 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluid Antenna Systems under Channel Uncertainty and Hardware Impairments: Trends, Challenges, and Future Research Directions
Jan 30, 2026Fluid antenna systems (FAS) have recently emerged as a promising paradigm for achieving spatially reconfigurable, compact, and energy-efficient wireless communications in beyond fifth-generation (B5G) and sixth-generation (6G) networks. By dynamically repositioning a liquid-based radiating element within a confined physical structure, FAS can exploit spatial diversity without relying on multiple fixed antenna elements. This spatial mobility provides a new degree of freedom for mitigating channel fading and interference, while maintaining low hardware complexity and power consumption. However, the performance of FAS in realistic deployments is strongly affected by channel uncertainty, hardware nonidealities, and mechanical constraints, all of which can substantially deviate from idealized analytical assumptions. This paper presents a comprehensive survey of the operation and design of FAS under such practical considerations. Key aspects include the characterization of spatio-temporal channel uncertainty, analysis of hardware and mechanical impairments such as RF nonlinearity, port coupling, and fluid response delay, as well as the exploration of robust design and learning-based control strategies to enhance system reliability. Finally, open research directions are identified, aiming to guide future developments toward robust, adaptive, and cross-domain FAS design for next-generation wireless networks.
RISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
Nov 06, 2025Most text-to-video(T2V) diffusion models depend on pre-trained text encoders for semantic alignment, yet they often fail to maintain video quality when provided with concise prompts rather than well-designed ones. The primary issue lies in their limited textual semantics understanding. Moreover, these text encoders cannot rephrase prompts online to better align with user intentions, which limits both the scalability and usability of the models, To address these challenges, we introduce RISE-T2V, which uniquely integrates the processes of prompt rephrasing and semantic feature extraction into a single and seamless step instead of two separate steps. RISE-T2V is universal and can be applied to various pre-trained LLMs and video diffusion models(VDMs), significantly enhancing their capabilities for T2V tasks. We propose an innovative module called the Rephrasing Adapter, enabling diffusion models to utilize text hidden states during the next token prediction of the LLM as a condition for video generation. By employing a Rephrasing Adapter, the video generation model can implicitly rephrase basic prompts into more comprehensive representations that better match the user's intent. Furthermore, we leverage the powerful capabilities of LLMs to enable video generation models to accomplish a broader range of T2V tasks. Extensive experiments demonstrate that RISE-T2V is a versatile framework applicable to different video diffusion model architectures, significantly enhancing the ability of T2V models to generate high-quality videos that align with user intent. Visual results are available on the webpage at https://rise-t2v.github.io.
Resource Allocation for Pinching-Antenna Systems: State-of-the-Art, Key Techniques and Open Issues
Jun 06, 2025Pinching antennas have emerged as a promising technology for reconfiguring wireless propagation environments, particularly in high-frequency communication systems operating in the millimeter-wave and terahertz bands. By enabling dynamic activation at arbitrary positions along a dielectric waveguide, pinching antennas offer unprecedented channel reconfigurability and the ability to provide line-of-sight (LoS) links in scenarios with severe LoS blockages. The performance of pinching-antenna systems is highly dependent on the optimized placement of the pinching antennas, which must be jointly considered with traditional resource allocation (RA) variables -- including transmission power, time slots, and subcarriers. The resulting joint RA problems are typically non-convex with complex variable coupling, necessitating sophisticated optimization techniques. This article provides a comprehensive survey of existing RA algorithms designed for pinching-antenna systems, supported by numerical case studies that demonstrate their potential performance gains. Key challenges and open research problems are also identified to guide future developments in this emerging field.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025



Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
Energy-Efficient Design for Downlink Pinching-Antenna Systems with QoS Guarantee
May 20, 2025



Pinching antennas have recently garnered significant attention due to their ability to dynamically reconfigure wireless propagation environments. Despite notable advancements in this area, the exploration of energy efficiency (EE) maximization in pinching-antenna systems remains relatively underdeveloped. In this paper, we address the EE maximization problem in a downlink time-division multiple access (TDMA)-based multi-user system employing one waveguide and multiple pinching antennas, where each user is subject to a minimum rate constraint to ensure quality-of-service. The formulated optimization problem jointly considers transmit power and time allocations as well as the positioning of pinching antennas, resulting in a non-convex problem. To tackle this challenge, we first obtain the optimal positions of the pinching antennas. Based on this, we establish a feasibility condition for the system. Subsequently, the joint power and time allocation problem is decomposed into two subproblems, which are solved iteratively until convergence. Specifically, the power allocation subproblem is addressed through an iterative approach, where a semi-analytical solution is obtained in each iteration. Likewise, a semi-analytical solution is derived for the time allocation subproblem. Numerical simulations demonstrate that the proposed pinching-antenna-based strategy significantly outperforms both conventional fixed-antenna systems and other benchmark pinching-antenna schemes in terms of EE.
Predicting Turn-Taking and Backchannel in Human-Machine Conversations Using Linguistic, Acoustic, and Visual Signals
May 19, 2025This paper addresses the gap in predicting turn-taking and backchannel actions in human-machine conversations using multi-modal signals (linguistic, acoustic, and visual). To overcome the limitation of existing datasets, we propose an automatic data collection pipeline that allows us to collect and annotate over 210 hours of human conversation videos. From this, we construct a Multi-Modal Face-to-Face (MM-F2F) human conversation dataset, including over 1.5M words and corresponding turn-taking and backchannel annotations from approximately 20M frames. Additionally, we present an end-to-end framework that predicts the probability of turn-taking and backchannel actions from multi-modal signals. The proposed model emphasizes the interrelation between modalities and supports any combination of text, audio, and video inputs, making it adaptable to a variety of realistic scenarios. Our experiments show that our approach achieves state-of-the-art performance on turn-taking and backchannel prediction tasks, achieving a 10\% increase in F1-score on turn-taking and a 33\% increase on backchannel prediction. Our dataset and code are publicly available online to ease of subsequent research.
Energy-Efficient Resource Allocation for NOMA-Assisted Uplink Pinching-Antenna Systems
May 12, 2025The pinching-antenna architecture has emerged as a promising solution for reconfiguring wireless propagation environments and enhancing system performance. While prior research has primarily focused on sum-rate maximization or transmit power minimization of pinching-antenna systems, the critical aspect of energy efficiency (EE) has received limited attention. Given the increasing importance of EE in future wireless communication networks, this work investigates EE optimization in a non-orthogonal multiple access (NOMA)-assisted multi-user pinching-antenna uplink system. The problem entails the joint optimization of the users' transmit power and the pinching-antenna position. The resulting optimization problem is non-convex due to tightly coupled variables. To tackle this, we employ an alternating optimization framework to decompose the original problem into two subproblems: one focusing on power allocation and the other on antenna positioning. A low-complexity optimal solution is derived for the power allocation subproblem, while the pinching-antenna positioning subproblem is addressed using a particle swarm optimization algorithm to obtain a high-quality near-optimal solution. Simulation results demonstrate that the proposed scheme significantly outperforms both conventional-antenna configurations and orthogonal multiple access-based pinching-antenna systems in terms of EE.
Sum Rate Maximization for NOMA-Assisted Uplink Pinching-Antenna Systems
May 01, 2025



In this paper, we investigate an uplink communication scenario in which multiple users communicate with an access point (AP) employing non-orthogonal multiple access (NOMA). A pinching antenna, which can be activated at an arbitrary point along a dielectric waveguide, is deployed at the AP to dynamically reconfigure user channels. The objective is to maximize the system sum rate by jointly optimizing the pinching-antenna's position and the users' transmit powers. The formulated optimization problem is non-convex, and addressed using the particle swarm optimization (PSO) algorithm. For performance benchmarking, two time division multiple access (TDMA) schemes are considered: one based on the pinching antenna individually activated for each user, and the other based on the single-pinching-antenna configuration serving all users. Numerical results demonstrate that the use of the pinching antenna significantly enhances the system sum rate compared to conventional antenna architectures. Moreover, the NOMA-based scheme outperforms the TDMA-based scheme with a single pinching antenna but is outperformed by the TDMA-based approach when the pinching antenna is adaptively configured for each user. Finally, the proposed PSO-based method is shown to achieve near-optimal performance for both NOMA and TDMA with a common pinching-antenna configuration.
Robust Resource Allocation for Over-the-Air Computation Networks with Fluid Antenna Array
Apr 22, 2025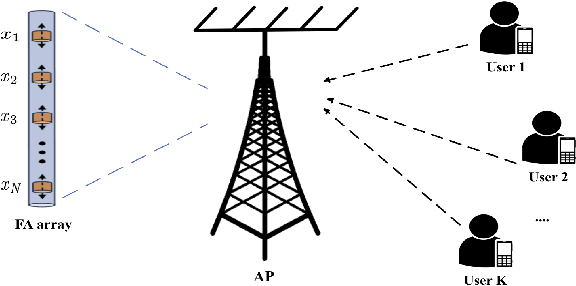
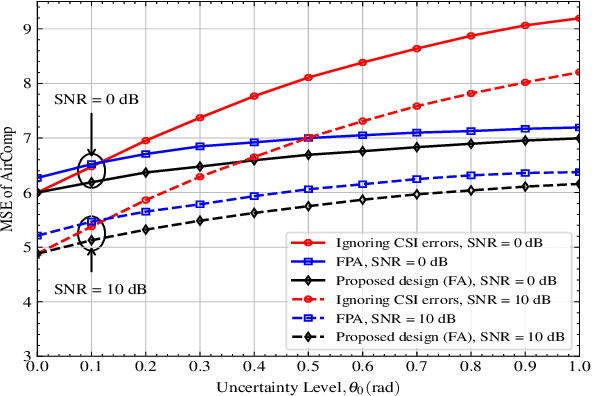
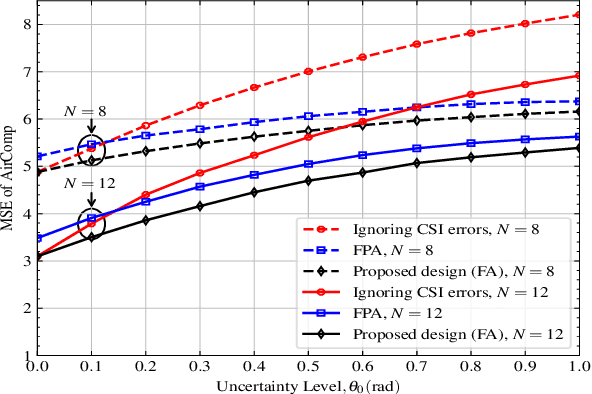
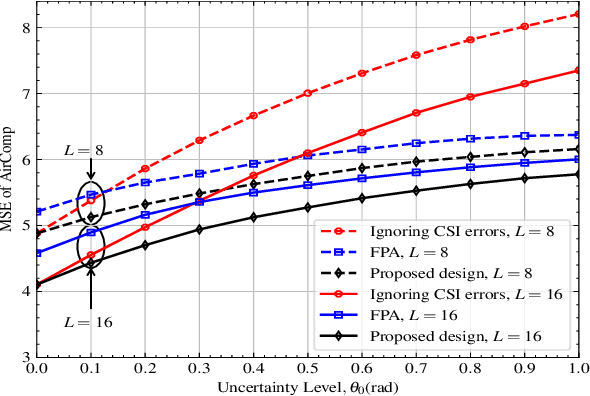
Fluid antenna (FA) array is envisioned as a promising technology for next-generation communication systems, owing to its ability to dynamically control the antenna locations. In this paper, we apply FA array to boost the performance of over-the-air computation networks. Given that channel uncertainty will impact negatively not only the beamforming design but also the antenna location optimization, robust resource allocation is performed to minimize the mean squared error of transmitted messages. Block coordinate descent is adopted to decompose the formulated non-convex problem into three subproblems, which are iteratively solved until convergence. Numerical results show the benefits of FA array and the necessity of robust resource allocation under channel uncertainty.
Recent Advances in Near-Field Beam Training and Channel Estimation for XL-MIMO Systems
Apr 08, 2025Extremely large-scale multiple-input multiple-output (XL-MIMO) is a key technology for next-generation wireless communication systems. By deploying significantly more antennas than conventional massive MIMO systems, XL-MIMO promises substantial improvements in spectral efficiency. However, due to the drastically increased array size, the conventional planar wave channel model is no longer accurate, necessitating a transition to a near-field spherical wave model. This shift challenges traditional beam training and channel estimation methods, which were designed for planar wave propagation. In this article, we present a comprehensive review of state-of-the-art beam training and channel estimation techniques for XL-MIMO systems. We analyze the fundamental principles, key methodologies, and recent advancements in this area, highlighting their respective strengths and limitations in addressing the challenges posed by the near-field propagation environment. Furthermore, we explore open research challenges that remain unresolved to provide valuable insights for researchers and engineers working toward the development of next-generation XL-MIMO communication systems.