynamics that underlie observed actions in a fixed, finite set of demonstrations from an expert agent. Accurate models of expertise in executing a task has applications in safety-sensitive applications such as clinical decision making and autonomous driving. However, the structure of an expert's preferences implicit in observed actions is closely linked to the expert's model of the environment dynamics (i.e. the ``world''). Thus, inaccurate models of the world obtained from finite data with limited coverage could compound inaccuracy in estimated rewards. To address this issue, we propose a bi-level optimization formulation of the estimation task wherein the upper level is likelihood maximization based upon a conservative model of the expert's policy (lower level). The policy model is conservative in that it maximizes reward subject to a penalty that is increasing in the uncertainty of the estimated model of the world. We propose a new algorithmic framework to solve the bi-level optimization problem formulation and provide statistical and computational guarantees of performance for the associated reward estimator. Finally, we demonstrate that the proposed algorithm outperforms the state-of-the-art offline IRL and imitation learning benchmarks by a large margin, over the continuous control tasks in MuJoCo and different datasets in the D4RL benchmark.
On the Robustness of deep learning-based MRI Reconstruction to image transformations
Nov 21, 2022



Although deep learning (DL) has received much attention in accelerated magnetic resonance imaging (MRI), recent studies show that tiny input perturbations may lead to instabilities of DL-based MRI reconstruction models. However, the approaches of robustifying these models are underdeveloped. Compared to image classification, it could be much more challenging to achieve a robust MRI image reconstruction network considering its regression-based learning objective, limited amount of training data, and lack of efficient robustness metrics. To circumvent the above limitations, our work revisits the problem of DL-based image reconstruction through the lens of robust machine learning. We find a new instability source of MRI image reconstruction, i.e., the lack of reconstruction robustness against spatial transformations of an input, e.g., rotation and cutout. Inspired by this new robustness metric, we develop a robustness-aware image reconstruction method that can defend against both pixel-wise adversarial perturbations as well as spatial transformations. Extensive experiments are also conducted to demonstrate the effectiveness of our proposed approaches.
Advancing Model Pruning via Bi-level Optimization
Oct 12, 2022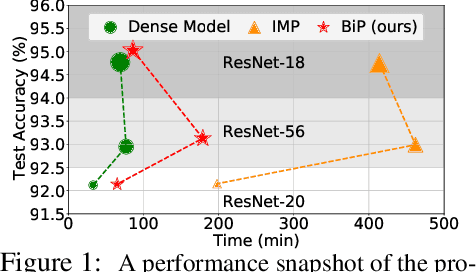
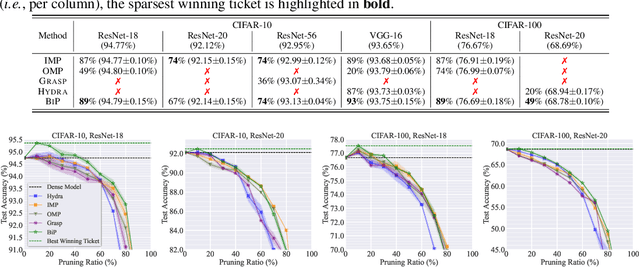
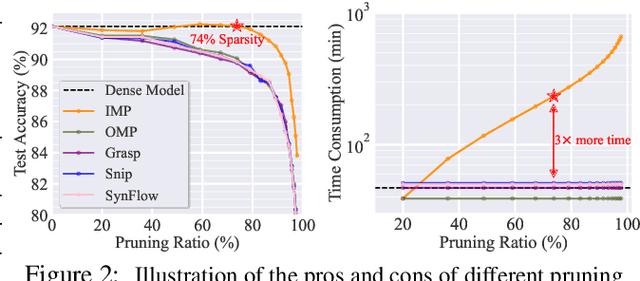
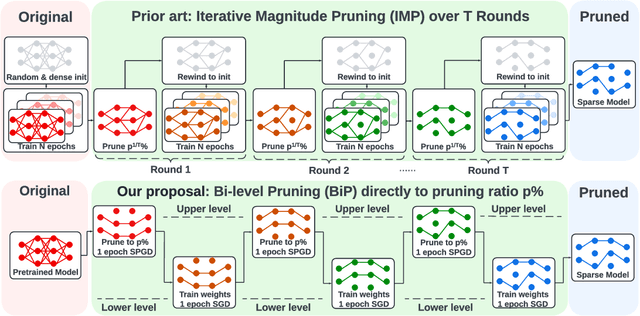
The deployment constraints in practical applications necessitate the pruning of large-scale deep learning models, i.e., promoting their weight sparsity. As illustrated by the Lottery Ticket Hypothesis (LTH), pruning also has the potential of improving their generalization ability. At the core of LTH, iterative magnitude pruning (IMP) is the predominant pruning method to successfully find 'winning tickets'. Yet, the computation cost of IMP grows prohibitively as the targeted pruning ratio increases. To reduce the computation overhead, various efficient 'one-shot' pruning methods have been developed, but these schemes are usually unable to find winning tickets as good as IMP. This raises the question of how to close the gap between pruning accuracy and pruning efficiency? To tackle it, we pursue the algorithmic advancement of model pruning. Specifically, we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BiP) is a special class of BLO problems with a bi-linear problem structure. By leveraging such bi-linearity, we theoretically show that BiP can be solved as easily as first-order optimization, thus inheriting the computation efficiency. Through extensive experiments on both structured and unstructured pruning with 5 model architectures and 4 data sets, we demonstrate that BiP can find better winning tickets than IMP in most cases, and is computationally as efficient as the one-shot pruning schemes, demonstrating 2-7 times speedup over IMP for the same level of model accuracy and sparsity.