 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Adapter for Face Recognition in the Wild
Dec 04, 2023



In this paper, we tackle the challenge of face recognition in the wild, where images often suffer from low quality and real-world distortions. Traditional heuristic approaches-either training models directly on these degraded images or their enhanced counterparts using face restoration techniques-have proven ineffective, primarily due to the degradation of facial features and the discrepancy in image domains. To overcome these issues, we propose an effective adapter for augmenting existing face recognition models trained on high-quality facial datasets. The key of our adapter is to process both the unrefined and the enhanced images by two similar structures where one is fixed and the other trainable. Such design can confer two benefits. First, the dual-input system minimizes the domain gap while providing varied perspectives for the face recognition model, where the enhanced image can be regarded as a complex non-linear transformation of the original one by the restoration model. Second, both two similar structures can be initialized by the pre-trained models without dropping the past knowledge. The extensive experiments in zero-shot settings show the effectiveness of our method by surpassing baselines of about 3%, 4%, and 7% in three datasets. Our code will be publicly available at https://github.com/liuyunhaozz/FaceAdapter/.
UniGS: Unified Representation for Image Generation and Segmentation
Dec 04, 2023



This paper introduces a novel unified representation of diffusion models for image generation and segmentation. Specifically, we use a colormap to represent entity-level masks, addressing the challenge of varying entity numbers while aligning the representation closely with the image RGB domain. Two novel modules, including the location-aware color palette and progressive dichotomy module, are proposed to support our mask representation. On the one hand, a location-aware palette guarantees the colors' consistency to entities' locations. On the other hand, the progressive dichotomy module can efficiently decode the synthesized colormap to high-quality entity-level masks in a depth-first binary search without knowing the cluster numbers. To tackle the issue of lacking large-scale segmentation training data, we employ an inpainting pipeline and then improve the flexibility of diffusion models across various tasks, including inpainting, image synthesis, referring segmentation, and entity segmentation. Comprehensive experiments validate the efficiency of our approach, demonstrating comparable segmentation mask quality to state-of-the-art and adaptability to multiple tasks. The code will be released at \href{https://github.com/qqlu/Entity}{https://github.com/qqlu/Entity}.
Dynamic Erasing Network Based on Multi-Scale Temporal Features for Weakly Supervised Video Anomaly Detection
Dec 04, 2023



The goal of weakly supervised video anomaly detection is to learn a detection model using only video-level labeled data. However, prior studies typically divide videos into fixed-length segments without considering the complexity or duration of anomalies. Moreover, these studies usually just detect the most abnormal segments, potentially overlooking the completeness of anomalies. To address these limitations, we propose a Dynamic Erasing Network (DE-Net) for weakly supervised video anomaly detection, which learns multi-scale temporal features. Specifically, to handle duration variations of abnormal events, we first propose a multi-scale temporal modeling module, capable of extracting features from segments of varying lengths and capturing both local and global visual information across different temporal scales. Then, we design a dynamic erasing strategy, which dynamically assesses the completeness of the detected anomalies and erases prominent abnormal segments in order to encourage the model to discover gentle abnormal segments in a video. The proposed method obtains favorable performance compared to several state-of-the-art approaches on three datasets: XD-Violence, TAD, and UCF-Crime. Code will be made available at https://github.com/ArielZc/DE-Net.
Exploiting Diffusion Prior for Generalizable Pixel-Level Semantic Prediction
Nov 30, 2023



Contents generated by recent advanced Text-to-Image (T2I) diffusion models are sometimes too imaginative for existing off-the-shelf property semantic predictors to estimate due to the immitigable domain gap. We introduce DMP, a pipeline utilizing pre-trained T2I models as a prior for pixel-level semantic prediction tasks. To address the misalignment between deterministic prediction tasks and stochastic T2I models, we reformulate the diffusion process through a sequence of interpolations, establishing a deterministic mapping between input RGB images and output prediction distributions. To preserve generalizability, we use low-rank adaptation to fine-tune pre-trained models. Extensive experiments across five tasks, including 3D property estimation, semantic segmentation, and intrinsic image decomposition, showcase the efficacy of the proposed method. Despite limited-domain training data, the approach yields faithful estimations for arbitrary images, surpassing existing state-of-the-art algorithms.
Text-Driven Image Editing via Learnable Regions
Nov 28, 2023Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pretrained text-to-image model and introduces a bounding box generator to find the edit regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences or long paragraphs. We conduct an extensive user study to compare our method against state-of-the-art methods. Experiments demonstrate the competitive performance of our method in manipulating images with high fidelity and realism that align with the language descriptions provided. Our project webpage: https://yuanze-lin.me/LearnableRegions_page.
Telling Left from Right: Identifying Geometry-Aware Semantic Correspondence
Nov 28, 2023



While pre-trained large-scale vision models have shown significant promise for semantic correspondence, their features often struggle to grasp the geometry and orientation of instances. This paper identifies the importance of being geometry-aware for semantic correspondence and reveals a limitation of the features of current foundation models under simple post-processing. We show that incorporating this information can markedly enhance semantic correspondence performance with simple but effective solutions in both zero-shot and supervised settings. We also construct a new challenging benchmark for semantic correspondence built from an existing animal pose estimation dataset, for both pre-training validating models. Our method achieves a PCK@0.10 score of 64.2 (zero-shot) and 85.6 (supervised) on the challenging SPair-71k dataset, outperforming the state-of-the-art by 4.3p and 11.0p absolute gains, respectively. Our code and datasets will be publicly available.
Pyramid Diffusion for Fine 3D Large Scene Generation
Nov 20, 2023
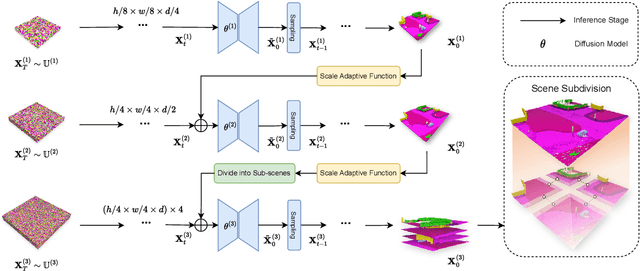
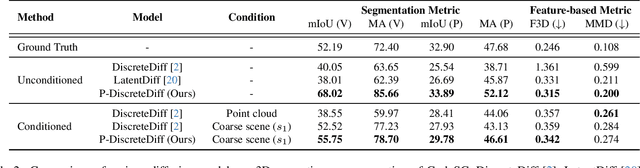

Directly transferring the 2D techniques to 3D scene generation is challenging due to significant resolution reduction and the scarcity of comprehensive real-world 3D scene datasets. To address these issues, our work introduces the Pyramid Discrete Diffusion model (PDD) for 3D scene generation. This novel approach employs a multi-scale model capable of progressively generating high-quality 3D scenes from coarse to fine. In this way, the PDD can generate high-quality scenes within limited resource constraints and does not require additional data sources. To the best of our knowledge, we are the first to adopt the simple but effective coarse-to-fine strategy for 3D large scene generation. Our experiments, covering both unconditional and conditional generation, have yielded impressive results, showcasing the model's effectiveness and robustness in generating realistic and detailed 3D scenes. Our code will be available to the public.
GLaMM: Pixel Grounding Large Multimodal Model
Nov 06, 2023



Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial efforts towards LMMs used holistic images and text prompts to generate ungrounded textual responses. Very recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring a single object category at a time, require users to specify the regions in inputs, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of generating visually grounded detailed conversations, we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed Grounded Conversation Generation (GCG) task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks e.g., referring expression segmentation, image and region-level captioning and vision-language conversations. Project Page: https://mbzuai-oryx.github.io/groundingLMM.
Rethinking Evaluation Metrics of Open-Vocabulary Segmentaion
Nov 06, 2023



In this paper, we highlight a problem of evaluation metrics adopted in the open-vocabulary segmentation. That is, the evaluation process still heavily relies on closed-set metrics on zero-shot or cross-dataset pipelines without considering the similarity between predicted and ground truth categories. To tackle this issue, we first survey eleven similarity measurements between two categorical words using WordNet linguistics statistics, text embedding, and language models by comprehensive quantitative analysis and user study. Built upon those explored measurements, we designed novel evaluation metrics, namely Open mIoU, Open AP, and Open PQ, tailored for three open-vocabulary segmentation tasks. We benchmarked the proposed evaluation metrics on 12 open-vocabulary methods of three segmentation tasks. Even though the relative subjectivity of similarity distance, we demonstrate that our metrics can still well evaluate the open ability of the existing open-vocabulary segmentation methods. We hope that our work can bring with the community new thinking about how to evaluate the open ability of models. The evaluation code is released in github.
One-for-All: Towards Universal Domain Translation with a Single StyleGAN
Oct 22, 2023



In this paper, we propose a novel translation model, UniTranslator, for transforming representations between visually distinct domains under conditions of limited training data and significant visual differences. The main idea behind our approach is leveraging the domain-neutral capabilities of CLIP as a bridging mechanism, while utilizing a separate module to extract abstract, domain-agnostic semantics from the embeddings of both the source and target realms. Fusing these abstract semantics with target-specific semantics results in a transformed embedding within the CLIP space. To bridge the gap between the disparate worlds of CLIP and StyleGAN, we introduce a new non-linear mapper, the CLIP2P mapper. Utilizing CLIP embeddings, this module is tailored to approximate the latent distribution in the P space, effectively acting as a connector between these two spaces. The proposed UniTranslator is versatile and capable of performing various tasks, including style mixing, stylization, and translations, even in visually challenging scenarios across different visual domains. Notably, UniTranslator generates high-quality translations that showcase domain relevance, diversity, and improved image quality. UniTranslator surpasses the performance of existing general-purpose models and performs well against specialized models in representative tasks. The source code and trained models will be released to the public.