 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepGraph: Towards Any Structural Pruning
Jan 30, 2023Structural pruning enables model acceleration by removing structurally-grouped parameters from neural networks. However, the parameter-grouping patterns vary widely across different models, making architecture-specific pruners, which rely on manually-designed grouping schemes, non-generalizable to new architectures. In this work, we study a highly-challenging yet barely-explored task, any structural pruning, to tackle general structural pruning of arbitrary architecture like CNNs, RNNs, GNNs and Transformers. The most prominent obstacle towards this ambitious goal lies in the structural coupling, which not only forces different layers to be pruned simultaneously, but also expects all parameters in a removed group to be consistently unimportant, thereby avoiding significant performance degradation after pruning. To address this problem, we propose a general and fully automatic method, Dependency Graph (DepGraph), to explicitly model the inter-dependency between layers and comprehensively group coupled parameters. In this work, we extensively evaluate our method on several architectures and tasks, including ResNe(X)t, DenseNet, MobileNet and Vision transformer for images, GAT for graph, DGCNN for 3D point cloud, alongside LSTM for language, and demonstrate that, even with a simple L1 norm criterion, the proposed method consistently yields gratifying performances.
Recent advances in artificial intelligence for retrosynthesis
Jan 14, 2023



Retrosynthesis is the cornerstone of organic chemistry, providing chemists in material and drug manufacturing access to poorly available and brand-new molecules. Conventional rule-based or expert-based computer-aided synthesis has obvious limitations, such as high labor costs and limited search space. In recent years, dramatic breakthroughs driven by artificial intelligence have revolutionized retrosynthesis. Here we aim to present a comprehensive review of recent advances in AI-based retrosynthesis. For single-step and multi-step retrosynthesis both, we first list their goal and provide a thorough taxonomy of existing methods. Afterwards, we analyze these methods in terms of their mechanism and performance, and introduce popular evaluation metrics for them, in which we also provide a detailed comparison among representative methods on several public datasets. In the next part we introduce popular databases and established platforms for retrosynthesis. Finally, this review concludes with a discussion about promising research directions in this field.
Is ProtoPNet Really Explainable? Evaluating and Improving the Interpretability of Prototypes
Dec 12, 2022ProtoPNet and its follow-up variants (ProtoPNets) have attracted broad research interest for their intrinsic interpretability from prototypes and comparable accuracy to non-interpretable counterparts. However, it has been recently found that the interpretability of prototypes can be corrupted due to the semantic gap between similarity in latent space and that in input space. In this work, we make the first attempt to quantitatively evaluate the interpretability of prototype-based explanations, rather than solely qualitative evaluations by some visualization examples, which can be easily misled by cherry picks. To this end, we propose two evaluation metrics, termed consistency score and stability score, to evaluate the explanation consistency cross images and the explanation robustness against perturbations, both of which are essential for explanations taken into practice. Furthermore, we propose a shallow-deep feature alignment (SDFA) module and a score aggregation (SA) module to improve the interpretability of prototypes. We conduct systematical evaluation experiments and substantial discussions to uncover the interpretability of existing ProtoPNets. Experiments demonstrate that our method achieves significantly superior performance to the state-of-the-arts, under both the conventional qualitative evaluations and the proposed quantitative evaluations, in both accuracy and interpretability. Codes are available at https://github.com/hqhQAQ/EvalProtoPNet.
SASFormer: Transformers for Sparsely Annotated Semantic Segmentation
Dec 06, 2022



Semantic segmentation based on sparse annotation has advanced in recent years. It labels only part of each object in the image, leaving the remainder unlabeled. Most of the existing approaches are time-consuming and often necessitate a multi-stage training strategy. In this work, we propose a simple yet effective sparse annotated semantic segmentation framework based on segformer, dubbed SASFormer, that achieves remarkable performance. Specifically, the framework first generates hierarchical patch attention maps, which are then multiplied by the network predictions to produce correlated regions separated by valid labels. Besides, we also introduce the affinity loss to ensure consistency between the features of correlation results and network predictions. Extensive experiments showcase that our proposed approach is superior to existing methods and achieves cutting-edge performance. The source code is available at \url{https://github.com/su-hui-zz/SASFormer}.
Conservative-Progressive Collaborative Learning for Semi-supervised Semantic Segmentation
Nov 30, 2022Pseudo supervision is regarded as the core idea in semi-supervised learning for semantic segmentation, and there is always a tradeoff between utilizing only the high-quality pseudo labels and leveraging all the pseudo labels. Addressing that, we propose a novel learning approach, called Conservative-Progressive Collaborative Learning (CPCL), among which two predictive networks are trained in parallel, and the pseudo supervision is implemented based on both the agreement and disagreement of the two predictions. One network seeks common ground via intersection supervision and is supervised by the high-quality labels to ensure a more reliable supervision, while the other network reserves differences via union supervision and is supervised by all the pseudo labels to keep exploring with curiosity. Thus, the collaboration of conservative evolution and progressive exploration can be achieved. To reduce the influences of the suspicious pseudo labels, the loss is dynamic re-weighted according to the prediction confidence. Extensive experiments demonstrate that CPCL achieves state-of-the-art performance for semi-supervised semantic segmentation.
Contrastive Identity-Aware Learning for Multi-Agent Value Decomposition
Nov 23, 2022



Value Decomposition (VD) aims to deduce the contributions of agents for decentralized policies in the presence of only global rewards, and has recently emerged as a powerful credit assignment paradigm for tackling cooperative Multi-Agent Reinforcement Learning (MARL) problems. One of the main challenges in VD is to promote diverse behaviors among agents, while existing methods directly encourage the diversity of learned agent networks with various strategies. However, we argue that these dedicated designs for agent networks are still limited by the indistinguishable VD network, leading to homogeneous agent behaviors and thus downgrading the cooperation capability. In this paper, we propose a novel Contrastive Identity-Aware learning (CIA) method, explicitly boosting the credit-level distinguishability of the VD network to break the bottleneck of multi-agent diversity. Specifically, our approach leverages contrastive learning to maximize the mutual information between the temporal credits and identity representations of different agents, encouraging the full expressiveness of credit assignment and further the emergence of individualities. The algorithm implementation of the proposed CIA module is simple yet effective that can be readily incorporated into various VD architectures. Experiments on the SMAC benchmarks and across different VD backbones demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code is available at https://github.com/liushunyu/CIA.
A Survey on Explainable Reinforcement Learning: Concepts, Algorithms, Challenges
Nov 15, 2022Reinforcement Learning (RL) is a popular machine learning paradigm where intelligent agents interact with the environment to fulfill a long-term goal. Driven by the resurgence of deep learning, Deep RL (DRL) has witnessed great success over a wide spectrum of complex control tasks. Despite the encouraging results achieved, the deep neural network-based backbone is widely deemed as a black box that impedes practitioners to trust and employ trained agents in realistic scenarios where high security and reliability are essential. To alleviate this issue, a large volume of literature devoted to shedding light on the inner workings of the intelligent agents has been proposed, by constructing intrinsic interpretability or post-hoc explainability. In this survey, we provide a comprehensive review of existing works on eXplainable RL (XRL) and introduce a new taxonomy where prior works are clearly categorized into model-explaining, reward-explaining, state-explaining, and task-explaining methods. We also review and highlight RL methods that conversely leverage human knowledge to promote learning efficiency and final performance of agents while this kind of method is often ignored in XRL field. Some open challenges and opportunities in XRL are discussed. This survey intends to provide a high-level summarization and better understanding of XRL and to motivate future research on more effective XRL solutions. Corresponding open source codes are collected and categorized at https://github.com/Plankson/awesome-explainable-reinforcement-learning.
Attention Diversification for Domain Generalization
Oct 09, 2022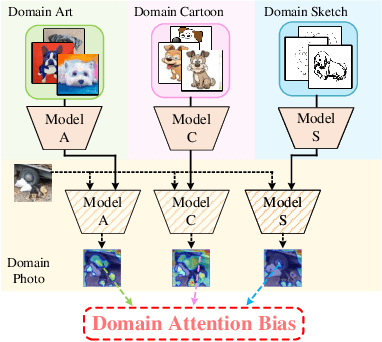
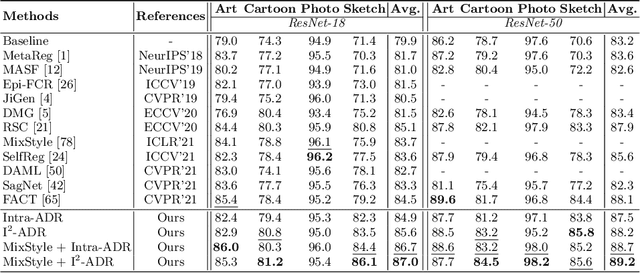
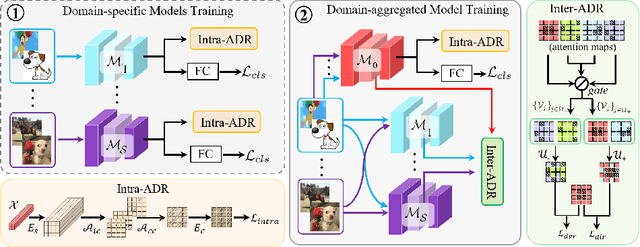
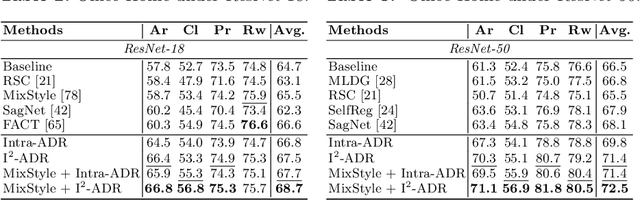
Convolutional neural networks (CNNs) have demonstrated gratifying results at learning discriminative features. However, when applied to unseen domains, state-of-the-art models are usually prone to errors due to domain shift. After investigating this issue from the perspective of shortcut learning, we find the devils lie in the fact that models trained on different domains merely bias to different domain-specific features yet overlook diverse task-related features. Under this guidance, a novel Attention Diversification framework is proposed, in which Intra-Model and Inter-Model Attention Diversification Regularization are collaborated to reassign appropriate attention to diverse task-related features. Briefly, Intra-Model Attention Diversification Regularization is equipped on the high-level feature maps to achieve in-channel discrimination and cross-channel diversification via forcing different channels to pay their most salient attention to different spatial locations. Besides, Inter-Model Attention Diversification Regularization is proposed to further provide task-related attention diversification and domain-related attention suppression, which is a paradigm of "simulate, divide and assemble": simulate domain shift via exploiting multiple domain-specific models, divide attention maps into task-related and domain-related groups, and assemble them within each group respectively to execute regularization. Extensive experiments and analyses are conducted on various benchmarks to demonstrate that our method achieves state-of-the-art performance over other competing methods. Code is available at https://github.com/hikvision-research/DomainGeneralization.
* ECCV 2022. Code available at https://github.com/hikvision-research/DomainGeneralization
A Survey of Neural Trees
Sep 07, 2022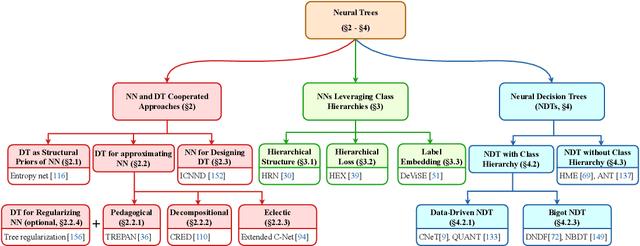
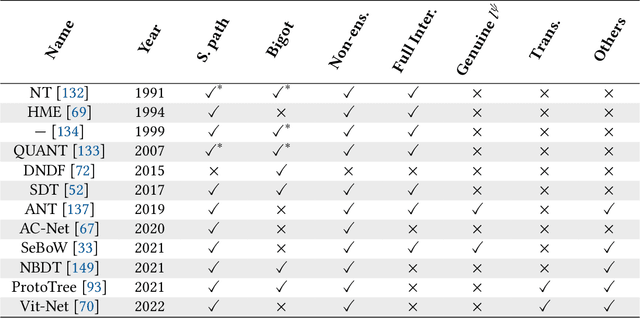
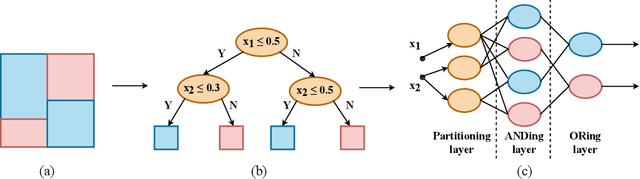
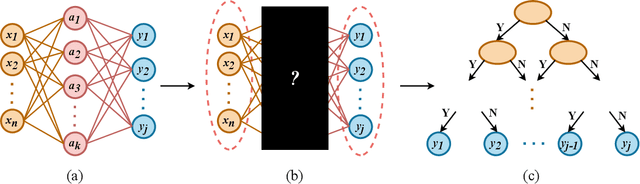
Neural networks (NNs) and decision trees (DTs) are both popular models of machine learning, yet coming with mutually exclusive advantages and limitations. To bring the best of the two worlds, a variety of approaches are proposed to integrate NNs and DTs explicitly or implicitly. In this survey, these approaches are organized in a school which we term as neural trees (NTs). This survey aims to present a comprehensive review of NTs and attempts to identify how they enhance the model interpretability. We first propose a thorough taxonomy of NTs that expresses the gradual integration and co-evolution of NNs and DTs. Afterward, we analyze NTs in terms of their interpretability and performance, and suggest possible solutions to the remaining challenges. Finally, this survey concludes with a discussion about other considerations like conditional computation and promising directions towards this field. A list of papers reviewed in this survey, along with their corresponding codes, is available at: https://github.com/zju-vipa/awesome-neural-trees
ProtoPFormer: Concentrating on Prototypical Parts in Vision Transformers for Interpretable Image Recognition
Aug 22, 2022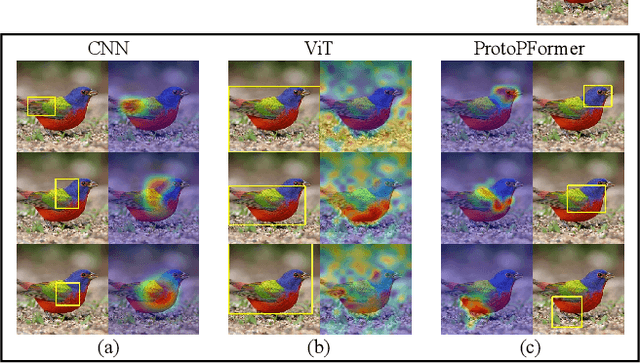
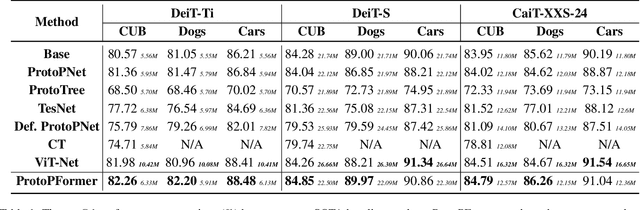
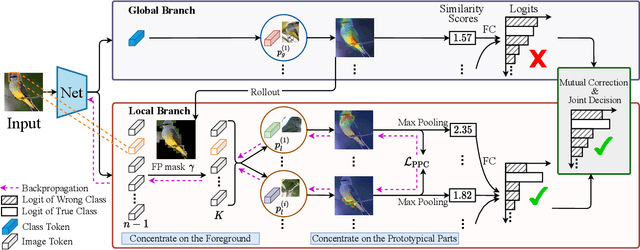
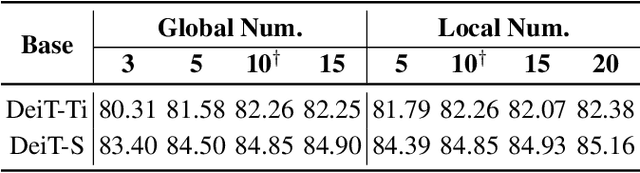
Prototypical part network (ProtoPNet) has drawn wide attention and boosted many follow-up studies due to its self-explanatory property for explainable artificial intelligence (XAI). However, when directly applying ProtoPNet on vision transformer (ViT) backbones, learned prototypes have a ''distraction'' problem: they have a relatively high probability of being activated by the background and pay less attention to the foreground. The powerful capability of modeling long-term dependency makes the transformer-based ProtoPNet hard to focus on prototypical parts, thus severely impairing its inherent interpretability. This paper proposes prototypical part transformer (ProtoPFormer) for appropriately and effectively applying the prototype-based method with ViTs for interpretable image recognition. The proposed method introduces global and local prototypes for capturing and highlighting the representative holistic and partial features of targets according to the architectural characteristics of ViTs. The global prototypes are adopted to provide the global view of objects to guide local prototypes to concentrate on the foreground while eliminating the influence of the background. Afterwards, local prototypes are explicitly supervised to concentrate on their respective prototypical visual parts, increasing the overall interpretability. Extensive experiments demonstrate that our proposed global and local prototypes can mutually correct each other and jointly make final decisions, which faithfully and transparently reason the decision-making processes associatively from the whole and local perspectives, respectively. Moreover, ProtoPFormer consistently achieves superior performance and visualization results over the state-of-the-art (SOTA) prototype-based baselines. Our code has been released at https://github.com/zju-vipa/ProtoPFormer.